- The paper demonstrates that RLHF fine-tunes LLMs for user alignment, achieving higher human preference even with fewer parameters.
- The methodology uses a three-step process: collecting demonstrations, ranking outputs, and applying PPO-based reinforcement learning.
- Results show marked improvements in truthfulness, reduced toxicity, and maintained NLP performance without sacrificing efficiency.
Training LLMs to Follow Instructions with Human Feedback
Introduction
This paper addresses the alignment issues faced by LLMs like GPT-3 with their users' intentions. Despite being trained on vast web data, these models often exhibit problematic behaviors such as generating untruthful, toxic, or tangential outputs. The discrepancy arises because the pretext task—predicting the next token on internet-derived texts—differs greatly from producing user-aligned responses focused on helpfulness, honesty, and harmlessness. This study introduces InstructGPT, a model fine-tuned using human feedback to better align LLM outputs with human intent across a variety of tasks.
Methodology
The fine-tuning process is a three-step approach leveraging reinforcement learning from human feedback (RLHF). Initially, a set of demonstrations is compiled whereby labelers showcase desired model behaviors. Following this, human rankings of various model outputs reinforce the supervised learning model. Finally, reinforcement learning fine-tunes the model against these rankings using the Proximal Policy Optimization (PPO) algorithm and a reward model predictive of human preferences.
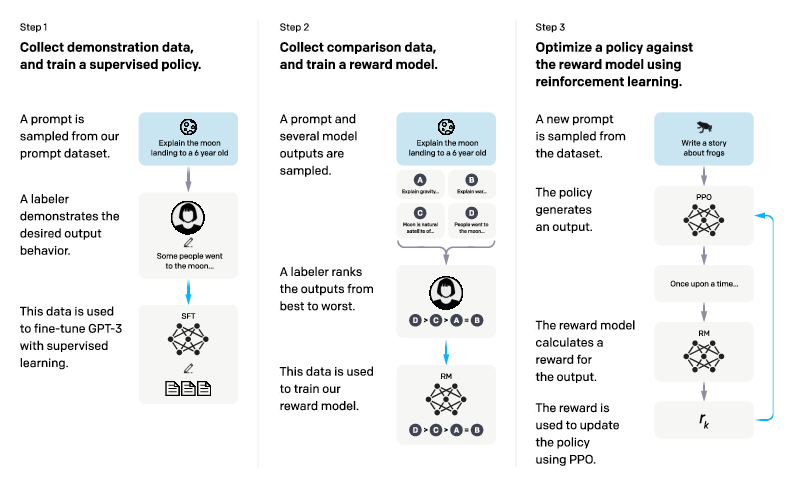
Figure 1: A diagram illustrating the three steps of our method, indicating the use of human feedback in training.
Results and Evaluations
Human evaluations demonstrate significant preference for outputs from InstructGPT over baseline GPT-3 models, despite InstructGPT using fewer parameters. Notably, outputs from a 1.3B parameter InstructGPT model are preferred to those from 175B GPT-3 models. Additionally, the InstructGPT models improve truthfulness and reduce toxic output generation substantially while maintaining comparable performance on standard NLP benchmarks. However, InstructGPT models still produce simple errors occasionally, such as failing to recognize false premises in questions.
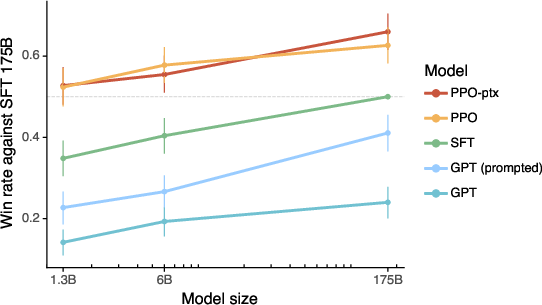
Figure 2: Human evaluations of InstructGPT models against GPT-3 baselines, showing preference for InstructGPT outputs on various prompts.
Implications and Open Questions
The findings suggest that RLHF is a promising direction for realigning LLMs with human intentions. By efficiently leveraging human feedback, models can achieve significant alignment without an "alignment tax"—a decrease in performance on established NLP tasks. Future research could explore refining human data collection methodologies, enhancing model responsiveness to adversarial prompts, and conceptualizing models that can adapt to diverse human values and preferences.
Additionally, determining how universally applicable the alignment techniques are, and how they can be adapted to further reduce biased and harmful outputs, remains an open avenue. Work is needed to develop methods ensuring models understand when not to comply with harmful or unethical user requests, which poses a serious challenge in current implementations.
In conclusion, aligning LLMs more closely with human values and preferences is crucial in mitigating risks associated with misuse. The exploration of RLHF offers a viable path towards more reliable and safe AI deployments across various applications, although continued research and ethical considerations remain vital.