Stream-R1: Reliability-Perplexity Aware Reward Distillation for Streaming Video Generation
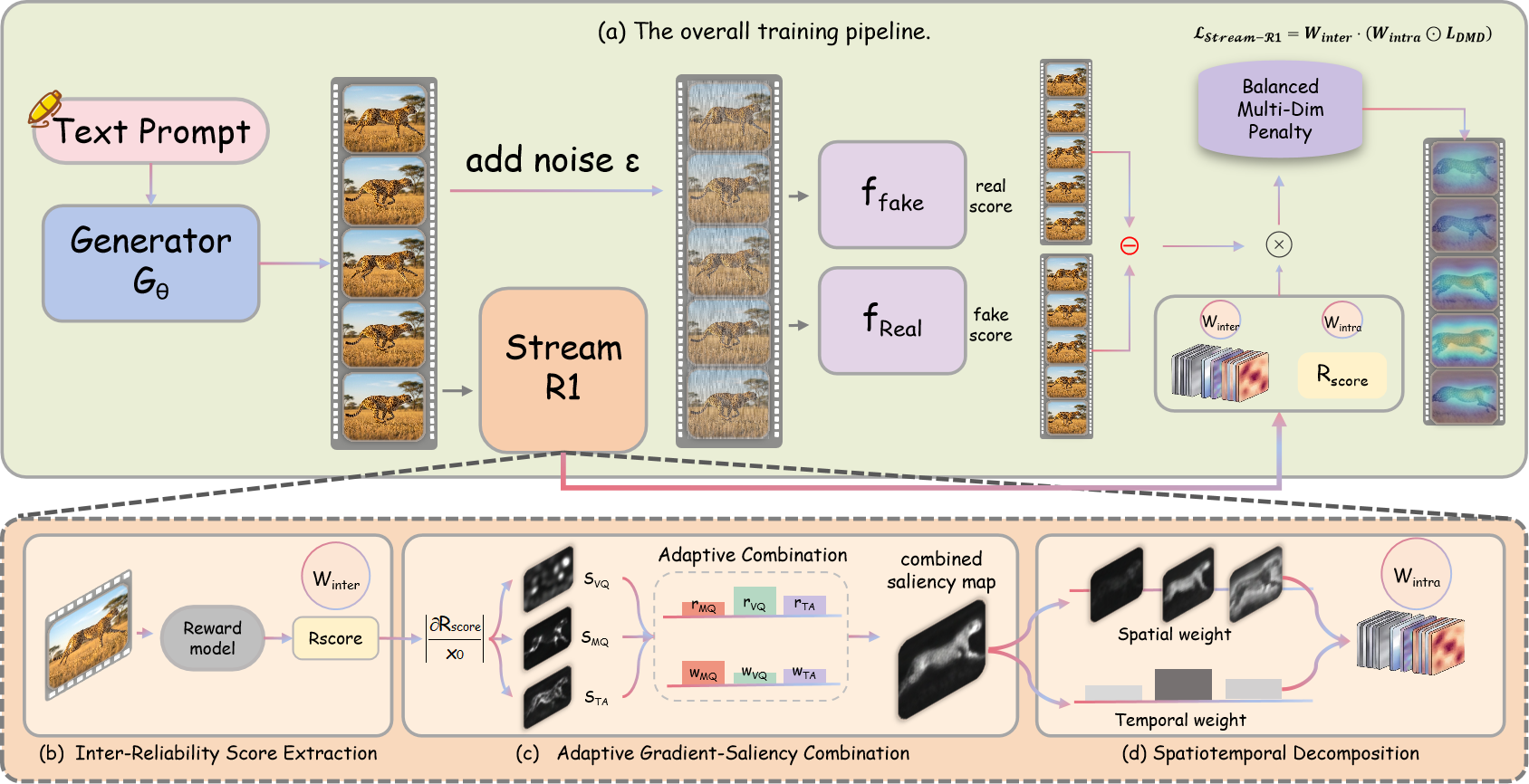
Abstract: Distillation-based acceleration has become foundational for making autoregressive streaming video diffusion models practical, with distribution matching distillation (DMD) as the de facto choice. Existing methods, however, train the student to match the teacher's output indiscriminately, treating every rollout, frame, and pixel as equally reliable supervision. We argue that this caps distilled quality, since it overlooks two complementary axes of variance in DMD supervision: Inter-Reliability across student rollouts whose supervision varies in reliability, and Intra-Perplexity across spatial regions and temporal frames that contribute unequally to where quality can still be improved. The objective thus conflates two questions under a uniform weight: whether to learn from each rollout, and where to concentrate optimization within it. To address this, we propose Stream-R1, a Reliability-Perplexity Aware Reward Distillation framework that adaptively reweights the distillation objective at both rollout and spatiotemporal-element levels through a single shared reward-guided mechanism. At the Inter-Reliability level, Stream-R1 rescales each rollout's loss by an exponential of a pretrained video reward score, so that rollouts with reliable supervision dominate optimization. At the Intra-Perplexity level, it back-propagates the same reward model to extract per-pixel gradient saliency, which is factored into spatial and temporal weights that concentrate optimization pressure on regions and frames where refinement yields the largest expected gain. An adaptive balancing mechanism prevents any single quality axis from dominating across visual quality, motion quality, and text alignment. Stream-R1 attains consistent improvements on all three dimensions over distillation baselines on standard streaming video generation benchmarks, without architectural modification or additional inference cost.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Stream-R1: A simple explanation
What this paper is about
This paper is about teaching an AI to make videos, one frame at a time, quickly and well. The AI starts as a “student” that tries to copy a slower but very high‑quality “teacher.” The usual way of teaching the student is to make it match the teacher everywhere, equally. The authors argue that this “treat everything the same” idea wastes learning. Instead, they propose Stream‑R1, a smarter way to learn that:
- trusts some training examples more than others, and
- focuses effort on the parts of each video that need the most improvement.
The goal is to get better, longer, more stable videos, without slowing the model down.
The key questions the paper asks
The paper boils its idea down to two simple questions:
- Which tries should we trust? (Inter‑Reliability)
- When the student makes a sample video (a “rollout”), sometimes the teacher’s advice for that rollout is helpful and on‑target, and sometimes it isn’t. How can we learn more from the trustworthy tries and less from the misleading ones?
- Where inside each try should we focus? (Intra‑Perplexity)
- Inside a single rollout, some frames or parts of a frame are already good, while other parts are messy or shaky. How can we push the model to work harder on the parts that still need the most fixing?
They also care about three kinds of quality at the same time:
- Visual quality (how good it looks),
- Motion quality (how smooth and consistent movement is), and
- Text alignment (does the video match the prompt).
How the method works (with simple analogies)
Think of training like coaching a sports team:
- The teacher is a star player who shows the right moves (but slowly).
- The student tries to copy those moves (fast).
- A judge watches and gives a score for each attempt, and can also point to exactly where the performance could most improve.
Here’s how Stream‑R1 uses that judge:
- Inter‑Reliability: trusting better attempts more
- For every student‑made video attempt (rollout), a “reward model” (the judge) gives it a score.
- Higher score = the teacher’s advice is more likely to be meaningful for that attempt.
- Stream‑R1 gives more learning weight to higher‑scoring attempts and less weight to lower‑scoring ones.
- Analogy: If a practice drill is clean and close to the right form, the coach’s small corrections are very useful—so we pay more attention to them.
- Intra‑Perplexity: focusing where it matters inside each attempt
- The same judge can tell not just “how good,” but also “what parts matter most.” It does this by creating a saliency map—a kind of heat map that lights up the frames and pixels that most affect the score if they changed a little.
- Stream‑R1 turns this into two kinds of weights:
- Temporal weights: Which frames need more attention?
- Spatial weights: Which regions inside each frame need more attention?
- Analogy: A coach pauses the video and circles the exact moments and body parts that need work, so the player can practice those spots more.
- Balancing the three goals (look, motion, and following the prompt)
- The judge gives three separate scores: visual quality, motion quality, and text alignment.
- Stream‑R1 automatically gives extra focus to whichever score is currently worst, so the model improves evenly instead of over‑fixating on just one thing (like looks) and ignoring the others (like motion).
- Analogy: If your footwork is behind your dribbling and shooting, the coach spends more time on footwork until it catches up.
- No slowdown at test time
- All this “smart weighting” happens only while training. When you ask the model to generate a video, it’s just as fast as before.
What they found and why it matters
On standard tests, Stream‑R1 beat strong baselines:
- Short videos (5 seconds): It scored higher overall than the previous best distillation method (Reward Forcing), and even slightly beat its own slow teacher on some scores—while running about 30× faster.
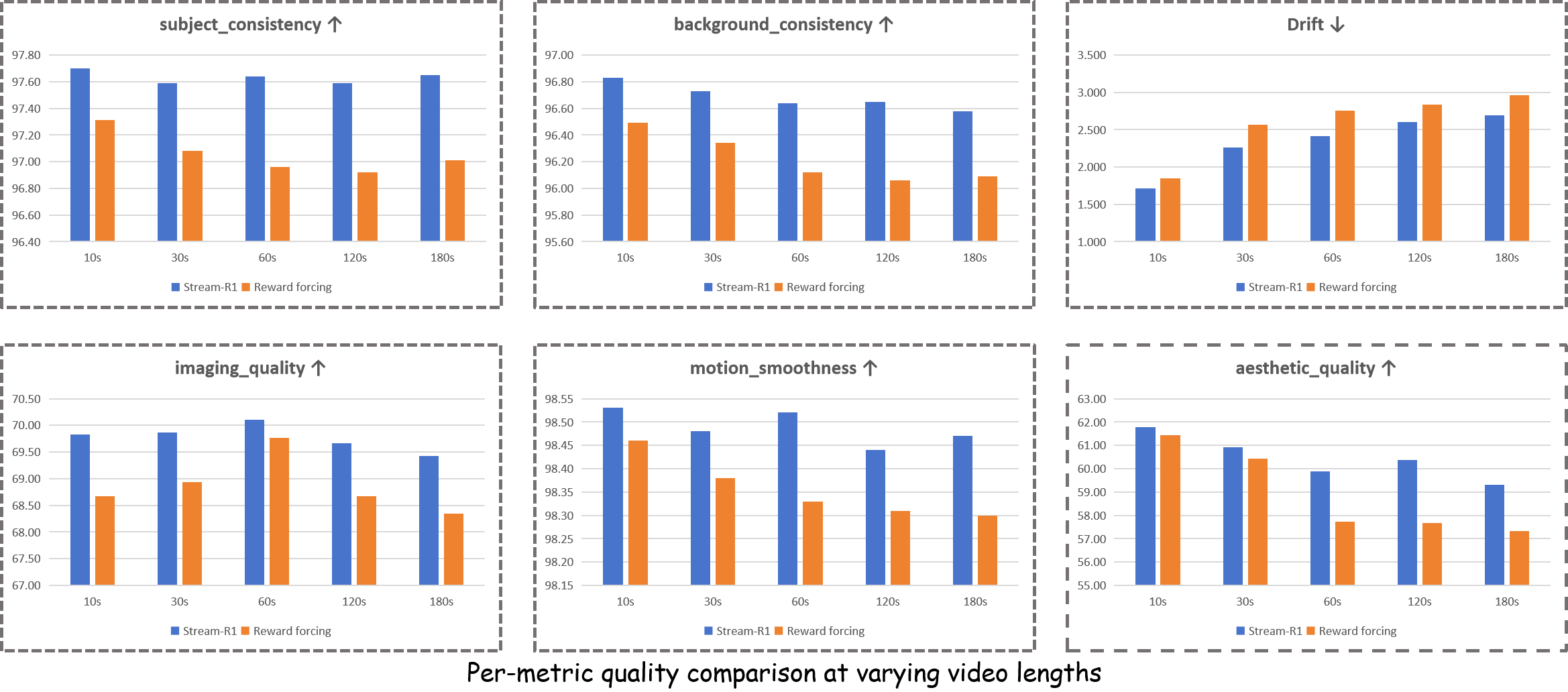
- Long videos (up to 3 minutes): Quality stayed higher for longer. Stream‑R1’s advantage grew as videos got longer, meaning it better resists problems that build up over time (like flicker, drift, or deformations).
- Human studies: People preferred Stream‑R1’s videos for motion reasonableness, visual quality, and overall choice.
Why this is important:
- It shows that “where you put your learning effort” matters a lot.
- It also shows you can sometimes make a fast student not just match, but even edge past, its slow teacher when you guide learning with good feedback.
What this could change in the future
- Better streaming video generators: more stable, longer, and more faithful to the prompt, without extra runtime cost.
- A general recipe for training: use a reward model both to pick which attempts to learn from and to point to exactly where to improve.
- This idea—“trust the good tries, focus on the weak spots”—could help other AI generators too (images, audio, text), whenever we have a reliable scoring model.
In short, Stream‑R1 is like having a smart coach: it knows which practice runs are worth studying, and it highlights the exact moments and places to fix. That extra guidance leads to sharper, steadier videos, especially as they get longer.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what remains missing, uncertain, or unexplored, along with concrete directions future work could act on:
- Unvalidated proxy for “reliability”: The method assumes higher scalar reward implies more reliable DMD supervision. No analysis quantifies correlation between rollout reward and (i) the alignment/angle of the DMD gradient
gwith the teacher’s “high-quality mode” direction, (ii) actual post-update quality improvement. Measure gradient–update efficacy (e.g., cosine similarity ofgto a teacher/likelihood gradient proxy) and the expected reward gain per training step across reward strata. - Reward-model calibration and bias: The pretrained video reward’s calibration, domain coverage, and bias are unknown. Systematically stress-test with out-of-distribution prompts, complex compositions, rare motions, and diverse styles; report per-category performance and fairness/bias analyses.
- Reward hacking risk: No evidence the student is not exploiting reward model artifacts (e.g., textures or motion patterns that inflate scores but harm human-perceived quality). Evaluate cross-reward generalization (optimize with R1, test on multiple independent reward models), adversarial prompt suites, and blinded large-scale human studies to detect reward overfitting.
- Saliency reliability as “perplexity”: The use of reward input gradients as a proxy for “improvement potential” is unproven. Validate with controlled edits by applying updates restricted to high-saliency vs. low-saliency regions and measuring differential reward/human gains; compare gradient saliency against occlusion-based maps, SmoothGrad, Integrated Gradients, Grad-CAM, and input×gradient.
- Pixel-space vs. latent-space mismatch: Saliency is computed in pixel space while DMD supervision operates on latents. Assess whether pixel-space saliency faithfully localizes regions where latent-space updates most improve reward; consider computing saliency in latent space or projecting pixel saliency into latent coordinates.
- Training-time overhead and scalability: The paper claims negligible overhead but provides no detailed profiling. Quantify added compute/memory from reward backprop per step as a function of frames, resolution, and reward heads; assess scalability to higher resolutions/longer clips and budget-constrained training.
- Hyperparameter sensitivity and robustness: Only limited sensitivity is reported (e.g.,
τ_min,σ_min). Provide broader sweeps and stability analysis forβ(exponential weight),τ(softmax temperature), sliding-window sizeN, balance weightλ, normalization choices, and saliency smoothing; offer transferability studies across datasets/teachers. - Stability of exponential inter-weighting: Exponential reweighting can amplify outliers and destabilize optimization. Investigate robust alternatives (e.g., clipped/logistic weights, winsorization), per-batch normalization, or adaptive temperature schedules; analyze gradient variance and training instability cases.
- Interaction with DMD critics (
f_real,f_fake): The method reweights generator updates but does not analyze how this affects training/calibration off_fakeor the overall min–max dynamics. Study convergence, critic over/underfitting, and potential mode bias under reweighting. - Conflict between inter- and intra-weights: No analysis of cases where a rollout gets downweighted (low inter-reliability) but contains highly salient local regions (high intra-perplexity). Explore tie-breaking strategies, hierarchical curricula, or decoupled weighting policies for these conflicts.
- Theoretical grounding: The paper motivates that reward gradient magnitude tracks non-flat reward regions but provides no theory. Develop conditions under which |∂R/∂x| predicts expected improvement in multi-objective, non-convex settings; analyze how saliency-guided weighting approximates a principled multi-objective optimization (e.g., Pareto front).
- Multi-objective balancing: The balance mechanism (softmax saliency mixing + std-penalty across VQ/MQ/TA) is heuristic. Compare to principled multi-objective optimizers (e.g., PCGrad, Pareto front solvers), adaptive scalarizations, or constrained optimization; quantify trade-offs and dominance relations across axes.
- Generality across models and tasks: Results are on Wan2.1 (1.3B student, 14B teacher) and a specific streaming stack. Test across: different teachers/students (scales, architectures), distillation variants (DMD2, self/rolling forcing), and tasks (image generation, controllable video, 3D/360° video).
- Long-horizon streaming: Evaluations up to 180s leave uncertainty about truly unbounded streaming. Benchmark hour-scale generation, scene changes, and memory recaching regimes; quantify cumulative drift, identity persistence, and background stability over very long timelines.
- Diversity vs. quality: Upweighting high-reward rollouts may narrow the distribution. Measure intra-prompt diversity (LPIPS, FVD across seeds), mode coverage, and semantic diversity; study diversity–quality trade-offs under different weighting strengths.
- Compositional/text alignment stress tests: VBench/Qwen-VL may not fully probe compositional prompts (multi-entity interactions, temporal constraints). Evaluate on compositional T2V benchmarks and human-authored complex narratives; report per-attribute success rates.
- Human evaluation scale and rigor: The human study (50 videos, 5 annotators) is small and lacks significance testing. Expand to larger, stratified samples with calibrated rubrics, confidence intervals, inter-rater reliability, and preregistered protocols.
- Alternative reliability estimators: Using reward as reliability may misalign with teacher modes. Explore uncertainty-aware measures (teacher ensembles, dropout variance, disagreement between
f_real/f_fake, teacher consistency under augmentations) and compare predictive power for “useful DMD gradients.” - Curriculum effects and hard-case neglect: Inter-weighting may under-train low-reward (hard) rollouts. Investigate curricula that gradually increase weights for hard cases, or dual-objectives ensuring minimum coverage of difficult prompts.
- Weight normalization design: The chosen per-frame spatial normalization and multiplicative spatiotemporal composition are not compared to additive or attention-like formulations. Ablate normalization schemes, smoothing, and per-scale saliency pooling.
- Black-box/non-differentiable rewards: The approach requires differentiable reward models. Explore approximations for black-box rewards (finite-difference saliency, learned saliency predictors), sample efficiency, and the impact on training variance.
- Beyond teacher quality frontier: The student surpasses the teacher on some metrics, indicating distribution shift. Analyze failure modes, robustness to domain transfer, and whether improvements persist under alternative evaluators and large-scale human judgments.
- Safety and content governance: No analysis of safety, toxicity, or misuse. Incorporate safety rewards, red-teaming, and sensitive content filters; report safety alignment metrics alongside quality.
- Reproducibility and disclosure: Important details are missing/implicit (exact reward model(s), dataset filtering specifics, code and seeds, prompt lists). Release code, reward checkpoints, standardized evaluation scripts, and full prompt splits for transparent replication.
- Evaluation metrics breadth: FVD, IS, CLIPScore, motion/identity retention benchmarks, and per-attribute failure rates are absent. Add a broader metric suite and report statistical significance.
- Parameter-efficiency and data-efficiency: Only 1,000 optimizer steps were used; the learning curve, data efficiency, and scaling laws remain unknown. Study performance vs. training steps, dataset size, and teacher/student scale.
- Extension to conditional controls: It’s unclear how Stream-R1 interacts with explicit controls (pose, depth, camera path). Evaluate whether saliency conflicts with control fidelity and adapt weighting to respect hard constraints.
Practical Applications
Immediate Applications
Below are actionable use cases that can be deployed with current tooling, leveraging the paper’s reliability-perplexity aware reward distillation and its “no architectural change, no inference overhead” property.
- Industry — Media/Entertainment: Real-time prompt-to-video generation for ads, trailers, and B‑roll
- Description: Use the 4-step student (≈30× faster than the teacher) to produce short-to-minute-long, higher-quality, more temporally stable videos for marketing and post-production pipelines.
- Potential products/workflows: “Stream-R1 Distilled Video API,” batch creative A/B generation, real-time preview in NLEs, generative B‑roll for virtual production backdrops.
- Dependencies/assumptions: Access to a reliable, differentiable video reward model (VQ/MQ/TA); teacher–student setup; current quality validated at ≈832×480 (scaling to 1080p+ may require engineering).
- Industry — Gaming/Interactive Media: In-engine streaming video assets and cutscenes
- Description: Generate temporally coherent cutscenes, environmental loops, and dynamic backgrounds on demand with fewer artifacts/drift over long rollouts.
- Potential products/workflows: Unity/Unreal plugins for on-the-fly video assets; dynamic NPC vignette generation; generative loading screens.
- Dependencies/assumptions: GPU availability for real-time; integration with chunked/streaming attention; reward model generalizes to game art styles.
- Industry — Social/Live Platforms: Generative overlays and live enhancement
- Description: Apply stable, reward-guided streaming generation for live shows and creator tools (e.g., generative lower-thirds, animated stickers, dynamic backgrounds) with improved motion smoothness and reduced drift.
- Potential products/workflows: Live OBS plugin; creator mobile app features; server-side overlay compositor.
- Dependencies/assumptions: Low-latency inference hardware; content safety guardrails (can be added as an additional reward axis over time).
- Industry — Post-production/Editing: Region- and frame-aware repair and refinement
- Description: Use reward gradient saliency maps to detect and selectively improve degraded regions/frames (blur, flicker, deformations), minimizing unnecessary re-renders.
- Potential products/workflows: “Reward Heatmap” panel and selective re-synthesis in Adobe Premiere/DaVinci Resolve; QC passes that auto-flag high-perplexity segments.
- Dependencies/assumptions: Backprop access to reward model; efficient round-tripping between editor and generator; saliency stability across content types.
- Industry/ML Ops — Faster, more robust distillation training
- Description: Plug the Inter-Reliability reweighting into existing DMD pipelines to bias training toward reliable rollouts; use spatiotemporal weighting to concentrate gradients where they matter.
- Potential products/workflows: “Stream-R1 Trainer” for Diffusers/Lightning; curriculum scheduling based on rollout reliability; compute-efficient training with better convergence.
- Dependencies/assumptions: Reward model scores correlate with supervision reliability; tolerant training infra for an extra reward backprop pass per step.
- Academia — Diagnostics and benchmarking for streaming models
- Description: Use reward saliency to analyze failure modes (where and when quality collapses), create drift-centric benchmarks, and compare training strategies.
- Potential tools/workflows: Saliency-based drift curves; per-axis (VQ/MQ/TA) improvement dashboards; ablations on temporal floors and temperature.
- Dependencies/assumptions: Agreement between reward scores and human preferences; reproducible evaluation prompts (e.g., VBench, MovieGen Video Bench).
- Platforms/Policy — Quality gating and procurement criteria
- Description: Deploy multi-axis reward thresholds to automatically gate low-quality or misaligned outputs before distribution; include balanced multi-dimensional reward reporting in vendor evaluations.
- Potential tools/workflows: Pre-publish QA filters; scorecards requiring per-axis VQ/MQ/TA metrics and balance penalties.
- Dependencies/assumptions: Calibrated thresholds; clear disclosure of reward models and known biases.
- Education/Creativity — Creator apps for smooth explainer clips and lessons
- Description: Produce more consistent, longer educational clips (e.g., science demonstrations, language-learning visuals) on consumer GPUs with better motion coherence.
- Potential tools/workflows: Desktop/mobile generative video apps; lesson plan templating with prompt libraries.
- Dependencies/assumptions: Hardware constraints on-device; prompt quality; appropriate content filtering.
Long-Term Applications
The following rely on additional research, scaling, or ecosystem development (e.g., reward models, high-res training, cross-modal generalization).
- Cross-modal generalization: Streaming audio, TTS, motion capture, and robotics policies
- Description: Extend reliability-perplexity guided distillation to other autoregressive domains (speech/music generation, humanoid motion synthesis, robot action streams), using domain-specific reward models.
- Potential products/workflows: Real-time voice/video co-generation with saliency-driven refinement; robot policy distillation emphasizing safety-critical timesteps.
- Dependencies/assumptions: High-quality, differentiable reward models for each modality; safe backprop interfaces; rigorous sim-to-real validation (for robotics).
- Safety and alignment as first-class reward axes
- Description: Add content safety, bias mitigation, and IP risk detectors as differentiable or proxy rewards to upweight safe, policy-compliant rollouts and deprioritize problematic regions/frames.
- Potential products/workflows: “Safety-Aware Stream-R1” training; regulated industry presets (education, healthcare marketing); compliance dashboards.
- Dependencies/assumptions: Reliable, differentiable safety signals (or distillable surrogates); low false positive/negative rates; policy co-design.
- Personalized and brand-aligned reward models
- Description: Fine-tune reward models to user/brand aesthetics and tone, steering the same student model toward different style manifolds via reweighting.
- Potential products/workflows: Brand style controllers; user-preference onboarding that adapts weights across VQ/MQ/stylistic alignment.
- Dependencies/assumptions: Preference data collection and privacy guarantees; robust generalization; avoiding mode collapse toward niche styles.
- 4K/60fps+ professional pipelines and tiled/streamed training
- Description: Scale Stream-R1 to high-resolution, high-FPS video via multi-scale saliency, tiling, and memory-aware chunking; preserve temporal stability across tiles/chunks with temporal weighting.
- Potential products/workflows: Broadcast-grade generative assets; premium ad production; cinema previsualization.
- Dependencies/assumptions: Substantial compute and memory optimization; artifact-free tile stitching; high-res teacher availability.
- On-device and edge deployment
- Description: Pair Stream-R1 with quantization/pruning and lightweight reward approximators to enable real-time generation on mobile/AR devices and creator peripherals.
- Potential products/workflows: AR glasses background generation; offline creator tools; edge-rendered dynamic signage.
- Dependencies/assumptions: Ultra-compact students; energy constraints; “reward-lite” saliency approximations without backprop.
- Human-in-the-loop reward shaping and interactive editing
- Description: Let editors “paint” or approve saliency maps to guide reweighting during fine-tuning or selective re-render, combining expert intent with gradient-derived cues.
- Potential products/workflows: NLE co-pilot that suggests/accepts saliency edits; iterative refinement sessions.
- Dependencies/assumptions: UX for interpretable saliency; stable training under partial manual overrides.
- Standardization and auditing of reward models
- Description: Establish common VQ/MQ/TA (and safety) reward benchmarks, documentation standards, and bias audits to ensure comparability and accountability across vendors.
- Potential products/workflows: Open evaluation suites; third-party certification; transparent “reward cards.”
- Dependencies/assumptions: Community coordination; legal/ethical frameworks; availability of high-quality human preference data.
- Active data curation and curriculum at scale
- Description: Use Inter-Reliability to prioritize samples, prompts, and rollouts during data collection and training (e.g., mining high-leverage long-tail cases), reducing compute cost per quality gain.
- Potential products/workflows: Data schedulers that adaptively grow training sets; continual learning with reliability-aware replay.
- Dependencies/assumptions: Stable correlation between reward and downstream generalization; safeguards against reward hacking.
- Automated editing co-pilots for pacing, stabilization, and retiming
- Description: Leverage temporal saliency to drive scene-level adjustments (stabilize shaky segments, retime choppy motion, smooth transitions) with minimal manual intervention.
- Potential products/workflows: “Temporal Doctor” module in NLEs; auto-cut suggestions based on drift forecasts.
- Dependencies/assumptions: Robust temporal saliency for diverse content; integration with non-diffusion editing operations.
- Open-source ecosystem and interoperability
- Description: Cross-framework adapters (e.g., Diffusers, Lightning, vLLM-like reward backends) that make reliability/perplexity weighting a standard toggle in distillation.
- Potential products/workflows: Reference implementations; evaluation harnesses for long-video drift; community challenge benchmarks.
- Dependencies/assumptions: Licensing for reward models; maintainers for multi-backend support; sustained community interest.
These applications are enabled by the paper’s key innovations: rollout-level reliability weighting, spatiotemporal reward-gradient saliency, adaptive multi-axis balancing (VQ/MQ/TA), and the practical advantages of no architectural changes and no inference-time cost. Feasibility hinges on the availability and quality of differentiable reward models, access to teacher–student training setups, and engineering to scale beyond the demonstrated resolution and durations.
Glossary
- Adaptive balancing mechanism: A strategy that dynamically balances multiple quality objectives to avoid over-optimizing any single axis. "An adaptive balancing mechanism further prevents any single quality axis from dominating across visual quality, motion quality, and text alignment."
- Autoregressive diffusion: A formulation of diffusion models that generates frames sequentially, enabling streaming synthesis. "reformulates video generation as autoregressive diffusion, enabling streaming, frame-by-frame synthesis that can in principle extend to arbitrary temporal horizons"
- Autoregressive rollouts: Sequences generated by a model using its own previous outputs as context during training or evaluation. "Self-Forcing trains the student on its own autoregressive rollouts to close the train-test distribution gap"
- Autoregressive streaming video diffusion models: Diffusion-based generators that produce video frames in sequence for potentially unbounded lengths. "Autoregressive streaming video diffusion models have emerged as a promising remedy, converting bidirectional architectures into causal generators that produce frames sequentially"
- Balance penalty: A regularizer that discourages uneven improvement across multiple reward dimensions. "The balance penalty is defined as the standard deviation of improvements across dimensions"
- Block-wise generation: Producing long videos by generating consecutive chunks or blocks autoregressively. "with autoregressive block-wise generation and EMA-Sink attention."
- Causal generators: Models that generate outputs based only on past information, not future context. "converting bidirectional architectures into causal generators that produce frames sequentially"
- Chunk-wise prediction: Predicting video content in chunks to scale autoregressive generation. "adopts chunk-wise prediction for scalable autoregressive generation."
- Conditional denoiser: A denoising network whose corrections depend on the current input rather than globally sampling from the data distribution. "is fundamentally a conditional denoiser: it provides a local correction whose direction is determined by where the input already lies"
- Direct Preference Optimization (DPO): A learning paradigm that optimizes models directly from pairwise human preferences without explicit rewards. "direct preference optimization (DPO) has been extended from LLMs to image and video diffusion models"
- Diffusion forcing: A training technique that integrates diffusion-based supervision to improve generation structure. "integrates diffusion forcing with structural planning for scalable synthesis"
- Distribution matching distillation (DMD): A distillation approach that trains a student to match a teacher’s output distribution, often via KL objectives. "with distribution matching distillation (DMD) emerging as the de facto choice."
- EMA (Exponential Moving Average): A parameter-averaging technique that stabilizes training by smoothing updates over time. "EMA is applied with a decay weight of 0.99 starting from step 200."
- EMA-Sink attention: An attention mechanism variant used for efficient long-range video generation. "with autoregressive block-wise generation and EMA-Sink attention."
- Exponential reweighting: Scaling losses or weights by an exponential function of a score to emphasize higher-scoring samples. "We convert this scalar into a per-sample loss multiplier through an exponential reweighting:"
- Flow matching: A training objective that aligns model trajectories with data flows, often used in generative models. "multi-scale flow matching to reduce the computational burden of long sequences"
- Flow-based dynamics scores: Metrics derived from optical flow or similar signals to quantify motion quality in videos. "flow-based dynamics scores do not distinguish camera motion from subject motion"
- GAN discriminator: An adversarial network trained to differentiate real from generated data, used here as auxiliary supervision. "introduces a GAN discriminator trained on real videos to compensate for the mode-covering bias of the teacher's score."
- Generation manifold: The space of possible outputs structured by a generative model’s learned distribution. "higher-reward regions of the generation manifold."
- Group Relative Policy Optimization (GRPO): A policy-gradient method that optimizes policies relative to group baselines for stability and performance. "adapt group relative policy optimization to flow matching"
- Inter-Reliability: Variance in the trustworthiness of supervision across different generated sequences (rollouts). "Inter-Reliability across different rollouts"
- Intra-Perplexity: Variation within a single rollout across space and time in how much further optimization can improve quality. "Intra-Perplexity across spatial regions and temporal frames"
- KL-divergence: A measure of difference between probability distributions, often used as a training objective. "minimizing a KL-divergence-based objective."
- KV recaching: Reusing key-value attention caches to efficiently extend generation over long sequences. "through KV recaching and stream-based fine-tuning for long video generation"
- Min-max scaling: Normalizing values to a fixed range by subtracting the minimum and dividing by the range. "normalized via min-max scaling"
- Mode-covering bias: A tendency of a model or estimator to spread probability mass broadly, potentially covering low-quality modes. "to compensate for the mode-covering bias of the teacher's score."
- Per-instance distribution discrepancy: The difference between student and teacher output distributions measured on a per-sample basis. "they all minimize the per-instance distribution discrepancy between student and teacher outputs"
- Per-pixel gradient saliency: The magnitude of the reward model’s gradient with respect to each pixel, indicating sensitivity or potential improvement. "per-pixel gradient saliency, which is factored into spatial and temporal weights"
- Policy gradient methods: Reinforcement learning algorithms that optimize parameters via gradients of expected rewards. "Policy gradient methods such as Flow-GRPO adapt group relative policy optimization to flow matching"
- Positional encoding: Representations that encode ordering information (e.g., time or space) for sequence models. "flexible positional encoding"
- Reward model: A learned evaluator that assigns scalar or multi-dimensional quality scores to generated outputs. "a pretrained video reward model"
- Saliency map: A spatial or spatiotemporal map highlighting regions most influential to a model’s output or score. "We compute the per-axis saliency map"
- Score functions: Gradients of the log-density used in score-based generative modeling and related distillation. "estimate the score functions of the real and fake distributions"
- Sliding window: A rolling buffer or window over recent samples/steps for computing statistics or trends. "We maintain a sliding window of size N"
- Stop-gradient operator: An operation that prevents gradient flow through a variable, treating it as a constant during backprop. "is the stop-gradient operator."
- Temperature parameter: A scalar controlling the sharpness of a softmax or weighting distribution. " is a temperature parameter controlling the sharpness of the allocation."
- Temporal weights: Per-frame weights that modulate optimization intensity across time. "The temporal weights are then mean-normalized such that "
- Vision-LLM (VLM): A model jointly trained on visual and textual data used for evaluation or guidance. "VLM-based evaluation."
Collections
Sign up for free to add this paper to one or more collections.

