A prospective clinical feasibility study of a conversational diagnostic AI in an ambulatory primary care clinic
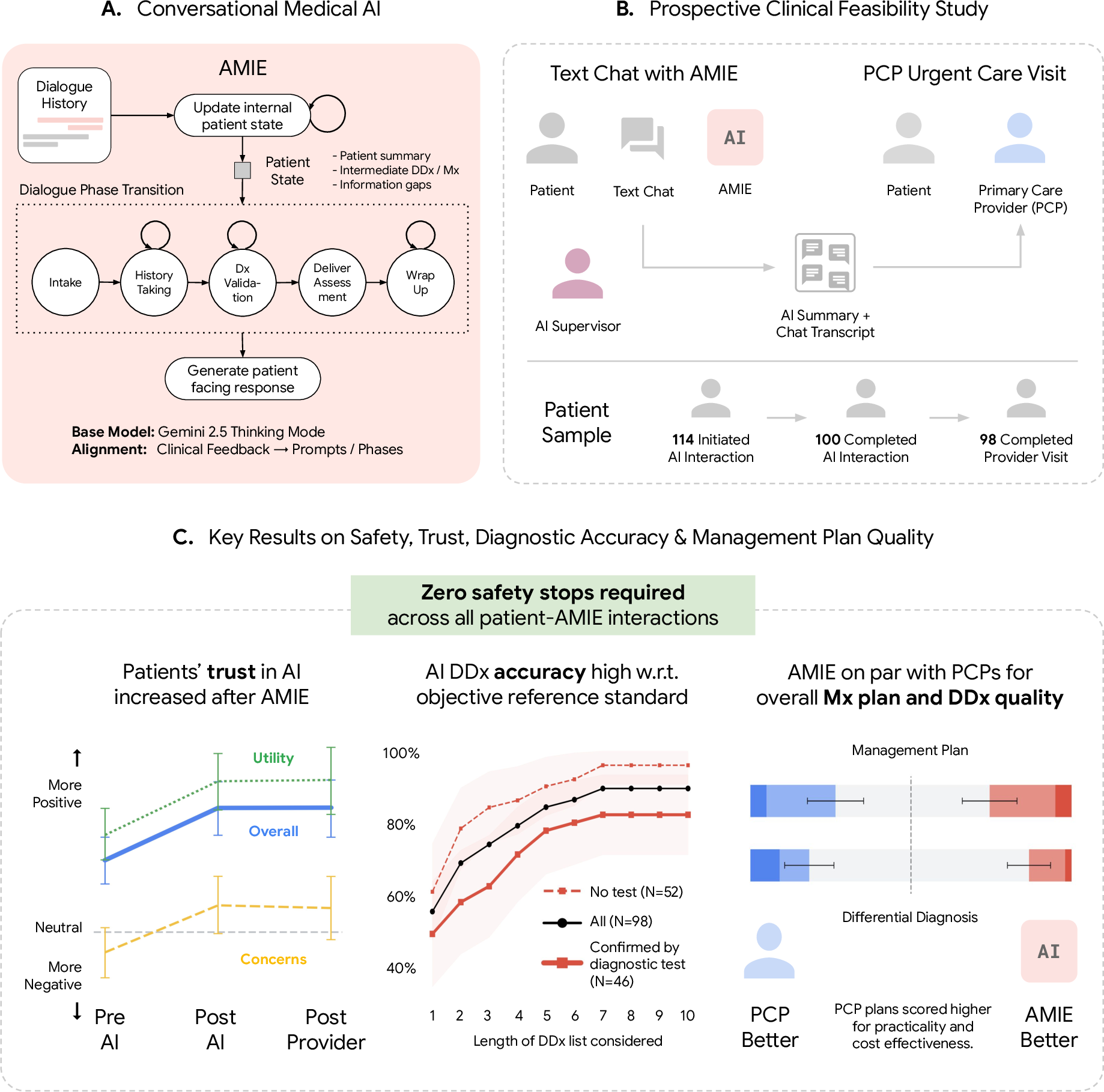
Abstract: LLM-based AI systems have shown promise for patient-facing diagnostic and management conversations in simulated settings. Translating these systems into clinical practice requires assessment in real-world workflows with rigorous safety oversight. We report a prospective, single-arm feasibility study of an LLM-based conversational AI, the Articulate Medical Intelligence Explorer (AMIE), conducting clinical history taking and presentation of potential diagnoses for patients to discuss with their provider at urgent care appointments at a leading academic medical center. 100 adult patients completed an AMIE text-chat interaction up to 5 days before their appointment. We sought to assess the conversational safety and quality, patient and clinician experience, and clinical reasoning capabilities compared to primary care providers (PCPs). Human safety supervisors monitored all patient-AMIE interactions in real time and did not need to intervene to stop any consultations based on pre-defined criteria. Patients reported high satisfaction and their attitudes towards AI improved after interacting with AMIE (p < 0.001). PCPs found AMIE's output useful with a positive impact on preparedness. AMIE's differential diagnosis (DDx) included the final diagnosis, per chart review 8 weeks post-encounter, in 90% of cases, with 75% top-3 accuracy. Blinded assessment of AMIE and PCP DDx and management (Mx) plans suggested similar overall DDx and Mx plan quality, without significant differences for DDx (p = 0.6) and appropriateness and safety of Mx (p = 0.1 and 1.0, respectively). PCPs outperformed AMIE in the practicality (p = 0.003) and cost effectiveness (p = 0.004) of Mx. While further research is needed, this study demonstrates the initial feasibility, safety, and user acceptance of conversational AI in a real-world setting, representing crucial steps towards clinical translation.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (in a nutshell)
This study tested a medical chatbot called AMIE in the real world, not just in labs. AMIE is a conversational AI that chats with patients by text before their urgent care visit, asks smart questions about their symptoms, and creates a short list of possible causes to help the patient and doctor prepare for the appointment. The researchers wanted to see if using AMIE with real patients in a clinic would be safe, helpful, and accurate enough to be worth using.
The big questions the researchers asked
To make their goals easy to follow, here are the main things they wanted to find out:
- Is it safe for real patients to chat with a medical AI before seeing a doctor?
- Do patients and doctors find the AI useful and easy to work with?
- How good is the AI’s “clinical reasoning”—for example, can it suggest the likely causes of a patient’s symptoms (called a differential diagnosis) and reasonable next steps?
- How does the AI’s work compare with what primary care providers (PCPs) do?
How the study worked (in plain language)
Think of AMIE like a very careful, well-trained helper that talks with a patient before their appointment, gathers key facts, and hands the doctor a clear, organized summary.
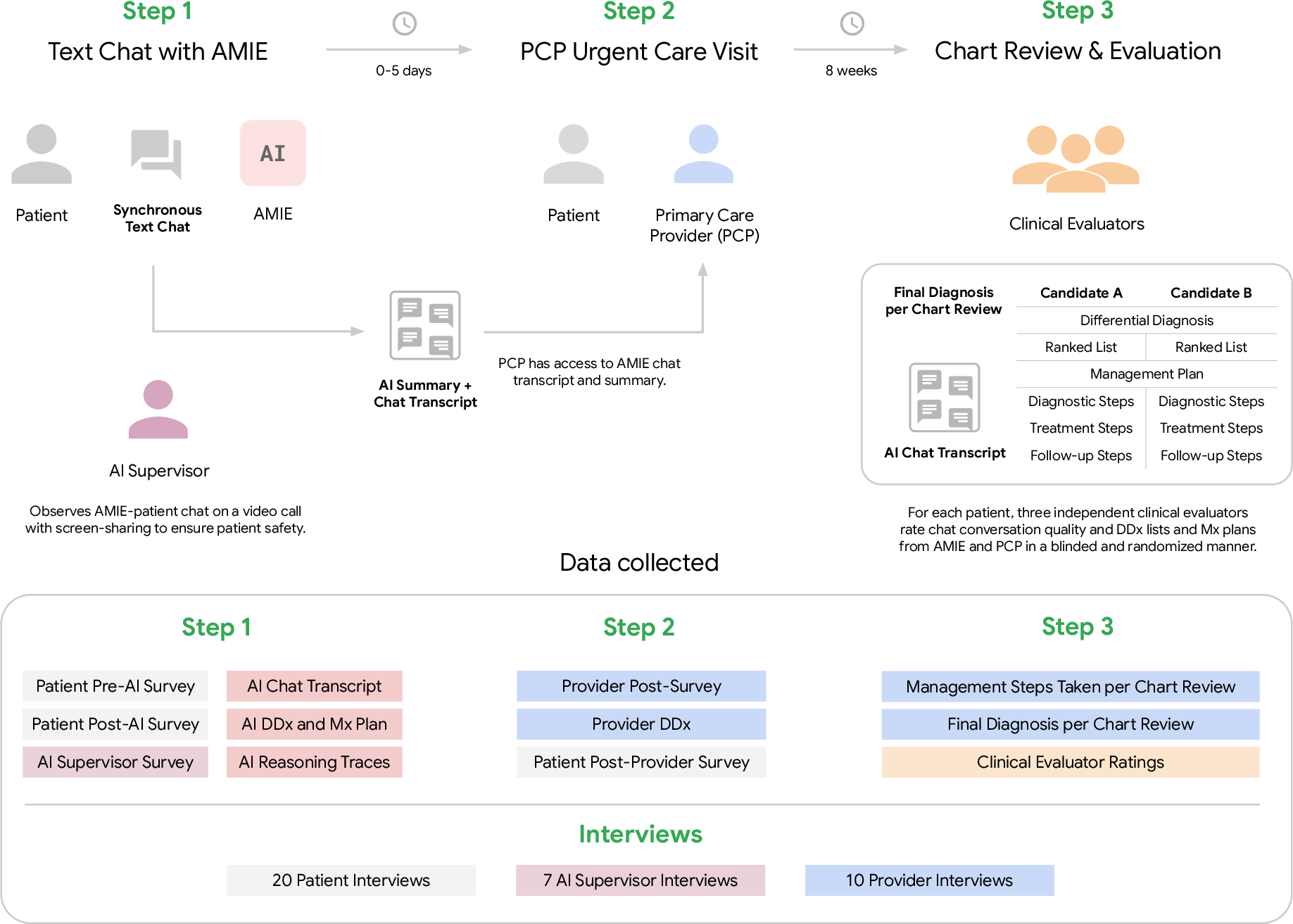
- Study type: This was a “prospective” study (like watching a game live instead of a replay) and “single-arm” (everyone used the AI—there wasn’t a second group without it).
- Who took part: 100 adult patients scheduled for urgent care at a large academic primary care clinic.
- What happened:
- Up to 5 days before the appointment, each patient had a text-chat with AMIE about their main symptom.
- A safety supervisor (a board-certified doctor) watched the chat in real time to make sure nothing unsafe happened and could stop it if needed.
- AMIE gave the patient information about possible diagnoses to discuss with their doctor. It also wrote a summary of the conversation for the doctor to read before the visit.
- After 8 weeks, the research team checked each patient’s medical chart to see what the final diagnosis ended up being.
- Important terms explained:
- “Differential diagnosis” (DDx): a shortlist of the most likely causes of a patient’s symptoms.
- “Management plan” (Mx): suggested next steps, like tests, treatments, or follow-ups.
- “Blinded review”: doctors rated the quality of plans without knowing whether they came from the AI or a human provider.
- “Feasibility”: can this work smoothly in real clinic workflows without causing problems?
What they found and why it matters
Here are the main results, explained simply:
- Safety
- Zero safety stops: Supervising doctors didn’t need to halt any of the 100 AI-patient chats for safety reasons.
- A few minor clarifications were made by supervisors, but no harmful events occurred.
- Patient experience
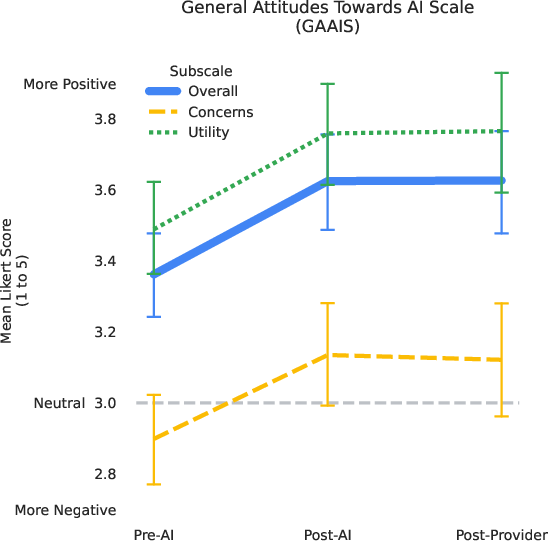
- Patients were highly satisfied and felt positive about the experience.
- Their attitudes toward AI in healthcare improved after using AMIE (this was measured with a standard survey and showed a statistically significant improvement, p < 0.001).
- Doctor experience
- Many primary care providers found AMIE’s notes and possible diagnoses useful and said it helped them feel more prepared for the visit.
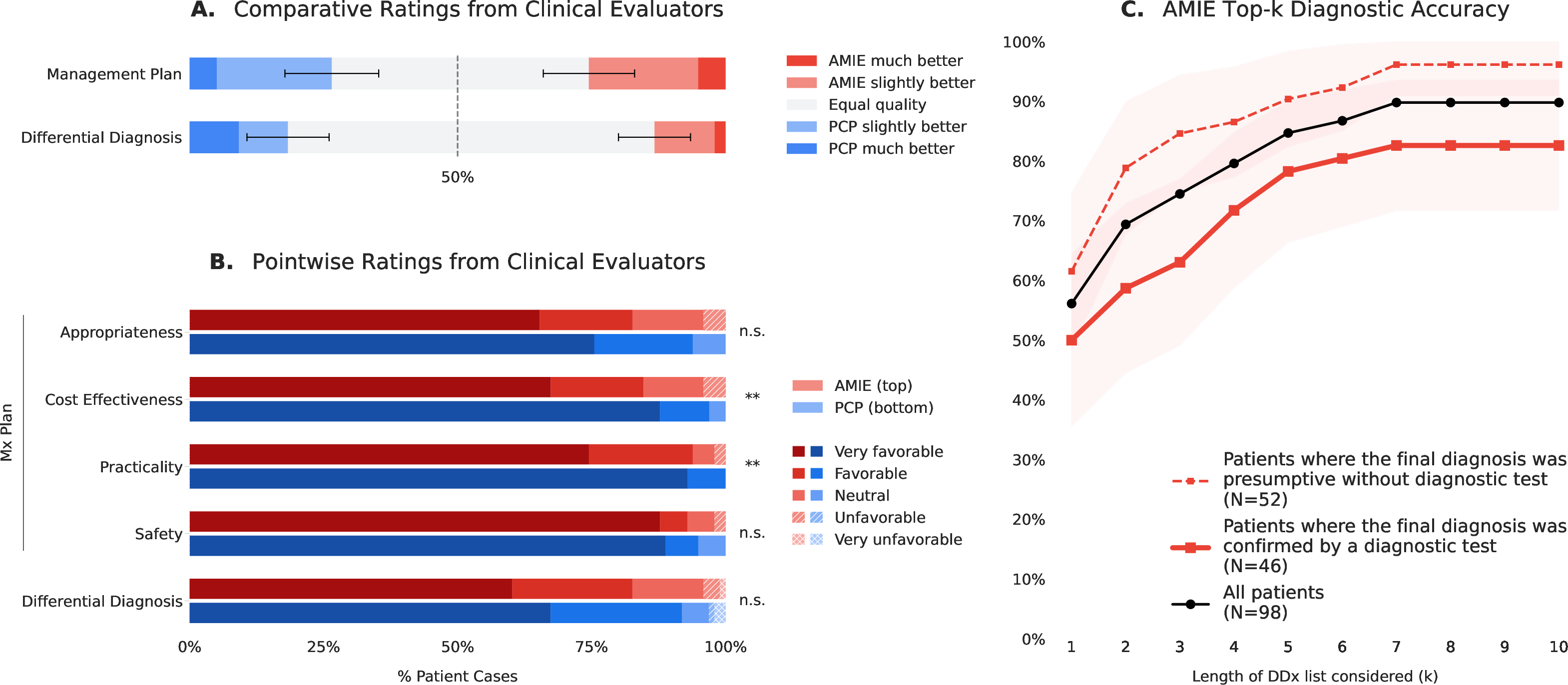
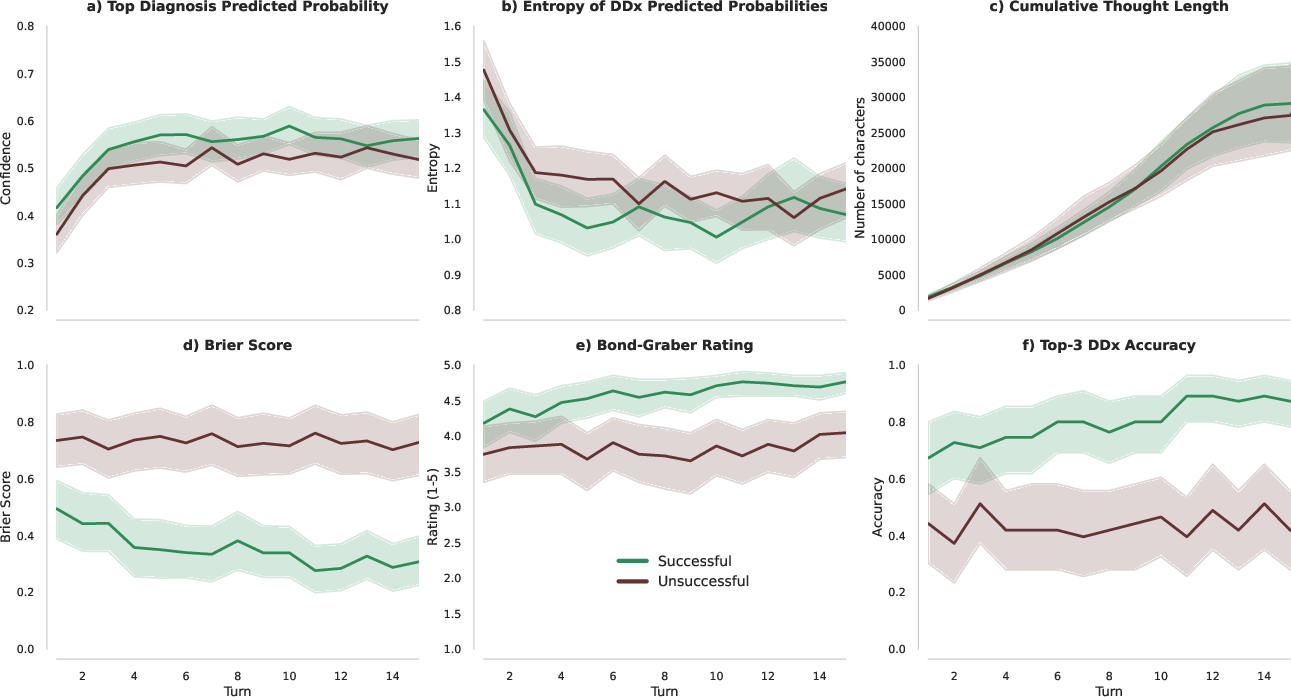
- Diagnostic accuracy
- AMIE’s shortlist of possible diagnoses included the final diagnosis (as confirmed by reviewing the charts 8 weeks later) in 90% of cases.
- In 75% of cases, the correct diagnosis was in AMIE’s top 3 suggestions.
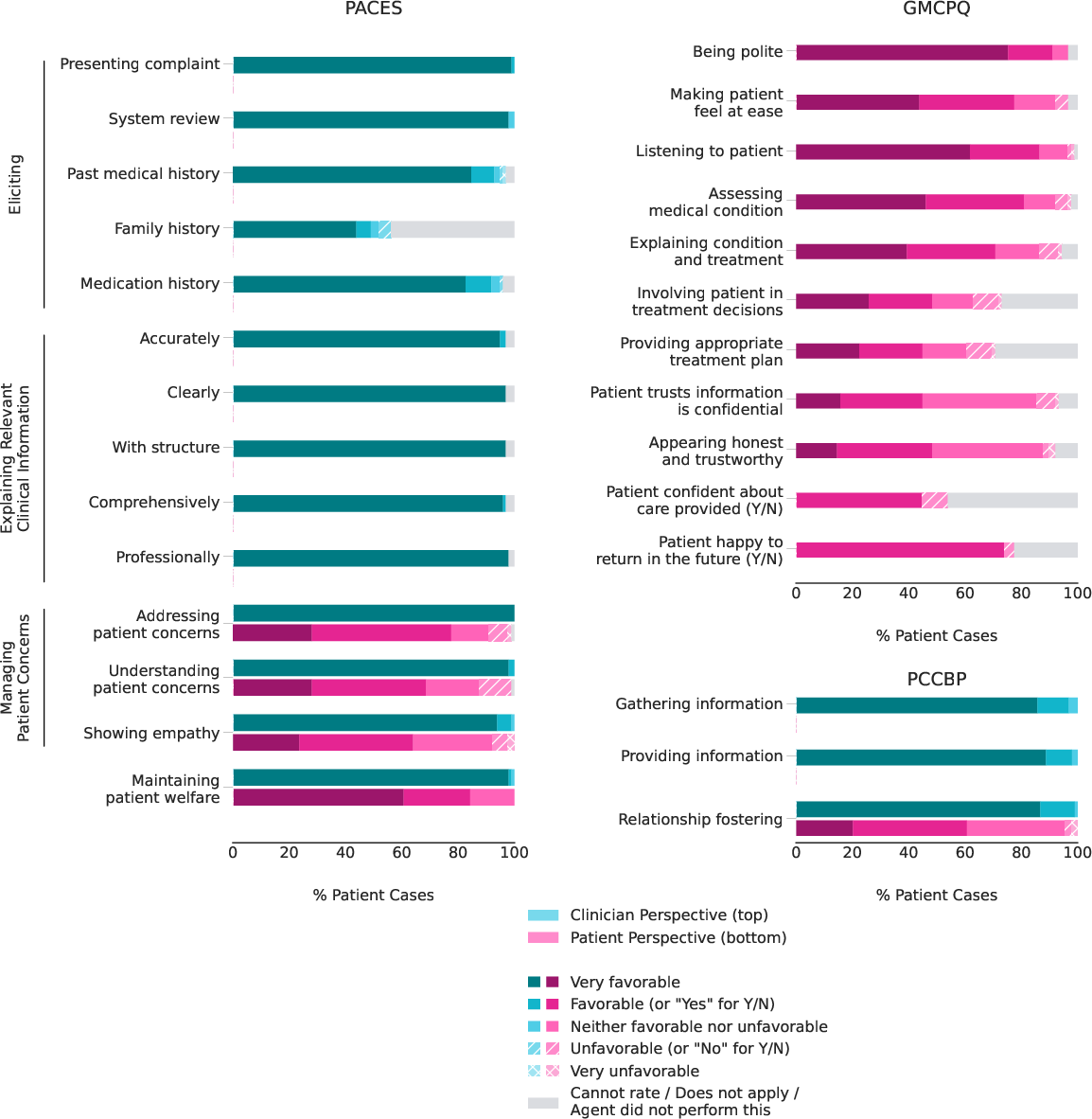
- When expert clinicians rated the quality of AMIE’s differential diagnoses and management plans—without knowing who wrote them—the overall quality was similar to that of human PCPs.
- However, human PCPs were better at making plans that were practical and cost-effective.
- Workflow and tech notes
- The team switched the AI’s underlying model mid-study to reduce lag time, and the process kept running smoothly.
Why this matters: These results suggest that a carefully supervised medical chatbot can safely collect patient history, help patients understand what might be going on, and prepare both patients and doctors for a more focused visit—without lowering quality or safety. That could save time and help clinics cope with doctor shortages.
What this could mean for the future
- Better-prepared visits: If patients arrive with a clear, AI-structured summary of their symptoms and a few likely causes to discuss, appointments can start at a more advanced point, saving time.
- Support for busy clinics: With primary care doctors in short supply, a safe, helpful AI assistant could reduce some workload and possibly lower burnout.
- Not a replacement for doctors: The AI helped with conversation and organization, but doctors were still better at planning practical, affordable next steps. The AI did not make final decisions or give unsupervised medical advice.
- Next steps: Larger, longer studies in different kinds of clinics (and with broader patient groups, including non-English speakers and mental health concerns) are needed to confirm benefits, improve cost/practicality, and ensure reliable safety without constant supervision.
In short, this first real-world test shows that a medical chatbot like AMIE can be safe, helpful, and fairly accurate when used carefully with doctor oversight—an encouraging step toward using AI to make healthcare more efficient and patient-friendly.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what remains missing, uncertain, or unexplored, framed to guide actionable future research:
- Single-arm design without randomization or control: cannot attribute changes in preparedness, satisfaction, or reasoning quality to AMIE versus usual care.
- PCP contamination and variable exposure: all PCPs were offered the AMIE transcript, but 27% did not review it; lack of stratified or randomized exposure prevents causal inference on clinician behavior or outcomes.
- Limited sample size (N=98 analyzed) and single academic site: underpowered for safety or subgroup analyses; external validity to community settings, multi-site health systems, and different payer/regulatory contexts is unknown.
- Restricted population and access requirements: English-only, established patients with portal access, non-phone device requirement, exclusion of pregnancy and mental health complaints; generalizability to LEP patients, mobile-only users, pediatrics, pregnancy, and behavioral health is unknown.
- Urgent care, single-complaint scope: performance for routine primary care, chronic disease management, complex multi-issue visits, and higher-acuity/ED settings remains untested.
- Real-time human supervision and debriefing: zero safety stops occurred under active physician monitoring and post-chat correction; safety, error rates, and patient understanding without live supervision are unknown, as are staffing burden, cost, and scalability.
- Unmeasured operational burden: no data on chat duration, number of turns, latency experienced by patients, clinician reading time, or net time saved/added to clinic workflow.
- Model swap mid-study (Gemini 2.5 Pro to 2.5 Flash): no pre/post stratified analysis of performance, safety, or user experience; confounding from model change and compute constraints unaddressed.
- No EHR integration: AMIE reasoned only from patient chat; impact of adding EHR/labs/imaging or past history is unknown; fairness of comparing AMIE (chat-only) to PCPs (full EHR access) is unclear.
- Diagnostic reference standard limitations: “final diagnoses” at 8 weeks were often presumptive; the proportion confirmed by objective tests was limited; potential misclassification biases top-k accuracy estimates.
- Documentation bias for PCP differentials: PCP reasoning extracted from charts may underrepresent full differential; the comparability to AMIE’s explicitly enumerated differential is uncertain.
- Blinding validity not reported: effectiveness of provenance blinding (and rater guessing accuracy) for DDx/Mx evaluations was not presented; potential residual bias remains.
- LLM-based reformatting for blinding: transforming PCP/AMIE outputs with an LLM can alter meaning; only a subset was manually audited; full semantic fidelity is uncertain.
- Evaluation of a management plan never shown to users: AMIE’s Mx plans were rated but not used in care; ecological validity of Mx quality assessments is limited.
- Limited safety quantification: beyond zero “stops,” the frequency and types of AMIE errors, near-misses, misinformation, and red-flag detection/triage performance were not systematically measured.
- No patient comprehension checks: whether patients understood tentative framing, uncertainties, and contingency advice (and avoided harmful self-management) was not assessed.
- Automation/anchoring bias unmeasured: potential effects of AMIE output on clinician diagnostic anchoring, test ordering, and overuse/underuse were not evaluated.
- Resource utilization and costs: no measurement of downstream testing, referrals, imaging, visits, total cost of care, or return-on-investment (including supervision and compute costs).
- Longitudinal outcomes absent: no effects on symptom resolution, complications, revisits, adherence, or longer-term attitudes toward AI beyond immediate post-visit measures.
- Equity and accessibility: impact on digital divide, non-English and low-literacy populations, disability access (screen readers, plain language), and mobile-first workflows remains untested.
- Subgroup performance: no analysis by age, gender, race/ethnicity, health/tech literacy, prior chatbot use, complaint category, or modality (telehealth vs in-person).
- Complaint-specific performance: no breakdown of DDx/Mx performance by presenting complaint (e.g., respiratory vs musculoskeletal vs dermatologic), where error profiles and safety risks differ.
- Triage boundary conditions: patients were pre-triaged as non-emergent; the system’s ability to detect and escalate true emergencies or subtle red flags remains unquantified.
- Temporal drift and knowledge currency: model knowledge cutoff (Jan 2025) and multi-month study period raise guideline-update risks; no process for maintaining clinical currency was studied.
- Inter-rater reliability not reported: kappa/ICC for clinical evaluators and Bond/Graber ratings were not provided, limiting confidence in rating stability.
- PCP type differences unexamined: no subgroup comparisons among attendings, residents, and NPs; supervision structures could influence quality and comparators.
- Visit efficiency not objectively measured: no data on visit length, documentation burden, inbox messaging volume, or burnout proxies; PCP “preparedness” is self-reported and subject to response bias (61% response rate).
- Patient recruitment and attrition biases: high exclusion/attrition and tech requirements may select for more tech-comfortable patients; representativeness to the clinic’s urgent care population is limited.
- Evolving symptoms between chat and visit (0–5 days): no analysis of how symptom progression or resolution attenuates the utility or accuracy of pre-visit conversations.
- Legal, regulatory, and liability questions: responsibilities for errors, informed consent at scale, documentation norms, medicolegal governance, and auditability are not addressed.
- Security and privacy at scale: reliance on manual PHI redaction for analysis is not scalable; risks and tooling for automated de-identification and secure sharing need evaluation.
- Guardrails and red-teaming: safety guardrails, prompt defenses, and adversarial testing (including mental health and self-harm scenarios) are not detailed for real-world deployment.
- Reproducibility and transparency: prompts, state logic, and agent design are not released; portability to other LLMs and health systems is untested.
- Infrastructure robustness: five sessions failed due to system issues; reliability engineering targets (uptime, failover, latency SLOs) and patient experience impacts were not quantified.
- Impact on clinician–patient relationship: effects on trust, rapport, shared decision-making, and perceived empathy (beyond immediate patient satisfaction scales) remain unclear.
- Scope expansion: handling multi-language, multimodal inputs (images, waveforms), and integration into different care pathways (pre-op, specialty intake, chronic care) remains to be explored.
Practical Applications
Immediate Applications
Below are specific, deployable use cases that leverage the study’s demonstrated feasibility, safety oversight protocol, and patient/clinician acceptability. Each item notes sectors, potential tools/workflows, and key dependencies.
- Pre-visit conversational intake and summarization for urgent care and primary care
- Sectors: healthcare, software (EHR), telehealth
- What: Deploy an AMIE-like chat in patient portals to collect structured histories pre-appointment, generate a concise summary plus patient-friendly “possible diagnoses to discuss,” and deliver transcripts to clinicians.
- Tools/workflows: Patient portal widget; five-phase dialogue agent; automatic summary and DDx handoff to EHR inbox or pre-visit note; clinician review step.
- Dependencies/assumptions: IRB/ethics or institutional approval; clinician-in-the-loop; English-only performance (per study); data privacy compliance (HIPAA); model quality comparable to Gemini 2.5 with Thinking mode.
- Visit preparedness coaching for patients
- Sectors: healthcare, patient education
- What: Provide tentative condition explanations and “questions to ask your clinician,” increasing patient preparedness and confidence without giving directive treatment advice.
- Tools/workflows: Patient-friendly modules integrated into the chat’s Deliver Assessment and Wrap-up phases; disclaimers; links to approved educational resources.
- Dependencies/assumptions: Clear disclaimers and guardrails; readability alignment; localization and health literacy tuning.
- Clinician efficiency support via pre-visit summaries
- Sectors: healthcare, EHR vendors
- What: Pre-visit summaries (HPI, pertinent positives/negatives) inserted into the EHR to reduce documentation burden and accelerate first minutes of the visit.
- Tools/workflows: FHIR-based import of structured note; provider inbox routing; flagging unresolved information gaps.
- Dependencies/assumptions: EHR integration; medico-legal policies clarifying authorship and attestation; acceptance by clinicians; monitoring for hallucination correction.
- Safety-supervised deployment playbook for patient-facing AI
- Sectors: healthcare, policy, compliance, AI ops
- What: Implement the study’s real-time human supervisor model and explicit stop criteria during early rollouts to mitigate risk.
- Tools/workflows: Supervisor console with screen-share, event logging; predefined stop reasons; post-chat debrief template; escalation procedures.
- Dependencies/assumptions: Staffing for supervision; training and calibration; incident logging and QA; budget for oversight.
- Prospective evaluation framework for AI-in-the-loop clinical tools
- Sectors: academia, health systems, regulators
- What: Reuse the protocol elements (pre-registration, IRB approval, GAAIS and patient communication rubrics, blinded comparative DDx/Mx rating) for hospital pilots and academic studies.
- Tools/workflows: REDCap-based surveys; blinded LLM-assisted transformation for evaluator rating; TRIPOD-LLM-aligned reporting.
- Dependencies/assumptions: Access to evaluators; data de-identification procedures; institutional permission.
- Blinded comparative assessment of AI vs. clinicians for diagnostic and management quality
- Sectors: academia, quality improvement, AI vendors
- What: Use the paper’s blinded, randomized rater design—with LLM-based normalization of outputs—to reduce provenance bias when comparing AI and clinician artifacts.
- Tools/workflows: Automated reformatting into standardized DDx/Mx templates; multi-rater panels; Bond/Graber scoring where applicable.
- Dependencies/assumptions: Careful auditing to preserve semantic integrity; rater training; secure data handling.
- Tooling to monitor and improve patient attitudes toward AI
- Sectors: healthcare, UX research, policy
- What: Routine collection of GAAIS pre/post interaction to track sentiment shifts and detect subgroups needing extra support.
- Tools/workflows: Embedded micro-surveys in patient portal; dashboards for QI teams; opt-in feedback loops.
- Dependencies/assumptions: Patient consent; minimal survey burden; analytics governance.
- Latency/cost-aware model orchestration for clinical chat
- Sectors: software/AI infrastructure, health IT
- What: Dynamically switch between model variants (e.g., Pro ↔ Flash) to meet clinic throughput and cost targets without significant quality loss.
- Tools/workflows: Policy-based routing; performance monitoring; fallbacks with alerts to supervisors.
- Dependencies/assumptions: Benchmarking across variants for safety/quality; vendor SLAs; capacity planning.
- Secure de-identification and data transfer workflows for AI studies
- Sectors: healthcare IT, research ops
- What: Adopt the paper’s Safe Harbor de-identification with manual auditing for cross-institution AI evaluation.
- Tools/workflows: De-ID pipelines; audit checklists; secure buckets; data use agreements.
- Dependencies/assumptions: Staff training; tooling to catch residual PHI; legal approvals.
- Resident education and OSCE-style practice with simulated patients
- Sectors: medical education
- What: Use the five-phase AMIE structure for simulated clinical dialogue practice, differential generation, and feedback.
- Tools/workflows: Simulation platform; iterative dialogues with state-aware reasoning; rubric-based scoring (GMCPQ/PACES/PCCBP).
- Dependencies/assumptions: Alignment with curricula; faculty oversight; guardrails to prevent misuse as a “cheat tool.”
Long-Term Applications
These applications require further research, scaling, regulatory clarity, broader populations, or deeper integration than demonstrated.
- Autonomous or semi-autonomous pre-triage for urgent care and telehealth
- Sectors: healthcare, telehealth operations
- What: AI conducts initial triage, schedules appropriate visit types, and flags red-flag symptoms for expedited care.
- Tools/workflows: Risk-stratification engine; integration with scheduling; real-time escalation to nurses or physicians.
- Dependencies/assumptions: Prospective safety/outcomes trials; liability frameworks; coverage/payer acceptance; robust emergency detection.
- AI-assisted management planning with cost- and practicality-aware recommendations
- Sectors: healthcare, payers, decision support
- What: Co-develop Mx plans that incorporate local formularies, costs, and practicality—addressing the study’s finding that clinicians outperformed AI on these dimensions.
- Tools/workflows: Payer formulary APIs; care pathway libraries; region-specific resource constraints; shared decision-making modules.
- Dependencies/assumptions: Up-to-date cost and coverage data; explainability; regular clinical governance reviews.
- Fully integrated EHR copilot for history, DDx, orders, and follow-up
- Sectors: healthcare, EHR vendors
- What: A longitudinal agent that drafts HPI, suggests DDx, recommends orders, and creates follow-up tasks, with clinician approval gates.
- Tools/workflows: CDS hooks, order set drafts, inbox tasking, reconciliation UI; audit logs.
- Dependencies/assumptions: Vendor integration; regulatory clearance as clinical decision support; robust guardrails; human verification.
- Multilingual and multimodal conversational diagnostics
- Sectors: healthcare access, global health, AI research
- What: Extend to non-English languages and multimodal inputs (photos, PDFs of prior labs, vitals), addressing broader patient populations and specialties.
- Tools/workflows: Translation with medical accuracy safeguards; image and document reasoning; bias and fairness audits.
- Dependencies/assumptions: Validation across languages and cultures; new safety benchmarks; privacy for images/documents.
- Mental health and pregnancy-inclusive pathways with specialized guardrails
- Sectors: healthcare, women’s health, behavioral health
- What: Extend safely into previously excluded domains with specialized red-flag detection, crisis pathways, and referrals.
- Tools/workflows: Tailored triage logic; integration with crisis lines; perinatal care workflows.
- Dependencies/assumptions: Domain-specific trials; heightened safety oversight; approvals from specialty societies.
- Continuous post-deployment safety monitoring with supervisor-on-demand
- Sectors: health systems, regulators, AI ops
- What: Transition from full-time supervision to adaptive oversight triggered by risk signals (e.g., uncertainty spikes, sensitive topics).
- Tools/workflows: Real-time risk scoring, automatic alerts, sampling audits, incident reporting systems.
- Dependencies/assumptions: Reliable uncertainty estimation; calibrated detectors for risky advice; clear escalation protocols.
- Population health and care navigation at scale
- Sectors: health systems, payers, public health
- What: Proactive outreach for symptom checks, chronic disease check-ins, and care gap closure leveraging conversational AI.
- Tools/workflows: Campaign orchestration; registries; integration with care management teams; multilingual scripts.
- Dependencies/assumptions: Consent for outreach; equity and access safeguards; avoidance of overburdening clinicians.
- Regulatory templates and policy frameworks for patient-facing diagnostic AI
- Sectors: policy/regulation, standards bodies
- What: Use the study’s protocol elements to inform guardrails, documentation standards (e.g., TRIPOD-LLM), and phased rollout policies.
- Tools/workflows: Reference safety criteria, reporting checklists, provenance-agnostic evaluation methods, informed consent templates.
- Dependencies/assumptions: Cross-stakeholder consensus; harmonization with FDA/EMA guidance and local laws.
- Economic evaluation and reimbursement models for AI-augmented visits
- Sectors: finance, payers, health economics
- What: Design and validate payment models for pre-visit AI intake that reduces visit time, improves throughput, or outcomes.
- Tools/workflows: Time-and-motion studies; cost-effectiveness analyses; value-based care alignment; CPT/HCPCS pathways.
- Dependencies/assumptions: Demonstrated ROI; payer adoption; safeguards against overutilization.
- Developer tools for transparent diagnostic reasoning and calibration
- Sectors: AI tooling, research
- What: Productize extraction of intermediate differentials and confidence over turns to audit, debug, and calibrate reasoning.
- Tools/workflows: Turn-by-turn differential visualizer; auto-raters for Bond/Graber; dataset generation for RLHF and safety tuning.
- Dependencies/assumptions: Stable APIs for thinking traces; privacy-preserving logs; human oversight of model updates.
- Equity-focused deployments to reduce digital divide
- Sectors: public health, health systems
- What: Mobile-first, low-bandwidth versions and community-assisted kiosks to reach populations without desktops or high tech literacy.
- Tools/workflows: Simplified UI; voice options; community health worker facilitation.
- Dependencies/assumptions: Accessibility testing; multilingual support; partnerships with community organizations.
- Cross-specialty extensions and referral optimization
- Sectors: healthcare, specialty clinics
- What: Use AI to prepare patients for specialty visits and improve referral quality (e.g., dermatology, cardiology), reducing cycle time to diagnosis.
- Tools/workflows: Specialty-specific intake checklists; attachment of structured summaries to referrals; pre-visit patient education.
- Dependencies/assumptions: Specialty validation; pathway alignment; data-sharing agreements.
- Federated learning and privacy-preserving improvement loops
- Sectors: AI research, health IT
- What: Improve models from distributed clinic data without centralizing PHI, maintaining safety and performance across sites.
- Tools/workflows: Federated/fine-tuning pipelines; differential privacy; site-level evaluations.
- Dependencies/assumptions: Technical maturity; governance agreements; consistent evaluation metrics.
Notes on feasibility and general assumptions across applications:
- Model performance may vary outside the study’s setting, language, and population; additional validation is needed.
- Clear clinician accountability and documentation of AI contributions are essential for medico-legal clarity.
- Robust governance—incident reporting, drift monitoring, and periodic audits—is required for sustained safety.
- Infrastructure, cost, and workflow change management will determine real-world adoption and ROI.
Glossary
- Agentic system: An AI setup that operates as an autonomous agent with structured prompts and phases to pursue goals. "aligned the prompts and conversation phases of this agentic system"
- AI supervisor: A human clinician monitoring live AI–patient chats with authority to intervene for safety. "the AI supervisor was instructed to intervene and interrupt the chat if it met any of the following pre-defined stop criteria"
- Ambulatory primary care clinic: An outpatient clinic providing non-hospitalized primary care services. "in an ambulatory primary care clinic"
- Auto-rater: An automated model used to evaluate outputs (e.g., diagnostic hypotheses) programmatically. "a Gemini 2.5 Pro-based auto-rater was used to assess the correctness"
- Binomial proportions: Proportions of successes in binary outcomes, often used for accuracy and preference rates. "error bars were computed using 95\% confidence intervals for binomial proportions."
- Blinded assessment: Evaluation where reviewers are unaware of the source (e.g., AI vs. clinician) to reduce bias. "Blinded assessment of AMIE and PCP DDx and management (Mx) plans suggested similar overall DDx and Mx plan quality"
- Blinding procedure: Methods to mask provenance or identifying details to ensure blinded evaluation. "a blinding procedure was used to transform management plans and differential diagnosis"
- Bond/Graber scale: A 5‑point rubric for rating the quality of a differential diagnosis. "rating of AMIE's differential diagnoses on the Bond/Graber scale"
- Bonferroni correction: A multiple-comparison adjustment that lowers the significance threshold to control family-wise error. "with Bonferroni correction"
- Chart review: Retrospective examination of patient records to establish outcomes or ground truth. "per chart review 8 weeks post-encounter"
- ClinicalTrials.gov: A registry for clinical studies providing protocol and identifier details. "pre-registered on ClinicalTrials.gov (NCT06911398)."
- Confidence intervals: Ranges that likely contain the true value of an estimate with a specified confidence level. "error bars were computed using 95\% confidence intervals for binomial proportions."
- CONSORT diagram: A standardized flowchart describing participant progression through a study. "The CONSORT diagram provides statistics regarding the flow of patient participants through our study (A)."
- Differential: The evolving list of candidate diagnoses being considered. "the differential and predicted probability for each diagnosis were extracted."
- Differential diagnosis (DDx): A ranked list of possible conditions explaining a patient’s presentation. "AMIE's differential diagnosis (DDx) included the final diagnosis"
- Diagnostic validation: A focused phase to confirm or refute provisional diagnostic hypotheses. "Diagnostic Validation."
- EHR (Electronic Health Record): Digital patient record used for clinical documentation and data review. "electronic health record (EHR)"
- EKG: A test recording the heart’s electrical activity to aid diagnosis. "imaging, microbiology, laboratory, pathology, EKG"
- Friedman omnibus test: A nonparametric test for comparing related groups across multiple conditions. "We used Friedman omnibus tests followed by pairwise two-sided Wilcoxon post-hoc tests"
- General Attitudes towards AI Scale (GAAIS): A survey instrument measuring perceptions of AI’s utility and concerns. "measured using the General Attitudes towards AI Scale (GAAIS)"
- General Medical Counsel Patient Questionnaire (GMCPQ): A rubric for patient-reported consultation quality. "the complete General Medical Counsel Patient Questionnaire (GMCPQ)"
- HIPAA authorization: Consent under U.S. law permitting use or disclosure of protected health information. "provided written informed consent and HIPAA authorization electronically via REDCap"
- Human-in-the-loop workflows: Processes where humans oversee or collaborate with AI during operation. "real human-in-the-loop workflows with PCPs"
- Internal state: The model’s maintained memory of summaries, hypotheses, and plans during a dialogue. "continuously maintains a rich internal state"
- IRB (Institutional Review Board): An ethics committee that reviews and approves research involving humans. "Due to institutional IRB constraints, we excluded patients with known pregnancy."
- Likert scale: An ordinal response scale (e.g., 1–5) for measuring attitudes or ratings. "individually on a 5-point Likert scale."
- Longitudinal disease management: Ongoing care and reasoning across multiple patient visits over time. "longitudinal disease management across multiple visits"
- Management plan (Mx): The proposed diagnostic tests, treatments, and follow-up steps for patient care. "management (Mx) plans"
- Multimodal artifacts of care: Clinical inputs beyond text (e.g., images, labs) used in reasoning. "encounters requiring clinical reasoning over multimodal artifacts of care"
- Objective Structured Clinical Examinations (OSCEs): Standardized, station-based clinical assessments using trained actors. "Objective Structured Clinical Examinations (OSCEs)"
- P-value: The probability of observing data at least as extreme as seen, assuming the null hypothesis is true. "p < 0.001"
- PACES: A clinical skills assessment focusing on communication and patient management. "the Practical Assessment of Clinical Examination Skills (PACES) components for âManaging patient concernsâ and âMaintaining patient welfareâ"
- Patient-Centered Communication Best Practices (PCCBP): A rubric assessing relationship-focused communication quality. "and the Patient-Centered Communication Best Practices (PCCBP) rubric on relationship fostering"
- Pre-registered study: A study whose analysis plan or protocol is publicly registered before data collection. "we conducted a pre-registered prospective feasibility study"
- Prespecified criteria: Predefined rules or thresholds set before analysis or monitoring. "prespecified criteria for safety interruptions"
- Presumptive diagnosis: A working diagnosis made without confirmatory testing. "presumptive (made by PCP without further testing)"
- Primary care provider (PCP): Clinician delivering front-line medical care and coordinating services. "primary care providers (PCPs)"
- Provenance bias: Bias introduced when raters infer the source (e.g., AI vs. human) of material being evaluated. "AI vs. PCP provenance bias"
- REDCap: A secure web platform for research data capture and management. "REDCap (Research Electronic Data Capture) is a secure, web-based software platform"
- Reflexive thematic analysis: A qualitative method where themes are iteratively developed by researchers. "used reflexive thematic analysis to identify overarching themes"
- Safe Harbor criteria: A de-identification standard under HIPAA specifying removal of 18 identifiers. "according to Safe Harbor criteria"
- Self limited: A condition that resolves on its own without specific medical intervention. "self limited"
- Single-arm feasibility study: A study with one intervention group aimed at assessing practicality and safety. "single-arm feasibility study"
- State-aware chain-of-reasoning: A prompting strategy where the model reasons stepwise while tracking evolving state. "a refined state-aware chain-of-reasoning strategy"
- Subspecialist: A physician with advanced specialization within a broader medical specialty. "made on referral to a subspecialist"
- Thinking Mode: A model setting that enables explicit intermediate reasoning traces. "Thinking Mode enabled"
- Top-3 accuracy: Proportion of cases where the correct answer appears among the top three predictions. "with 75\% top-3 accuracy."
- Top-k diagnostic accuracy: Proportion where the true diagnosis appears within the top k ranked candidates. "AMIE's Top-k diagnostic accuracy"
- TRIPOD-LLM: Reporting guidelines adapted for studies involving LLMs. "This study is reported in accordance with the guidelines set forth by TRIPOD-LLM"
- Triage: The process of prioritizing care based on urgency and resource availability. "had already been determined by clinic triage staff not to need emergency care."
- Wilcoxon signed-rank test: A nonparametric paired test comparing two related samples. "two-way Wilcoxon signed-rank tests"
- Wilcoxon post-hoc tests: Follow-up nonparametric comparisons performed after an omnibus test. "Wilcoxon post-hoc tests"
Collections
Sign up for free to add this paper to one or more collections.