- The paper introduces a novel method that embeds spatial regularization through Multi Node Prediction to enhance PDE surrogate modeling.
- It proposes a Temporal Correction block that stabilizes integration for stiff dynamics and reduces long-term error accumulation.
- The work integrates 3D Rotary Positional Embeddings to infuse geometric biases, yielding a 20–30% RMSE reduction in simulations.
Mesh Based Simulations with Spatial and Temporal Awareness
Introduction
"Mesh Based Simulations with Spatial and Temporal Awareness" (2605.01542) presents a new methodological framework for improving mesh-based machine learning surrogates of computational fluid dynamics (CFD) and physical simulations. The central claim is that despite substantial progress in GNN and Transformer architectures, their training regimes have remained fundamentally naive—generally formulated as node-wise regression under explicit Euler time-stepping. These choices neglect the numerical structure of PDE solvers such as FEM, especially in the presence of stiff dynamics and the demand for physically consistent local interactions. To address this gap, the authors propose three architectural contributions: Multi Node Prediction (MNP) for implicit spatial regularization, Temporal Correction for stable discrete integration, and 3D Rotary Positional Embeddings to encode equivariant geometric biases.
Motivation and Limitations of Prior Work
In mesh-based physics simulation, GNNs and message-passing neural networks have achieved strong predictive accuracy, particularly for applications in weather forecasting, hemodynamics, and mechanics. However, canonical surrogates historically rely on pointwise (node-level) supervision and explicit time integration schemes that have well-known issues:
- Node-wise losses: ignore local differential consistency, so predicted fields can be locally inconsistent in flux, violating PDE conservation laws over stencils.
- Explicit Euler schemes: are numerically unstable for stiff systems and amplify drift in autoregressive rollouts.
The paper identifies that GNN community efforts have largely optimized architectures while leaving these two training artifacts unchallenged. This overfits surrogates to pointwise statistics while disregarding mesh-informed regularity and time-stepping stability crucial for long-term accuracy in physics simulation.
Multi Node Prediction: Spatial Consistency Enforcement
The Multi Node Prediction (MNP) task introduces an auxiliary, stencil-level objective: for each randomly selected interior node, the model predicts both its own future state and the future states of its immediate neighbors, using a structured cross-attention (star) mechanism operating on both latent and freshly encoded features. This approach regularizes the latent representation such that it encodes not only local state but also enough context to reconstruct the physical field over a neighborhood.
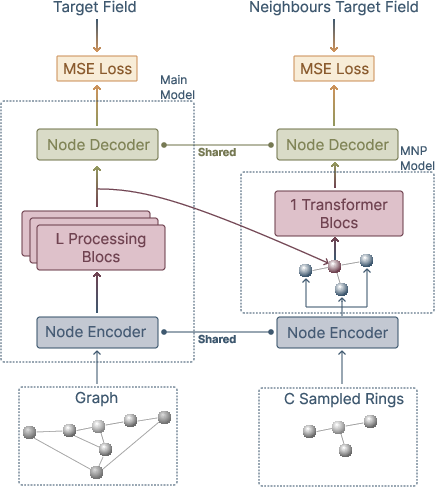
Figure 1: MNP mechanism—cross-attention over a central latent node and encoded neighbors predicts target fields for all nodes in the local stencil.
This modification is theoretically grounded: the paper provides an explicit result proving that patch-level prediction bounds the error in discrete gradients, rendering MNP a form of discrete Sobolev regularization. Compared to simply adding a supervised gradient loss on node outputs, MNP yields stronger improvement in both short- and long-term RMSE, validating the hypothesis that explicit neighborhood consistency is critical for PDE surrogates.
Temporal Correction: Implicit Integration via Cross-Attention
Explicit Euler updates (forward residual flows) are unstable for stiff dynamics, a regime common in mesh-based physical simulations. The proposed Temporal Correction block splits each spatial processing stage into a learnt predictor-corrector update:
- The first (predictor) advance is a regular message-passing or attention-based step.
- The second (corrector) is a learnable gating and mixing block with cross-attention, using the predicted future state as queries and the previous state as keys/values, optionally followed by a mixing MLP.
By design, this architecture can emulate classical implicit/θ-method integration schemes, which are known to offer strictly larger stability regions than Euler (theorem and empirical results in the supplement). Empirically, the addition of this block has a pronounced effect on the reduction of error accumulation in long rollouts.
3D Rotary Positional Encoding: Geometric Inductive Biases
Long-range anisotropic dynamics are poorly captured on irregular meshes with vanilla attention or message passing. The authors propose integrating 3D Rotary Positional Embeddings into attention score computation. This approach rotates query and key features axis-wise, with rotation angles proportional to multi-scale, centered spatial coordinates, injecting translation-invariant relative position information into attention while remaining efficient and parameter-free.
The ablation studies show that 3D RoPE, when combined with absolute coordinates, provides significant performance gains, outperforming alternatives such as raw learnable positional embeddings or relative biases.
Empirical Evaluation
The framework is benchmarked on three canonical datasets—Flow past a Cylinder, Deforming Plate, and Brain Aneurysm (varying from 1,000 to 250,000 nodes), using three architectures (MeshGraphNet, Transolver, and a vanilla Transformer). The evaluation spans both short horizon (1-step RMSE) and long autoregressive rollouts. The results demonstrate:

Figure 2: Improvement in 1-step RMSE across all models and datasets relative to baselines with equivalent parameter budgets.
- Consistent improvements: All three modules yield 20–30% improvement in RMSE metrics for all models and datasets, with training and inference time overhead under 10%.
- Scaling behavior: Gains persist at increasing model width and depth (see scaling plots), with caveats at benchmark saturation regimes (e.g., Cylinder).
- Latent representation: MNP produces latent states that are closer to encoded targets (see Figure 3/12), and are more linearly informative for auxiliary tasks such as pressure or WSS prediction.
- Robustness: Improvements are robust under training time variation, model capacity scaling, and out-of-distribution (geometry-shift) generalization.
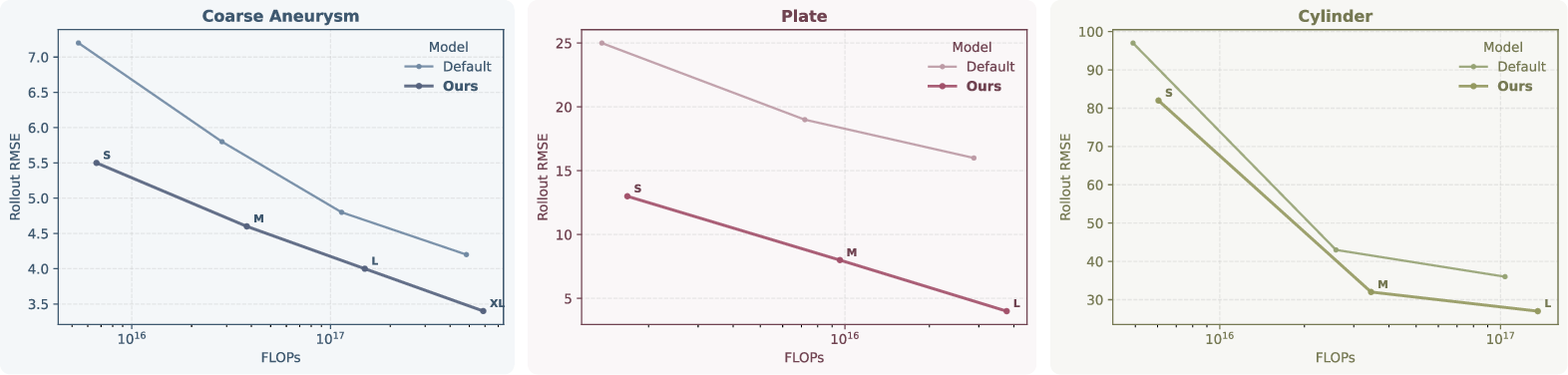
Figure 4: Rollout RMSE performance as a function of model size across datasets, demonstrating that the proposed approach maintains or increases gains with model scaling.
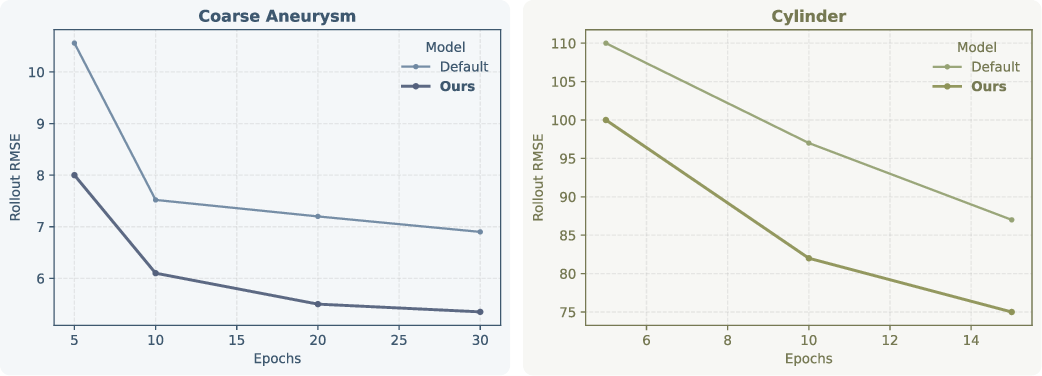
Figure 5: All-rollout RMSE for MeshGraphNet as a function of training schedule—improvements scale with training duration.
Ablation and Theoretical Analysis
The ablation section isolates the marginal and combinatorial impact of each module, including various alternatives:
- MNP vs. direct field gradient supervision,
- RoPE variants,
- Frequency and type of temporal correction,
- Additional physics-informed loss terms (divergence, cosine similarity).
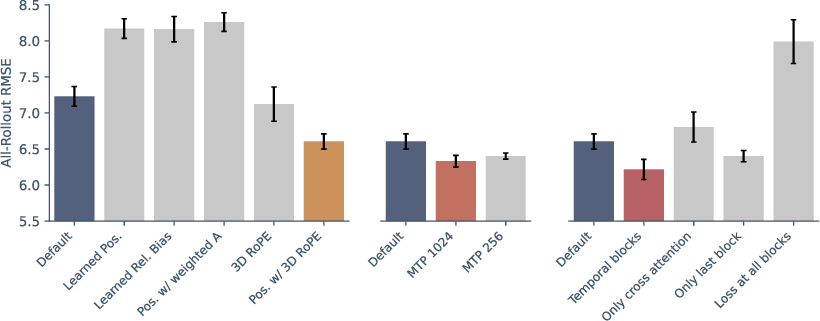
Figure 6: Ablation results for RoPE, MNP, and Temporal Correction; MNP yields superior improvements over naive gradient-based losses, and both gating/mixing are necessary in the temporal block.
Theoretical sections rigorously connect the MNP objective to H1 consistency and show that the predictor-corrector block can strictly enlarge the stability region via a learned θ-method. This alignment of ML training objectives with classical numerical analysis is a key methodological contribution.
Implications, Limitations, and Future Work
The findings indicate that mesh-based GNNs and Transformer solvers should be viewed not merely as function approximators, but as learnable PDE solvers whose architectural and training biases must reflect domain-specific numerical constraints. The explicit inclusion of spatial and temporal numerical structures improves surrogate fidelity, especially in stiff, anisotropic, or geometry-varying regimes.
Practical implications include increased simulation stability for long-time horizons, improved physical generalization to unseen mesh geometries, and enhanced interpretability of learned latent states. These results are likely relevant beyond CFD, impacting any domain where spatiotemporal surrogate models for PDEs are required, such as solid mechanics, climate prediction, and medical flow diagnostics.
Potential extensions include:
- Application to higher-order stencils and alternative mesh connectivities,
- Unified integration with physics-informed and multi-modal loss terms,
- Generalization to coupled multi-physics and feedback control contexts,
- Exploration of automated mesh adaptation strategies guided by surrogate uncertainty.
Conclusion
This work demonstrates that enforcing spatial and temporal inductive biases at both objective and architectural levels addresses critical weaknesses in mesh-based simulation surrogates. The combination of Multi Node Prediction, explicit temporal correction via cross-attention, and geometric equivariant positional encodings leads to substantial and robust accuracy improvements, more faithful long-horizon rollouts, and richer latent encodings. The proposed framework sets a methodological standard for future mesh-based ML surrogates, harmonizing deep learning pipelines with fundamental principles of numerical analysis and PDE discretization.
(2605.01542)

