SymptomAI: Towards a Conversational AI Agent for Everyday Symptom Assessment
Abstract: LLMs excel at diagnostic assessments on currated medical case-studies and vignettes, performing on par with, or better than, clinical professionals. However, existing studies focus on complex scenarios with rich context making it difficult to draw conclusions about how these systems perform for patients reporting symptoms in everyday life. We deployed SymptomAI, a set of conversational AI agents for end-to-end patient interviewing and differential diagnosis (DDx), via the Fitbit app in a study that randomized participants (N=13,917) to interact with five AI agents. This corpus captures diverse communication and a realistic distribution of illnesses from a real world population. A subset of 1,228 participants reported a clinician-provided diagnosis, and 517 of these were further evaluated by a panel of clinicians during over 250 hours of annotation. SymptomAI DDx were significantly more accurate (OR = 2.47, p < 0.001) than those from independent clinicians given the same dialogue in a blinded randomized comparison. Moreover, agentic strategies which conduct a dedicated symptom interview that elicit additional symptom information before providing a diagnosis, perform substantially better than baseline, user-guided conversations (p < 0.001). An auxiliary analysis on 1,509 conversations from a general US population panel validated that these results generalize beyond wearable device users. We used SymptomAI diagnoses as labels for all 13,917 participants to analyze over 500,000 days of wearable metrics across nearly 400 unique conditions. We identified strong associations between acute infections and physiological shifts (e.g., OR > 7 for influenza). While limited by self-reported ground truth, these results demonstrate the benefits of a dedicated and complete symptom interview compared to a user-guided symptom discussion, which is the default of most consumer LLMs.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
SymptomAI: A Simple Explanation
What is this paper about?
This paper describes SymptomAI, a chat-based health assistant that talks with people about their symptoms and suggests possible reasons they might be feeling sick. The researchers tested SymptomAI with thousands of real people to see how well it can ask good questions and come up with a smart “shortlist” of possible causes, similar to what a doctor does during an interview.
What questions were the researchers trying to answer?
The study focused on three simple questions:
- Can an AI chat assistant run a good, personalized symptom interview (like a careful health “detective”)?
- Can it suggest likely causes (a “differential diagnosis,” or DDx) accurately when people describe symptoms in their own words?
- Will it keep working well across many real-life conditions and types of people?
How did they do the study?
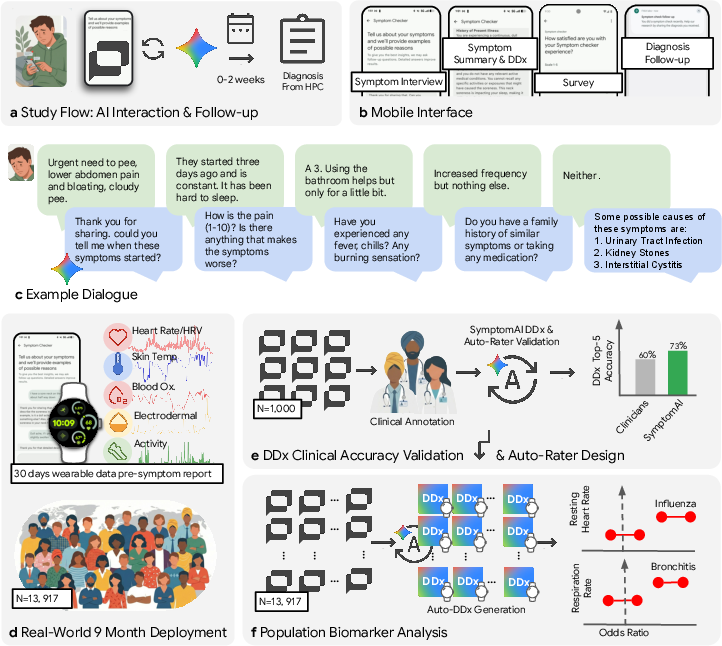
To test SymptomAI in the real world, the team ran a large study inside the Fitbit app:
- 13,917 people across the United States used SymptomAI to talk about their symptoms. This created a big set of real conversations, not just textbook cases.
- People were randomly assigned to one of five versions of the AI. Some versions followed a strict list of classic doctor questions (like when symptoms started, how strong they are, what makes them better or worse). Others asked flexible follow-up questions. One basic version mostly waited for the user to lead the conversation.
- Some participants later reported the diagnosis they got from a healthcare provider, giving the researchers a way to check accuracy.
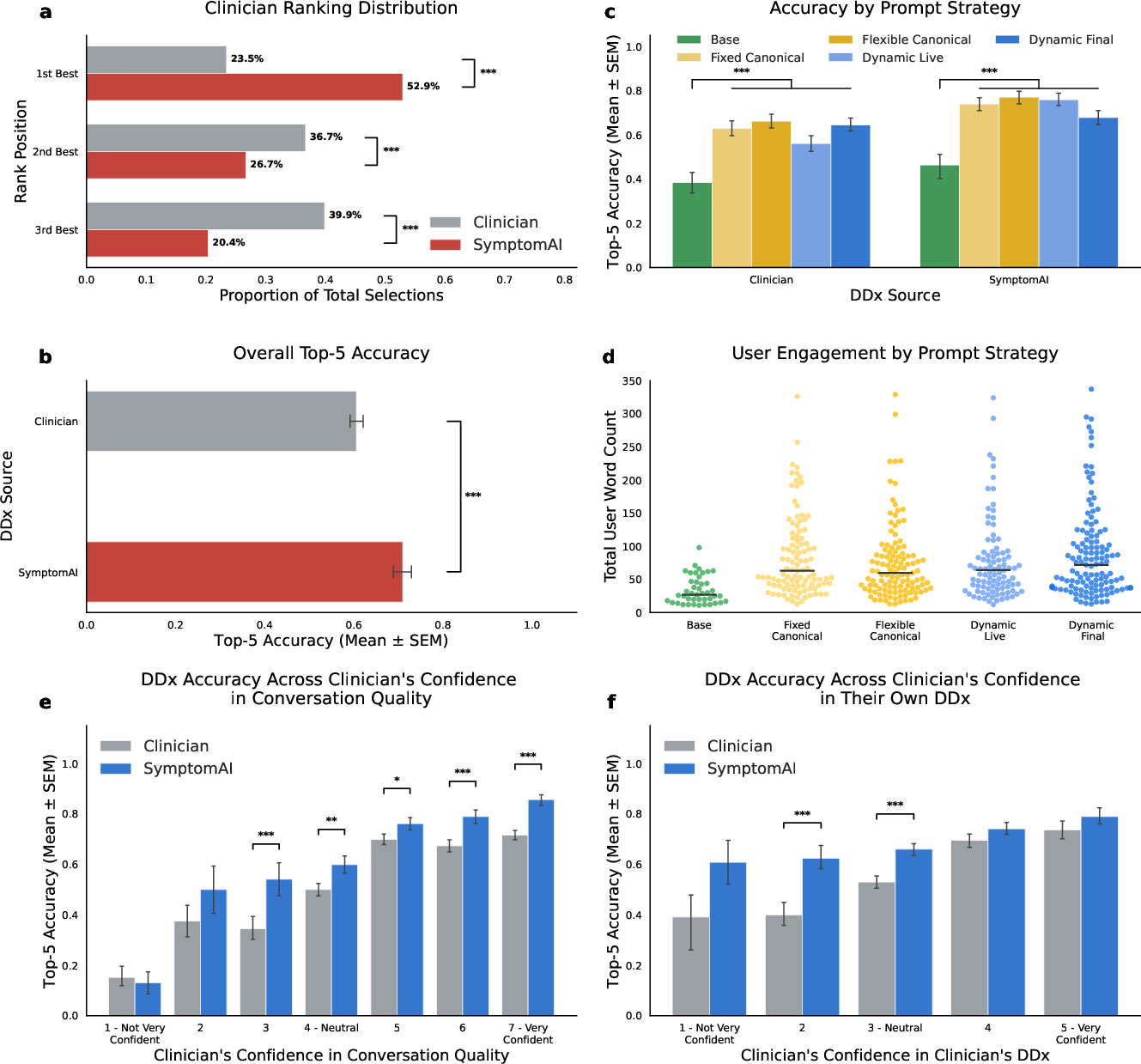
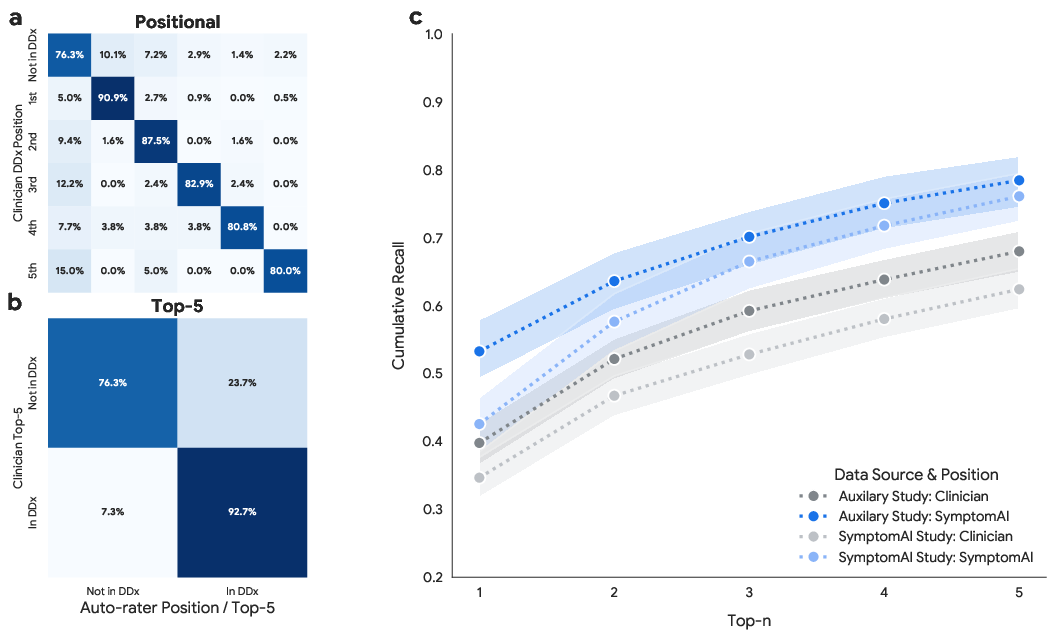
- For a careful check, three experienced family doctors reviewed a subset of 517 conversations. They looked at anonymous “top-5” lists of possible causes from SymptomAI and from two independent clinicians (who only saw the chat transcript). The reviewers didn’t know who wrote each list (“blinded” review) and judged which list was best.
- The team also tested SymptomAI with 1,509 people from a general U.S. population panel (not just Fitbit users) to see if results held up elsewhere.
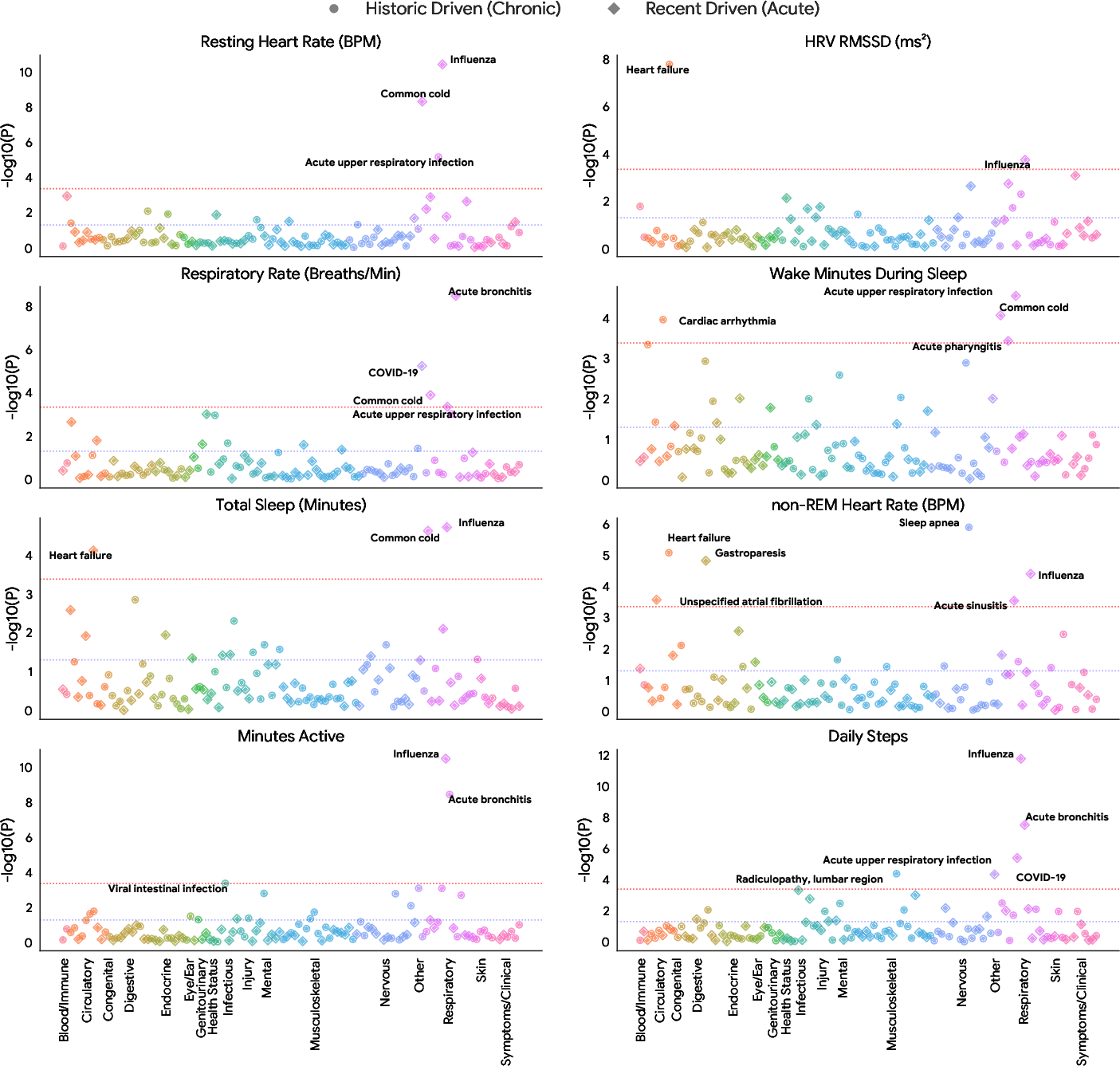
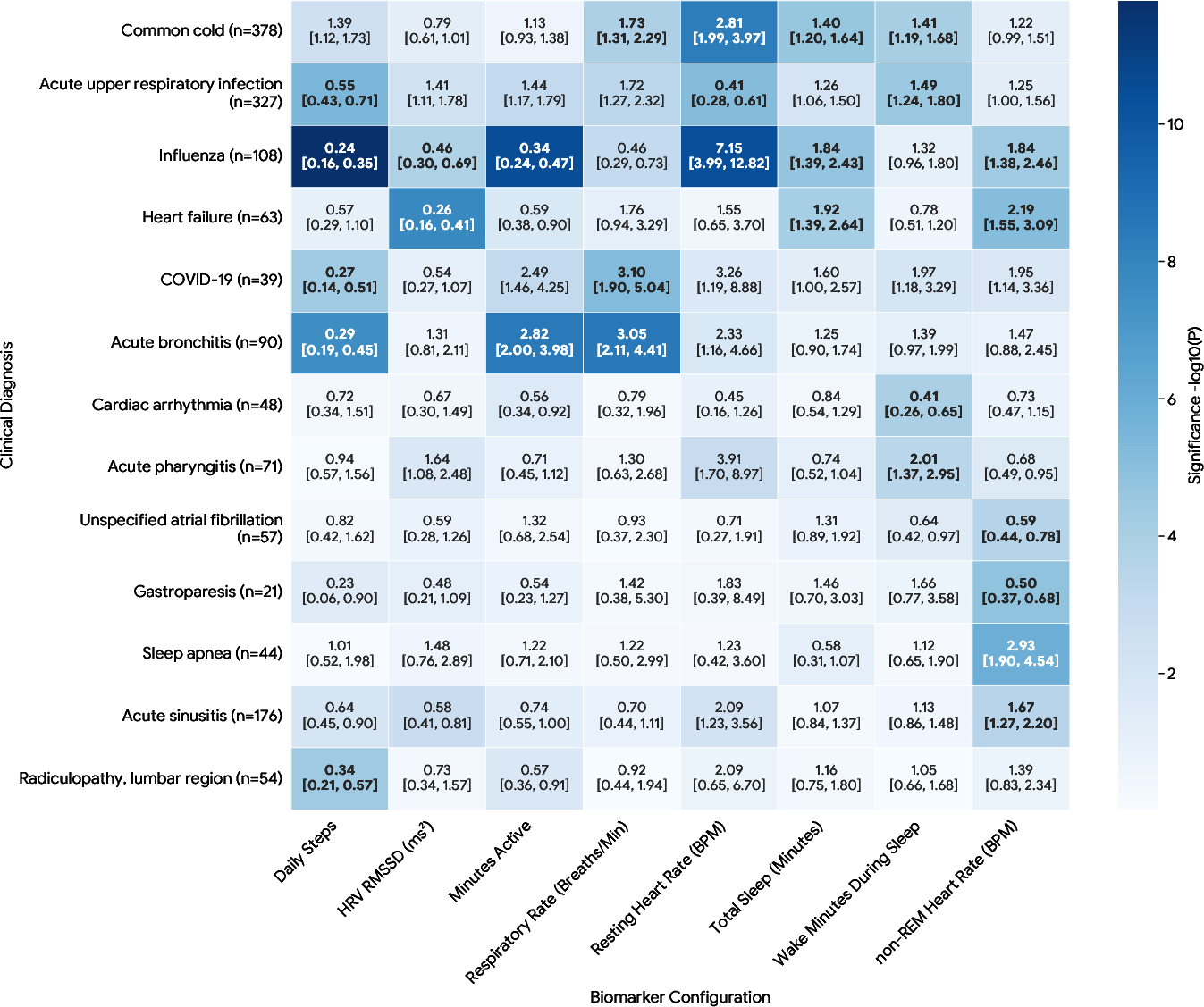
- Finally, the researchers used SymptomAI’s suggested top diagnosis to look for patterns in more than 500,000 days of wearable data (like heart rate, sleep, and temperature) across nearly 400 conditions. This broad scan across many conditions is called a “phenome-wide association study” (PheWAS)—think of it as checking which body signals tend to change for which illnesses.
Helpful terms:
- Differential diagnosis (DDx): a short list of the most likely causes of your symptoms.
- Blinded review: judges don’t know who produced the answers, so they can be fair.
- Auto-rater: a computer system that helps score accuracy consistently across many cases.
- PheWAS: scanning many conditions to see how they relate to certain body signals.
What did they find, and why is it important?
Here are the main results:
- Interviews that ask follow-up questions work better. Versions of SymptomAI that actively asked more questions were much more accurate than the version that just let the user lead the conversation. In simple terms: the AI worked better when it behaved like a careful interviewer, not a passive answerer.
- Doctors often preferred SymptomAI’s lists. When blinded reviewers compared three lists (one from SymptomAI, two from independent clinicians), they picked SymptomAI’s list as best more than half the time.
- SymptomAI’s accuracy was higher than clinicians’ when both worked from the same chat transcript. This was especially true when information was limited or unclear—SymptomAI stayed relatively strong even when the case was tough.
- The results generalized beyond Fitbit users. In a separate U.S. population sample, SymptomAI’s accuracy stayed high and close to the main study’s results.
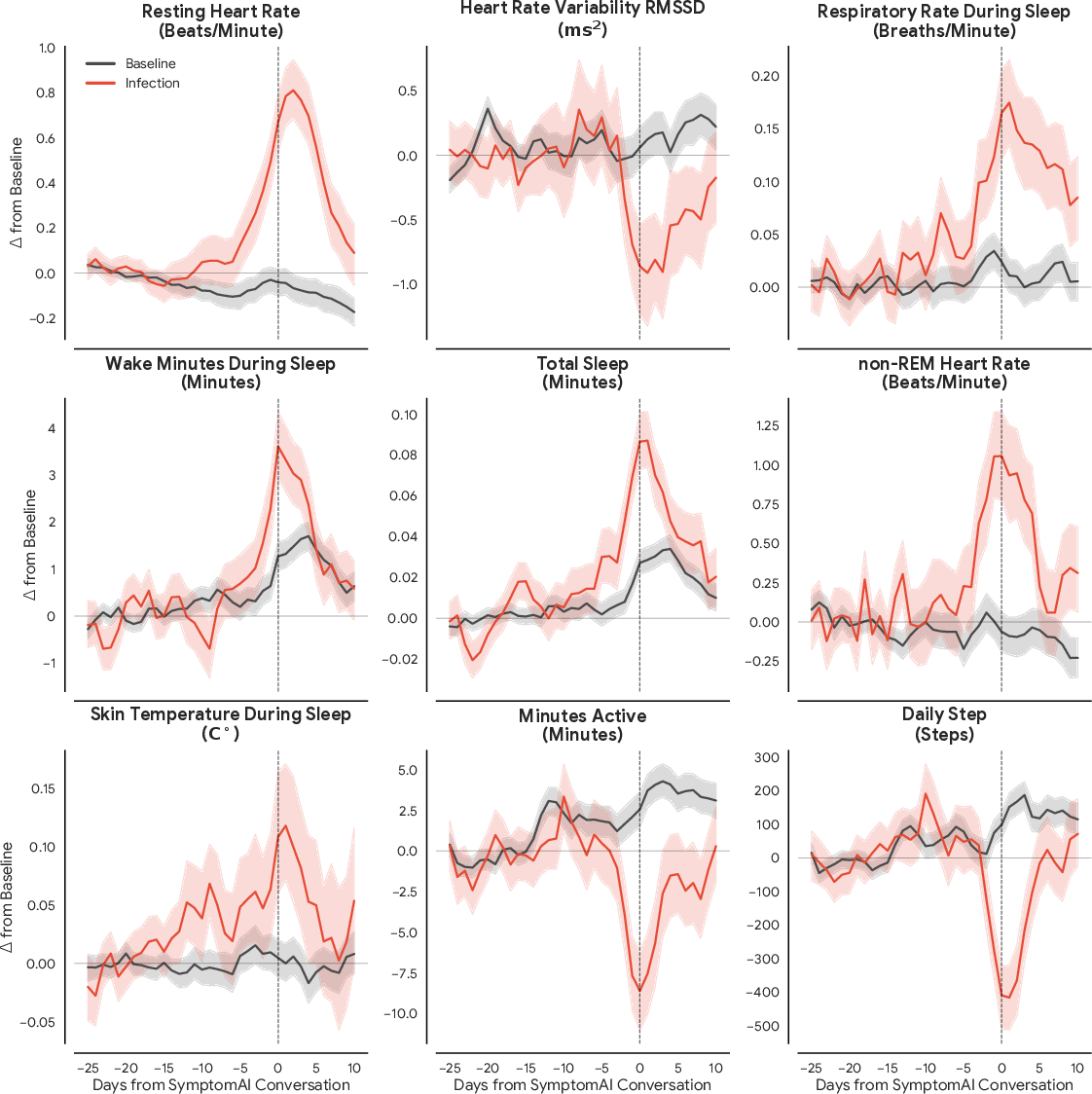
- Wearables showed clear changes around some illnesses. For example, during acute respiratory infections (like the flu), people’s body signals (e.g., heart rate, sleep interruptions, skin temperature) shifted in the days leading up to when they talked to SymptomAI. This suggests wearables might help spot illness earlier and could trigger a timely symptom check-in.
Why this matters:
- Most consumer AI chats today don’t insist on asking enough follow-up questions before giving an opinion. This study shows that a structured, question-rich interview can make AI symptom assessment safer and more accurate.
- Using AI labels at scale made it possible to study how illnesses relate to wearable signals across hundreds of conditions—something very hard to do with limited clinical labels.
What could this mean for the future?
- Better design for health chats: AI symptom tools should act like thoughtful interviewers—asking clear, targeted questions—before suggesting possible causes.
- Earlier help: If wearables notice unusual changes, they could prompt a quick AI check-in, helping people seek care sooner for things like respiratory infections.
- Scalable research: AI-generated labels (used carefully and ethically) can unlock large studies of how daily body signals relate to many illnesses, possibly leading to earlier detection and better public health insights.
Important limits to keep in mind
- Some “ground truth” diagnoses were self-reported by participants, which can include errors.
- The clinicians who competed with SymptomAI saw only the chat transcript; they didn’t run the interview themselves.
- SymptomAI is a research prototype, not a medical device, and it doesn’t replace professional care. Many conditions still require tests or exams to confirm.
Bottom line
When an AI health assistant takes the lead and asks the right follow-up questions—like a good detective—it can build a stronger picture of what’s going on. In this large real-world study, that approach made SymptomAI’s suggestions more accurate and often preferred over clinicians’ lists made from the same information. Combined with wearables, this kind of careful AI interviewing could help people get timely, useful guidance and enable big-picture health research—while still needing proper medical confirmation when necessary.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The study advances conversational AI for symptom assessment at scale, but several uncertainties and unmet needs remain:
- Ground truth validity: Reliance on self-reported clinician diagnoses (often delayed and second/third-hand) introduces label noise; no linkage to EHR, claims, or lab-confirmed diagnoses to independently verify accuracy.
- Timing misalignment: The temporal relation between the AI conversation and the clinician diagnosis is not standardized, risking mismatches (e.g., early/late disease stages) that affect accuracy evaluation.
- Top-5 accuracy vs clinical utility: Primary accuracy metric is top-5 DDx; real-world decision-making often depends on top-1 and triage safety. The study does not quantify top-1 accuracy, calibration, or triage appropriateness.
- Safety and harm assessment: No measurement of unsafe advice, over-/under-triage, missed emergent conditions, or potentially harmful recommendations (e.g., false reassurance in red-flag scenarios).
- Clinician comparison validity: Baseline clinicians reviewed AI-conducted interviews rather than conducting their own history-taking, limiting an end-to-end clinician vs AI comparison; the size and representativeness of the clinician pool and inter-rater agreement are not reported.
- Auto-rater (LLM verifier) dependence: Large-scale accuracy relies on an auto-rater; details on its architecture, training data, independence from SymptomAI, calibration, error modes, and external validation are insufficient.
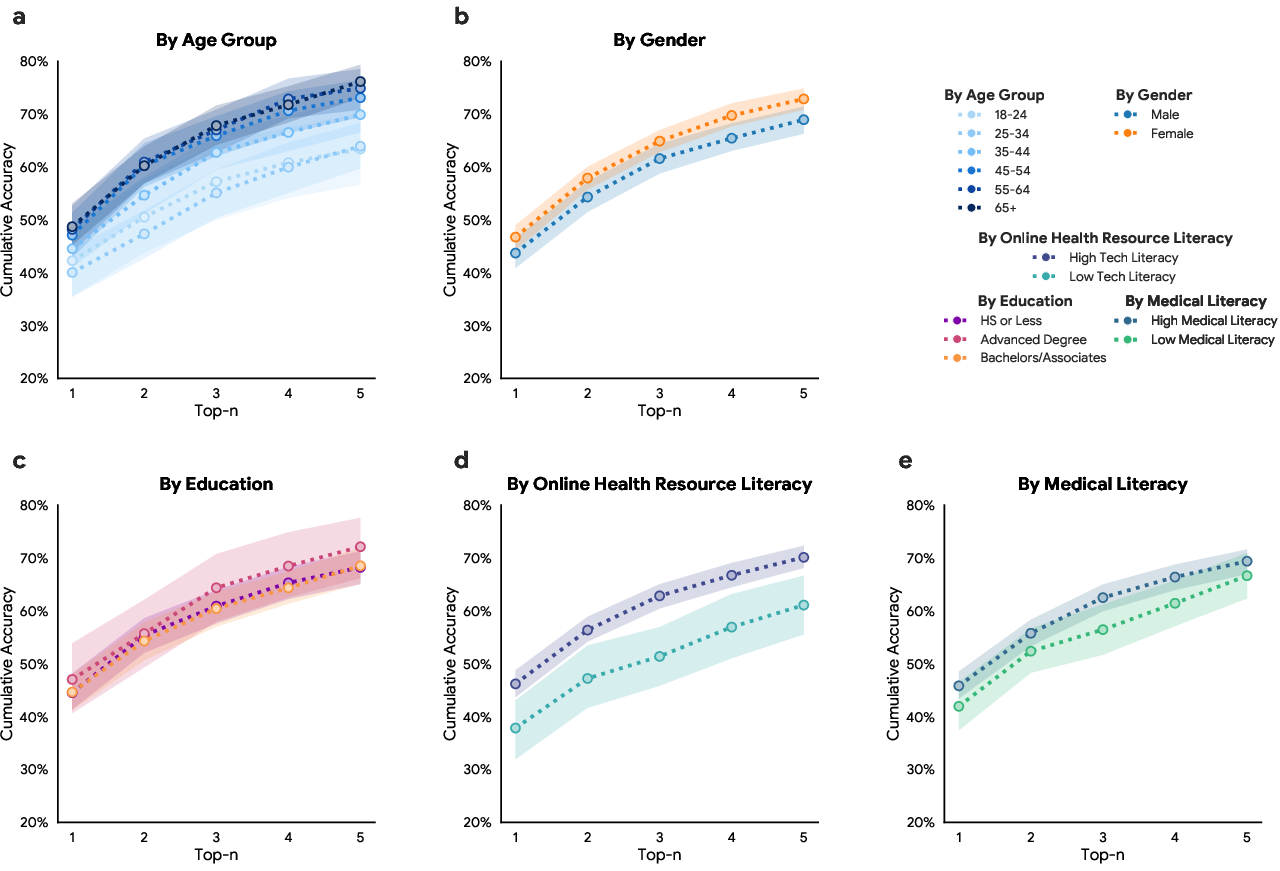
- Generalizability beyond study populations: Participants are US Fitbit users (and a US general panel for auxiliary analysis). Performance across non-wearable owners, older adults, pediatrics, low-SES groups, rural populations, and non-US contexts is unknown.
- Demographic fairness: No stratified performance by race/ethnicity, socioeconomic status, geography, language, or health literacy; potential bias and equity concerns remain unquantified.
- Language coverage: Language(s) used are not detailed; performance in non-English or multilingual conversations—and with interpreters—is untested.
- Health literacy and communication style: Effects of low health literacy, nonstandard symptom narratives, and communication impairments on AI performance are not analyzed.
- Rare and high-acuity conditions: Performance on rare diseases and time-critical emergencies (e.g., MI, stroke, sepsis, ectopic pregnancy) is not separately evaluated; safety-critical false negatives are not quantified.
- Multi-morbidity and multi-label cases: The evaluation assumes a single “ground truth” diagnosis; handling of multiple concurrent conditions or symptom clusters is not analyzed.
- Elicitation vs length confounding: The observed benefit of “eliciting more information” is not disentangled from conversation length/word count; controlled studies varying structure vs length are needed.
- Prompt design transparency: The full prompt content (e.g., Arms 2–5) is partially omitted ({paper_content}), limiting reproducibility and interpretability of agentic strategies.
- Model non-stationarity: The deployment spans months; potential model updates/drift are not tracked. It is unclear whether the underlying model and prompts were held fixed.
- Calibration and uncertainty: The system’s confidence estimates, probability calibration, abstention behavior, and how uncertainty is communicated to users are not evaluated.
- User outcomes and behavior: The study does not measure downstream outcomes (e.g., care-seeking, time to care, adherence to triage advice, clinical outcomes, costs) or effects on healthcare utilization.
- Human factors and UX trade-offs: Forcing additional turns improved accuracy but the impact on user burden, satisfaction, trust, and dropout is not reported.
- Clinician workflow integration: How outputs integrate into clinical workflows, handoffs, documentation, or shared decision-making remains unexplored.
- Regulatory readiness: No assessment of requirements for regulatory validation, risk management, post-market surveillance, or clinical safety cases.
- Wearable-label coupling: PheWAS uses AI-generated labels for all participants, compounding label noise; no sensitivity analyses to label uncertainty or alternative labeling strategies are shown.
- Confounding in biosignal analyses: PheWAS controls age/sex/weight but not seasonality, geography, circulating pathogen prevalence, device model/version, or behavior change confounders; potential spurious associations remain.
- Missing data and device heterogeneity: Handling of missing wearable data, variable wear-time, and device-model differences is not described; these may bias biosignal findings.
- Temporal window choices: Robustness of biosignal associations to different “recent” and “historic” windows and lag structures is not tested.
- External validation of biosignal findings: No replication using clinically verified diagnoses or independent datasets (e.g., lab-confirmed influenza/COVID) to validate reported ORs (e.g., influenza OR > 7).
- Proactive detection claims: The proposed wearable-triggered proactive SymptomAI engagement is not tested; effects on earlier detection, transmission reduction, or care outcomes remain hypothetical.
- Error analysis: No granular audit of failure modes (e.g., systematic misses, anchoring, demographic skews, specific symptom patterns) to guide mitigation.
- Adversarial and out-of-scope inputs: Robustness to misleading, incomplete, or adversarial user inputs and guardrails against unsafe guidance are not evaluated.
- Longitudinal performance: How repeated use, increased user familiarity, or evolving/chronic conditions affect performance over time is unknown.
- Comparative benchmarking: No head-to-head comparisons with other state-of-the-art LLM agents or regulated symptom checkers on the same real-world cohort.
- Cost-effectiveness: Economic analyses (e.g., cost per correct triage/diagnosis, potential system-wide savings or burdens) are not performed.
- Reproducibility constraints: Raw wearable data are not shareable; partial prompt opacity and reliance on proprietary models limit independent replication.
- Ethical safeguards: Policies for escalation, duty of care in emergencies, and handling disclosures of self-harm or abuse in conversational settings are not described.
These gaps highlight pathways for future work, including verified clinical labels (EHR/labs), safety and triage evaluation, demographic fairness audits, controlled elicitation experiments, longitudinal and outcome-based trials, robust biosignal confounding control, and transparent, reproducible agent designs.
Practical Applications
Immediate Applications
The paper’s findings and assets enable several deployable use cases across sectors. Below are concrete applications that can be implemented now, with likely tools/workflows and key dependencies noted.
- Symptom interview upgrade for consumer health chatbots (healthcare, software)
- Use an agentic “guided interview” pattern (minimum turns, follow‑up questions) to replace user‑guided chats, improving differential accuracy in symptom assessment.
- Tools/workflows: Prompt libraries enforcing HPI elements (e.g., OPQRST), dynamic follow‑ups, red‑flag screening, top‑K DDx with rationale; A/B tests vs. baseline chat.
- Assumptions/dependencies: Clear disclosures (non‑diagnostic), safety guardrails, jurisdictional compliance; performance monitored on local user populations.
- Pre‑visit intake and triage in telehealth and clinics (healthcare)
- Deploy SymptomAI‑style interview in patient portals or waiting rooms to collect structured histories and candidate DDx, routing to urgent, routine, or self‑care pathways.
- Tools/workflows: EHR intake form generator, clinician‑friendly summary, structured data export (FHIR), red‑flag escalation.
- Assumptions/dependencies: Clinician oversight; integration with EHR; liability and consent language; not billed as diagnosis.
- Asynchronous history collection for clinician efficiency (healthcare)
- Offload HPI gathering to an AI interview prior to visits to reduce clinician time and variation in histories, especially for urgent care and primary care.
- Tools/workflows: Patient‑facing chat; clinician summary with prioritized DDx and missing‑info prompts.
- Assumptions/dependencies: Acceptance by clinicians; documentation standards; monitoring for hallucinations.
- Research labeling at scale for wearable studies (academia, wearables)
- Use AI-generated top diagnoses as proxy labels to conduct large‑scale phenome‑wide biosignal analyses when clinical labels are scarce.
- Tools/workflows: Auto‑rater pipelines to score DDx quality; regression frameworks linking diagnoses with time‑windowed biosignals.
- Assumptions/dependencies: Explicit research consent; careful handling of label noise; IRB oversight.
- Conversation dataset for NLP and HCI research (academia, software)
- Leverage the released de‑identified conversations and clinician evaluations for benchmarking conversational agents, question strategies, and auto‑raters.
- Tools/workflows: Open code for analysis and plotting; reproducible prompt/arm comparisons; HCI studies on turn‑taking and elicitation strategies.
- Assumptions/dependencies: Data access approvals; privacy-preserving protocols.
- QA/evaluation infrastructure using an LLM “auto‑rater” (software, healthcare)
- Adopt validated auto‑rater methods to score DDx quality at scale for continuous model evaluation and safer deployments.
- Tools/workflows: Evaluation harness with blinded comparisons; agreement checks against clinician‑rated subsets.
- Assumptions/dependencies: Ongoing calibration to clinical judgments; drift detection.
- UX pattern: model‑guided elicitation for other domains (software, customer support)
- Apply the interview‑first pattern to any LLM assistant that depends on user‑provided context (e.g., insurance claims, IT support) to improve output quality.
- Tools/workflows: Turn‑budgeted interviews; canonical vs. dynamic question templates; stop‑criteria rules.
- Assumptions/dependencies: Domain‑specific safety and privacy constraints.
- Patient self‑preparation checklist (daily life, education)
- Provide individuals a simple structured checklist (onset, location, quality, severity, provoking/palliating factors, associated symptoms) to prepare for visits.
- Tools/workflows: Printable/interactive checklists; consumer‑facing health app modules.
- Assumptions/dependencies: Clear non‑diagnostic framing; accessibility and multilingual support.
- Policy and procurement guidance for symptom checkers (policy, healthcare)
- Recommend minimum standards (structured elicitation before DDx, red‑flag detection, transparency about limitations) for procurement and deployment.
- Tools/workflows: Implementation checklists; model reporting templates (intended use, evaluation metrics).
- Assumptions/dependencies: Alignment with regulators; stakeholder buy‑in.
- Wellness notifications tied to symptom interviews (wearables, consumer health)
- When users manually report feeling unwell, trigger a structured interview to capture accurate onset and context for personal tracking or care navigation.
- Tools/workflows: In‑app prompts; privacy‑preserving summaries; user‑controlled sharing with clinicians.
- Assumptions/dependencies: Consent; non‑diagnostic use; clear opt‑ins.
Long‑Term Applications
These opportunities build directly on the paper’s innovations but require further research, scaling, integration, or regulatory clearance before real‑world deployment.
- Proactive, biosignal‑triggered check‑ins for early infection (healthcare, wearables, public health)
- Combine deviations in HR, HRV, sleep, respiration, and temperature with SymptomAI‑style interviews to catch respiratory infections earlier and reduce transmission.
- Tools/workflows: Anomaly detection models; risk thresholds; just‑in‑time prompts; telehealth scheduling.
- Assumptions/dependencies: High‑precision thresholds; false‑positive mitigation; regulatory approvals for any diagnostic claims.
- Clinician‑supervised diagnostic copilot (healthcare)
- Integrate the agent into EHRs as a diagnostic aid that suggests differentials and next‑best questions/tests, especially in low‑information cases where it excelled.
- Tools/workflows: EHR plugins; audit trails; counterfactual explanations; red‑flag escalation.
- Assumptions/dependencies: Clinical trials on outcomes; governance; malpractice frameworks.
- Regulatory‑approved consumer symptom assessment (healthcare, policy)
- Evolve from research prototype to a regulated medical device that offers risk‑stratified guidance with clear actionability.
- Tools/workflows: SaMD lifecycle; post‑market surveillance; bias and safety auditing.
- Assumptions/dependencies: Evidence from multi‑site trials; robust risk management.
- Real‑time syndromic surveillance (public health, policy)
- Aggregate de‑identified symptom conversations and wearable signals to detect outbreaks and seasonal waves in near‑real time.
- Tools/workflows: Privacy‑preserving analytics; federated aggregation; dashboards for health departments.
- Assumptions/dependencies: Privacy laws and consent; sampling bias corrections; partnerships with agencies.
- Longitudinal personal health baselines (healthcare, wearables)
- Build individualized models that fuse recurring interviews and biosignals to detect exacerbations in chronic conditions (e.g., asthma, heart failure).
- Tools/workflows: Personal baseline modeling; trend detection; care plan integration.
- Assumptions/dependencies: Adherence; device consistency; clinical validation.
- Multimodal diagnostic reasoning (healthcare, software)
- Extend interviews with labs, imaging, vitals, and medication data for richer differential generation and test prioritization.
- Tools/workflows: Data connectors (FHIR, DICOM); multimodal LLMs; recommendation policies for tests/referrals.
- Assumptions/dependencies: Data access/consent; generalization across health systems; evaluation on outcomes.
- Workforce augmentation and documentation automation (healthcare, finance/insurance)
- Use the agent for comprehensive HPI capture, triage documentation, and insurance‑compliant notes; surface gaps for clinician confirmation.
- Tools/workflows: Structured note generators; CPT/ICD suggestions; claims pre‑checks.
- Assumptions/dependencies: Accuracy safeguards; payer acceptance; auditing for upcoding risks.
- Education and assessment (academia, medical education)
- Deploy as standardized virtual patients and feedback tools to teach HPI and differential diagnosis; evaluate student interviews at scale.
- Tools/workflows: OSCE integrations; rubric‑aligned auto‑raters; scenario banks.
- Assumptions/dependencies: Alignment with curricula; fairness across learner groups.
- Global and multilingual symptom assessment (global health, policy)
- Adapt interviewing strategies to low‑resource settings and diverse languages to improve access where clinicians are scarce.
- Tools/workflows: Localized prompts; offline/edge variants; cultural adaptation.
- Assumptions/dependencies: Language performance; equity and access to devices; community partnerships.
- Standardized evaluation frameworks for medical LLMs (policy, academia)
- Institutionalize auto‑rater‑augmented evaluation with clinician‑blinded subsets, real‑world cases, and reporting standards.
- Tools/workflows: Reference datasets; harmonized metrics (top‑K DDx accuracy, safety events); governance bodies.
- Assumptions/dependencies: Cross‑institution collaboration; continuous updating.
- Care navigation and benefits guidance for payers (insurance/finance)
- Use interview outputs to match members to in‑network providers, virtual care, or self‑care resources, reducing unnecessary ED visits.
- Tools/workflows: Network directory matching; benefit eligibility checks; member engagement campaigns.
- Assumptions/dependencies: Member consent; fairness and bias monitoring; ROI evidence.
- Population‑level research accelerators (academia, pharma)
- Leverage AI‑labeled phenotypes to recruit cohorts and monitor endpoints in observational studies and pragmatic trials more efficiently.
- Tools/workflows: Consent pipelines; phenotype registries; validation subsamples with clinician adjudication.
- Assumptions/dependencies: Regulatory acceptance of proxy labels; reproducibility across devices and sites.
Cross‑cutting assumptions and dependencies
- Regulatory and legal: Clear separation of information vs. diagnosis unless approved; governance for safety, bias, and accountability.
- Privacy and consent: HIPAA/GDPR compliance; transparent user controls; de‑identification and aggregation safeguards.
- Generalizability: Validation beyond US and beyond specific wearable ecosystems; attention to demographic and condition diversity.
- Technical robustness: Guardrails for red‑flags, uncertainty handling, and hallucinations; monitoring for model drift.
- Integration and adoption: EHR connectors, clinician workflows, and telehealth pathways; stakeholder training and incentives.
- Equity: Access for users without wearables or broadband; multilingual and accessible interfaces.
Glossary
- agentic strategies: Prompting or design approaches that give an AI agent autonomy to decide which questions to ask or actions to take during an interaction. "agentic strategies which conduct a dedicated symptom interview that elicit additional symptom information before providing a diagnosis, perform substantially better than baseline, user-guided conversations ()."
- Area Under the Curve (AUC): A scalar metric summarizing a classifier’s performance across thresholds, typically the area under the ROC curve. "AUC = 0.65"
- auto-rater: An automated evaluator (often an LLM) used to score or verify the quality or correctness of outputs at scale. "we employed an auto-rater to assess the DDx accuracy of SymptomAI across the entire cohort of participants who self-reported a diagnosis (N=1,228)."
- blinded randomized comparison: An evaluation design where the assessor is unaware of the authorship/source and items are randomized to reduce bias. "given the same dialogue in a blinded randomized comparison."
- Bonferroni significance threshold: A multiple-comparisons correction that adjusts the p-value threshold to control family-wise error. "The Bonferroni significance threshold per biosignal (ranging from to ) is indicated by a red line"
- Cohen’s g: An effect size measure (often used with McNemar’s test) quantifying the magnitude of change or difference in paired nominal data. "McNemarâs Test: Median OR = 2.47, 95\% CI Cohenâs [0.17, 0.25], p 0.001"
- Cohen’s h: An effect size for differences between proportions, useful for interpreting the magnitude of effects in binomial outcomes. "This is also supported by a Cohenâs of 0.39, indicating a clear, consistent, small-to-medium effect size, in favor of SymptomAI."
- de-identified dataset: A dataset stripped of direct identifiers to protect participant privacy. "we are releasing a de-identified dataset of the conversations (with identifiers removed) and clinician evaluations used in this study to qualified researchers."
- differential diagnosis (DDx): A ranked list of candidate conditions that could explain a patient’s symptoms. "We deployed SymptomAI, a set of conversational AI agents for end-to-end patient interviewing and differential diagnosis (DDx)"
- Fisher’s Exact Test: An exact statistical significance test for contingency tables, often used with small sample sizes. "Fisherâs Exact Test - "
- Health Care Provider (HCP): A licensed clinician or professional authorized to deliver medical care. "diagnoses recieved from a Health Care Provider (HCP)."
- history of present illness (HPI): A structured narrative of a patient’s current symptoms and their progression, used in clinical history-taking. "highly structured history of present illness (HPI) interviews based on canonical medical history taking questions"
- Institutional Review Board (IRB): An ethics committee that reviews research involving human subjects to ensure protection of participants. "using the IRB-approved consent form"
- LLM verifier: A LLM used to validate or grade other model outputs, often as an automated quality checker. "an LLM verifier (i.e., auto-rater)"
- logistic regression: A statistical model for predicting binary outcomes based on predictor variables. "All phenome-wide analyses were performed using multiple logistic regression models adjusted for age, sex, and weight"
- McNemar’s Test: A statistical test for paired nominal data assessing changes or differences on a dichotomous trait. "SymptomAI demonstrated higher top-5 DDx accuracy over the baseline clinician's DDx (McNemarâs Test: Median OR = 2.47, 95\% CI Cohenâs [0.17, 0.25], p 0.001)."
- odds ratio (OR): A measure of association quantifying how the odds of an event differ between groups. "odds ratio of 2.20, one-sided binomial test against expected , , "
- Phecode: A standardized code system that groups ICD codes into clinically meaningful phenotype categories for research. "We find only a small shift in diagnosis category Phecode: (, )."
- phenome-wide association study (PheWAS): A study design that tests associations between exposures (or biomarkers) and a wide array of phenotypes across the phenome. "we treated the top diagnosis generated by SymptomAI as a reference label for these research study participants, enabling a phenome-wide association study (PheWAS) \citep{bastarache2022phenome}"
- phenotype labeler: A tool or model that assigns phenotype labels (e.g., disease categories) from data. "Leveraging SymptomAI as a phenotype labeler enables phenome-wide analysis of biosignals across the study population."
- retrospective reviews: Analyses performed after the fact using previously collected records or transcripts. "All clinical evaluations were conducted as retrospective reviews of the conversation transcripts"
- top-5 accuracy: A metric indicating whether the correct label appears among the top five predicted candidates. "we see similar performance of 75.2\% top-5 accuracy of SymptomAI's DDx on the auxiliary study population"
- wearable biosignals: Physiological measurements collected by wearable devices (e.g., heart rate, sleep metrics). "enabling a phenome-wide association study (PheWAS) of nearly 400 unique medical diagnoses with over 500,000 days of wearable biosignals."
- Welch's t-test: A two-sample t-test variant robust to unequal variances and/or unequal sample sizes. "Welch's t-test ()"
Collections
Sign up for free to add this paper to one or more collections.