- The paper introduces KVInject and AttnRouter, enabling training-free, high-fidelity image editing through per-category attention manipulation in MMDiT.
- KVInject uses an α-blend operator to mix source and noise key/value projections within targeted layer and step bands, boosting composite scores by up to 3.8%.
- AttnRouter employs a CLIP-based auto-classifier for routing different edit categories, achieving a 6.4% performance gain over traditional methods.
Per-Category Attention Routing for Training-Free Image Editing on MMDiT
Introduction
The paper "AttnRouter: Per-Category Attention Routing for Training-Free Image Editing on MMDiT" (2605.01480) rigorously characterizes attention-level interventions for training-free image editing in multi-modal diffusion transformers (MMDiTs). The authors focus on Qwen-Image-Edit-2511—a 60-block transformer where noise and source-image tokens are concatenated, flowing through a single joint-attention backbone. This architecture complicates the transfer of prior training-free editing methods rooted in UNet design, as classic separation between self- and cross-attention is abolished. The work pioneers a new attention manipulation protocol, KVInject, and introduces AttnRouter—a category-aware dispatcher that achieves superior preservation and fidelity outcomes across diverse edit types.
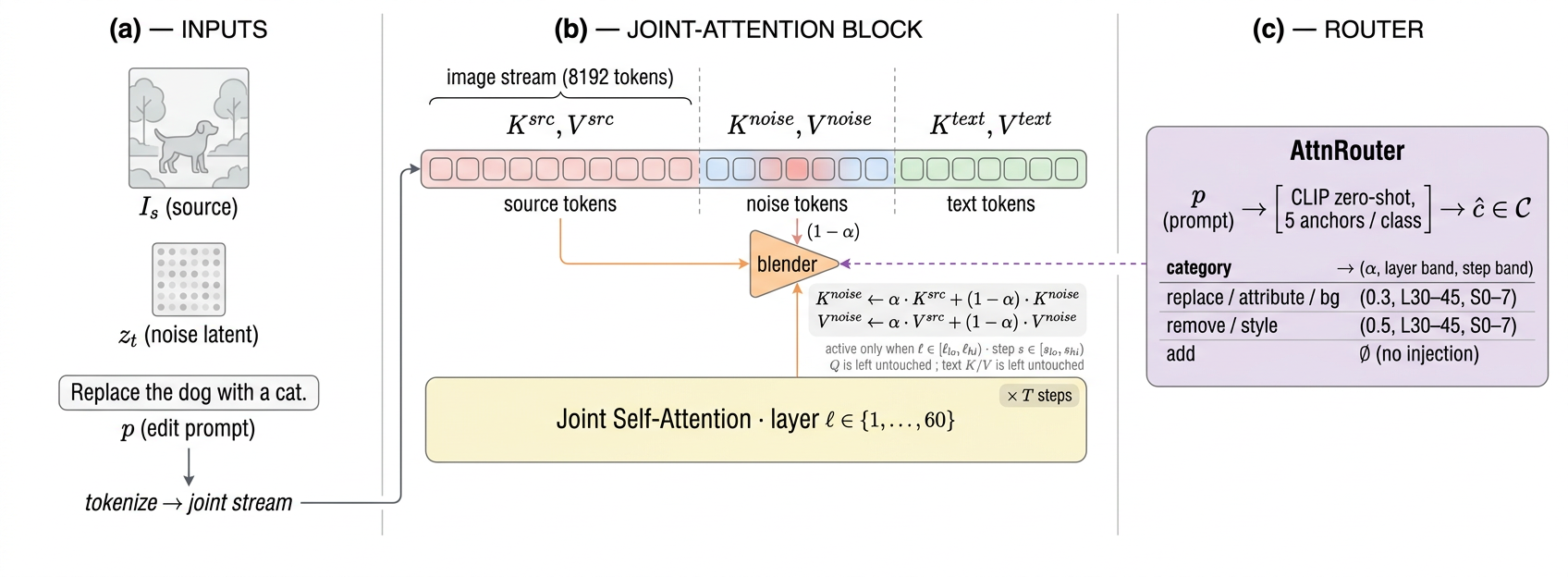
Figure 1: End-to-end pipeline: tokens from source image and noise are encoded in a shared latent, concatenated for joint attention; KVInject blends keys/values in noise stream toward source within a local layer/step band; AttnRouter selects configuration per edit category.
Methods
KVInject: Attention-Level α-Blend Operator
KVInject replaces classical two-pass attention control by blending source-half key/value projections into the noise-half with an α-weighted scheme, restricted to configurable layer and step bands. Unlike MasaCtrl, which relies on attention map caching in a neutral prompt forward, KVInject deploys the edit-prompt forward for blending, leveraging semantically aligned source token representations. This direct approach eliminates brittle dependency on extra passes and decouples editing efficacy from prompt matching.
Algorithmically, for a given band, KVInject operates:
Knoise′=αKsrc+(1−α)Knoise
applied only to the noise stream, maintaining text-token projections untouched.
AttnRouter: Per-Category Operation Routing
Extensive empirical evaluation demonstrates that attention-manipulation preferences are highly category-dependent. AttnRouter systematizes routing across edit categories via a discrete lookup table mapping category labels to optimal KVInject configurations or to no-edit baselines. Deployment leverages an auto-classifier—based on CLIP zero-shot prediction—which closely approximates oracle routing performance due to high route overlap across confusable categories.
Routing decisions are made at inference using stratified anchor sentence centroids in CLIP text space, yielding robust and efficient test-time operation selection without retraining or gradient search.
Empirical Results
Composite Metric Improvement and Ablations
Main results indicate that:
- KVInject with optimal configuration (typically α=0.3, layers 30--45) increases composite score by 3.8%.
- AttnRouter (oracle) achieves a 6.4% gain, while auto-routing with CLIP classifier (55% accuracy) attains 98% of oracle performance, owing to route-sharing among categories.
Classical MasaCtrl, transplanted from UNet, degrades composite score by 31% due to the neutral prompt's failure in yielding useful K/V for injection in MMDiT.
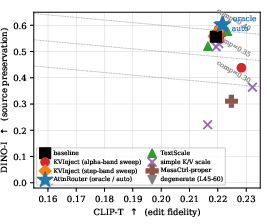
Figure 2: CLIP-T vs. DINO-I scatter: AttnRouter (blue stars) reaches highest iso-composite contours; MasaCtrl (brown plus) collapses along source preservation axis.
Ablation studies further resolve:
- Editing effectiveness is sharply localized to layers 30--45 and denoising steps 0--7; injection outside these bands produces near-identity images or fails to enact edits.
- Composite scores peak for α in [0.3,0.5], with over-injection (α=0.7) causing prompt-aligned degeneration.
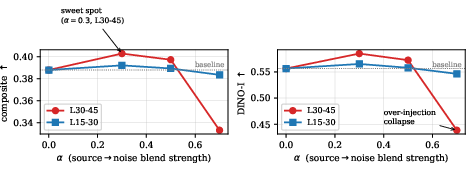
Figure 3: α-sweep curves indicate optimal editing at α=0.3 in layers 30--45; excessive blending collapses source preservation.
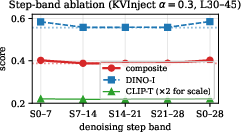
Figure 4: Step-band ablation reveals that gains are confined to early denoising steps S0--7; later steps return to baseline.
Comparative Attention Visualization
KVInject produces structured noise-to-source attention maps, with strong diagonals and regionally salient off-diagonal peaks. Cosine similarity between noise and source keys/values dips most in layers 30--45, aligning with the quantitative ablation.
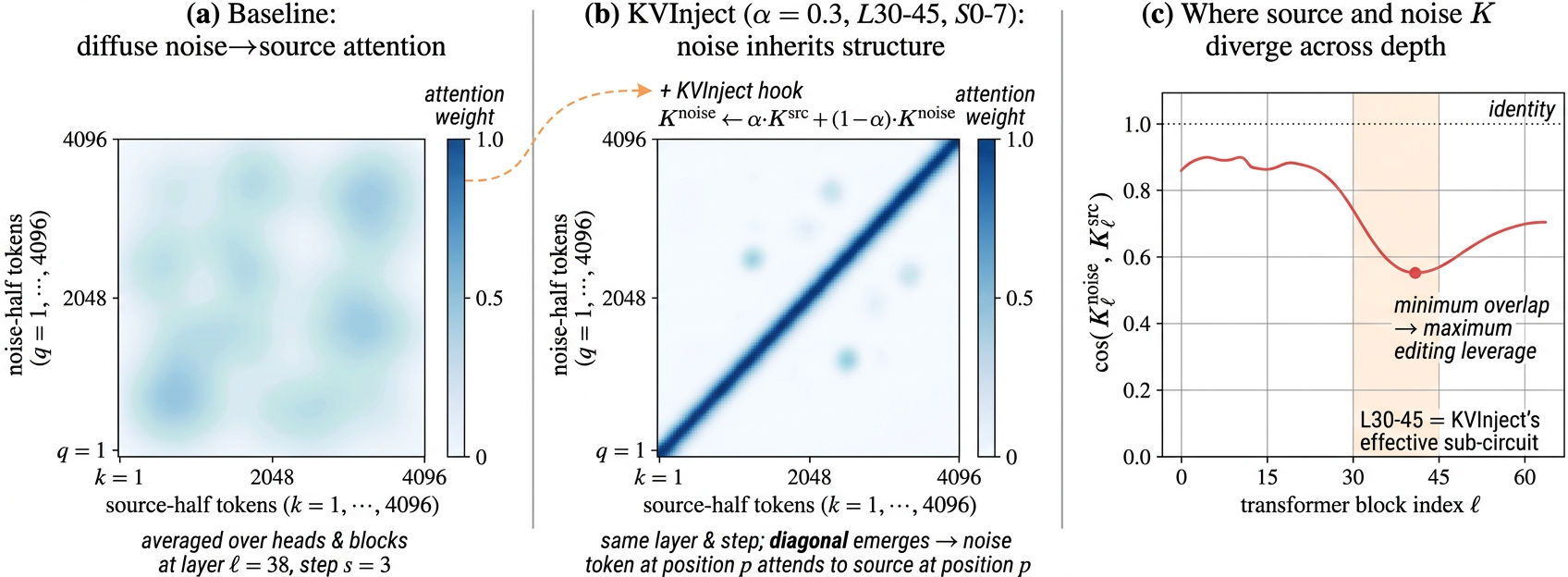
Figure 5: Schematic visualization: baseline maps diffuse; KVInject induces noise-to-source correspondence; maximal divergence in layers 30--45.
Per-Category Analysis
Router-based configuration yields highest gains for style edits (+24%), modest for attribute/background, and negligible for add edits. Injecting source K/V is counterproductive for add, as it suppresses content insertion; hence, baselines are preferred.
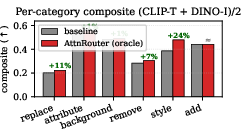
Figure 6: Per-category composite improvement: style edits benefit most from AttnRouter, add edits show no improvement.
Qualitative results substantiate router's superior preservation of background/identity in style, attribute, and background edits versus baseline or single static operation.

Figure 7: Qualitative comparison grid: AttnRouter maintains source structure in edits where baseline fails.
Discussion
The findings confirm that MMDiT fundamentally alters training-free editing—requiring manipulation of tightly co-attended source and noise streams rather than orthogonal self-/cross-attention levers. KVInject's same-forward blending exploits source token semantic alignment in the edit context, eliminating failure modes associated with neutral prompt inversion. The per-category routing paradigm outperforms any single operator, revealing operational heterogeneity across edit types.
Negative results, including MasaCtrl underperformance and K/V rescaling collapse, highlight that UNet-era folklore is non-transferable to transformer-based diffusion. The robust efficacy of AttnRouter with imperfect classifiers advances test-time adaptability for editors, pointing to practical deployment routes.
Avenues for future research include regionally masked KVInject variants, per-step α scheduling, and differentiable router heads, which enable finer adaptation and performance improvement. Extension to other MMDiT backbones and evaluation on additional benchmarks will further cement these insights.
Conclusion
The paper provides a systematic blueprint for training-free image editing in transformer-based diffusion models, introducing KVInject for efficient attention blending and AttnRouter for category-aware operation routing. Structured ablations localize editing utility to specific layers and steps, and per-category routing achieves significant gains in composite metrics, with rapid auto-classification approximating oracle performance. The insights and protocols outlined redefine attention manipulation for image editing in MMDiT architectures and establish practical, robust avenues moving forward.

