Understanding Self-Supervised Learning via Latent Distribution Matching
Abstract: Self-supervised learning (SSL) excels at finding general-purpose latent representations from complex data, yet lacks a unifying theoretical framework that explains the diverse existing methods and guides the design of new ones. We cast SSL as latent distribution matching (LDM): learning representations that maximize their log-probability under an assumed latent model (alignment), while maximizing latent entropy to prevent collapse (uniformity). This view unifies independent component analysis with contrastive, non-contrastive, and predictive SSL methods, including stop gradient approaches. Leveraging LDM, we derive a nonlinear, sampling-free Bayesian filtering model with a Kalman-based predictor for high-dimensional timeseries. We further prove that predictive LDM yields identifiable latent representations under mild assumptions, even with nonlinear predictors. Overall, LDM clarifies the assumptions behind established SSL methods and provides principled guidance for developing new approaches.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper gives a simple, unifying way to understand many popular self-supervised learning (SSL) methods. The big idea is called latent distribution matching (LDM). It says: when we turn raw data (like images, sounds, or time series) into hidden codes (representations), we should:
- pull together codes that belong together (alignment), and
- keep all codes well spread out so they don’t collapse to the same thing (uniformity).
The authors show that this view connects classic ideas (like independent component analysis, or ICA) with modern SSL methods (contrastive, non-contrastive, and predictive models like SimCLR, VICReg, CPC, BYOL, SimSiam, and JEPA). They also introduce a new predictive model that uses a Kalman filter (a tool for tracking changing systems) and prove when SSL can actually recover the true hidden factors that made the data.
What questions did the authors ask?
In friendly terms, they asked:
- Can we explain very different SSL methods using one simple, shared principle?
- Does chasing “mutual information” (how much two things tell you about each other) really matter for good representations?
- Can this framework suggest new, better SSL models (especially for time series)?
- When do these methods learn the real hidden causes of the data (not just some random coding of it)?
How did they study it? (Methods in simple terms)
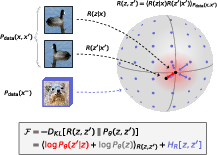
Think of data as dots in a huge space (like all possible images). An encoder is a function that turns each data point into a hidden code (a “point” in a new space). The LDM idea says: choose a simple model for how you want codes to look and behave, then train the encoder so that the actual codes match that model’s “shape” (its distribution).
Two key parts:
- Alignment: Make codes from related inputs (like two augmented views of the same image, or neighboring time points) close to each other. This is like saying “two photos of the same cat should have nearby codes.”
- Uniformity (entropy): Keep all codes spread out enough (high variety) so the network doesn’t cheat by mapping every input to the same code. This prevents “collapse.”
Some technical words explained:
- Distribution matching: Imagine you have a cloud of points (your learned codes) and a target cloud shape (your simple model). You adjust the encoder until your cloud matches the target cloud.
- Entropy: A measure of “spread” or variety. High entropy means codes are well distributed; low entropy means they’re bunched up.
- Mutual information (MI): How much knowing one thing tells you about another. In SSL, people often try to maximize MI between two related views. The authors show this isn’t the main hero—keeping entropy high already does most of the job.
- Stop-gradient: During training, you “freeze” one side so the other side can’t chase moving targets too aggressively. It’s a common trick in BYOL/SimSiam/JEPA.
- Kalman filter: A classic “predict-and-correct” tracker. It predicts the next state of a system (like where a moving dot will be) and also tells you how confident it is (uncertainty).
- Identifiability: A guarantee that the learned codes reflect the true hidden factors that created the data (up to simple changes like scaling or reordering), not just some random reshuffling.
How this unifies known SSL methods:
- Contrastive methods (like SimCLR) show alignment by pulling paired views together and push all others apart. In LDM, that’s alignment + an entropy estimator that uses “neighbors” (like a soft counting of negatives).
- Non-contrastive methods (like VICReg) use penalties that keep variance high and avoid redundancy to raise entropy—no explicit negatives needed.
- Predictive methods (like CPC, JEPA) focus on time: they predict the future code from the past codes. In LDM, that’s matching a predictive model of codes over time, plus entropy to avoid collapse. Stop-gradient turns into a clever way to estimate the “conditional entropy” (spread given the past) without heavy math.
New approach:
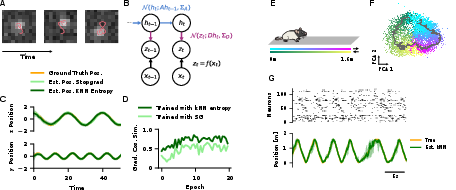
- The authors build a predictive SSL model with a Kalman-based predictor. It learns hidden codes that can be tracked over time and gives a built-in uncertainty estimate—useful for noisy, high-dimensional time series.
What did they find and why does it matter?
Main findings:
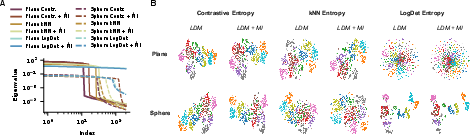
- One framework fits many SSL methods. By choosing a simple “latent model” and a way to measure entropy, you can derive contrastive, non-contrastive, and predictive SSL losses from the same recipe.
- Mutual information isn’t the key driver. In practice, maximizing MI on top of entropy doesn’t change the learned representations much. What matters more is how you estimate entropy and what geometry you assume for the code space (e.g., on a sphere vs. in a flat space).
- New predictive model with uncertainty. Their Kalman-based SSL can learn to track hidden states in videos and neural recordings (rat hippocampus spikes) while also estimating uncertainty. That’s powerful for real-world, noisy signals.
- Identifiability guarantees. Under mild assumptions (like prediction errors being roughly Gaussian and the encoder not squashing different inputs into the same code), their predictive LDM can recover the true hidden factors up to simple transforms. This helps explain why predictive SSL works so well.
Why this matters:
- A unified view helps researchers design better SSL methods on purpose, instead of relying on trial-and-error.
- Knowing that MI adds little beyond entropy can save effort and simplify models.
- Being able to estimate uncertainty in SSL for time series is important for safety and reliability (e.g., in tracking, healthcare, or robotics).
- Identifiability means the learned codes can be meaningfully interpreted and trusted.
What could this change?
- Clearer design rules: Instead of tweaking countless training tricks, researchers can pick a latent model (what kinds of relationships codes should follow) and a robust entropy estimator, then let distribution matching do the rest.
- Better time-series SSL: The Kalman-based approach encourages uncertainty-aware, prediction-driven learning for videos, sensors, and brain signals.
- Stronger theory behind SSL: The results connect classic source-separation (ICA) ideas with modern SSL and show when we can expect to recover true hidden causes.
- New focus on entropy estimation: Since entropy matters most, inventing better, stable, and fast-to-optimize entropy estimators could significantly boost SSL quality.
- Rethinking “compression”: SSL might not mainly throw away information; instead, it re-parameterizes the data “manifold” into a geometry that makes important features easy to use.
In short, this paper gives a simple, powerful lens for understanding and improving SSL: match the shape of your learned codes to a chosen latent model, keep them well spread out, and use prediction wisely—often, that’s all you need.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of concrete gaps and open questions that the paper leaves unresolved. These identify where assumptions may be too strong, where empirical validation is limited, and where theory or methodology needs to be extended or stress-tested.
- Practical invertibility: How to diagnose, enforce, or regularize “invertibility on the data manifold” in modern encoders during training, and how to quantify deviations in practice.
- When MI helps: Formal conditions and counterexamples characterizing regimes where mutual information maximization contributes beyond entropy maximization (e.g., early training, compressive representations, noisy/weak views), including gradient-level analyses beyond the tested settings.
- Early-training dynamics: The stop-gradient conditional-entropy approximation shows gradient alignment only late in training; what techniques (schedules, warm-starts, architectural biases) improve its validity and stability at initialization.
- Entropy estimator theory: Bias/variance, sample complexity, and asymptotic consistency of kNN/KDE/LogDet estimators in high-dimensional latent spaces; error propagation into representation quality and identifiability.
- Scalable entropy estimation: Algorithms to make kNN/KDE-based entropy differentiable, memory-efficient, and stable for large batches and high dimensions; batch-bias corrections and streaming/online variants.
- Geometry-aware entropy: Principled entropy estimators that respect latent-manifold geometry (e.g., spherical, hyperbolic, toroidal), replacing ad hoc use of LogDet on spheres or flat priors on non-Euclidean spaces.
- Misspecification robustness: Quantitative robustness guarantees for identifiability and performance when the latent predictive noise model (Gaussian/von Mises–Fisher) or prior is misspecified (e.g., heavy-tailed, heteroskedastic, nonstationary).
- Predictor coverage: A precise, testable definition of “predictor covers the latent space,” along with architectural or regularization mechanisms that ensure it during training.
- Convergence vs identifiability: Optimization landscape analysis and algorithms with convergence guarantees to identifiable solutions, not just identifiability “at the optimum.”
- Augmentation design: Necessary/sufficient conditions on the paired-view or augmentation distribution that guarantee identifiability under latent distribution matching; procedures to validate augmentation sufficiency.
- Compressive encoders: Systematic evaluation of LDM vs MI-based objectives when latent dimensionality is intentionally low (non-invertible mappings), including trade-offs in downstream utility.
- Latent dimension selection: Criteria for choosing latent dimensionality (under/overcomplete) and its impact on identifiability, optimization, and downstream tasks.
- Capacity control of Pθ: How to regularize the latent model so it does not overfit the empirical latent distribution and undermine identifiability (e.g., preventing trivial matching via overly flexible Pθ).
- Support mismatch: Diagnostics and remedies when the supports of R and Pθ do not coincide (e.g., collapse modes, implicit out-of-support mass), especially with deterministic encoders.
- Degenerate “uniformity”: Guarantees and practical heuristics ensuring that entropy maximization does not promote trivial “spread-everything” solutions that harm alignment.
- Batch and negatives: Theoretical and empirical characterization of batch-size/negative-sampling effects on KDE/kNN entropy estimators and representation quality; optimal negative distributions and memory-bank strategies.
- Beyond sphere/plane: Systematic exploration of alternative latent geometries (e.g., hyperbolic, product manifolds) and corresponding likelihoods/entropy estimators with identifiability guarantees.
- Masked/other SSL families: Extending the LDM mapping and theory to masked autoencoding, clustering-based SSL, diffusion-style objectives, and reconstruction hybrids; clarifying when they fit the LDM lens.
- Stochastic encoders: A full treatment (theory + experiments) of stochastic recognition models R(z|x), including benefits for entropy estimation, uncertainty propagation, and identifiability.
- Large-scale validation: Experiments on larger datasets and modalities (ImageNet-1k+, video, audio, text, multimodal image–text) and more challenging downstream tasks (detection, segmentation, retrieval), beyond linear probing.
- Robustness and transfer: Impact of entropy estimator choice and latent model on robustness (corruptions, OOD shift), few-shot transfer, continual learning, and domain adaptation.
- Computational cost: Profiling and benchmarks of the added LDM/entropy components (time, memory), including ablations on estimator hyperparameters (e.g., bandwidth, number of neighbors).
- Kalman predictor generalization: Extending to nonlinear dynamics and non-Gaussian noise (EKF/UKF, particle filters, neural filters) and comparing their identifiability, stability, and scalability.
- Learning dynamics models: Methods to learn latent dynamics structure (e.g., Jacobians, linearization points, regime switches) within the LDM framework while retaining identifiability.
- Uncertainty calibration: Rigorous evaluation of uncertainty quality (NLL, calibration curves, sharpness) in the Kalman-based SSL, including comparisons to probabilistic baselines.
- Neuroscience benchmarks: Broader validations on neural data (beyond a single hippocampal task), comparisons with state-of-the-art decoders, and tests of causal interpretability.
- Broader identifiability classes: Extending proofs beyond Gaussian/vMF residuals to heavy-tailed, mixture, and heteroskedastic models; time-varying covariances and partially observed dynamics.
- Enforcement of injectivity: Practical regularizers (e.g., Jacobian conditioning, invertible backbones, Lipschitz constraints) that promote manifold-wise invertibility and their effect on learning.
- Formal MI–LDM link: A general theorem showing when approximate MI maximization reduces to distribution matching under model misspecification, and delineating exceptions.
- Proper priors: Replacing improper “flat” priors with proper priors and quantifying the impact on normalization, gradients, and identifiability.
- Reproducibility: Public release of code, detailed augmentation protocols, and seeds to verify the empirical claims about MI vs LDM equivalence and the sensitivity to entropy estimators.
Practical Applications
Immediate Applications
The following applications can be deployed now using the paper’s Latent Distribution Matching (LDM) framework, entropy estimation choices, and the Kalman-based predictive SSL prototype.
- Design and debugging of SSL objectives via LDM “design knobs”
- Sectors: software/ML engineering, AI platforms, education (ML courses).
- What: Use LDM’s alignment + entropy view to systematically choose latent model (e.g., Gaussian vs von Mises–Fisher, sphere vs plane) and entropy estimator (KDE, kNN, LogDet) to reproduce/extend SimCLR-, VICReg-, BYOL/SimSiam-, and JEPA-like objectives. Quickly swap entropy estimators to control geometry and uniformity without relying on MI maximization.
- Tools/workflows: A lightweight SDK for “plug-in entropy estimators” and latent space choices; unit tests that verify non-collapse via entropy; ablation templates comparing LDM vs MI-based objectives.
- Dependencies/assumptions: Requires standard SSL setups with view pairing/augmentations; stable entropy estimator configuration (bandwidth, k in kNN); sufficient latent dimensionality; invertibility on the data manifold is encouraged by entropy but not guaranteed if capacity is too low.
- Compute- and memory-efficient training by removing explicit MI maximization
- Sectors: software/ML infra, on-device/edge AI.
- What: Adopt LDM without MI terms (no InfoNCE-style negatives) for comparable representation quality to MI-maximizing counterparts, reducing negative-sampling overhead and large-batch pressure in contrastive pipelines.
- Tools/workflows: “MI-free” pretraining recipes for images and sequences; batch-size constrained training on single GPUs; deployment pipelines for edge devices that avoid contrastive queues.
- Dependencies/assumptions: Data regimes where entropy estimators are well-behaved; care with collapse-avoidance (choose robust entropy estimator); similar augmentations to baseline SSL.
- Uncertainty-aware latent state estimation with a Kalman-based predictive SSL backbone
- Sectors: robotics, manufacturing (predictive maintenance), IoT/sensing, healthcare research (wearables), finance research (time series).
- What: Use the proposed Kalman-based predictor in latent space to obtain real-time state estimates and calibrated uncertainty without likelihood modeling in pixel/signal space. Enables online filtering in learned embeddings for high-dimensional streams.
- Tools/workflows: A “Latent Kalman JEPA” module integrated with encoders for sensor fusion; dashboards plotting state and covariance; alerting using predictive residuals and variance.
- Dependencies/assumptions: Approximate Gaussian noise on prediction errors; encoder invertibility on the data manifold for best identifiability; predictor “coverage” of latent space; stationarity or slowly varying dynamics unless model adapts (e.g., input-conditioned parameters).
- Neuroscience pipelines for unsupervised decoding with confidence bounds
- Sectors: academia (neuroscience, cognitive science), neurotech.
- What: Apply the Kalman-based predictive SSL workflow to neural spike trains to decode behavioral variables (e.g., position) with credible intervals—no supervised labels required, as shown on hippocampal data.
- Tools/workflows: Lab analysis notebooks for latent-space filtering; uncertainty-aware decoding benchmarks for new datasets; parameter sweeps over latent dimensions and predictors.
- Dependencies/assumptions: Sufficient recording quality and time structure; Gaussian-like predictive errors or robustification; careful preprocessing; ethics/IRB compliance for neural data.
- System identification in engineering from raw high-dimensional observations
- Sectors: control engineering, robotics, industrial automation.
- What: Use predictive LDM to learn latent dynamics that align with underlying system states up to affine transformations, enabling linear decoders for state recovery and monitoring.
- Tools/workflows: Drop-in modules for system-ID from video/sensor streams; linear probes on latent states for interpretability; alarms based on predictive residuals.
- Dependencies/assumptions: Temporal structure with informative auxiliary signals/views; approximate encoder injectivity on the data manifold; noise consistent with model assumptions.
- Representation evaluation and benchmarking built around entropy and latent models
- Sectors: academia, industry R&D.
- What: Benchmark SSL variants by explicitly reporting latent model choice and entropy estimator (rather than MI surrogates), using linear probing and eigenspectrum diagnostics as in the paper.
- Tools/workflows: Benchmark harness reporting entropy quality, latent uniformity, collapse metrics, and spectrum.
- Dependencies/assumptions: Availability of standard datasets and compute; consistent evaluation protocols.
- Anomaly and drift detection using latent entropy and predictive residuals
- Sectors: operations/monitoring (AIOps, MLOps), manufacturing, finance research.
- What: Monitor latent entropy and Kalman residual statistics to detect distribution shift and anomalies in streaming data without labels.
- Tools/workflows: Thresholds on residual norms and covariance; moving-window entropy monitors; integration with observability stacks.
- Dependencies/assumptions: Stable baseline; calibrated predictor covariances; controlled update schedules to avoid “learning the anomaly.”
- Curriculum and training materials to teach unified SSL theory
- Sectors: education, professional training.
- What: Replace disparate SSL stories with a single LDM narrative (alignment + entropy), clarifying MI’s limited role and how stop-grad approximates conditional entropy.
- Tools/workflows: Lecture modules; coding labs that re-derive VICReg/SimCLR/JEPA from LDM; visualization of entropy effects on representation geometry.
- Dependencies/assumptions: None beyond standard ML course setup.
Long-Term Applications
These applications are promising but require further research, scaling, or validation (e.g., stronger entropy estimators, broader identifiability conditions, real-world constraints).
- Safety-critical state estimation for autonomous systems with identifiable latents
- Sectors: autonomous driving, aerial robotics, industrial robots.
- What: Combine predictive LDM with Kalman-like latent predictors for interpretable, identifiable state spaces and principled uncertainty—supporting certification and safety cases.
- Tools/products: Certifiable state-estimation stack with latent-space diagnostics; sensor-fusion modules that operate entirely in learned embeddings.
- Dependencies/assumptions: Robust identifiability under non-Gaussian noise, multimodal sensors, and nonstationary dynamics; formal verification methods; compliance with safety standards.
- Healthcare-grade forecasting and monitoring from patient time series
- Sectors: healthcare, digital therapeutics.
- What: Use identifiable latent factors with uncertainty to support early warning (e.g., sepsis), treatment response modeling, and personalized monitoring from EHRs and wearables, while avoiding hand-crafted labels.
- Tools/products: Clinical decision support modules with calibrated confidence; latent-factor dashboards for clinicians; FDA/CE-mark readiness via uncertainty quantification.
- Dependencies/assumptions: Regulatory validation; bias/shift robustness; data governance and privacy; domain-tailored entropy estimators for sparse/irregular sampling.
- Interpretable factor discovery in finance and econometrics
- Sectors: finance, macroeconomics research.
- What: Leverage predictive LDM identifiability to recover latent market factors (up to affine transforms) with uncertainty, improving risk estimation and stress testing.
- Tools/products: Factor analytics with confidence bounds; regime-change detectors using latent residuals and entropy.
- Dependencies/assumptions: Market nonstationarity and heavy tails may violate Gaussian/vMF assumptions—requires robust predictors and entropy estimators; regulatory model risk management.
- Grid and energy systems latent state forecasting and control
- Sectors: energy, smart grids.
- What: Learn identifiable latent states of grid dynamics from high-dimensional sensor networks for forecasting, stability monitoring, and adaptive control with quantified uncertainty.
- Tools/products: Control-room assistants that operate on learned latent states; anomaly and contingency detection via predictive residuals.
- Dependencies/assumptions: High reliability requirements; adaptation to rare-event distributions; integration with SCADA/EMS.
- Foundation models with uncertainty-aware, modality-agnostic LDM pretraining
- Sectors: AI foundation models (vision, audio, multimodal).
- What: Build pretraining pipelines where latent model choice and entropy estimation are first-class citizens, enabling principled uncertainty and identifiability across modalities.
- Tools/products: “Entropy Estimator Zoo” and “Latent Model Configurator” integrated into pretraining stacks; standardized reporting/metrics for latent uniformity and invertibility.
- Dependencies/assumptions: Scalable, stable entropy estimators for trillion-token/imagenet-scale data; efficient training without MI negatives; community standards.
- Causal and scientific discovery in spatiotemporal sciences
- Sectors: climate science, neuroscience, genomics, materials.
- What: Use predictive LDM to recover meaningful latent processes (up to affine transformations) from complex spatiotemporal measurements, aiding hypothesis generation and mechanistic modeling.
- Tools/products: Research toolkits coupling identifiable latent SSL with downstream linear models and hypothesis tests; uncertainty-aware latent embeddings for simulation-forecast fusion.
- Dependencies/assumptions: Confirmatory studies; domain-specific noise models deviating from Gaussian; careful interpretation of affine equivalences.
- Standards and policy for uncertainty quantification and reporting in SSL
- Sectors: policy, standards bodies, regulatory tech.
- What: Define guidelines that SSL systems report latent uncertainty and entropy metrics, and disclose latent model/estimator choices, improving safety and transparency.
- Tools/products: Benchmark protocols and checklists; compliance tooling for uncertainty reporting.
- Dependencies/assumptions: Cross-industry agreement; mapping uncertainty metrics to risk frameworks; empirical validation that uncertainty correlates with failure modes.
- Consumer applications with privacy-aware, on-device unsupervised personalization
- Sectors: mobile, wearables, smart home.
- What: On-device predictive LDM for activity recognition, keyboard personalization, or photo organization with calibrated confidence and no labels or cloud data transfer.
- Tools/products: Edge libraries implementing MI-free LDM with efficient entropy estimation; privacy-preserving updates.
- Dependencies/assumptions: Efficient, low-power entropy estimators; robustness to nonstationary user behavior; privacy constraints and opt-in data handling.
Notes on cross-cutting assumptions and dependencies:
- Identifiability guarantees rely on: (i) approximate Gaussian/vMF predictive residuals; (ii) encoder invertibility on the data manifold; (iii) predictor coverage of the latent space. Deviations may still work empirically but weaken guarantees.
- Entropy estimation is a critical practical lever; stability and differentiability of KDE/kNN/LogDet approximations strongly affect results.
- Temporal structure (paired views or sequences) and well-chosen augmentations remain prerequisites for successful SSL training.
- Calibrated uncertainty requires well-tuned predictors and covariance estimation; outlier-heavy or regime-shifting data may need robust variants.
Glossary
- Affine transformation: A linear mapping followed by a translation; in identifiability results, solutions can be unique up to such transformations. "up to an affine transformation."
- Alignment: In SSL, the objective component that pulls representations of related views together in latent space. "correspond to alignment and uniformity terms"
- Auxiliary variables: Additional observed variables used to make nonlinear ICA identifiable. "using assumptions such as temporal structure or auxiliary variables"
- Bayesian filtering: Sequential probabilistic estimation of hidden states from observations and dynamics. "Bayesian filtering model"
- BYOL: A non-contrastive SSL method (Bootstrap Your Own Latent) that learns representations without explicit negatives. "such as BYOL"
- Change of variables: The transformation rule for densities/entropies under invertible mappings, used here to relate entropies across spaces. "the formula for the change of variables in the entropy."
- Conditional dependencies: Specified relationships in latent space (e.g., between paired or temporal latents) that make nonlinear source recovery well-posed. "additional conditional dependencies in the latent variable distribution"
- Conditional entropy: Entropy of a variable given others; maximizing it (or approximations) helps prevent collapse in predictive SSL. "conditional entropy maximization"
- Contrastive learning: SSL paradigm that attracts positives and repels negatives in latent space. "contrastive learning such as SimCLR."
- Contrastive Predictive Coding (CPC): A contrastive, predictive SSL objective that relates future and context via a discriminative bound. "contrastive SSL (e.g., CPC)"
- Coverage of the latent space: An assumption that the predictor’s domain spans the relevant latent states, needed for identifiability. "the predictor covers the latent space."
- Covariance log-determinant: The log of the determinant of a covariance matrix; used as a proxy for entropy in VICReg-like objectives. "covariance log-determinant"
- Data manifold: The lower-dimensional subset of input space that real data occupies; invertibility is often required only on this set. "on the data manifold"
- Distribution matching: Training the encoder so the induced latent distribution matches an assumed latent model. "distribution matching in latent space."
- Empirical latent distribution: The distribution over latents induced by the encoder on data, used as the target for matching. "empirical latent distribution R(\boldsymbol{z})"
- Entropy estimator: A method to approximate entropy (e.g., KDE, kNN, parametric) for uniformity terms in SSL. "entropy estimator"
- Flat prior: An (often improper) uniform prior that does not favor any region of latent space. "improper flat prior."
- Gaussian predictor: A predictive model that assumes Gaussian conditional distributions for the next latent. "under a Gaussian predictor"
- Identifiability: The ability to recover true latent variables (up to trivial transformations) from observed data. "Identifiability is a core concept"
- Independent Component Analysis (ICA): A framework to recover statistically independent latent sources from mixed observations. "independent component analysis"
- InfoMax: An ICA/learning principle maximizing mutual information between inputs and outputs, often equivalent to likelihood under assumptions. "including InfoMax and likelihood-based methods"
- InfoNCE: A contrastive bound often used to maximize mutual information between representations. "InfoNCE has been derived before"
- Invertibility on the data manifold: The requirement that the encoder be one-to-one for data, enabling likelihood/entropy equivalences. "invertible on the data manifold"
- JEPA: Joint-Embedding Predictive Architecture; a predictive SSL family operating in latent space. "JEPA"
- Kalman-based predictor: A predictor using Kalman filtering equations to model latent dynamics and uncertainty. "Kalman-based predictor"
- Kernel density estimation (KDE): A nonparametric density (and entropy) estimator using kernels centered at samples. "kernel density estimation (KDE)"
- k-nearest neighbors (kNN) entropy estimator: A nonparametric entropy estimator based on neighbor distances. "kNN entropy estimator"
- Kullback–Leibler divergence (KL divergence): A directed divergence measuring how one distribution differs from another. "KL divergence"
- Latent model: The assumed probabilistic model over latent variables that the encoder’s distribution is matched to. "latent model"
- Latent variables: Hidden factors generating observed data; SSL aims to learn representations aligned with these. "latent variables"
- Log-determinant of the Jacobian: A term arising from change-of-variable formulas, used by flows and related models. "log-determinant of the Jacobian"
- Log-likelihood: The logarithm of the likelihood; maximizing it often corresponds to matching latent distributions under invertibility. "model log-likelihood"
- Manifold normalizing flows: Flow models adapted to data manifolds, relating likelihood maximization to latent distribution matching. "manifold normalizing flows"
- Mutual information (MI): A measure of shared information between variables; often targeted or bounded in SSL. "MI is invariant under arbitrary invertible transformations"
- Non-contrastive SSL: Methods that learn without explicit negative pairs, relying on other mechanisms to avoid collapse. "non-contrastive SSL"
- Non-degenerate covariance: A covariance matrix that is full rank (invertible), required for certain identifiability arguments. "non-degenerate covariance"
- Nonlinear ICA: ICA where the mixing/unmixing functions are nonlinear, requiring extra structure for identifiability. "nonlinear ICA"
- Normalizing flow networks: Invertible neural networks trained via likelihood by transforming data into a simple latent distribution. "normalizing flow networks"
- Optimal transport: A mathematical framework for mapping one distribution to another with minimal cost; used to view SSL as distribution matching. "from the perspective of optimal transport"
- Ornstein–Uhlenbeck process: A mean-reverting stochastic process used as a latent dynamics example. "two Ornstein-Uhlenbeck processes"
- Parametric entropy estimator: An entropy approximation assuming a parametric family (e.g., Gaussian) for the latent distribution. "parametric entropy estimator"
- Rate reduction: A principle reducing redundancy/information rate in representations, linked to SSL objectives. "rate reduction"
- Representational collapse: A failure mode where encodings map many inputs to the same value, losing information. "representational collapse."
- Reverse KL-Divergence: The KL divergence with arguments swapped, emphasizing different aspects of mismatch. "reverse KL-Divergence"
- SimCLR: A contrastive SSL method using InfoNCE on augmented image pairs on the unit sphere. "SimCLR"
- SimSiam: A non-contrastive SSL method that uses stop-gradient and predictor networks without negatives. "SimSiam"
- Stop gradient (stopgrad): A training trick that prevents gradient flow through certain paths, stabilizing non-contrastive/predictive SSL. "stopgrad"
- Support (of a distribution): The set where a distribution assigns nonzero probability; matching requires overlapping supports. "the same support"
- Temporal generative models: Models that generate sequences by predicting future observations rather than latents. "temporal generative models"
- Uniformity: The objective component encouraging spread-out latent representations to avoid collapse. "uniformity"
- Unmixing matrix: The matrix (in linear ICA) that separates mixed signals into independent components. "unmixing matrix "
- Variational bound: A tractable lower bound (e.g., on MI) used for optimization in place of an intractable target. "variational bound on the \ac{MI}"
- Variational inference: An optimization framework approximating complex distributions with simpler ones via bounds. "variational inference principles"
- VICReg: A non-contrastive SSL method using variance, invariance, and covariance regularization. "VICReg"
- von Mises–Fisher (vMF) distribution: A distribution on the sphere; used to model directional similarity in contrastive SSL. "von Mises-Fisher (vMF) distribution"
- Volume preserving: A transformation with unit determinant; used as a constraint in source separation. "volume preserving (determinant of )"
- V-JEPA: A variant of JEPA using vector quantization or specific architectural choices; discussed in comparison to identifiability. "V-JEPA"
Collections
Sign up for free to add this paper to one or more collections.