- The paper introduces Apt-Serve, which leverages a hybrid cache scheme combining KV and hidden caches to reduce memory usage and enable larger batch sizes.
- It adapts runtime scheduling by formulating the batch composition as an optimization problem to minimize pending time under memory constraints.
- Performance evaluation demonstrates up to an 8.8× increase in throughput compared to state-of-the-art LLM inference serving systems.
Apt-Serve: Adaptive Request Scheduling on Hybrid Cache for Scalable LLM Inference Serving
The paper "Apt-Serve: Adaptive Request Scheduling on Hybrid Cache for Scalable LLM Inference Serving" introduces a novel framework addressing the bottlenecks in LLM inference serving systems related to cache management and scheduling policies. As the demand for LLMs continues to grow, meeting latency Service-Level Objectives (SLOs) while maintaining high request rates becomes increasingly challenging. This paper analyzes the inadequacies in existing systems and proposes Apt-Serve, which enhances effective throughput by integrating a hybrid cache scheme and adaptive scheduling mechanism.
Introduction
LLM inference serving systems are crucial for a wide variety of AI-driven applications, necessitating scalability to accommodate increasing user requests with low latency. Current systems struggle to maintain high throughput, primarily due to constraints imposed by memory-intensive KV caches and inflexible batch composition under First-Come-First-Serve (FCFS) scheduling policies. The essential contributions of Apt-Serve include a hybrid cache strategy combining KV cache with hidden cache to reduce memory usage, allowing larger batch sizes, and an adaptive scheduling algorithm optimizing batch compositions based on runtime data.
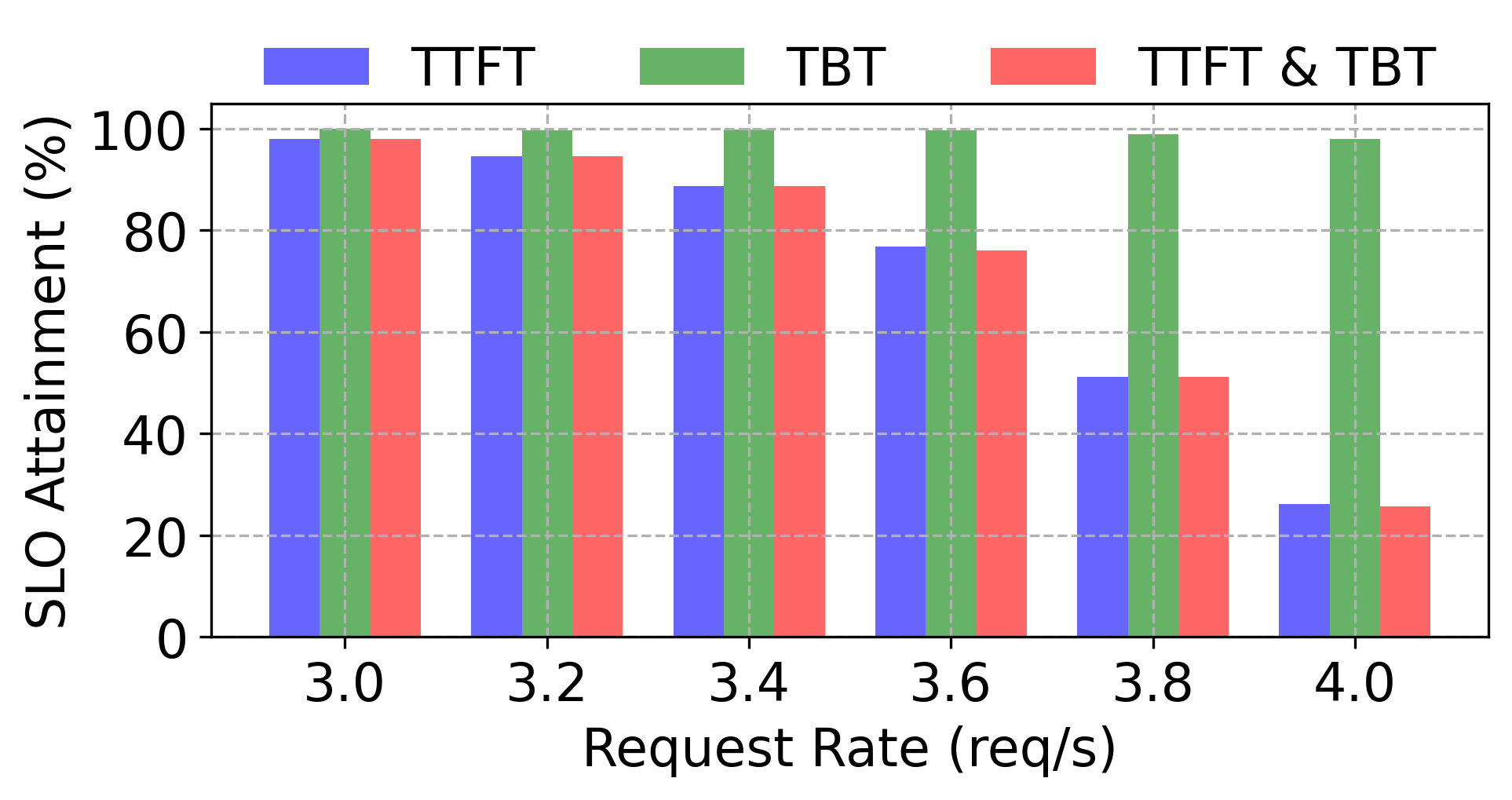
Figure 1: Serving sampled requests from the ShareGPT dataset and comparing their SLO attainment on different systems.
Hybrid Cache Scheme
The KV cache mechanism is pivotal for reducing computational complexity during LLM inference but is memory-intensive, restricting batch sizes and effective throughput. Apt-Serve addresses this by introducing a hidden cache, which stores reusable input hidden state vectors taking up less memory compared to key and value vectors. This hybrid approach enables larger batch sizes by dynamically switching between cache types depending on the memory constraints and the current request load.
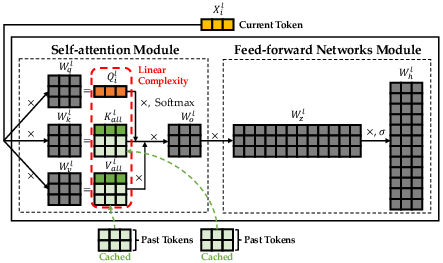
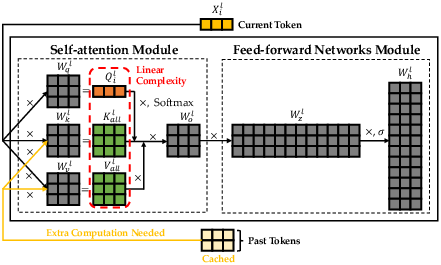
Figure 2: Decoding with KV cache in a Transformer layer.
Adaptive Runtime Scheduling
Apt-Serve's adaptive runtime scheduling framework optimizes batch composition by taking into account dynamically tracked information about requests, such as pending time and memory requirements. This involves formulating the scheduling decision as an optimization problem that maximizes the reduction in pending time while adhering to memory constraints. The efficient greedy-based solution provided in the paper includes theoretical guarantees and scales well with increased candidate requests.
Extensive evaluations demonstrate Apt-Serve's significant improvements in effective throughput across various real-world datasets and LLM configurations. It achieves up to 8.8× enhancement in throughput compared to state-of-the-art systems like Sarathi-Serve and vLLM because of its ability to adaptively manage cache usage and efficiently schedule requests.
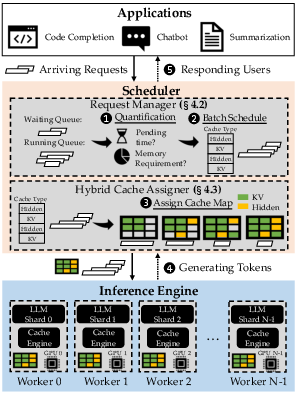
Figure 3: An overview of Apt-Serve.
Implications and Future Directions
Apt-Serve paves the way for more scalable LLM serving systems by rethinking cache management and runtime scheduling. Its design is orthogonal to many existing optimizations such as prefill-decode coalescing and can be integrated with disaggregated hardware frameworks. Future research may focus on extending hybrid cache designs in distributed settings and exploring learning-based dynamic scheduling approaches to further enhance request handling efficiency.
Conclusion
The Apt-Serve framework significantly advances scalable LLM inference serving by effectively addressing memory constraints and scheduling inflexibility. Its hybrid cache scheme and adaptive scheduling method offer a promising pathway toward higher throughput and more responsive LLM-based applications, ensuring adherence to strict latency SLOs even as request rates continue to rise.

