Model Predictive Control with Differentiable World Models for Offline Reinforcement Learning
Abstract: Offline Reinforcement Learning (RL) aims to learn optimal policies from fixed offline datasets, without further interactions with the environment. Such methods train an offline policy (or value function), and apply it at inference time without further refinement. We introduce an inference time adaptation framework inspired by model predictive control (MPC) that utilizes a pretrained policy along with a learned world model of state transitions and rewards. While existing world model and diffusion-planning methods use learned dynamics to generate imagined trajectories during training, or to sample candidate plans at inference time, they do not use inference-time information to optimize the policy parameters on the fly. In contrast, our design is a Differentiable World Model (DWM) pipeline that enables endto-end gradient computation through imagined rollouts for policy optimization at inference time based on MPC. We evaluate our algorithm on D4RL continuous-control benchmarks (MuJoCo locomotion tasks and AntMaze), and show that exploiting inference-time information to optimize the policy parameters yields consistent gains over strong offline RL baselines.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Plain-language explanation of “Model Predictive Control with Differentiable World Models for Offline Reinforcement Learning”
What is this paper about? (Brief overview)
This paper is about teaching a computer to make good decisions using only a big collection of past experiences, without letting it practice in the real world. The authors build a “mental simulator” of the world (a world model) and combine it with a planning strategy that updates the decision-maker on the fly, right when it’s about to act. This makes the agent smarter at test time, even though it never gathers new training data.
Think of it like learning to drive by watching lots of dashcam videos (offline learning), then using a fast, accurate driving simulator in your head to look a few seconds ahead and adjust your steering before you actually turn the wheel.
What questions are the researchers trying to answer?
The paper focuses on two simple questions:
- Can we make an offline-trained agent perform better by letting it spend extra computation at test time to adapt itself to the exact situation it’s currently in?
- If we build a “differentiable” world model (a simulator we can calculate gradients through), can we use it to update the agent’s decision-making right before it acts?
How do they do it? (Methods in everyday language)
The method combines three ideas you can picture in daily life:
- A world model: Like a video game physics engine that predicts “if I press this button now, what happens next?” Here, it predicts the next state (what the world looks like) and the reward (how good that move was).
- Planning a few steps ahead: Like looking a few moves into the future in chess or a few seconds ahead on the road.
- Fine-tuning on the fly: Right before taking an action, slightly adjust your strategy based on what the simulator predicts.
In more detail (lightly listed to clarify the steps):
- They first train offline (using only past data):
- A policy: this is the agent’s rule for choosing actions (like a playbook).
- A critic (value function): a tool for scoring how good a situation is.
- A reward predictor: estimates the immediate reward for any state and action.
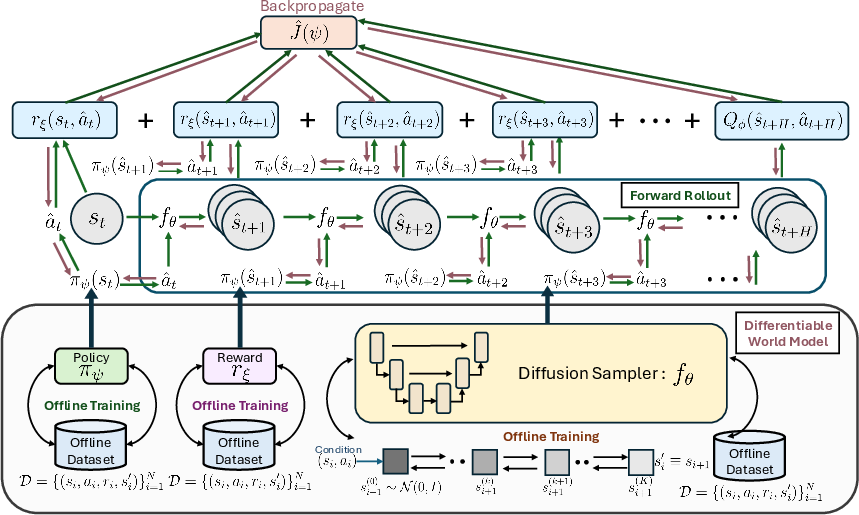
- A dynamics model: predicts what the next state will be if you take an action in a state. They use a “diffusion model” (a type of generative model popular in making images) customized to predict the next state. “Differentiable” means they can compute how small changes in the input would affect the output—this is key for tuning the policy.
- At test time (when the agent is deployed):
- Starting from the current state, they roll out several short, imagined futures using the world model and the current policy.
- They score each imagined future by adding up the predicted rewards, plus a “terminal bonus” from the critic at the end of the short horizon.
- Then they use gradients (think of it as a mathematical nudge in the best direction) to slightly improve the policy based on these imagined futures.
- Finally, they take just the first action in the real environment and repeat the process at the next step. This is called Model Predictive Control (MPC): plan a short distance, act, re-plan, and so on.
Analogy: It’s like walking across a room in the dark:
- You imagine a few steps ahead based on what you know (world model).
- You adjust your direction a little to avoid bumping into things (policy update).
- You take one careful step, then imagine again.
What did they find, and why is it important?
- The agent performed better when it used this “imagine-and-adjust” process at test time than when it simply used the frozen policy learned offline.
- They tested on standard benchmarks (D4RL) that include simulated robots (like HalfCheetah, Hopper, Walker2d) and navigation tasks (AntMaze).
- The method consistently improved scores compared to strong offline learning baselines. In many cases, the improvements were clear, and on a large majority of tasks the adapted policy beat the original pre-trained policy.
- This is important because it shows that extra thinking at test time—using a learned simulator—can help an agent act better without needing risky real-world practice. It’s a smart way to be adaptive while still staying “offline.”
Why does this work?
- Predicting long-term value directly is hard, especially from offline data. But predicting “what happens next” (the next state and immediate reward) is often easier and more reliable.
- By planning over a short horizon and updating the policy based on those predictions, the agent can adapt to the exact state it’s facing.
- Making the world model differentiable lets the agent use gradients to improve its policy quickly at test time, not just during training.
What could this mean in the real world? (Implications)
- Safer, more reliable deployment: In places where trial-and-error is expensive or dangerous (like healthcare, self-driving, and real robots), this approach offers a way to improve performance without more real-world practice.
- Better use of existing data: Many industries have big logs of past behavior. This method turns those logs into both a world model and a smarter, adaptable policy.
- A general recipe: It suggests a broader principle—spending extra computation at test time to adapt to the current situation can boost performance in decision-making systems.
In short, the paper shows a practical and effective way to combine offline learning, a learned simulator, and quick on-the-fly adjustments so that agents can act more intelligently when it counts.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of unresolved issues that future work could address.
Theory and guarantees
- Absence of performance guarantees for inference-time policy optimization: no bounds on regret, improvement, or degradation relative to the pretrained policy after E gradient steps.
- No convergence or stability analysis of the inner-loop updates under model error; conditions on step size α, horizon H, particles M, and policy class that ensure monotone improvement are unknown.
- Lack of robustness guarantees to world-model misspecification; no analysis of worst-case performance under dynamics/reward prediction error.
- No safety guarantees or constraints during inference-time adaptation; risk of out-of-distribution (OOD) actions induced by on-the-fly policy updates is unquantified.
World-modeling and uncertainty
- World model is one-step conditional diffusion without uncertainty quantification; how to incorporate epistemic uncertainty (e.g., ensembles, Bayesian diffusion) into the MPC objective is unexplored.
- No mechanism to penalize or detect OOD imagined rollouts; integrating likelihood-based constraints or behavior priors to keep simulated states within the data manifold remains open.
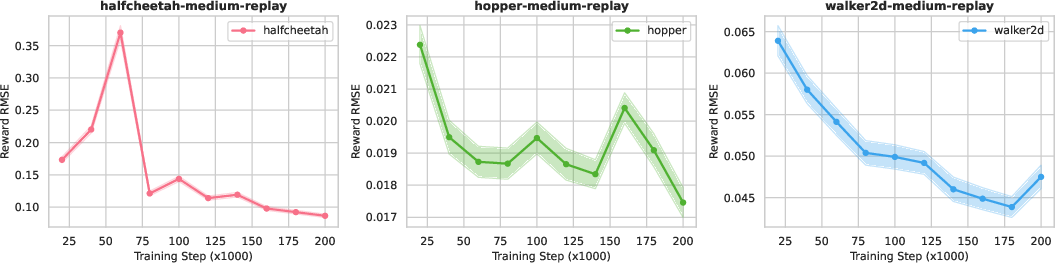
- Reward is learned separately via supervised regression, even when the true reward is known (as in D4RL); the effect of reward model bias on control performance and gradients is not analyzed.
- No study of multi-step (trajectory-level) generative models vs. one-step diffusion for improved long-horizon accuracy and stability of gradients.
- Sensitivity of the method to diffusion hyperparameters (noise schedule, reverse variance, number of denoising steps K) and their impact on planning quality is unreported.
- No ablations comparing diffusion to alternative differentiable samplers (flows, latent dynamics, autoregressive models, ODE/SDE-based generative models).
Algorithmic design and optimization
- No trust region, KL penalty, or behavior-regularization term applied during inference-time updates; the extent to which the updated policy can drift from the dataset policy is unbounded.
- Unclear policy stochasticity assumptions; the method appears to optimize a deterministic policy, leaving open how to handle stochastic policies and entropy regularization in the inner loop.
- Gradient through H-step rollouts and K-step diffusion unrolls may suffer from vanishing/exploding gradients; lack of diagnostics on gradient norms and mitigation strategies (e.g., clipping, normalization, TD(λ)-style returns).
- No variance-reduction techniques for Monte Carlo over diffusion noise; the effect of M (number of particles) and whether to resample noise across E inner steps on gradient bias/variance is unstudied.
- Terminal critic Qφ is trained offline under a different policy; the mismatch between terminal values and the adapted policy is unaddressed (e.g., reweighting, on-the-fly terminal value correction).
- Lack of principled horizon selection; trade-offs between H (rollout length) and reliance on Qφ are not characterized and no guidelines are provided.
- No mechanism to prevent model exploitation during inner-loop optimization; regularizers that penalize low data-likelihood states or high model uncertainty are absent.
- Persistence of online parameter updates across timesteps/episodes may cause policy drift or catastrophic forgetting; whether to reset to the pretrained policy each episode or maintain a moving anchor is not explored.
- Memory/computation cost of backpropagating through H×K steps is not analyzed; checkpointing, truncated backprop, or architectural changes for efficiency are not investigated.
Evaluation scope and methodology
- Benchmarks are limited to low-dimensional state-based D4RL tasks; applicability to high-dimensional observations (images), contact-rich dynamics, or partial observability is untested.
- No real-time latency analysis; feasibility of running E inner steps with M particles and horizon H on embedded/robotic hardware is unknown.
- Limited failure-mode analysis: on tasks where no gain is observed (e.g., hopper-random, walker2d-random), the causal factors (data coverage, model error, reward sparsity) are not dissected.
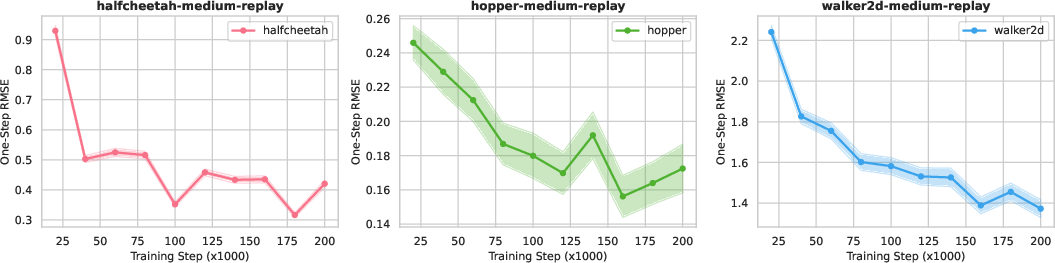
- No correlation study between model RMSE (dynamics/reward) and control performance; thresholds of model accuracy required for beneficial inference-time updates are unclear.
- Hyperparameter sensitivity (α, H, M, E) and robustness across seeds/datasets are not systematically reported.
- Baseline comparability: some baselines are taken from prior papers with potentially different training budgets and evaluation protocols; fairness of comparisons is not audited.
- AntMaze results rely on learned reward; impact of sparse/terminal rewards and learned surrogate errors on planning quality is not analyzed.
- Absence of ablations for each component (reward model, terminal critic, diffusion vs. Gaussian dynamics, removal/addition of regularizers) to isolate sources of improvement.
Extensions and practical concerns
- Safety-constrained or risk-sensitive variants (e.g., CVaR, chance constraints) for inference-time adaptation with world-model uncertainty are not considered.
- Combining uncertainty-aware planning (e.g., robust MPC or pessimism) with differentiable rollouts remains an open design direction.
- Joint or periodic adaptation of the terminal critic at inference time (e.g., fitted OPE or value correction) is unexplored.
- Transfer and generalization: how well inference-time adaptation helps under dataset shift to new initial states/goals or across tasks is not evaluated.
- Integration with search-based planning (e.g., CEM) or guided sampling to warm-start gradients and reduce compute is untested.
Practical Applications
Overview
The paper introduces an inference-time adaptation method for offline reinforcement learning (RL) that combines a pre-trained policy, a differentiable world model of dynamics and rewards (implemented via conditional diffusion models), and a terminal critic to perform receding-horizon, gradient-based updates at deployment. The key capability is policy optimization at inference time through backpropagation over “imagined” rollouts under a differentiable generative dynamics model—without additional online exploration—yielding consistent improvements over strong offline RL baselines on D4RL benchmarks.
Below are practical, real-world applications that leverage these findings and methods. Each entry includes sector alignment, potential tools/products/workflows, and feasibility assumptions/dependencies.
Immediate Applications
These can be piloted or deployed now where sufficient offline logs exist, latency budgets allow limited extra computation at decision time, and differentiable world models are accurate enough locally.
- Adaptive process control with logs-driven receding-horizon updates (Sector: Industrial automation/energy)
- Use case: Improve set-point tracking and constraint satisfaction in building HVAC, chemical plants, and microgrid DER control by refining a pre-trained offline RL policy in situ using a differentiable world model learned from historian data.
- Tools/workflows: Train conditional diffusion dynamics and reward models from SCADA/BMS logs; wrap the incumbent MPC or RL controller with an “inference-time optimizer” that performs H-step imagined rollouts and E gradient steps before issuing the first action each control cycle.
- Assumptions/dependencies: Local model accuracy for short horizons; adequate latency headroom (tens–hundreds of ms); safety monitors/guardrails for constraint enforcement; representative logs across operating regimes; terminal critic calibration.
- Warehouse and factory robotics: context-aware policy refinement at deployment (Sector: Robotics)
- Use case: Refine pick-and-place or AMR navigation policies per aisle/task using offline logs (simulator and past runs), improving robustness to load configurations and minor layout changes.
- Tools/workflows: ROS/MoveIt integration; edge GPU running differentiable dynamics (e.g., learned kinematics/dynamics + contact surrogates); short-horizon MPC-like backprop updates; fallback to base policy under compute or model-uncertainty constraints.
- Assumptions/dependencies: Differentiable approximations to contact and actuation limits; reliable short-horizon predictions; strict latency budgets (tens of ms); uncertainty-aware gating.
- Session-level adaptation in recommender systems and ads (Sector: Software/Internet advertising)
- Use case: Per-session policy refinement using imagined rollouts of user-response models to optimize multi-step objectives (e.g., dwell time, session return, conversion).
- Tools/workflows: Train conditional diffusion/world models of user response from interaction logs; deploy an inference-time optimizer for the serving policy that runs a few gradient steps within per-request latency budgets; integrate with existing bandit constraints and safety/business rules.
- Assumptions/dependencies: Calibrated reward proxies; latency ceilings (~10–100 ms); bias control (counterfactual confounding in logs); guardrails for user harm and fairness.
- Building energy management and demand response (Sector: Energy/buildings)
- Use case: Daily adaptation to weather and occupancy by refining a pre-trained policy using a differentiable dynamics model learned from historical telemetry and prior seasons.
- Tools/workflows: World-model training pipeline from BMS logs; inference-time adaptation embedded in the BAS controller; risk-sensitive terminal value to limit discomfort/overruns.
- Assumptions/dependencies: Adequate coverage of seasonal patterns; robust reward modeling of comfort/cost; compute capacity on-site; validation in digital twin before deployment.
- Low-level control tuning for advanced driver-assistance systems in restricted settings (Sector: Automotive)
- Use case: Track-specific or route-specific adaptation for lane-keeping/ACC in test tracks or geo-fenced ODDs using offline fleet logs and simulator data.
- Tools/workflows: Differentiable surrogate dynamics (vehicle + lane geometry); on-ECU or edge module that performs limited gradient-based updates per scenario; safety envelope and monitor.
- Assumptions/dependencies: Strict real-time constraints; regulatorily acceptable deployment envelope; accurate short-horizon dynamics; validation via HIL/SiL.
- Market execution and microstructure-aware decision support in backtesting/paper trading (Sector: Finance)
- Use case: Inference-time refinement of execution policies per regime in a backtesting or paper-trading environment to improve fill quality and slippage under a learned dynamics model of short-term price/queue evolution.
- Tools/workflows: Diffusion world models trained on order book data; receding-horizon updates during simulation; integration with existing backtest engines.
- Assumptions/dependencies: Deployment to live trading requires additional controls and compliance; model misspecification risk; latency considerations for HFT contexts.
- Adaptive tutoring sequences in learning platforms (Sector: Education)
- Use case: Per-learner session adaptation by refining the teaching policy using a learned model of student response dynamics to maximize mastery/engagement over short horizons.
- Tools/workflows: Offline RL pre-training from historic clickstreams and assessments; inference-time optimizer running in the recommendation pipeline; constraints from curriculum policies.
- Assumptions/dependencies: Log confounding and reward alignment; privacy-preserving modeling; tight latency budgets.
- Cluster/job scheduling and autoscaling under shifting workloads (Sector: Cloud/DevOps)
- Use case: On-the-fly refinement of scheduling/autoscaling decisions per workload burst using a dynamics model learned from cluster telemetry.
- Tools/workflows: Integrate with Kubernetes/Slurm controllers; differentiable world model of queueing and scaling delays; MPC-like gradient updates before dispatch decisions.
- Assumptions/dependencies: Latency tolerance for scheduler decisions; model fidelity for short horizons; guardrails for SLO violations and fairness.
- Game AI that adapts to player behavior within a match (Sector: Gaming)
- Use case: NPC controllers refine tactics per player style using a world model trained on prior games, improving challenge and engagement.
- Tools/workflows: Run-time gradient updates with short imagined rollouts; on-device compute budget management; content moderation constraints.
- Assumptions/dependencies: Short-horizon model sufficiency; predictable latency; reward alignment to UX metrics.
Long-Term Applications
These require further research, scaling, safety assurances, or domain-specific validation and regulation before broad deployment.
- Patient-specific treatment planning and clinical decision support (Sector: Healthcare)
- Use case: Inference-time adaptation of treatment sequencing (e.g., dosing schedules, personalized pathways) from EHR-derived world models to optimize multi-step outcomes.
- Tools/products: Validated, uncertainty-aware generative dynamics models; integration into CDSS with interpretability; prospective trials; regulatory clearance (e.g., FDA).
- Dependencies: Causal modeling to address confounding; strict safety constraints; robust reward definitions; privacy and security compliance.
- End-to-end or mid-level autonomous driving with online refinement (Sector: Automotive)
- Use case: Use differentiable world models (sensorimotor or mid-level) to refine policies per scene in real time, complementing or replacing heuristic MPC modules.
- Tools/products: Real-time differentiable perception-to-motion models; certifiable safety envelopes; hardware acceleration for gradient-based planning; verification/monitoring.
- Dependencies: Hard real-time constraints; distributional robustness; rigorous verification; multi-agent modeling and intent prediction.
- General-purpose household and service robots (Sector: Robotics)
- Use case: On-device, task- and scene-specific adaptation for manipulation and navigation in unstructured environments using differentiable world models with partial observability.
- Tools/products: Differentiable physics/graphics simulators; visuomotor diffusion dynamics; uncertainty-aware MPC; safety and human-robot interaction standards.
- Dependencies: Scalable training data; POMDP handling; risk-sensitive objectives; compute/power limits.
- Smart grid and large-scale energy system control (Sector: Energy)
- Use case: Distributed, risk-aware MPC with differentiable world models for grid balancing, voltage control, and DER orchestration with per-interval adaptation.
- Tools/products: Digital twins with differentiable surrogates; constraint-aware gradient planning; operator-facing control UIs; market/regulatory integration.
- Dependencies: System identification fidelity; strict reliability constraints; cyber-physical security; regulatory approvals.
- Multi-agent traffic, logistics, and operations (Sector: Transportation/logistics)
- Use case: City-scale traffic signal control, fleet routing, and hub operations with inference-time refinement under learned multi-agent world models.
- Tools/products: Scalable, differentiable multi-agent dynamics; decentralized MPC with gradient messages; coordination protocols.
- Dependencies: Scalability, stability, and fairness; robust generalization to rare events; data-sharing and privacy frameworks.
- Ads marketplaces and real-time bidding with guardrails (Sector: Advertising/Martech)
- Use case: Per-impression or per-bidder inference-time adaptation to shifting auction dynamics with uncertainty-aware world models and strict constraints.
- Tools/products: Ultra-low-latency optimizers; compliance and fairness filters; market-simulation sandboxes for validation.
- Dependencies: Sub-10 ms latency; auction-policy compliance; bias/feedback-loop mitigation; robust off-policy evaluation.
- LLM/agent planning with differentiable environment surrogates (Sector: Software/AI)
- Use case: Augmenting tool-using agents with learned differentiable surrogates of external tools/APIs to perform gradient-guided plan refinement at inference time.
- Tools/products: Differentiable emulators of API effects; hybrid search-gradient planning loops; MLOps for world-model versioning.
- Dependencies: Faithfulness of surrogates; safe fallback to exact tools; alignment of surrogate reward and task metrics.
- Tooling ecosystem and standards
- Use case: Commercial “inference-time optimizer” SDKs for offline RL; model registries for dynamics/reward/critic components; debuggers/visualizers for imagined rollouts; compliance/audit trails for inference-time updates.
- Tools/products: PyTorch/JAX libraries for differentiable world-model MPC; compilers for efficient backprop through samplers; uncertainty quantification and safety layers; governance dashboards.
- Dependencies: Interop standards; cost-aware scheduling; reproducibility and auditability.
Cross-Cutting Assumptions and Dependencies
Across applications, feasibility depends on several technical and operational factors:
- Data coverage and quality: Offline datasets must cover relevant state–action regions; otherwise, the learned world model and reward predictor can be systematically biased.
- World model fidelity and uncertainty: Short-horizon accuracy and calibrated uncertainty are critical; incorporating pessimism/regularization or uncertainty penalties can mitigate exploitation of model errors.
- Latency and compute budgets: The number of particles M, horizon H, and inner steps E must fit real-time constraints; hardware acceleration and model compression may be required.
- Safety and constraints: Risk-aware objectives, terminal critics, and constraint-handling (e.g., shields, invariant sets) are necessary in safety-critical domains.
- Distribution shift and non-stationarity: Periodic retraining and drift detection are needed; inference-time adaptation helps locally but does not replace robust retraining.
- Reward alignment and measurement: Reward models must accurately reflect business or safety objectives; proxies should be validated and continuously monitored.
- Governance and compliance: Domains like healthcare, finance, and automotive require regulatory approvals, audit trails for inference-time adaptations, and human oversight.
By pairing pre-trained offline RL policies with differentiable world models and MPC-style inference-time optimization, organizations can exploit additional compute at deployment to realize performance gains while adhering to the constraints of offline learning—making this a practical step toward safer and more adaptive decision-making systems.
Glossary
- Absorbing state: A terminal state that, once entered, the process remains in with no further transitions or rewards. "transitions to an absorbing state"
- Action-value function: Also called Q-function; expected return from a state–action pair under a policy. "optimal action-value function"
- AntMaze: A D4RL benchmark suite of ant robot navigation mazes used for offline RL evaluation. "AntMaze environments"
- Behavior cloning regularizer: A penalty that encourages the learned policy to stay close to dataset actions. "behavior cloning regularizer"
- Behavior policy: The (unknown) policy that generated the offline dataset. "behavior policy"
- Behavior-Regularized Actor Critic (BRAC): An offline RL approach that constrains the learned policy to remain near the behavior policy. "Behavior Regularized Actor Critic (BRAC)"
- Behavior prior: A prior over actions derived from behavior data used to constrain planning. "behavior prior"
- Bellman error: The squared difference enforcing consistency with the Bellman equation in TD learning. "minimizing a Bellman error"
- Chain rule (recursive): Applying the chain rule iteratively through time and model components to compute gradients. "via a recursive chain rule"
- Conservative Q Learning (CQL): An offline RL method that penalizes overestimated Q-values on out-of-distribution actions. "Conservative Q Learning (CQL)"
- D4RL: A standard suite of offline RL datasets and evaluation protocols. "D4RL continuous-control benchmarks"
- Decision Diffuser: A diffusion-based policy that generates actions or trajectories by iterative denoising. "Decision Diffuser"
- Decision Transformer (DT): A model that casts offline RL as sequence modeling conditioned on desired return. "Decision Transformer"
- Denoising loss (simplified): The training objective for diffusion models that predicts the injected noise. "The simplified denoising loss is"
- DiffGenWM (differentiable generative world model): A model that can sample next states and provide gradients with respect to conditioning inputs. "differentiable generative world model (DiffGenWM)"
- Diffusion probabilistic models: Generative models that learn data distributions by reversing a noise-adding diffusion process. "Diffusion probabilistic models"
- Distribution shift: Mismatch between the learned policy’s state–action distribution and the dataset distribution. "address this distribution shift"
- Flow Q learning: A flow-based generative-policy method for reinforcement learning. "Flow Q learning"
- Flow-based policies: Generative models using invertible flows to produce actions or trajectories. "flow-based policies"
- Forward diffusion (noising) process: The process that incrementally adds noise to data in diffusion models. "forward diffusion (noising) process"
- Gym-MuJoCo: A collection of continuous-control tasks based on the MuJoCo physics simulator. "Gym-MuJoCo tasks"
- Jacobian recursion: A recurrence relation for derivatives used to propagate sensitivities through rollouts. "Jacobian recursion"
- Markov decision process (MDP): A mathematical framework for sequential decision making with Markovian dynamics and rewards. "Markov decision process (MDP)"
- Model Predictive Control (MPC): A control paradigm that optimizes action sequences over a rolling horizon using a dynamics model. "Model Predictive Control (MPC)"
- Model uncertainty: Uncertainty in predictions of a learned dynamics model used to penalize risky plans. "model uncertainty"
- Monte Carlo estimator: A sample-based approximation of an expectation over randomness (e.g., diffusion noise). "The Monte Carlo estimator is"
- Occupancy measure: The distribution over state–action pairs induced by a policy along trajectories. "occupancy measure "
- Offline Reinforcement Learning (RL): Learning policies from a fixed dataset without further environment interaction. "Offline Reinforcement Learning (RL)"
- Pessimistic surrogate MDP: A conservative model that avoids unreliable regions by penalizing or truncating transitions. "pessimistic surrogate MDP"
- Policy Jacobians: Derivatives of the policy outputs with respect to states and parameters, used in gradient propagation. "policy Jacobians"
- Receding-horizon: An MPC strategy that repeatedly optimizes over a short horizon and executes only the first action. "receding-horizon model predictive control (MPC)"
- ReBRAC: A practical, minimalist implementation of behavior-regularized actor–critic for strong offline RL performance. "ReBRAC"
- Reparameterized sampling procedure: Sampling by transforming base noise through a deterministic function of inputs and noise. "reparameterized sampling procedure"
- Reward predictor: A learned function that estimates immediate reward for state–action pairs. "reward predictor"
- Reverse (denoising) process: The learned generative process in diffusion models that removes noise step by step. "The reverse (denoising) process"
- Random Network Distillation (RND): A technique that measures novelty via prediction error from a fixed random target network. "random-network-distillation-based penalties"
- Return conditioned sequence modeling: Predicting actions conditioned on a target return within a sequence-modeling framework. "return conditioned sequence modeling"
- Return-conditioning: Guiding generative models or planners by conditioning on desired return values. "via return-conditioning"
- TD3+BC: An offline RL baseline combining TD3 with behavior cloning regularization. "TD3+BC"
- Terminal critic: A Q-function used to provide terminal value at the end of a finite-horizon imagined rollout. "terminal critic "
- Temporal-difference learning (TD): A family of methods that bootstrap value estimates using one-step predictions. "Temporal-difference learning."
- Trajectory Transformer (TT): A sequence model that plans by decoding high-reward trajectories. "Trajectory Transformer"
- Variance schedule: The sequence of noise levels governing the forward and reverse steps in diffusion models. "variance schedule"
- World model: A learned model of environment dynamics (and sometimes rewards) used for planning or policy optimization. "world model of state transitions and rewards"
Collections
Sign up for free to add this paper to one or more collections.

