- The paper introduces a mathematical framework to analyze LLM inference stability under KV cache constraints using discrete-time Markov chains.
- It derives critical processing rates and stability conditions based on memory growth profiles, offering guidelines for GPU provisioning and scheduling.
- Empirical validations on Meta-Llama and multi-GPU setups confirm close alignment between theoretical predictions and practical performance.
Queueing-Theoretic Stability Analysis for LLM Inference with KV Cache Constraints
Introduction
The paper "A Queueing-Theoretic Framework for Stability Analysis of LLM Inference with KV Cache Memory Constraints" (2605.04595) addresses the operational fundamentals of LLM inference from a queueing theory perspective, explicitly incorporating GPU memory limitations arising from key-value (KV) caching. Unlike classical ML inference workloads, LLMs exhibit pronounced memory intensiveness due to per-request KV cache growth—prompt lengths and sequential token generation amplify the demand on GPU resources. The framework proposes rigorous stability and instability conditions for LLM inference systems, characterized as discrete-time Markov chains, with a focus on practical GPU provisioning, scheduling, and scaling for sustained operation under stochastic request arrival.
Modeling LLM Inference with KV Cache Constraints
The model represents a single GPU worker constrained by a KV cache memory threshold M (tokens, not bytes), serving prompt requests that arrive stochastically. Each request i possesses a prompt size si and an output length oi, sampled independently from a joint distribution p(s,o). LLM inference is decomposed into two phases:
- Prompt Phase: The input is chunked (s^ tokens per chunk), processed sequentially, with memory accumulation proportional to chunk index.
- Decode Phase: Tokens are generated sequentially. Each new token increases memory by one unit, maxing out at si+oi before KV cache release.
Batching constraints enforce that aggregate memory usage at any time does not exceed M. Scheduling is work-conserving; FCFS and SJF are permissible. The processing time is normalized per batch, enabling discrete-slot analysis with arrival rate λ (requests/slot) and mean batch duration bˉ.
Rigorous Stability and Instability Conditions
The system's stability is formalized through Markov chain positive recurrence. The critical processing rate i0 is derived as:
i1
where i2 quantifies total memory consumed during both prompt and decode phases. Stability requires i3, with i4 representing headroom for the largest single request. Conversely, for i5, backlog grows unbounded and the service is deemed overloaded. A Lyapunov function is constructed over total outstanding memory demand, proving strict negative drift outside a compact set under work-conserving policies.
Empirical Validation and Numerical Results
Validation is conducted across single- and multi-GPU setups using Meta-Llama-3-8B and vLLM, over diverse joint prompt/decode length regimes. Theoretical predictions for i6 align closely with empirical GPU service rates, with Gap Absolute Percentage (GAP) error <10% even under time-varying distributions and heavy-tailed workload profiles.
The Cumulative Distribution Function of batch processing times under uniform 1:1 PD ratio illustrates the near-constant per-batch cost in real deployment:
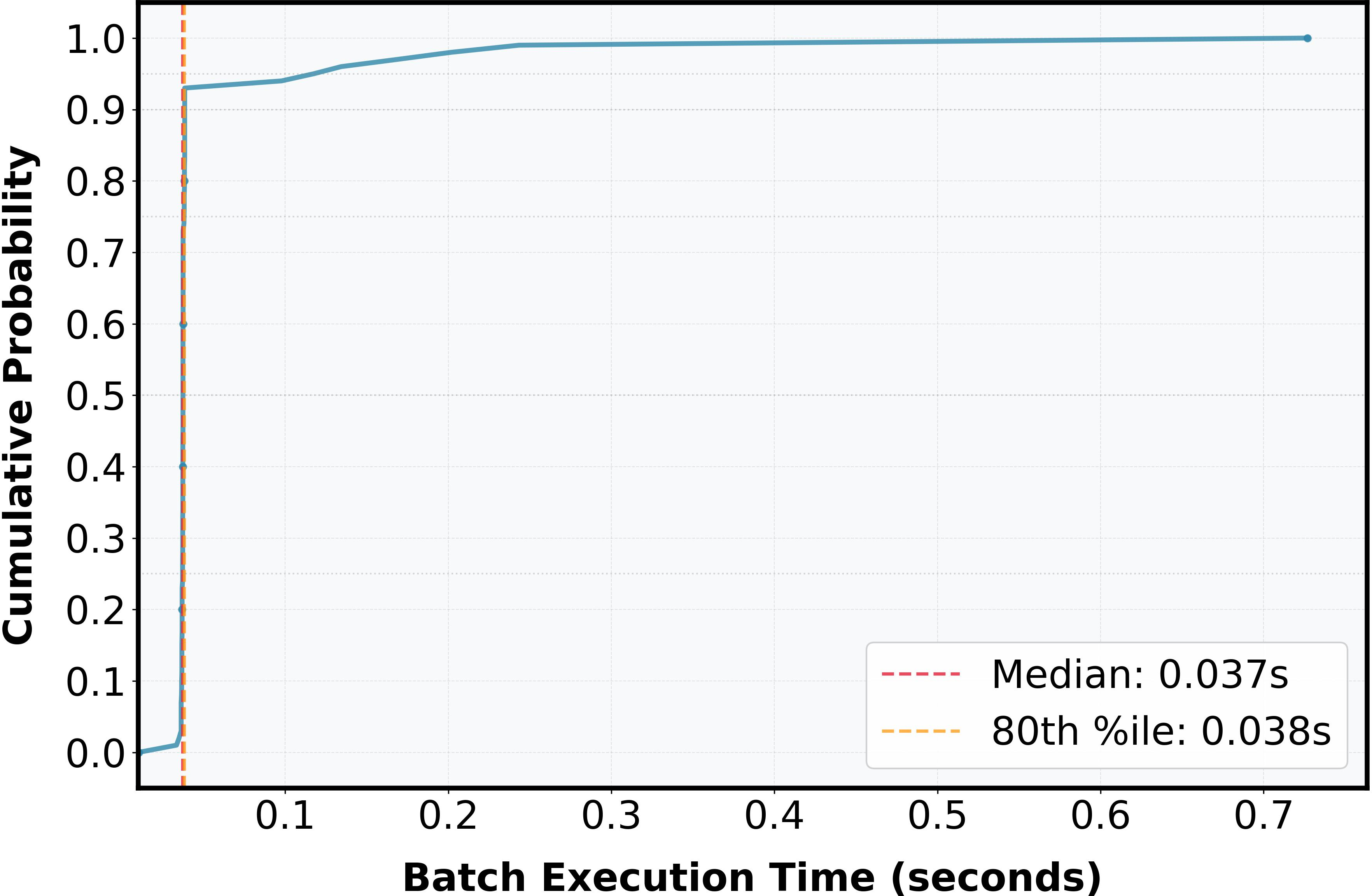
Figure 1: Cumulative Distribution Function for batch execution time with prefill/decode ratio 1:1 requests.
Queue growth dynamics under variable arrival rates are visualized: system is stable for i7, exhibiting bounded queue sizes; for i8, queue length grows linearly, confirming overload.
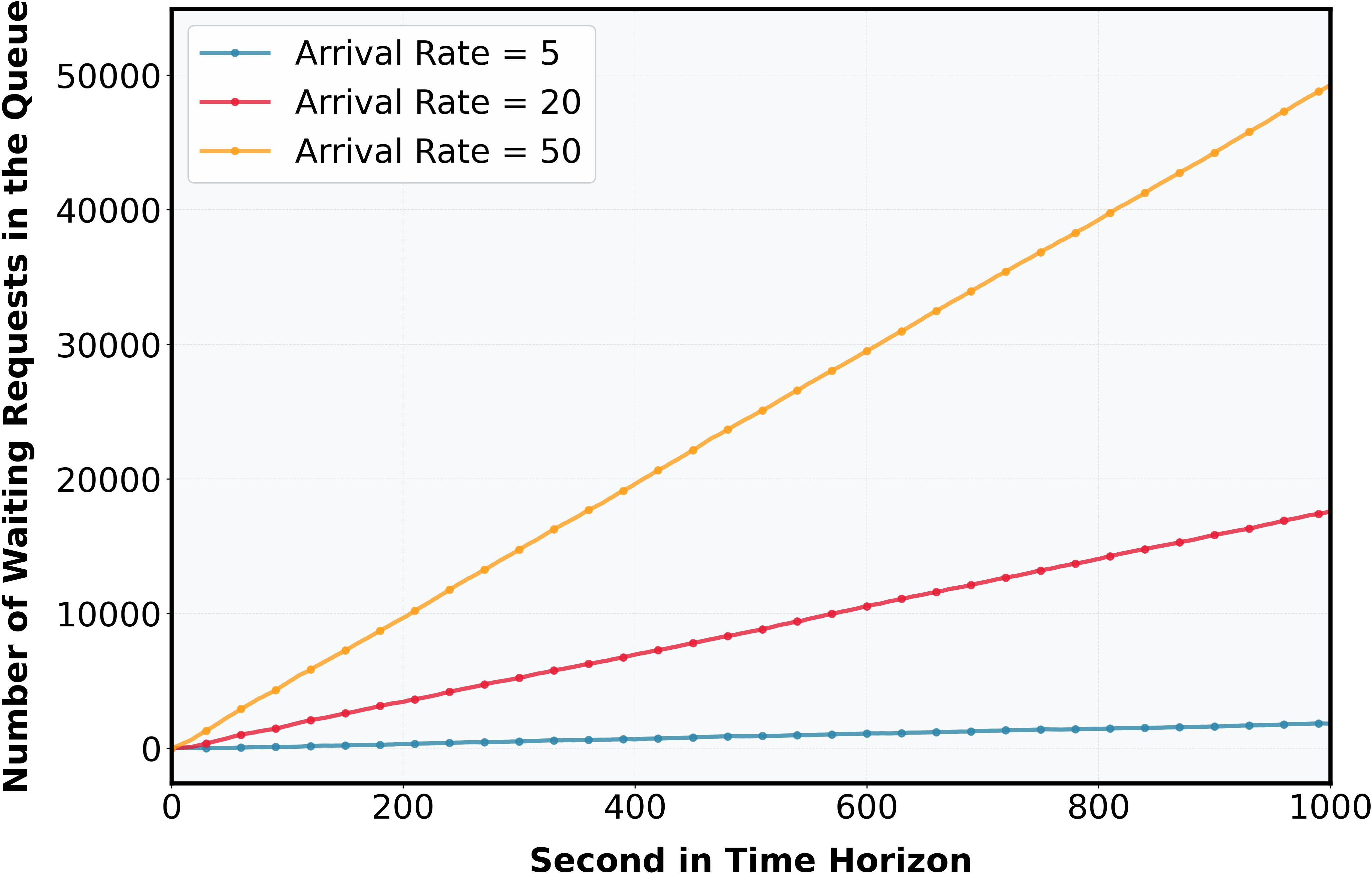
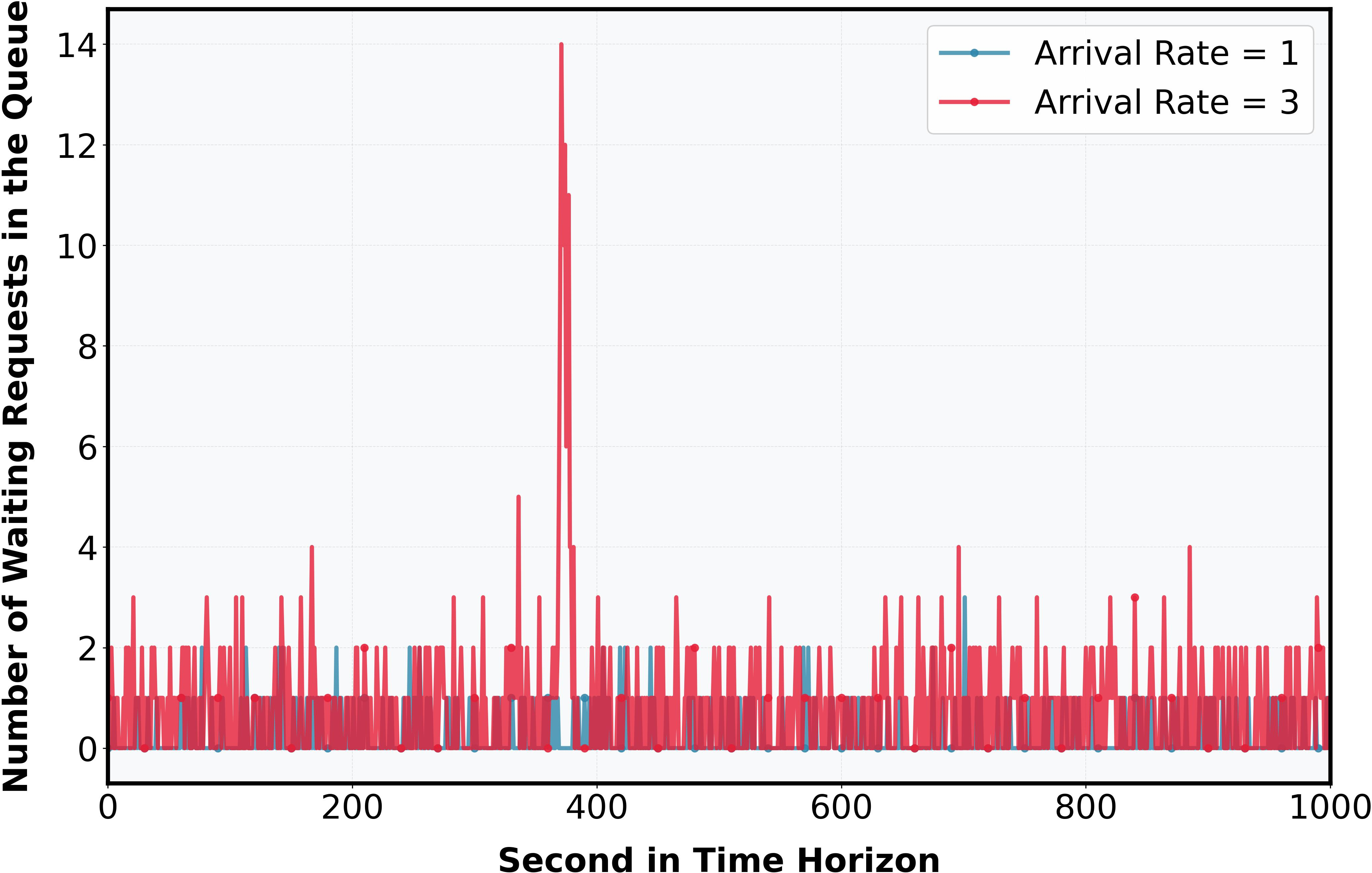
Figure 2: Number of waiting requests in the queue during the time horizon; left: overloaded (i9), right: stable (si0).
Marginal and joint probability density functions from the LongBench v2 dataset demonstrate the importance of modeling real input-output distributions in capacity planning.
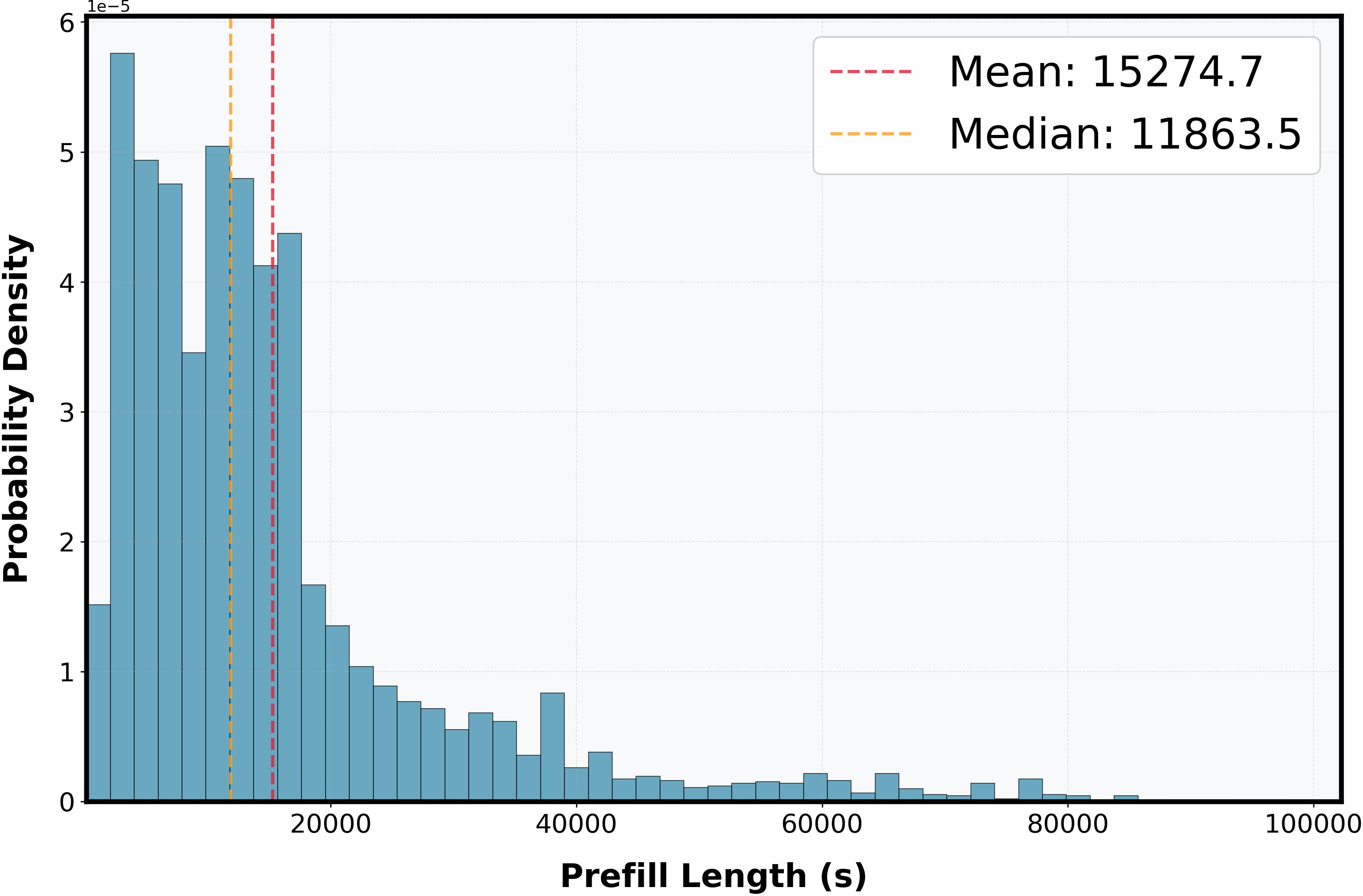
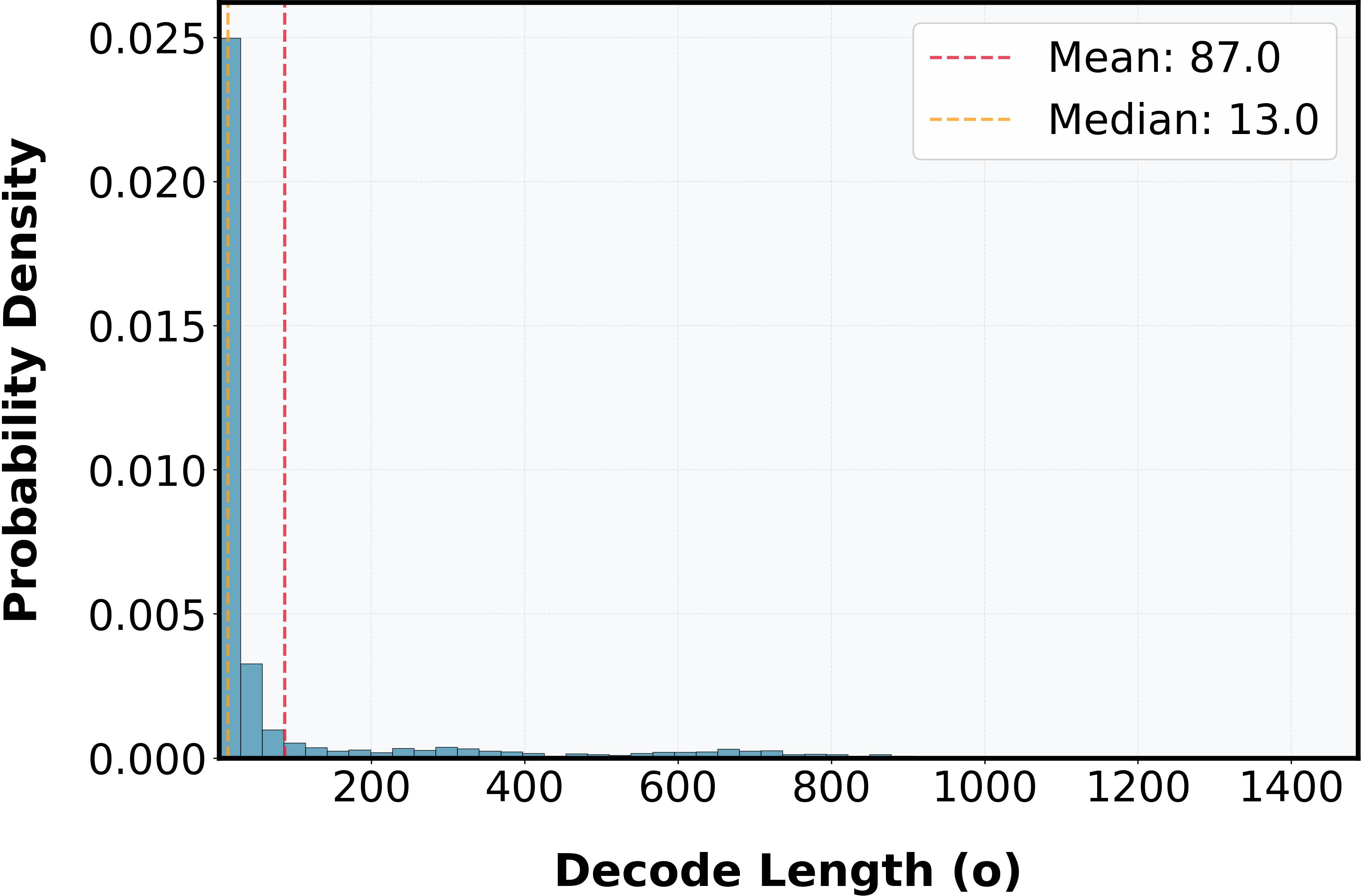
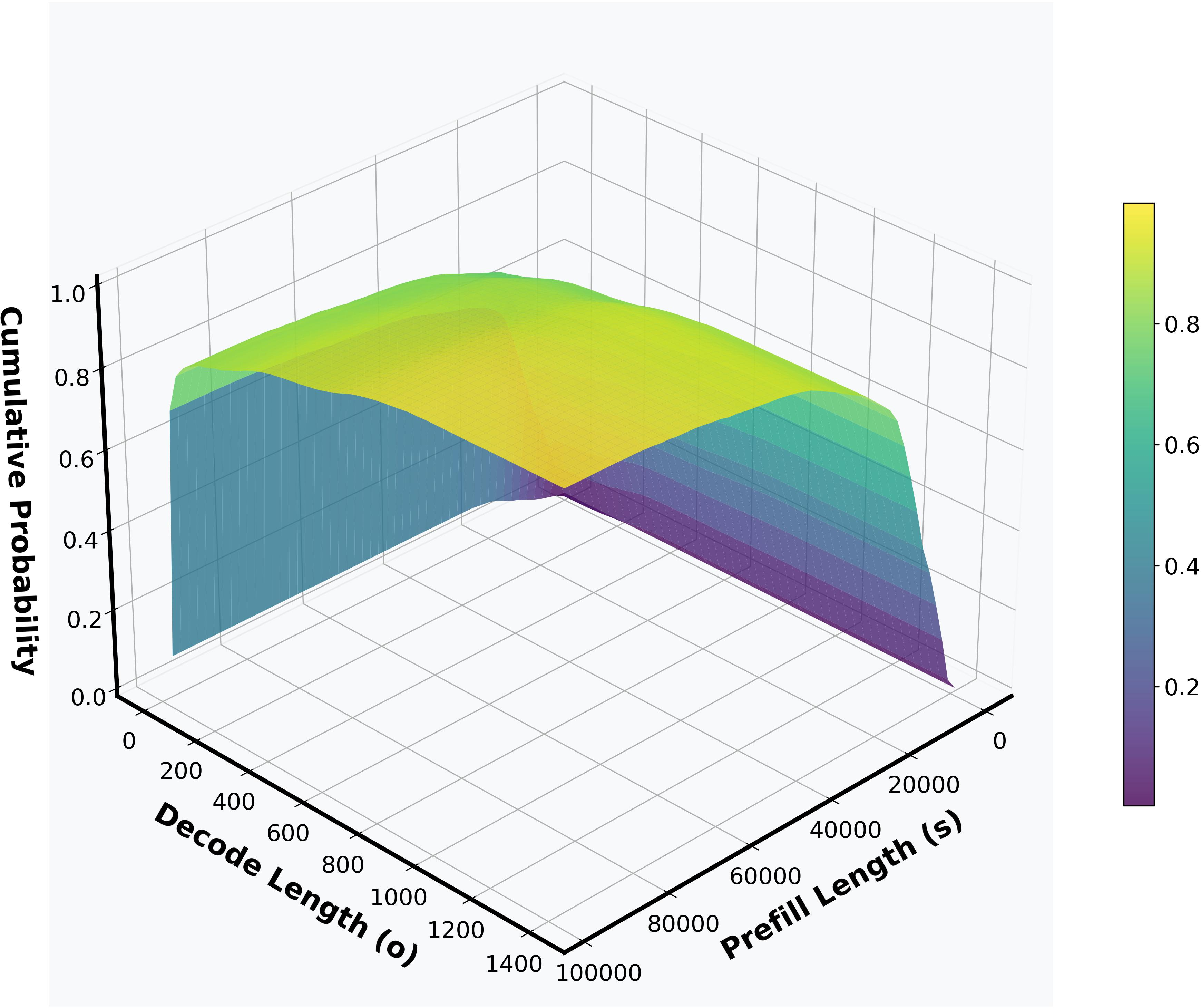
Figure 3: Marginal probability density function of prefill length (si1) from LongBench v2.
Multi-GPU cluster experiments corroborate the theoretical approach's scalability. For eight parallel GPUs, predicted aggregate service rates closely match empirical measurements, with a 3.38% gap, under uniform load balancing.
Practical and Theoretical Implications
The presented framework enables quantitative GPU provisioning: given si2 and system si3, deployment is guided by si4 for target utilization si5. This ensures avoidance of both over-provisioning (idle resources) and under-provisioning (queue instability). The robust convergence of theoretical/empirical rates across various scheduling, memory, and workload regimes supports practical adoption in production LLM inference service architecture.
Architecturally, the framework generalizes to tensor parallelism (by logical worker abstraction) but indicates further research is required for pipeline parallelism and decode-prompt disaggregation, where tandem or networked queues with separate constraints emerge. Modeling heavy-tailed batch processing demands necessitates trimmed mean statistical estimators for si6.
Theoretically, this work aligns LLM inference with stochastic bin packing and queueing networks—extending classical models by capturing the dynamic growth of per-request memory and chunked processing. It offers a closed-form operational stability criterion grounded in the actual memory trajectory per request, filling a notable gap in the literature.
Conclusion
The paper formalizes the queueing-theoretic stability boundary for LLM inference with explicit KV cache constraints, demonstrating high predictive accuracy for practical GPU resource management. The Lyapunov-based approach yields precise guidance for system provisioning and scaling, minimizing latency and maximizing throughput without violating memory limits. Extensions to more complex queueing topologies for advanced LLM serving architectures are a promising avenue for future research.

