- The paper introduces a novel adapter stack retrofitted onto frozen DiTs, decoupling semantic instructions from spatial location cues.
- It employs a learned MaskPredictor and SpatialGate to achieve precise, mask-free local edits, reducing L1 error by 43%.
- Empirical evaluations show enhanced edit fidelity and preservation of unedited regions, outperforming conventional mask-based methods.
Region-Aware Adapter Injection for Mask-Free Local Image Editing
Introduction and Motivation
Instruction-driven local image editing with diffusion transformers (DiTs) has attained considerable practical importance but still presents critical limitations. Standard architectures, especially those employing joint-attention over concatenated image and text tokens, lack explicit mechanisms to localize edits spatially. This results in semantic “leakage,” where edits intended for a specific region (e.g., "remove hand sanitizer") propagate into unrelated areas, violating the expected locality of user instructions. While mask-based solutions provide spatial control, they necessitate high-quality, user-supplied masks—an impractical requirement at scale due to annotation overhead and failure modes in automatic segmentation.
Figure 1: Vanilla DiTs diffuse local instruction into surrounding pixels, while the proposed method factorizes "what" (instruction) from "where" (mask), injects both via adapter/gate modules, and grounds the spatial region with a learned MaskPredictor—eliminating the user mask requirement at deployment.
This paper introduces a co-trained, instruction- and region-aware adapter framework (“Ours”) for local editing in frozen DiTs. The approach injects spatial and semantic guidance separately at every transformer block, uses a learned SpatialGate to selectively route editing, and a MaskPredictor for mask-free inference. The end result is spatially precise, mask-free, instruction-guided image editing with strong edit fidelity and preservation of unedited regions.
Architecture and Methodology
System Overview
The core contribution is a parameter-efficient adapter stack retrofittable onto a frozen multi-billion parameter DiT backbone. Five principal, jointly trained components comprise the system:
- Block Adapter: At every DiT block, a cross-attention adapter injects a structured condition stream, fusing spatial and semantic cues; only adapter parameters are trainable.
- Condition Encoder: The edit mask is encoded into spatial tokens; instruction encoder hidden states are compressed via Perceiver cross-attention into semantic tokens. Both are fused in a lightweight transformer and injected at every block.
- SpatialGate: Produces soft, per-token gates to apply the adapter signal to the edit region, preserving the rest of the image through identity mapping—effectively “editing where you mean.”
- Region-Aware Loss: Focuses optimization on the edit region by reweighting gradients via the mask, avoiding dilution of the learning signal across unchanged pixels.
- MaskPredictor: A lightweight head that grounds the edit region directly from source image and instruction, enabling fully mask-free deployment.
Figure 2: Training and inference pipeline: spatial/semantic tokens are encoded, fused, and injected with adapters and SpatialGate; MaskPredictor enables user-free region grounding at inference.
This architecture explicitly separates “what” (instruction semantics) from “where” (location), with the fusion transformer learning the interaction between instruction and spatial tokens.
Training and Inference
The system is trained on (source, instruction, target, mask) tuples. During training, the backbone remains entirely frozen; only adapter-stack modules are updated. For inference, the MaskPredictor predicts the edit mask from the instruction and source image without any user-supplied mask. A region-aware loss amplifies the gradient signal in the changing region vs. background, accelerating convergence and improving local precision.
Ablation and Parameter Efficiency
A systematic ablation across 7 architectural variants demonstrates that each module (Block Adapter, Region-aware Loss, SpatialGate, MaskPredictor) boosts local edit performance, and their composition yields super-additive improvements. The adapter-stack overhead is moderate (∼25% of backbone parameters) and does not require gradient updates in the main DiT backbone.
Empirical Evaluation
Datasets and Metrics
Evaluations are performed on two complementary benchmarks:
- MagicBrush: Paired, human-annotated testbed for pixel-level preservation and edit accuracy.
- Emu-Edit Test: A suite of 9 instruction categories (no GT target), designed to stress instruction-following and generalization.
Metrics include L1/L2 pixel differences (lower is better), CLIP image similarity (CLIP-I, higher is better), DINO similarity, and CLIP-T (text/image alignment with target caption, higher is better).
Main Results
The proposed method attains column-maximal L1 reductions and top-2 preservation scores on MagicBrush and Emu-Edit, outperforming both contemporary mask-free and oracle-mask methods. Notably, compared to the unadapted DiT backbone, L1 is reduced by 43%. Against the oracle-mask UltraEdit baseline, further gains are observed, notably -33% L1 and substantial improvements in CLIP-I and DINO similarity. On GEdit-Bench-EN, the framework achieves the highest reported semantic correctness and perceptual quality (G_SC=8.44, G_PQ=8.73).
Qualitative Results and Mask Robustness
Qualitative comparisons exhibit precise region-localized edits and near-pixel-perfect preservation outside the edit, whereas baselines frequently introduce global drift or fail to confine changes. The system’s mask robustness analysis demonstrates monotonic metric degradation under mask perturbations, indicating reliable fallbacks, and shows that the predicted mask from MaskPredictor matches the error introduced by minor morphological perturbations to ground-truth masks.
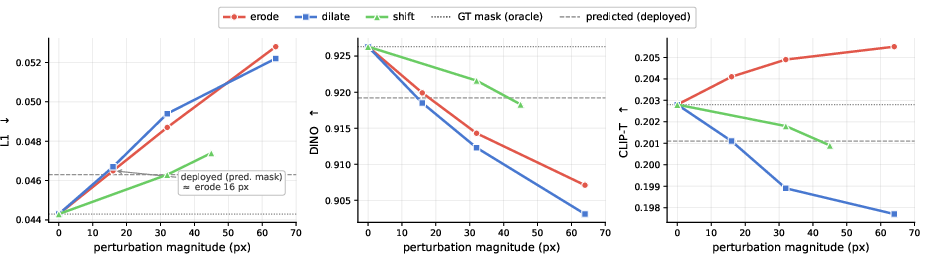
Figure 3: Sweeping perturbations to the ground-truth mask confirms monotonic performance degradation and minimal gap between the predicted mask and oracle-masked configurations.

Figure 4: MaskPredictor convergence: as training proceeds, predicted masks align closely with ground truth, supporting mask-free local editing.
Figure 5: Qualitative comparison on MagicBrush dev: the proposed system preserves unedited regions and applies edits as instructed, whereas baselines tend to over-edit or mis-localize.
Implications, Limitations, and Future Directions
Practical Impact
The region-aware, mask-free editing capability has direct applicability in commercial creative workflows, rapid product retouching, and iterative advertisement design—domains that critically benefit from precise, non-destructive local editing. By decoupling edit spatiality from explicit manual annotation, the approach overcomes the scale and friction limitations of prior mask-conditioned protocols.
Theoretical Significance
This work demonstrates that explicit, fine-grained spatial conditioning—injecting “what” and “where” cues separately and throughout the model—remediates the implicit spatial ambiguity of joint-attention architectures, even at considerable backbone scales. The design also validates that parameter-efficient, non-disruptive adapters can successfully retrofit spatial locality into frozen DiT backbones, without necessitating task- or data-specific full retraining.
Limitations and Open Challenges
- The approach presumes edits with well-localized spatial anchors. Global-style or distributed edits are less well constrained and may warrant falling back to the base model.
- Single-mask encoding can underperform in multi-object or complex-region edits.
- MaskPredictor performance diminishes on instructions lacking spatial specificity.
- The system inherits biases in underlying DiT backbones and is currently resource-intensive (requiring >70GB memory during training).
Future Work
- Extension to per-object or multi-region conditioning streams for compositional/multi-instruction edits.
- Exploration of per-block vs. shared condition streams for even finer spatial control.
- Incorporation of uncertainty-aware region prediction and self-correcting mask generation.
- Integration with provenance and watermarking technologies to mitigate disinformation risks.
Conclusion
This work rigorously isolates and solves spatial leakage in diffusion transformer-based image editing via a mask-aware, modular adapter stack and learned MaskPredictor, enabling mask-free, spatially precise, instruction-guided editing. The method sets new state-of-the-art in multiple local-edit benchmarks, validating both its theoretical premise and practical utility. The principled decoupling of spatial and semantic conditioning, together with direct edit-region grounding, establishes a new paradigm for parameter-efficient adaptation of large generative backbones and charts several directions for future research in controllable image generation and editing.
Reference:
“Edit Where You Mean: Region-Aware Adapter Injection for Mask-Free Local Image Editing” (2604.23763)