- The paper presents a unified framework that combines MPPI control with a Dreamer module trained via reinforcement learning to enable continuous, real-time gait adaptation.
- The proposed method achieves up to a 36.48% reduction in energy consumption compared to fixed-gait policies by jointly optimizing control actions and gait parameters.
- The framework ensures smooth transitions and robust performance through infinite-horizon planning over continuous gait spaces, demonstrating its potential for practical quadruped deployment.
Real-Time Gait Adaptation for Quadrupeds using Model Predictive Control and Reinforcement Learning
Introduction and Motivation
Quadrupedal locomotion in robotics has traditionally relied on either model-based control (e.g., MPC) with fixed, pre-specified gait libraries or model-free RL approaches that tend to converge to a single dominant gait. Both paradigms exhibit limitations: MPC lacks adaptability to changing environments and task demands, while RL struggles to produce diverse, stable gaits and seamless transitions. The paper introduces a unified framework that leverages Model Predictive Path Integral (MPPI) control, guided by a Dreamer module trained via RL, to enable real-time, continuous optimization of both control actions and gait parameters. This approach aims to achieve adaptive, energy-efficient, and robust locomotion by integrating learned dynamics, reward, and value functions into the planning process.
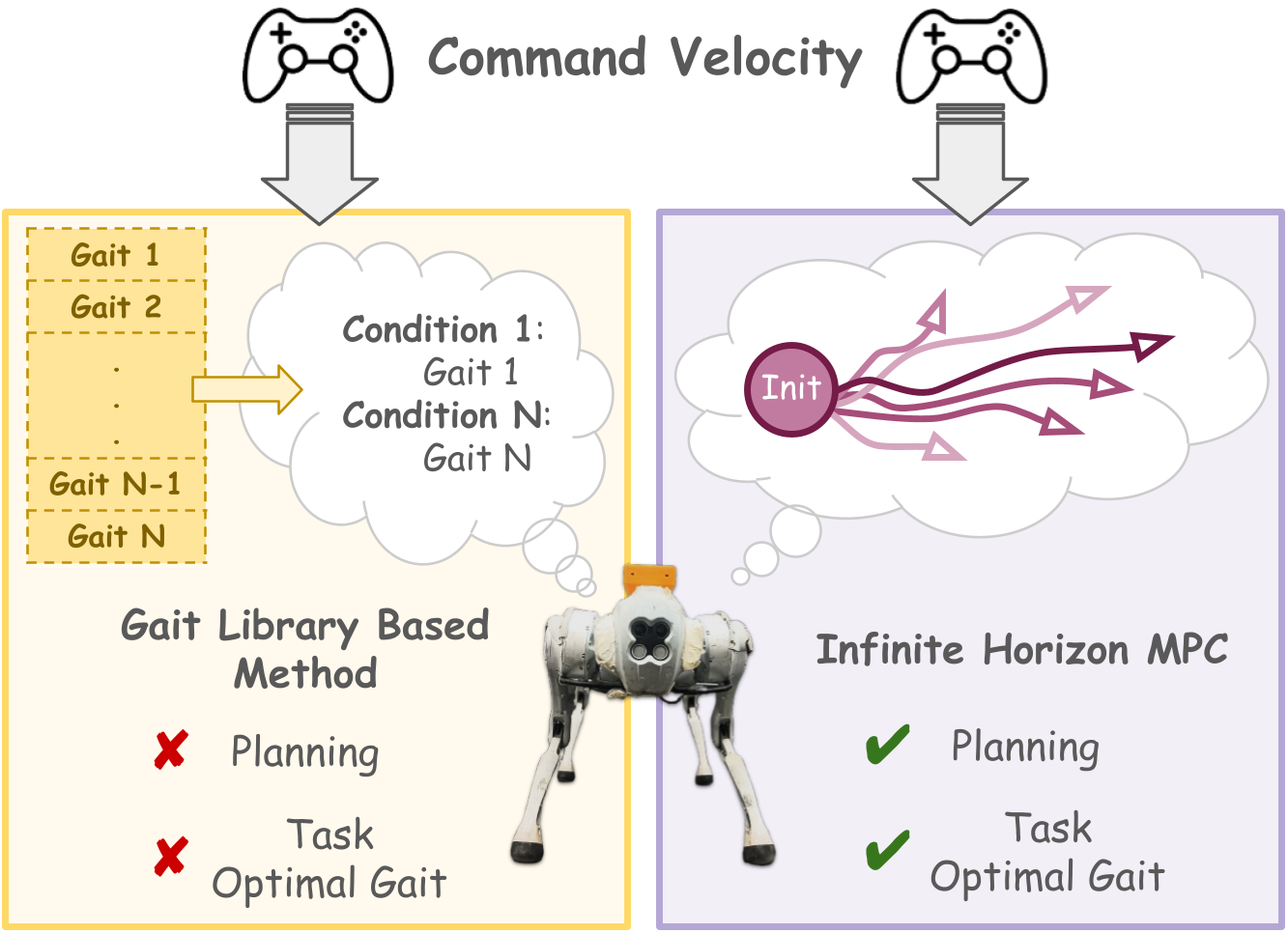
Figure 1: Conventional approaches (left) rely on discrete gait switching with predefined libraries. The proposed framework (right) performs joint optimization over actions and continuous gait parameters using learned dynamics and a reward-based planner.
Framework Architecture and Training Pipeline
The system models quadruped locomotion as an infinite-horizon discounted POMDP, with the Dreamer module learning latent dynamics, reward, and value functions from observation histories. The RL policy is trained using PPO, conditioned on gait parameters, and the Dreamer module is trained in parallel to provide all components required for deployment-time planning. The observation space includes joint positions, velocities, timing references, commanded gait, projected gravity, and previous actions. The action space consists of joint-angle perturbations applied to nominal joint angles, processed through an actuator network.
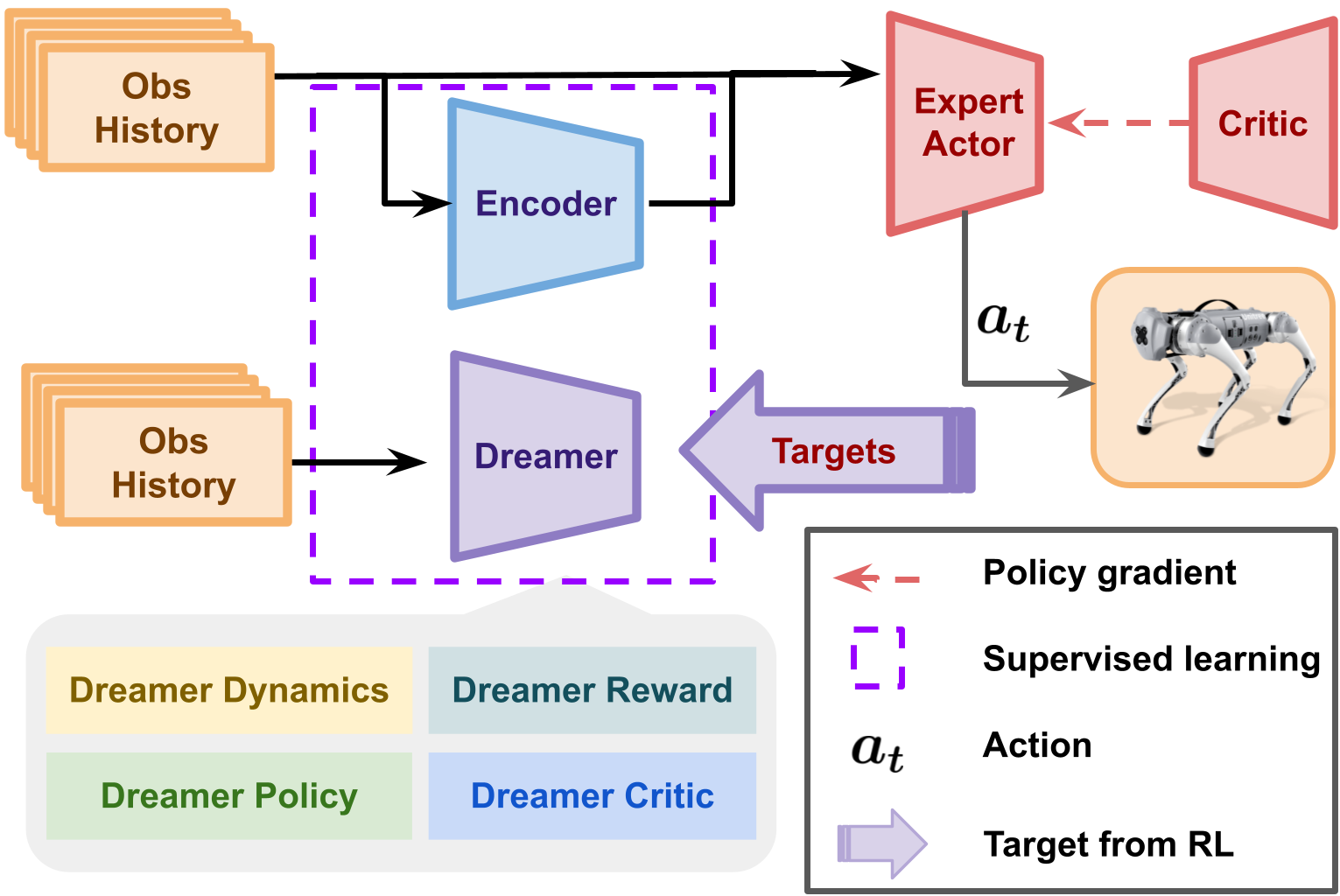
Figure 2: Overview of the training pipeline: the Dreamer module learns latent dynamics, reward, and value functions from observation histories, while the expert actor is trained using supervised signals from Dreamer outputs.
The reward structure during training combines velocity tracking, energy efficiency, angular velocity minimization, action continuity, and gait continuity, with additional penalties for actor divergence and abrupt gait changes during deployment. The Dreamer module provides a cloned policy for warm-starting MPPI, a learned dynamics model, a generalized reward model, and a value function for infinite-horizon planning.
Model Predictive Path Integral (MPPI) Planning
During deployment, the MPPI planner jointly optimizes control actions and gait parameters in real time. The optimization problem maximizes the expected cumulative reward, subject to the learned Dreamer dynamics. MPPI is chosen for its sampling-based nature, which allows it to operate with non-differentiable models and directly incorporate action and gait constraints.
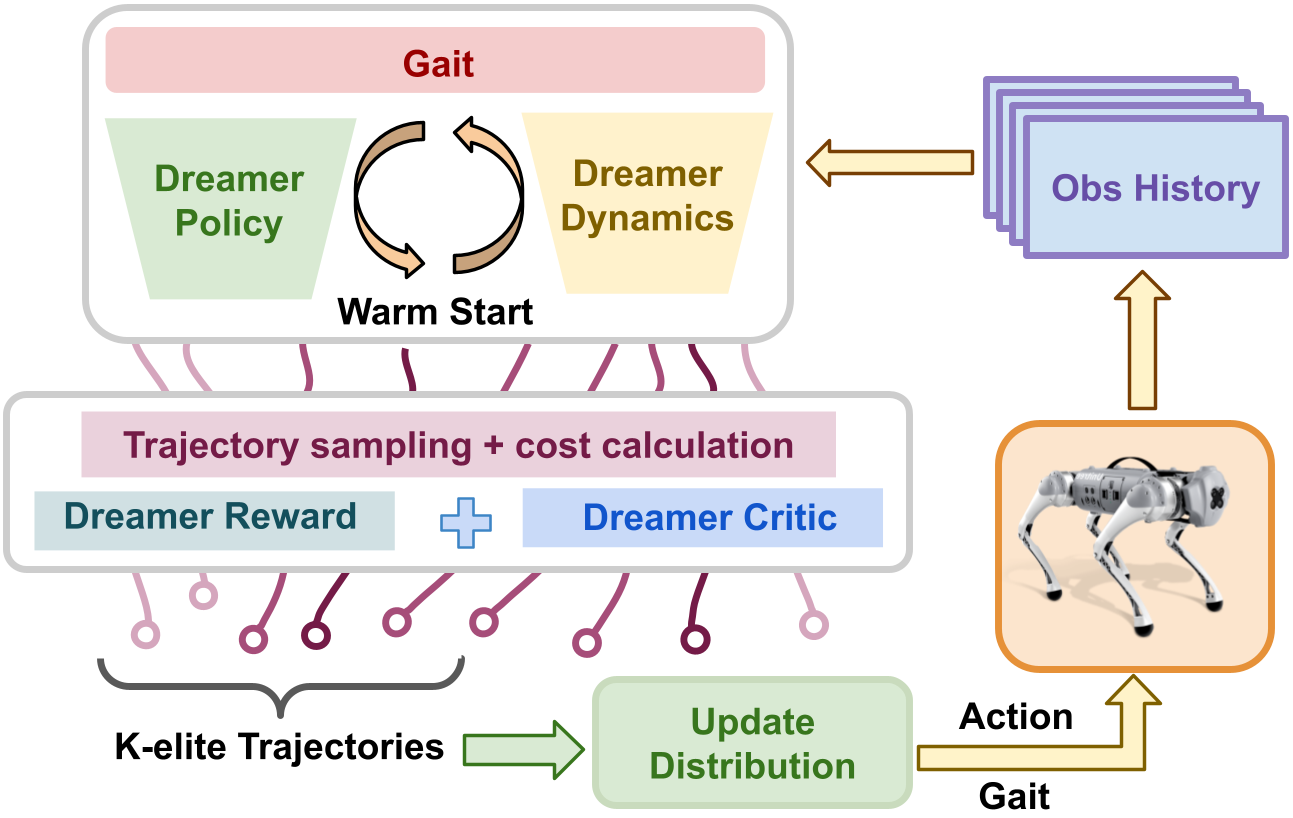
Figure 3: Pictorial representation of the MPPI algorithm: the warm start utilizes Dreamer policy and dynamics to generate initial trajectories to help MPPI.
At each timestep, trajectories are sampled from the Dreamer policy and dynamics model to initialize the MPPI distribution. Action and gait sequences are then sampled, and rollouts are generated through the Dreamer dynamics. Returns are computed using the Dreamer reward model with value bootstrapping, and elite trajectories are selected to update the sampling distribution. The first action and updated gait command are executed, enabling continuous adaptation.
Gait parameters are represented as a [3×1] vector encoding phase offsets between leg pairs, allowing for continuous modulation of gait structures. A wrap function enforces smooth and bounded variation.
Experimental Evaluation
Fixed-Gait Ablation
An ablation study on the Unitree Go1 in simulation demonstrates the limitations of fixed-gait policies. Four major gaits (trot, pace, bound, pronk) are evaluated across a range of commanded velocities. Results show that no single gait performs optimally across all speeds; for example, trotting maintains low velocity errors but constant CoT, while pronking becomes more energy-efficient at higher speeds.
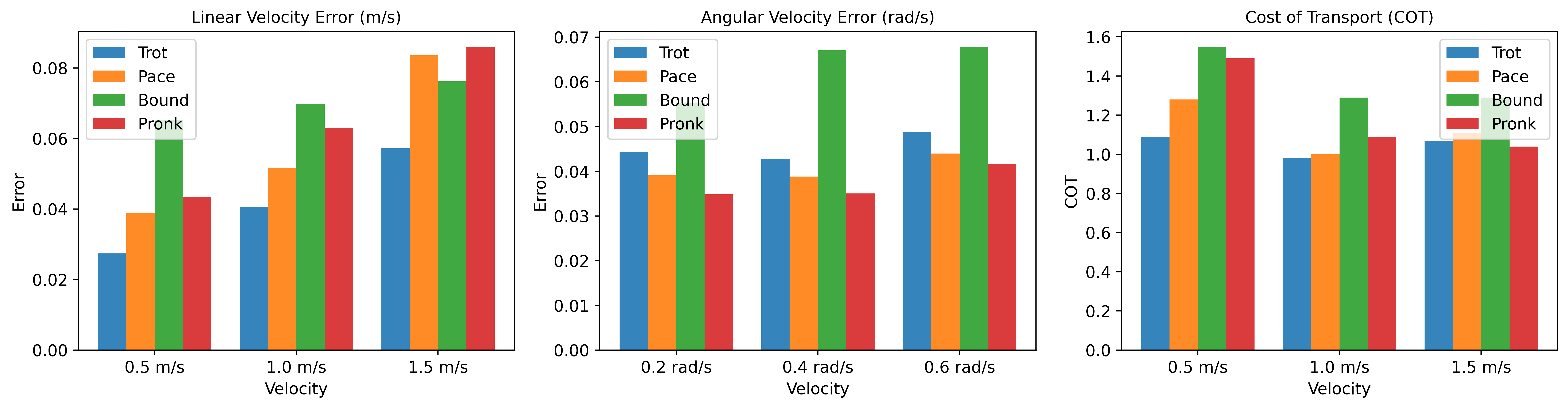
Figure 4: Performance comparison of fixed gaits across command velocities on flat terrain, illustrating the limitations of using a single gait policy and the need for adaptive gait selection.
Adaptive Gait Optimization
Under a continuously increasing velocity command, the proposed planner enables the robot to track the desired velocity with smooth acceleration and stable, periodic joint trajectories. Foot contact patterns reveal continuous, context-specific gait transitions, with no abrupt changes or degradation in stability.
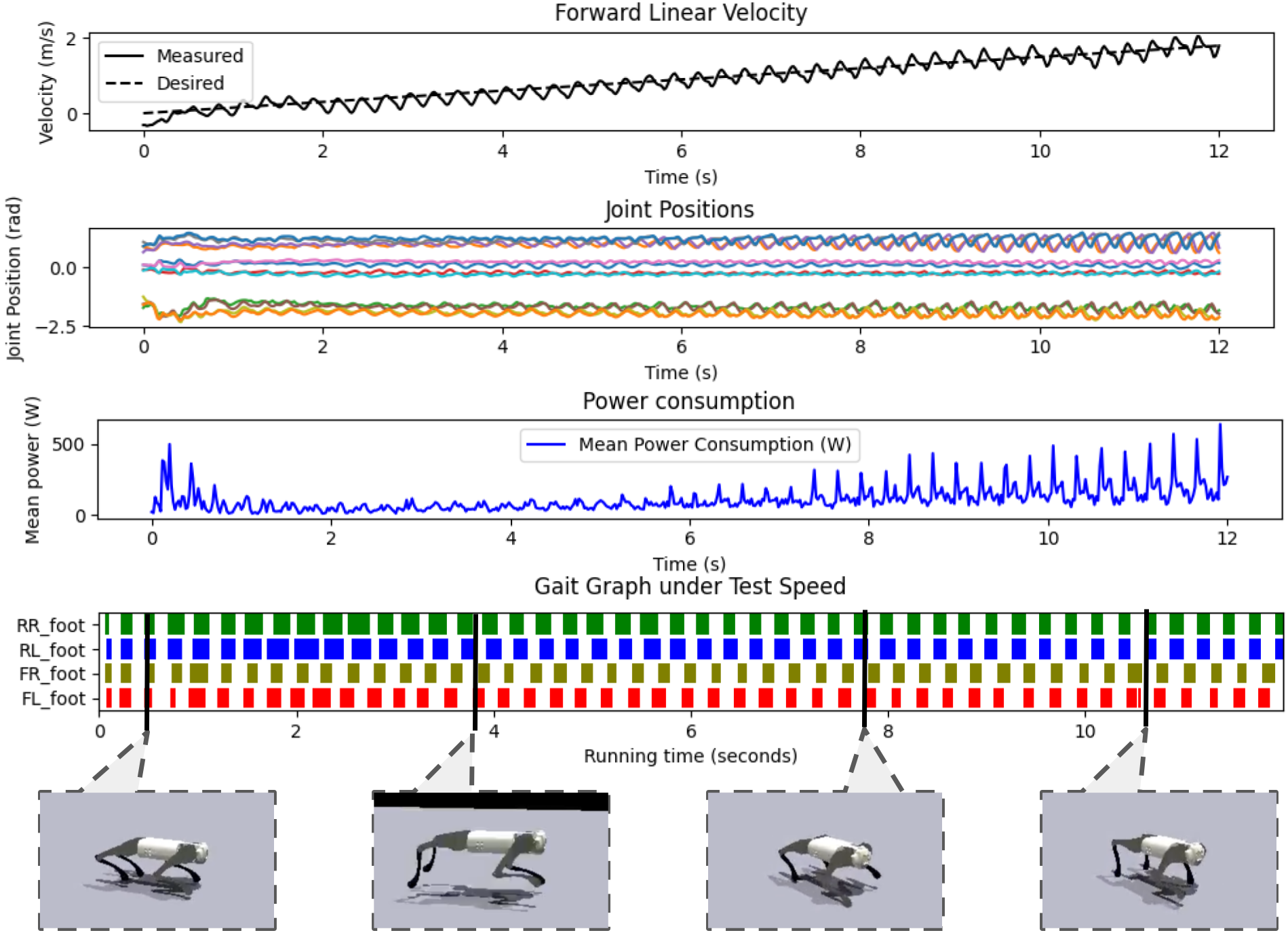
Figure 5: Evaluation of the proposed locomotion planner under a continuously increasing velocity command, showing effective velocity tracking, stable joint trajectories, and adaptive gait transitions.
Energy Efficiency
The framework achieves a consistent reduction in energy consumption, as measured by Cost of Transport (CoT), across all commanded velocities. Compared to fixed-gait RL baselines, the proposed method reduces CoT by up to 36.48%, with energy savings of 15–20% relative to the most efficient fixed gait at each speed. This demonstrates the inefficiency of single-gait policies and the advantage of dynamic gait adaptation.
Implementation Considerations
The system was trained on an NVIDIA A6000 GPU, requiring 5–6 hours for RL policy and Dreamer module training. Deployment was evaluated at 330 Hz control frequency on an RTX 3080 GPU, indicating feasibility for real-world hardware deployment with onboard GPU computation. The modular architecture supports integration with any RL algorithm capable of gait-conditioned policies and can be extended to multi-terrain locomotion and visual input for predictive planning.
Theoretical and Practical Implications
The framework advances the state of quadrupedal locomotion by enabling infinite-horizon planning over both actions and continuous gait parameters, guided by learned models. It demonstrates that joint optimization in a continuous gait space yields superior adaptability and energy efficiency compared to discrete gait libraries or single-gait RL policies. The use of MPPI with Dreamer models provides a scalable approach for real-time deployment, accommodating non-smooth dynamics and constraints.
Future work may focus on terrain-aware extensions, integration with structured models (e.g., Lagrangian Neural Networks), and further reduction of computational overhead for embedded deployment.
Conclusion
The proposed framework for real-time gait adaptation in quadrupeds combines MPPI control with a Dreamer module to jointly optimize actions and continuous gait parameters. Simulation results on the Unitree Go1 show accurate velocity tracking, smooth and robust gait transitions, and up to 40% reduction in energy consumption compared to fixed-gait baselines. The architecture is modular, extensible, and suitable for deployment on modern hardware, representing a significant step toward adaptive, efficient, and robust quadrupedal locomotion in dynamic environments.

