- The paper introduces a three-stage framework that integrates outcome-guided rationale generation with Direct Preference Optimization to enhance clinical prediction accuracy.
- It uses synthetic and challenging sample re-generation along with an iterative refinement (iReMedi) to tackle prediction tasks for mortality, readmission, and length-of-stay.
- Experimental results show significant improvements, including up to 19.9% F1 gain in length-of-stay prediction and enhanced interpretability compared to prior methods.
ReMedi: Advancing LLM-Based Clinical Prediction Through Outcome-Guided Reasoning
Motivation and Context
The clinical outcome prediction tasks—mortality, readmission, and length-of-stay forecasting using EHRs—demand architectures that handle heterogeneous, structured input while offering robust medical interpretability. Prior approaches mainly rely on retrieval-augmented generation (RAG), medical graph distillation, or direct prompting of general-purpose LLMs, leading to underutilization of models’ intrinsic reasoning abilities and challenges in alignment between generated rationales and predictions. Existing solutions such as KARE require proprietary teacher models and predefined ontologies, limiting adaptability and real-world scalability. ReMedi introduces a new framework with a focus on outcome-guided reasoning, directly integrating ground-truth supervision and preference optimization into fine-tuning.
Architecture Overview
ReMedi’s pipeline operates in three stages—Sample Generation, Challenging Sample Re-Generation, and Model Training—augmented by a warm-start phase and an iterative refinement variant, iReMedi. The workflow capitalizes on generating rationale-answer pairs, harnessing both ground-truth-aligned and challenging samples, and optimizing via supervised fine-tuning (SFT) followed by Direct Preference Optimization (DPO).
The initial stage creates rationale-answer pairs using a base LLM, filtered for correctness. Incorrect samples are paired with their ground-truth counterpart and integrated into DPO datasets to enrich preference signals. Challenging queries undergo label rationalization, repeated sampling, and explicit filtering to avoid reasoning that merely parrots ground-truth hints. Synthetic data from these processes is subsequently leveraged for SFT and DPO. Iterative refinement via iReMedi executes the cycle repeatedly, each time reinitializing from the base model to prevent overfitting and encourage generalization.
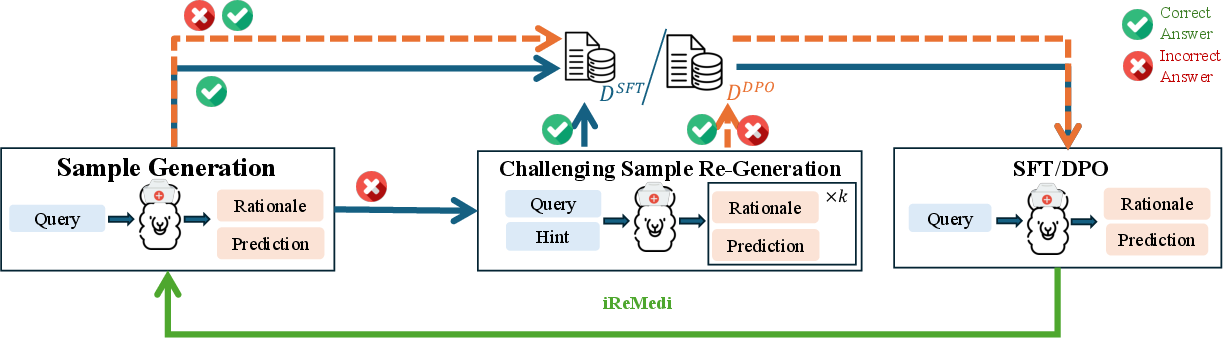
Figure 1: Overview of ReMedi, which operates iteratively across three stages: sample generation, challenging sample re-generation, and model training via SFT/DPO.
Experimental Evaluation
Dataset and Task Specification
The evaluation protocol employs the MIMIC-IV dataset with rigorous class balancing and standardized splits for mortality, readmission, and length-of-stay prediction. Tasks are formulated as multi-class or binary classification, with medical codes mapped to natural language via Clinical Classifications Software and medication encoded using the ATC system.
Baseline Comparisons
ReMedi is benchmarked against both prompting-based and fine-tuned LLMs, ranging from Gemini-2.5-Flash, MedReason, MedGemma, HuatuoGPT variants, and knowledge-distilled models like KARE. Prompting-based LLMs, even with reasoning traces, exhibited near-random guessing due to insufficient domain adaptation and reasoning alignment. Fine-tuned models show incremental improvements, but fall short on challenging task nuances.
Numerical Results and Component Analysis
ReMedi delivers impressive improvements: up to 19.9% F1 gain in length-of-stay, with iReMedi further enhancing performance. For mortality and readmission, accuracy gains versus KARE reach 1.8% and 9.1%, with iReMedi consistently producing further increments. Ablation studies demonstrate the critical contribution of DPO and challenging sample re-generation—removing DPO leads to significant F1 reduction, and direct application of general-domain techniques like STaR yields only marginal gains (e.g., 59.1% accuracy vs 90.5% in ReMedi), validating ReMedi's specialized architecture.
Alignment Assessment and Case Analysis
Manual and model-based evaluation of alignment between rationale content and prediction labels reveals that ReMedi not only improves quantitative metrics but also achieves superior interpretive consistency compared to KARE, particularly in nuanced cases (such as readmission risk assessment with confounding chronic conditions). Case studies demonstrate ReMedi’s ability to differentiate subtle clinical trajectories, yielding better risk stratification and prediction coherence. For instance, where prior LLMs over-predict risk due to chronic comorbidities, ReMedi can incorporate the lack of acute exacerbation signals and recent management history for more accurate predictions.
Practical and Theoretical Implications
ReMedi’s outcome-guided rationale generation and DPO fine-tuning constitute a robust pattern for clinical domain adaptation, emphasizing task-specific alignment and leveraging difficult cases to drive learning efficiency. The modular design, combining SFT and DPO, provides a scalable template for broader healthcare prediction applications. The iterative variant (iReMedi) points towards future directions in progressive refinement, potentially extending to open-ended clinical reasoning or multimodal medical prediction. The framework highlights the inadequacy of generic self-improvement strategies for specialized medical reasoning and underscores the importance of leveraging domain-specific supervision and challenging queries.
Limitations and Future Directions
Key limitations include residual rationale-prediction misalignment, restricted evaluation to traditional prediction tasks with well-defined outcome labels, and scalability issues related to model size (as the study focuses on HuatuoGPT-o1-7B). Systematic investigation of clinical correctness with domain experts and adaptation for large-scale models remain open directions. Expansion into more complex, open-question domains and integration with multimodal data (e.g., imaging, clinical notes) is a natural progression.
Conclusion
ReMedi establishes a high-performance paradigm for LLM-based clinical outcome prediction, deploying outcome-guided rationale generation and preference optimization to capitalize on modeling difficult queries. With empirically validated gains across standard benchmarks, the framework demonstrates both enhanced predictive performance and coherent reasoning interpretability. Future work will need to address broader clinical reasoning tasks and scalability across larger models and multimodal inputs.