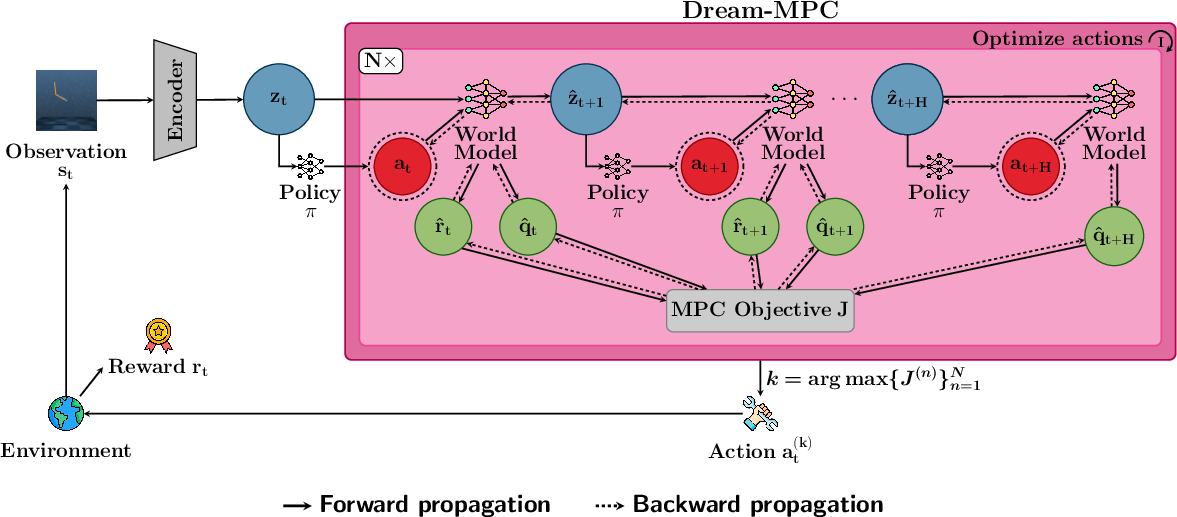
Dream-MPC: Gradient-Based Model Predictive Control with Latent Imagination
Abstract: State-of-the-art model-based Reinforcement Learning (RL) approaches either use gradient-free, population-based methods for planning, learned policy networks, or a combination of policy networks and planning. Hybrid approaches that combine Model Predictive Control (MPC) with a learned model and a policy prior to leverage the advantages of both paradigms have shown promising results. However, these approaches typically rely on gradient-free optimization methods, which can be computationally expensive for high-dimensional control tasks. While gradient-based methods are a promising alternative, recent works have empirically shown that gradient-based methods often perform worse than their gradient-free counterparts. We propose Dream-MPC, a novel approach that generates few candidate trajectories from a rolled-out policy and optimizes each trajectory by gradient ascent using a learned world model, uncertainty regularization and amortization of optimization iterations over time by reusing previously optimized actions. Our results on 24 continuous control tasks show that Dream-MPC can significantly improve the performance of the underlying policy and can outperform gradient-free MPC and state-of-the-art baselines. We will open source our code and more at https://dream-mpc.github.io.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces Dream-MPC, a smarter way for robots and AI agents to plan their next moves. It combines:
- a “world model” (a learned simulator that predicts what might happen next),
- a policy (a fast rule-of-thumb for what to do),
- and gradient-based planning (using the “direction of improvement” to refine a plan).
The goal is to plan good actions quickly and reliably, even in complex tasks, while using less computing power than common sampling-heavy methods.
What questions did the researchers ask?
In simple terms, they asked:
- Can we make planning with learned simulators faster and better by using gradients (the direction that makes things better) instead of trying thousands of random guesses?
- Why have earlier gradient-based methods struggled, and how can we fix that?
- Can combining a learned policy (a good starting guess) with gradient-based planning improve performance and reduce computation?
How did they do it? (Explained with everyday ideas)
Think of controlling a robot like a self-driving scooter:
- The policy is a quick reflex: “At this moment, turn slightly right.”
- The world model is your mental simulator: “If I turn right now, where will I be in 2 seconds?”
- Planning is choosing a short sequence of actions that looks best in the near future.
Here’s how Dream-MPC works:
- Latent imagination (world model): Instead of simulating raw pixels or full physics, the system predicts in a compact “latent space,” like imagining the future with a simplified mental map. This is faster and still useful.
- Model Predictive Control (MPC): At every step, it plans a short future (like planning the next few seconds), picks the first action, then replans next time. This keeps it adaptable.
- Start from a good guess (policy prior): Instead of starting from scratch, it rolls out a few (just a handful) candidate action sequences from a learned policy. This gives “warm starts” that are already pretty good.
- Use gradients to improve plans: Imagine you’re climbing a hill in the fog to reach the top (the best outcome). A gradient tells you which direction goes uphill. Dream-MPC uses the learned model to compute these “uphill” directions and nudges each candidate plan to be better—this is gradient ascent.
- Be careful with uncertainty: The learned model can be wrong, especially in unfamiliar situations. Dream-MPC measures how uncertain the model seems (using an ensemble of value predictors) and penalizes risky, uncertain plans. That keeps it from being overconfident.
- Reuse past work (action reuse): Because MPC replans every step, previous optimized actions are reused as a starting point. This “amortizes” the work over time—like carrying over your previous half-finished plan—so you need fewer updates each step.
- Fewer guesses, more guidance: Traditional sampling methods (like CEM/MPPI) try hundreds or thousands of random action sequences per step. Dream-MPC tries only a few, then uses gradients to improve them. That’s more efficient, especially when the action space is large.
What did they find?
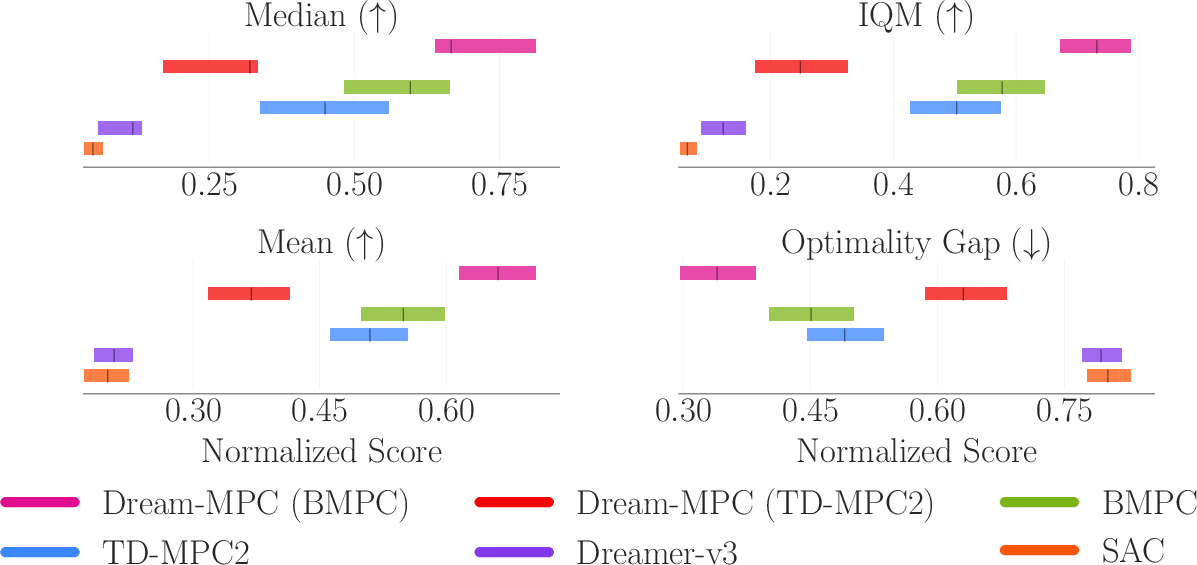
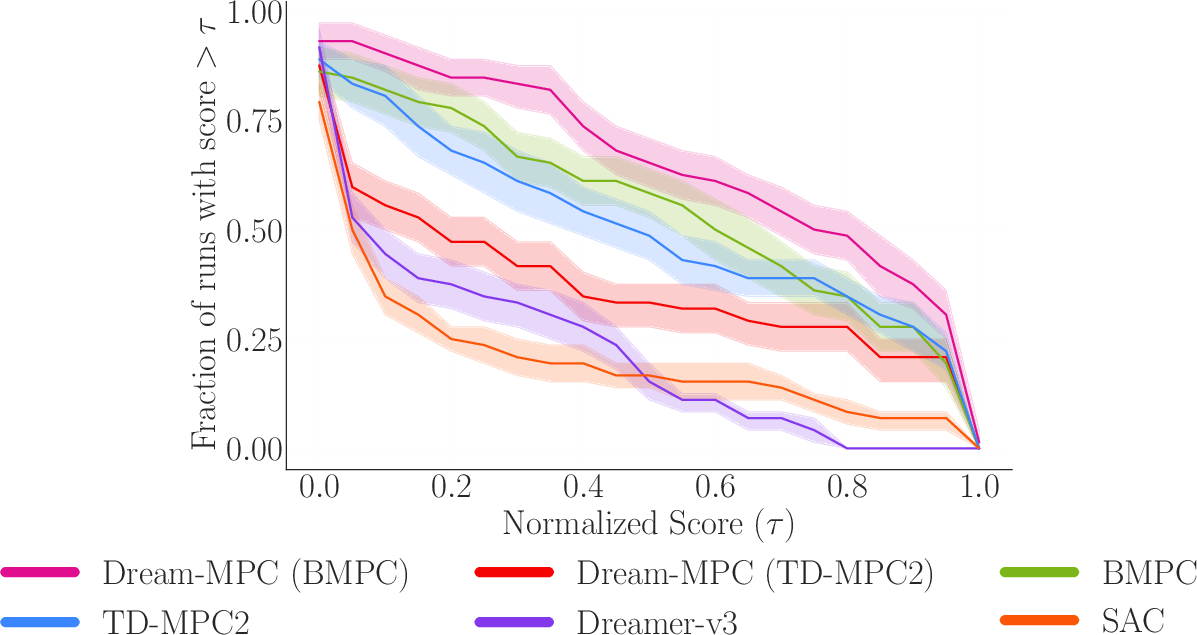
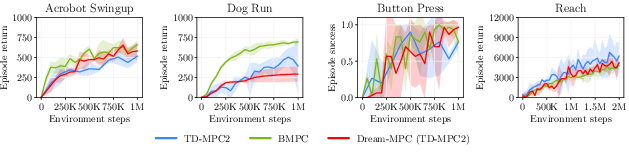
Across 24 continuous-control tasks (locomotion and manipulation, including some with camera images), Dream-MPC showed:
- Better performance than strong baselines when paired with a good policy:
- With a strong policy (BMPC), Dream-MPC often outperformed gradient-free MPC (like MPPI) and other state-of-the-art methods.
- It significantly boosted the performance of the underlying policy at test time.
- Much lower compute during planning:
- Example comparison: a typical MPPI setup might do 9,216 model evaluations per step; Dream-MPC used around 15 in their setting.
- In lower-dimensional tasks, Dream-MPC’s per-step planning time was comparable to (or slightly faster than) MPPI.
- Works with image inputs too:
- On several tasks using camera images, Dream-MPC improved over the policy and could match or beat MPPI.
- Training-time use:
- When used during training (not just at test time), Dream-MPC could match TD-MPC2 on some tasks and slightly lag on very high-dimensional ones (less candidate diversity can cause “sticking” to weaker solutions). Still, the overall trend was promising.
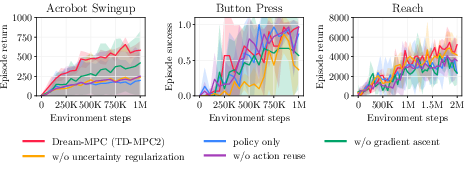
- Two key add-ons made the difference:
- Uncertainty penalty: helped avoid overconfident, bad plans in parts of the world model it hadn’t learned well.
- Action reuse: reduced computation and improved stability by carrying good plans forward.
Why is this important?
- Faster and more reliable planning: Using gradients and good starting guesses lets the system plan with far fewer trials, making it more practical for real robots or embedded devices with less computing power.
- Scales to harder problems: Sampling-based methods struggle as the number of possible actions grows. Gradients scale better: adding action dimensions increases the number of “directions,” not the number of random guesses needed.
- Safer decisions: Uncertainty-aware planning reduces the chance of the system making bold moves in situations it doesn’t understand well, leading to more robust behavior.
Bottom line: what’s the impact?
Dream-MPC shows that gradient-based planning with a learned world model can be both fast and high-performing when paired with a good policy and careful uncertainty handling. This could help robots and other autonomous systems plan effectively in real time, even in complex, high-dimensional tasks—bringing us closer to reliable, efficient decision-making in the real world. Future directions include adapting the planning parameters on the fly, improving the policy prior further, and extending to multi-task settings.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, phrased to guide actionable follow-up research.
- Lack of theoretical guarantees: no analysis of convergence, stability, or optimality for gradient ascent over learned latent dynamics with action reuse and uncertainty penalties.
- Dependence on a high-quality policy prior: performance drops when the prior is weak (e.g., TD-MPC2 policy). Strategies to learn/improve priors jointly with planning, or to design alternative proposal distributions, are not explored.
- Limited uncertainty modeling: the uncertainty penalty is based on a Q-ensemble statistic (mean×std) without calibration analysis; alternatives (e.g., Bayesian ensembles, bootstrapping, trajectory-level epistemic/aleatoric separation, CVaR/risk-sensitive objectives) are not evaluated.
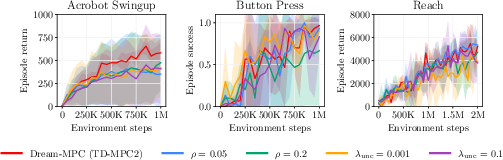
- Fixed penalty coefficient: the uncertainty regularization coefficient is set globally (λ_unc = 0.01) with limited sensitivity analysis; no adaptive schemes grounded in uncertainty calibration or task-agnostic tuning are provided.
- Action bounds and constraint handling: how action constraints are enforced during gradient updates (projection, squashing, clamping) is unspecified; no incorporation of state/action constraints or safety constraints into the MPC objective.
- Gradient quality and optimizer choice: no systematic study of gradient pathologies (vanishing/exploding, noise, bias from model error), smoothing, or clipping; no comparisons to alternative optimizers (Adam, momentum, line search, LBFGS) or second-order methods (iLQR/DDP).
- Diversity of candidate trajectories: reliance on very few candidates (N≈5) sampled from the policy; no mechanisms for diversity (e.g., random restarts, entropy incentives, dropout/ensemble-based proposals) or adaptive candidate allocation based on problem difficulty.
- Amortization via action reuse: the reuse coefficient ρ is fixed; no adaptive or state-dependent scheduling, and no analysis of closed-loop stability, drift, or failure modes due to reusing stale plans.
- Horizon selection: planning horizon is static; no principled method to adapt horizon based on model uncertainty/error accumulation, or to mix short- and long-horizon value bootstrapping dynamically.
- Compute accounting: comparisons emphasize model evaluations but not backward-pass costs; a compute/latency–performance trade-off matched to fair budgets across methods (e.g., MPPI vs gradient-based with equal wall-clock or FLOPs) is missing.
- Real-time and embedded deployment: inference timing is reported only on an RTX 4090; no evaluation on CPUs or embedded platforms (e.g., Jetson), and no characterization of latency variance under real-time constraints.
- Simulation-only validation: no real-robot experiments; sim-to-real robustness, latency constraints under sensing/actuation delays, and safety in deployment remain unaddressed.
- Training with gradient-based MPC: combining gradient-based MPC with imitation (BMPC-like bootstrapping) was avoided due to anticipated instability; stabilization strategies (e.g., curriculum, trust regions, entropy, candidate diversity, conservative value learning) are unexplored.
- Visual observation scope: image-based experiments cover a small set of DMControl tasks; robustness to visual distractors, domain shifts, partial observability, and more complex visuals is untested.
- Model error robustness: performance degradation with longer horizons suggests model-bias sensitivity; formal analysis and robust planning techniques (e.g., uncertainty-aware horizon, trajectory-level pessimism, value clipping, robust dynamics) are not investigated.
- Value overestimation mitigation: only an uncertainty penalty is used; integration and comparison with alternative pessimistic/RL techniques (double/ensemble Q, conservative value estimation, MOPO/COMBO-style penalties) within gradient-based MPC is missing.
- World-model generality: results span TD-MPC2, BMPC, and Dreamer, but a systematic comparison of generative vs control-centric models, model capacity, latent dimensionality, and representation smoothness on planner performance is absent.
- Sparse/delayed rewards: while some sparse tasks are included, there is no focused analysis of how gradients propagate through sparse rewards/value bootstrapping, nor techniques to handle extremely delayed/terminal rewards in gradient-based planning.
- Exploration during training: no dedicated exploration strategy is proposed for gradient-based MPC training (e.g., optimism/pessimism, intrinsic motivation, uncertainty-driven exploration); impact on data diversity is unclear.
- Latent geometry and differentiability: the effect of latent representation smoothness, modeling choices, and non-smooth transitions on optimizer behavior and gradient signal quality is not analyzed.
- Uncertainty in Dreamer integration: when integrating with Dreamer (which may lack Q-ensembles), the computation of the uncertainty term is not fully specified or compared across possible implementations.
- Statistical robustness: many results report 3 seeds; high-variance tasks and broad claims could benefit from more seeds and stronger statistical testing.
- Multi-task generalization: the approach is evaluated on single-task models; extensions to multi-task world models, task-conditioned planning, and transfer are left open.
- Scalability limits: beyond HumanoidBench and dog, scalability to very high-dimensional action spaces (e.g., dexterous hands, multi-agent control) is not quantified; upper bounds and failure regimes are unknown.
- Stochastic/partially observed dynamics: robustness to stochastic transitions, observation noise, or non-Markovian settings is not evaluated; gradient-based planning in stochastic latent models remains unexamined.
- Adaptive compute policies: no mechanism to adjust N (candidates), I (iterations), or H (horizon) online based on time budget or uncertainty; compute–performance adaptation remains an open design point.
- Comparison to trajectory optimization baselines: no head-to-head evaluation against iLQR/DDP or differentiable shooting in latent space to contextualize gains of pure gradient ascent.
- Reproducibility: code is promised but not available within the paper; exact implementation details (e.g., gradient clipping, action projection) and configs for all 24 tasks are necessary for faithful reproduction.
Practical Applications
Immediate Applications
Below are actionable ways to use the paper’s findings and method today, with sector links, potential tools/workflows, and feasibility notes.
- Efficient on-robot planning for resource-constrained platforms
- Sectors: robotics (manufacturing, logistics, agriculture, service robots, drones).
- What to deploy: a Dream-MPC planner module that replaces MPPI/CEM in TD-MPC2/BMPC/Dreamer stacks to cut model evaluations and latency; ROS2 controller node; Jetson-friendly inference builds (FP16, TensorRT/ONNX).
- Workflow: collect task data → train world model + policy → integrate Dream-MPC as the online planner → monitor uncertainty → periodic re-training.
- Dependencies/assumptions: a trained differentiable world model and a reasonably strong policy prior; calibrated uncertainty coefficient; control loop timing and actuator limits modeled; GPU or fast CPU with autodiff.
- Retrofitting existing model-based RL deployments to reduce latency and cost
- Sectors: software/ML Ops for RL, robotics integrators.
- What to deploy: swap MPPI/CEM with Dream-MPC at inference for TD-MPC2 or BMPC models; add uncertainty regularization and action reuse to existing planners.
- Workflow: load pre-trained checkpoints → run Dream-MPC at test time (no re-training) → A/B test on existing tasks (e.g., DMControl, Meta-World-like internal simulators).
- Dependencies/assumptions: compatible model architecture (encoder/dynamics/reward/value); stability checks on high-dimensional tasks; tuning step size and horizon for each plant.
- Vision-based closed-loop control with low compute
- Sectors: autonomous mobile robots, quadrupeds, manipulation with cameras.
- What to deploy: Dream-MPC with image encoders (as validated on image-based DMControl tasks).
- Workflow: camera stream → encoder → Dream-MPC latent planning → control outputs at 20–50 Hz.
- Dependencies/assumptions: latency-aware perception pipeline; robust encoder training; lighting/domain shift mitigation.
- High-DoF manipulator control with fewer samples
- Sectors: industrial automation, assembly, lab automation.
- What to deploy: Dream-MPC latent-space planner for 6–24 DoF arms as a plugin for standard arms (e.g., Franka, UR).
- Workflow: train control-centric world model → warm-start planning with policy → gradient-based refinement → apply first action.
- Dependencies/assumptions: accurate contact and friction modeling in the world model; safety envelope or guard policy for hard constraints.
- Risk-aware online planning via uncertainty regularization
- Sectors: safety-critical robotics, process automation, UAV operations.
- What to deploy: planning objective with value-ensemble-based uncertainty penalty to avoid OOD trajectories.
- Workflow: maintain Q-ensemble; compute mean × std uncertainty; penalize in MPC objective; log uncertainty for safety auditing.
- Dependencies/assumptions: ensemble calibration; uncertainty coefficient selection; fallback policy/controller for high-uncertainty states.
- Simulation-to-real transfer with conservative exploration
- Sectors: robotics (warehousing, inspection, agriculture).
- What to deploy: Dream-MPC with uncertainty penalty and action reuse to limit risky extrapolation at deployment.
- Workflow: train with domain randomization → deploy with Dream-MPC → monitor uncertainty → gradually expand operating envelope.
- Dependencies/assumptions: coverage in sim training data; accurate reward/cost shaping reflecting real objectives.
- Real-time embedded control where MPPI/CEM are too heavy
- Sectors: drones, mobile platforms, small manipulators.
- What to deploy: Dream-MPC with N≈5 candidates and I≈1–2 iterations (as in paper), giving ~10–20 ms per control step on desktop GPUs; edge acceleration as available.
- Workflow: fixed small candidate budget; action reuse across steps; compile-time graph optimization (TorchScript/JAX/XLA).
- Dependencies/assumptions: stable gradients through the model; bounded horizon; execution-time determinism.
- Academic benchmarking and teaching
- Sectors: academia, education.
- What to deploy: open-source Dream-MPC code; reproducible rliable-based reporting (IQM, optimality gap).
- Workflow: integrate Dream-MPC into course assignments on model-based RL; compare gradient-based vs sampling MPC; ablation studies (uncertainty, reuse).
- Dependencies/assumptions: access to the provided repo/datasets; GPU for rapid iteration.
- Policy-only systems with on-demand local refinement
- Sectors: robotics production lines, autonomous labs.
- What to deploy: a “policy-first, optimize-if-needed” runtime that calls Dream-MPC when predicted value is low or uncertainty high.
- Workflow: run policy; gatekeeper checks value/uncertainty; invoke Dream-MPC for K steps when necessary.
- Dependencies/assumptions: well-calibrated value and uncertainty; interruptible planner; smooth handover logic.
- Process control pilots with learned differentiable surrogates
- Sectors: energy (HVAC), manufacturing (CNC/feed rates), logistics (conveyor timing).
- What to deploy: Dream-MPC on top of learned differentiable plant models to achieve MPC-like control with fewer simulations than CEM/MPPI.
- Workflow: collect telemetry → train surrogate world model → deploy Dream-MPC → monitor constraints via penalties and uncertainty.
- Dependencies/assumptions: accurate surrogate fidelity in operating region; formal safety envelope; human-in-the-loop oversight.
Long-Term Applications
These use cases require further research, scaling, or engineering to reach robust deployment.
- On-road autonomy components with learned world models
- Sectors: automotive, robotics.
- Potential products: uncertainty-aware gradient-based local planners in latent space for short-horizon maneuvers (merging, obstacle avoidance).
- Dependencies/assumptions: highly reliable world models from multi-sensor input; formal safety cases; explicit constraint handling beyond penalties; certification.
- Industrial process MPC with learned dynamics at scale
- Sectors: chemicals, petroleum, semiconductor fabs.
- Potential products: Dream-MPC controllers with safety filters and constraint solvers; hybrid physics+learned models.
- Dependencies/assumptions: rigorous validation, stability guarantees, integration with DCS/PLC; runtime fail-safes; regulatory approval.
- Wearables, prosthetics, and exoskeletons with on-device planning
- Sectors: healthcare, assistive robotics.
- Potential products: battery-efficient Dream-MPC on embedded accelerators; personalized world models.
- Dependencies/assumptions: low-latency sensing; patient-specific data; robust out-of-distribution detection; clinical trials.
- Household generalist robots using multi-task world models
- Sectors: consumer robotics.
- Potential products: generalist latent world models with Dream-MPC for manipulation/navigation across many tasks; hierarchical planners.
- Dependencies/assumptions: multi-task training at scale; robust vision-language grounding; safe exploration in homes.
- Humanoid locomotion and whole-body manipulation
- Sectors: advanced robotics.
- Potential products: unified Dream-MPC controllers for balance, stepping, manipulation; on-board inference with accelerators.
- Dependencies/assumptions: contact-rich dynamics fidelity; torque/thermal limits in model; tight real-time scheduling; safety backups.
- Model-based RL compilers and hardware acceleration
- Sectors: semiconductors, ML tooling.
- Potential products: compilers that fuse world-model rollout and gradient steps; ASICs/NPUs optimized for world-model MPC.
- Dependencies/assumptions: stable operator sets for autodiff; standardized interfaces; sustained demand for on-device planning.
- Safety standards for uncertainty-penalized ML control
- Sectors: policy/regulation, industry consortia.
- Potential outputs: guidelines for value-ensemble calibration; minimum uncertainty penalties; test protocols and reporting.
- Dependencies/assumptions: consensus on metrics; regulatory engagement; public datasets/benchmarks.
- Digital twins with differentiable simulators for planning
- Sectors: manufacturing, logistics, energy grids.
- Potential products: differentiable twins paired with Dream-MPC for continuous re-optimization of operations.
- Dependencies/assumptions: high-fidelity differentiable models; data synchronization; privacy and IP constraints.
- Autonomous scientific labs with risk-aware planning
- Sectors: R&D automation (chemistry, biology, materials).
- Potential products: Dream-MPC for sequence design (pipetting, temperature control) guided by uncertainty to avoid risky protocols.
- Dependencies/assumptions: experiment simulators that are differentiable; strong priors from expert policies; safety interlocks.
- Financial execution and market making with differentiable simulators
- Sectors: finance.
- Potential products: Dream-MPC-like planners on learned market simulators for short-horizon execution.
- Dependencies/assumptions: credible differentiable simulators; strict risk controls; compliance and auditability.
Notes on Assumptions and Dependencies Across Use Cases
- Model quality matters: world model errors and value overestimation can degrade performance; ensemble-based uncertainty helps but needs calibration.
- Policy prior quality is pivotal: warm-starting from a strong policy is a key determinant of gradient-based MPC success, especially in high dimensions.
- Real-world constraints: penalty-based handling may be insufficient; safety layers, constraint solvers, or control barrier functions may be needed.
- Compute and latency: while Dream-MPC reduces evaluations vs MPPI/CEM, stable performance requires bounded horizons and tuned step sizes; embedded acceleration is beneficial.
- Data and coverage: success depends on training data covering the operational envelope; explicit OOD detection and conservative penalties help during deployment.
- Hyperparameters: the method is relatively robust to reuse and uncertainty coefficients, but initial deployment should include sensitivity checks.
- Monitoring and fallback: production systems should include online tracking of value/uncertainty, watchdogs for gradient anomalies, and safe fallback controllers.
Glossary
- Action reuse coefficient: A scalar parameter controlling how much of previously optimized actions are reused when initializing the next plan. "Action reuse coefficient "
- Amortization (of optimization): Reusing or spreading optimization effort across time steps to reduce per-step computation. "amortization of optimization iterations over time by reusing previously optimized actions."
- Bootstrapping (in RL): Using value estimates beyond the planning horizon to approximate long-term returns. "bootstrap return estimates beyond the horizon ."
- Compounding error problem: The accumulation of model prediction errors over multi-step rollouts that degrades planning or learning. "compounding error problem"
- Control-centric world model: A world model trained to directly support control objectives rather than reconstructing observations. "control-centric world model"
- Cross Entropy Method (CEM): A sampling-based, gradient-free trajectory optimization algorithm that iteratively refines a distribution over action sequences. "Cross Entropy Method (CEM)"
- Epistemic uncertainty: Uncertainty due to lack of knowledge about the model or environment, often estimated via model or value function ensembles. "balancing estimated returns and (epistemic) model uncertainty"
- Extrapolation errors: Errors that arise when the model is queried on state-action pairs outside the training distribution. "This can lead to extrapolation errors"
- Gradient ascent: An optimization method that adjusts variables in the direction of increasing an objective. "optimizes each trajectory by gradient ascent"
- Gradient-based MPC: Model Predictive Control that updates action sequences via gradient-based optimization through a differentiable model. "combines gradient-based MPC with a learned policy network and world model"
- Gradient-free optimization: Search or sampling-based optimization methods that do not require gradients. "gradient-free optimization methods"
- Imaginary rollouts: Model-based simulations of future trajectories used for planning without interacting with the real environment. "planning through imaginary rollouts with MPC"
- Imitation learning: Training a policy to mimic an expert (e.g., an MPC planner) from demonstration data. "uses imitation learning of the MPC planner"
- Interquartile median (IQM): A robust aggregate performance measure that summarizes the median of scores within the interquartile range. "interquartile median (IQM)"
- Joint-embedding prediction: A training objective that aligns or predicts in a shared embedding space to learn useful representations for control. "joint-embedding prediction"
- Latent dynamics model: A learned transition model that predicts next latent states given current latent state and action. "latent dynamics model "
- Latent imagination: Planning or optimizing in a latent space by “imagining” future trajectories using a learned model. "Gradient-Based Model Predictive Control with Latent Imagination"
- Latent space: A compact, learned representation space in which planning and predictions are performed. "latent space "
- Markov Decision Process (MDP): A formal framework for sequential decision-making characterized by states, actions, transitions, rewards, and discounting. "Markov Decision Process (MDP)"
- Model Predictive Control (MPC): A receding-horizon control approach that optimizes a sequence of actions over a finite horizon and applies the first action. "Model Predictive Control (MPC)"
- Model Predictive Path Integral (MPPI): A sampling-based MPC method that evaluates and weights trajectories using path integral formulations. "Model Predictive Path Integral (MPPI)"
- Monte Carlo Tree Search: A planning technique that builds a search tree by stochastic simulations to guide decision-making. "Monte Carlo Tree Search"
- Normalized-Score: A rescaled performance metric that maps raw scores to a common scale relative to random and target performance. "\text{Normalized-Score}(x) ="
- Offline RL: Reinforcement learning from a fixed dataset without additional environment interaction. "for offline RL and multi-task world models"
- Optimality gap: The difference between the achieved performance and the best-known or target performance. "Optimality gap"
- Percentile bootstrap with stratified sampling: A statistical procedure to compute confidence intervals by resampling data within strata. "the percentile bootstrap with stratified sampling"
- Planning horizon: The number of future steps over which MPC optimizes actions. "planning horizon "
- Policy prior: A learned policy used to initialize or guide the planner’s candidate action sequences. "The policy prior serves to guide the sampling-based MPPI trajectory optimizer"
- Population-based methods: Optimization techniques that operate on and evolve a population of candidate solutions. "population-based methods for planning"
- Proposal distribution: A distribution from which candidate action sequences are sampled to initialize optimization. "use a Gaussian as a proposal distribution"
- Q-function: An action-value function estimating expected return for state-action pairs, often used for bootstrapping and planning. "Q-function "
- Receding horizon: The MPC procedure of replanning at each step over a moving finite horizon and executing only the first action. "we optimize actions over a receding horizon"
- Replay buffer: A memory of past transitions used to train world models and value functions in model-based RL. "maintains a replay buffer "
- TD-learning: Temporal-Difference learning; a method for value estimation using bootstrapped targets from subsequent predictions. "TD-learning"
- Terminal value: The value estimate appended at the end of the planning horizon to approximate returns beyond it. "Predict terminal value "
- Uncertainty regularization: Penalizing high-uncertainty trajectories during planning to reduce overestimation and improve robustness. "uncertainty regularization"
- Value overestimation: A bias where predicted values are systematically higher than true returns, degrading decision quality. "TD-MPC2 suffers from value overestimation."
- Warm-start: Initializing optimization with a good starting solution to improve convergence and performance. "warm-start the optimization procedure"
- World model: A learned model of environment dynamics and rewards used to simulate future outcomes for planning. "learned world model"
Collections
Sign up for free to add this paper to one or more collections.

