Online Scheduling for LLM Inference with KV Cache Constraints
Published 10 Feb 2025 in cs.LG, cs.AI, and math.OC | (2502.07115v4)
Abstract: LLM inference, where a trained model generates text one word at a time in response to user prompts, is a computationally intensive process requiring efficient scheduling to optimize latency and resource utilization. A key challenge in LLM inference is the management of the Key-Value (KV) cache, which reduces redundant computations but introduces memory constraints. In this work, we model LLM inference with KV cache constraints theoretically and propose a novel batching and scheduling algorithm that minimizes inference latency while effectively managing the KV cache's memory. More specifically, we make the following contributions. First, to evaluate the performance of online algorithms for scheduling in LLM inference, we introduce a hindsight optimal benchmark, formulated as an integer program that computes the minimum total inference latency under full future information. Second, we prove that no deterministic online algorithm can achieve a constant competitive ratio when the arrival process is arbitrary. Third, motivated by the computational intractability of solving the integer program at scale, we propose a polynomial-time online scheduling algorithm and show that under certain conditions it can achieve a constant competitive ratio. We also demonstrate our algorithm's strong empirical performance by comparing it to the hindsight optimal in a synthetic dataset. Finally, we conduct empirical evaluations on a real-world public LLM inference dataset, simulating the Llama2-70B model on A100 GPUs, and show that our algorithm significantly outperforms the benchmark algorithms. Overall, our results offer a path toward more sustainable and cost-effective LLM deployment.
The paper introduces an online scheduling algorithm (MC-SF) that manages growing KV cache memory during sequential token generation in LLM inference.
The study formulates a hindsight optimal integer programming model and establishes a lower bound competitive ratio of Ω(√n) for deterministic methods.
Empirical evaluations on synthetic and real-world data show that MC-SF reduces end-to-end latency by up to 8× compared to baseline approaches.
Online Scheduling for LLM Inference with KV Cache Constraints
Problem Formulation and Motivation
The paper introduces an analytical and practical study of online scheduling for LLM inference under constraints imposed by Transformer Key-Value (KV) cache memory. LLM inference is characterized by sequential token generation, where each output token is dependent on previously generated tokens, and the associated KV cache memory grows linearly with sequence length. As modern deployments involve serving large numbers of user requests on GPUs, efficient scheduling is demanded not only to minimize user-perceived latency but also to ensure memory feasibility and sustainable operational cost.
The authors model LLM inference as a non-preemptive online scheduling problem, where incoming requests (prompts) and their responses (tokenized outputs) are batched and scheduled on a single worker (GPU) under a fixed memory constraint. Notably, memory usage for each request increases incrementally with every inference step due to the KV cache growth, and only one batch can be processed at a time.
The mathematical model provides a precise abstraction:
Each request i has prompt length si and output length oi
Memory usage at any step is si+j for the jth output token (1≤j≤oi)
Scheduling/batching must satisfy ∑i active(si+oi(t))≤M for every timestep t
Decisions must be made online; future arrivals and output lengths are unknown at scheduling time
This formalization addresses unique characteristics absent from classical job scheduling and batching literature, particularly the unbounded memory growth and strict sequential dependencies of Transformer-based LLMs.
Figure 1: Example of online batching and scheduling, illustrating how incoming prompts and partially-generated outputs are batched together under KV cache constraints.
Hindsight Optimal Scheduling and Competitive Analysis
To benchmark scheduling policies, the paper first formulates an integer programming (IP) approach that computes the minimum total inference latency (end-to-end) given complete knowledge of future request arrivals and output lengths. The IP encodes non-preemptive sequencing, evolving memory usage, and strict memory constraint per timestep. This hindsight optimal policy serves as a lower bound (gold standard) for any feasible online algorithm.
Key theoretical result: no deterministic online algorithm can guarantee a bounded competitive ratio under arbitrary arrival sequences; specifically, the competitive ratio lower bound is Ω(n) for n requests. This is due to adversarial arrivals that exploit information asymmetry.
The Memory-Constrained Shortest-First Scheduling Algorithm (MC-SF)
To address practical feasibility, the authors present MC-SF, a polynomial-time online algorithm comprising two components:
At each batch decision, prioritize requests already in progress (partially completed) to minimize their latency.
Add as many new waiting requests as possible to the batch, selected in non-decreasing order of output length oi, ensuring that memory feasibility holds not only at the current timestep but at all future steps during their execution (i.e., the evolving KV cache occupation never exceeds M).
The feasibility check is performed at token completion times, leveraging the fact that peak memory usage occurs at these points.
MC-SF is computationally efficient, running in O(M2) per decision step, and is shown to achieve a constant competitive ratio O(1) for the important case of simultaneous arrivals with identical prompt sizes and sufficient memory (M≥2maxi(si+oi)). Under identical output lengths, the competitive ratio is further bounded by 4.
Empirical Evaluation: Synthetic and Real-World Data
Synthetic Experiments
MC-SF is compared against the hindsight optimal in two synthetic settings:
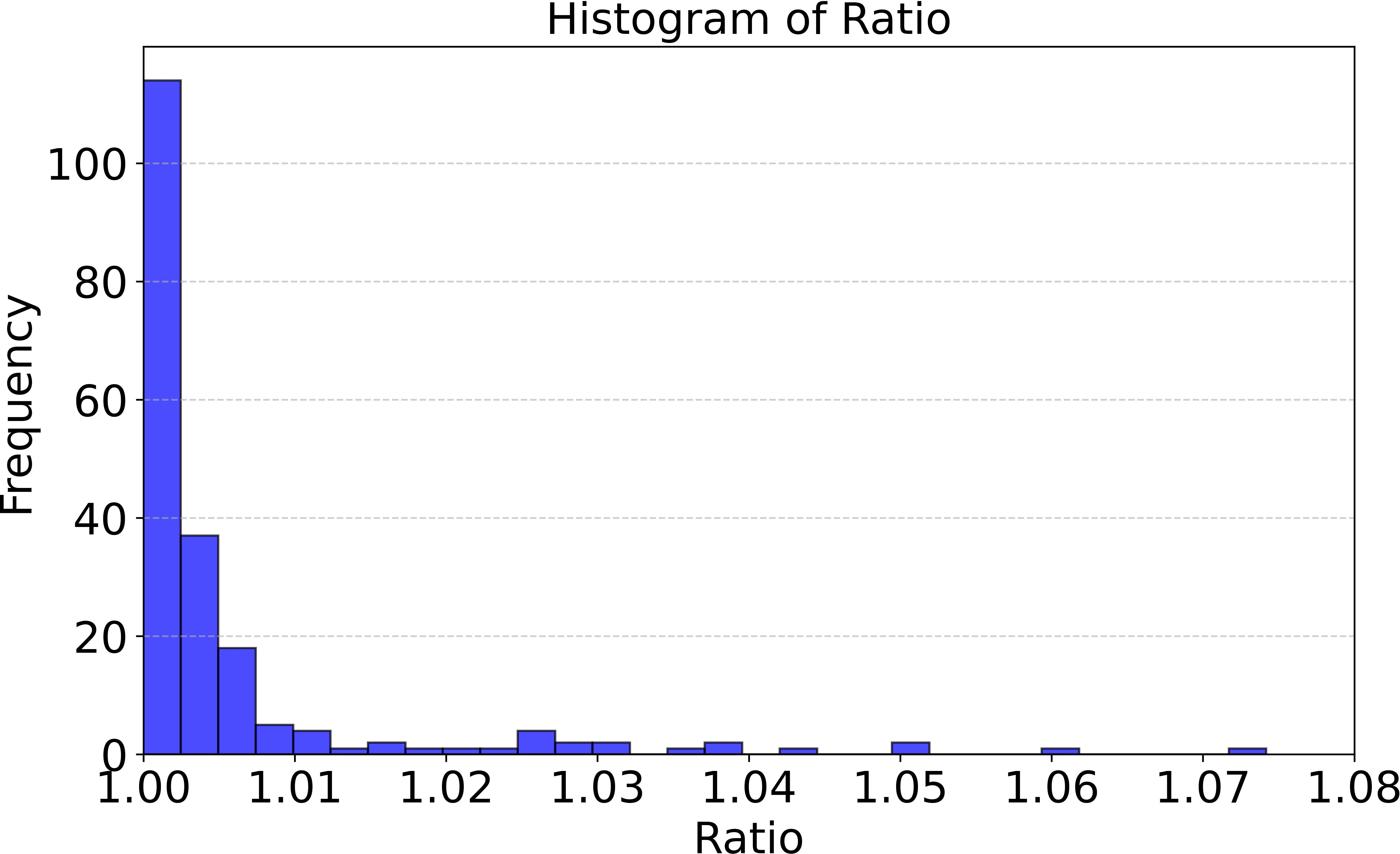
All-at-once arrivals: All requests known at time zero. Average latency ratio: 1.005; MC-SF achieves exact optimal in a majority of trials (114 out of 200).
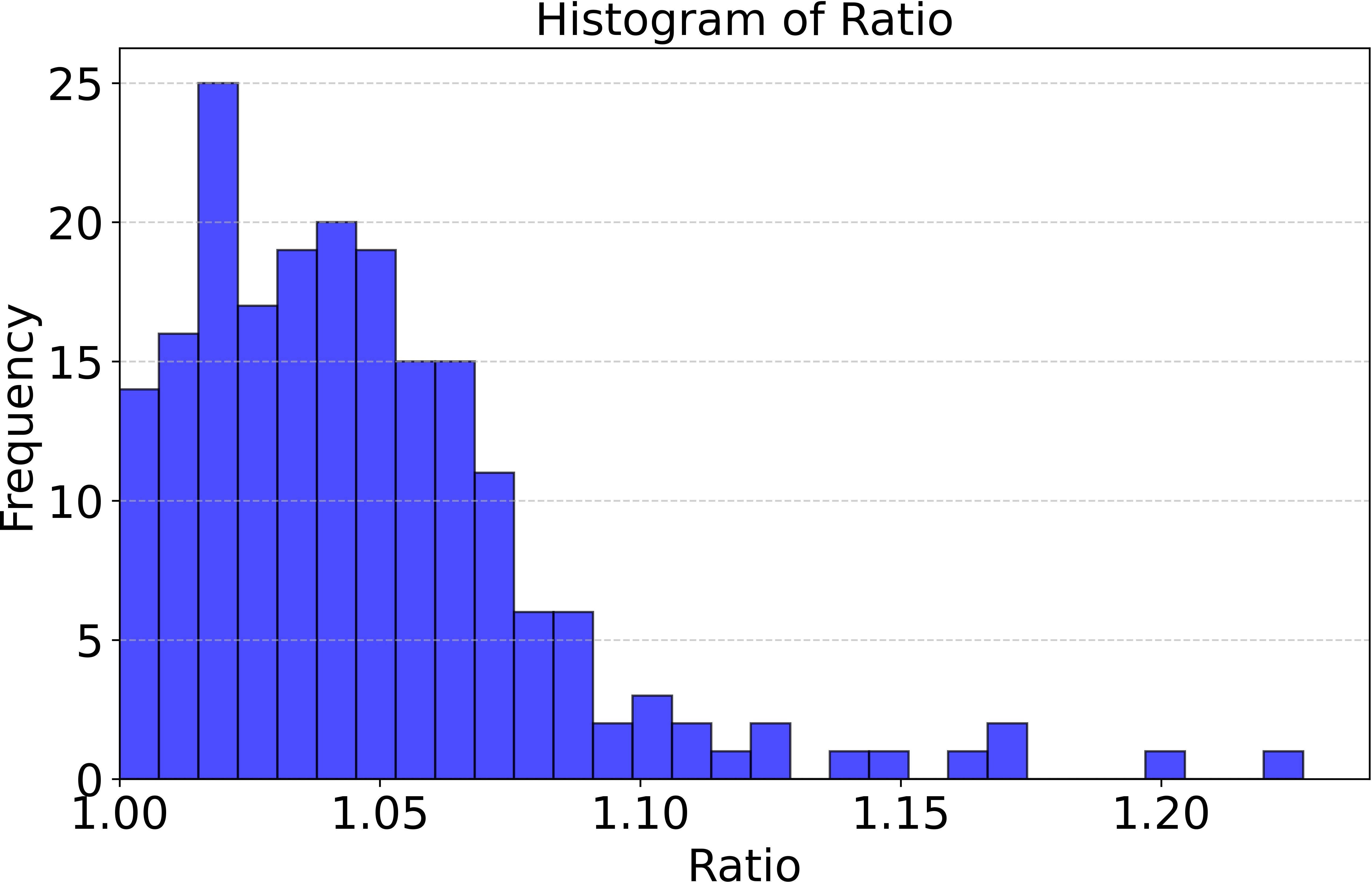
Online Poisson arrivals: Requests arrive stochastically. Average latency ratio: 1.047; the worst-case observed ratio is 1.227.
These ratios reveal that MC-SF is structurally close to optimal even under substantial uncertainty in arrivals.
Figure 2: Histogram of latency ratio (MC-SF vs. Hindsight Optimal) for both all-at-once and online stochastic arrival models.
Large-Scale Real Data Simulation
Using the LMSYS-Chat-1M dataset (10,000 prompts, real-world conversation traces), MC-SF is simulated against several representative scheduling baselines:
α-protection β-clearing (probabilistic clearing upon KV cache overflow)
MC-Benchmark (combines FCFS batching and future memory feasibility checks)
Experiments are run under two demand regimes (arrival rates λ=50 for high, λ=10 for low) using a Llama2-70B model on A100 GPUs with realistic memory limits.
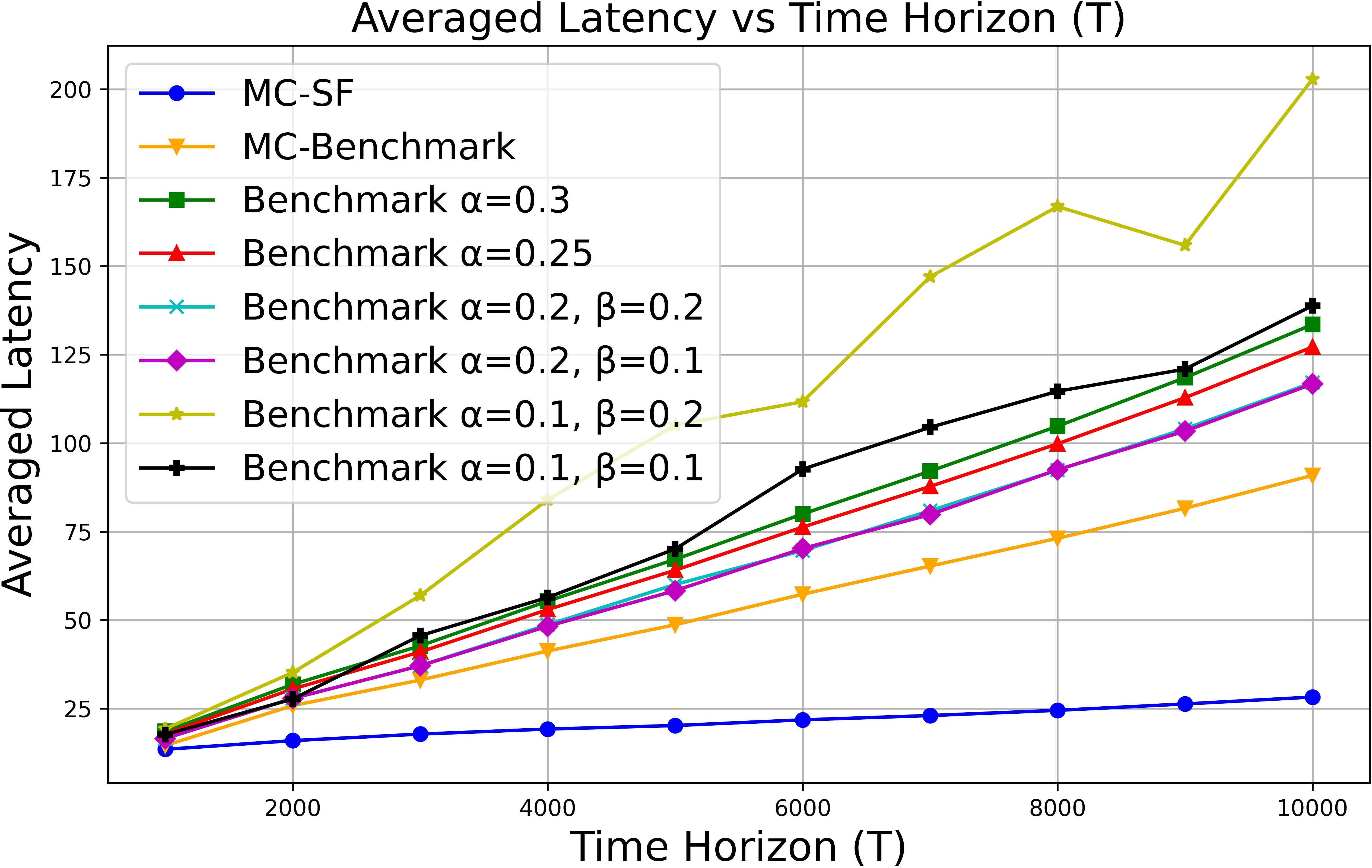
Results demonstrate robust superiority of MC-SF:
Average end-to-end latency is up to 6× lower in high-demand settings and >8× lower in low-demand compared to best baselines
MC-SF maintains full memory utilization without overflows; baselines frequently suffer eviction, excess recomputation, or inefficient memory use
Figure 3: Average end-to-end latency across scheduling algorithms for high and low demand regimes; MC-SF yields the lowest slope and best scaling.
Implementation and Deployment Considerations
MC-SF can be implemented in LLM serving frameworks with minimal overhead; batching logic must incorporate lookahead memory feasibility checks at all relevant completion times.
Algorithms dependent on hyperparameters (α, β) require empirical tuning and may incur unnecessary evictions or recomputation under realistic workloads.
Accurate prediction of output length oi is assumed; imperfect predictors can be accommodated by conservative over-provisioning or adaptive clearing policies, though at a cost in efficiency.
For scaling to multiple workers, further research is required in distributed scheduling under inter-worker communication and memory coordination.
Theoretical and Practical Implications
This work formalizes the impact of KV cache growth on LLM inference scheduling, bridging gaps between systems research and online algorithm analysis. Explicit memory tracking over sequential token generations is necessary to avoid costly resource contention, outages, and waste.
The strong empirical and theoretical performance of MC-SF positions it as a principled default for LLM serving, especially for deployments aiming to reduce operational costs, power usage, and improve user-perceived latency. The algorithm's design aligns with sustainability goals by maximizing memory utilization and minimizing the number of active GPUs, which is critical given the documented resource demands of large-scale LLM deployments.
Open directions include robust scheduling under inaccurate output length predictions, optimization over multiple parallel workers, and handling bursty or outlier jobs in otherwise stochastic traffic.
Conclusion
The study provides a rigorous foundation and practical tools for online batching and scheduling of LLM inference under KV cache constraints. The MC-SF algorithm achieves near-optimal latency and full memory safety, robustly outperforming industry-standard heuristics. This work establishes concrete strategies for improving the efficiency, sustainability, and scalability of LLM inference servers, and opens new avenues for algorithmic research in resource-constrained AI serving environments.
“Emergent Mind helps me see which AI papers have caught fire online.”
Philip
Creator, AI Explained on YouTube
Sign up for free to explore the frontiers of research
Discover trending papers, chat with arXiv, and track the latest research shaping the future of science and technology.Discover trending papers, chat with arXiv, and more.