Reason2Decide: Rationale-Driven Multi-Task Learning
Abstract: Despite the wide adoption of LLMs (LLM)s, clinical decision support systems face a critical challenge: achieving high predictive accuracy while generating explanations aligned with the predictions. Current approaches suffer from exposure bias leading to misaligned explanations. We propose Reason2Decide, a two-stage training framework that addresses key challenges in self-rationalization, including exposure bias and task separation. In Stage-1, our model is trained on rationale generation, while in Stage-2, we jointly train on label prediction and rationale generation, applying scheduled sampling to gradually transition from conditioning on gold labels to model predictions. We evaluate Reason2Decide on three medical datasets, including a proprietary triage dataset and public biomedical QA datasets. Across model sizes, Reason2Decide outperforms other fine-tuning baselines and some zero-shot LLMs in prediction (F1) and rationale fidelity (BERTScore, BLEU, LLM-as-a-Judge). In triage, Reason2Decide is rationale source-robust across LLM-generated, nurse-authored, and nurse-post-processed rationales. In our experiments, while using only LLM-generated rationales in Stage-1, Reason2Decide outperforms other fine-tuning variants. This indicates that LLM-generated rationales are suitable for pretraining models, reducing reliance on human annotations. Remarkably, Reason2Decide achieves these gains with models 40x smaller than contemporary foundation models, making clinical reasoning more accessible for resource-constrained deployments while still providing explainable decision support.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Brief Overview
This paper introduces a way to train AI models so they can both make accurate decisions and clearly explain why they made those decisions. The method is called Reason2Decide. It’s especially focused on healthcare tasks (like nurse triage and medical questions), where explanations are important for trust and safety.
Key Objectives and Questions
The researchers wanted to solve two big problems:
- Models often learn to explain only the “correct” answers seen during training, but in real life they must explain their own guesses—which can be wrong. This mismatch is called exposure bias.
- Many systems treat “prediction” and “explanation” as separate tasks, so the explanation doesn’t always match the prediction.
In simple terms: Can we train a model to make a decision and explain it in a way that fits the decision—even when the decision is imperfect?
Methods and Approach (Explained Simply)
Think of the model like a student learning math:
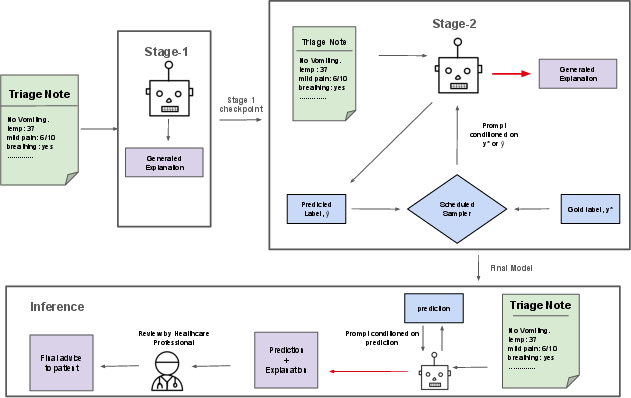
- Stage-1: Learn “how to show your work.” The model practices writing good explanations (called rationales) for medical decisions, without worrying about making the decision itself yet. This builds a foundation for clear reasoning.
- Stage-2: Do both the “answer” and the “show your work” together. The model predicts the label (for example, “go to the emergency department” vs “home care”) and then explains why.
A key idea they use is called scheduled sampling. Here’s an analogy:
- Training wheels: At first, the model explains using the correct labels provided by the teacher (gold labels).
- Gradual independence: Over time, the model more often explains using its own predicted labels (its guesses), not just the teacher’s. This prepares it for real-world use, where it must explain its own decisions—even if they’re not perfect.
They tested this with different sizes of a popular model family (T5-Small, T5-Base, T5-Large) and compared against other training methods and big “zero-shot” models (which aren’t fine-tuned for the task).
Tasks and Data (short and simple)
They tried Reason2Decide on:
- Clinical triage notes: Given a nurse’s note, predict the care recommendation (like “go to ED now”) and explain the decision.
- PubMedQA: Medical yes/no/maybe questions with explanations.
- BioASQ yes/no: Medical questions with supporting text snippets (used as rationales).
They also tested different sources of explanations:
- Written by nurses
- Edited by an AI for grammar
- Fully generated by an AI
Main Findings and Why They Matter
- Better predictions and explanations: Reason2Decide beat other fine-tuning methods in both accuracy (especially Macro-F1, a fairness-focused metric that treats all classes more equally) and explanation quality (using measures like BERTScore and BLEU, which check how similar the generated explanation is to a good one).
- Explanations match decisions more closely: By training the model to explain its own predictions, the rationale aligns with the label more consistently. This reduces “contradicting” explanations (like explaining why it’s urgent while predicting a low-urgency label).
- Works across different rationale sources: Even when Stage-1 used only AI-generated explanations, the model still improved—suggesting we don’t always need expensive human-written rationales to pretrain.
- Smaller models can do well: Their 800M-parameter T5-Large (about 40× smaller than some big foundation models) still performed strongly. That’s good news for hospitals or clinics with limited computing resources.
- Strong across multiple medical datasets: The approach improved results on clinical triage and medical QA tasks, showing it can generalize across different kinds of healthcare language.
Implications and Potential Impact
- More trustworthy AI in healthcare: When a model’s explanation matches its decision, doctors and nurses can better understand and verify the reasoning, which builds trust.
- Lower cost and wider access: If good performance is possible with smaller models and AI-generated explanations, hospitals and clinics with fewer resources can still use helpful decision support tools.
- Better training strategy: Teaching models to “explain their own answers” during training prepares them for real-world use, where their predictions won’t always be perfect.
- Next steps: The authors suggest expanding to other medical areas, trying different types of reasoning (like step-by-step “Chain-of-Thought”), optimizing training settings, and adding more human evaluation—important in high-stakes domains.
In short, Reason2Decide trains AI to both decide and explain in a way that fits together, making medical decision support more accurate, understandable, and practical.
Knowledge Gaps
Below is a concise, actionable list of knowledge gaps, limitations, and open questions left unresolved by the paper:
- Generalization beyond evaluated tasks: No evidence the approach works for other clinical NLP settings (e.g., diagnosis coding, temporal prognosis, multi-label phenotyping, report generation) or non-clinical domains; evaluate transfer to varied tasks, label granularities, and formats.
- Out-of-distribution robustness: No tests under domain shift (new hospitals, note styles, dialects, abbreviations) or temporal drift; assess performance under OOD inputs and update strategies.
- Low-resource regimes: Limited exploration of data-scarce settings (only a 12% robustness subset); quantify data-efficiency and minimum human-rationale requirements for Stage-1/Stage-2.
- Rare/critical classes: No per-class analysis for highly imbalanced triage labels; report class-wise recall/precision, error types, and cost-sensitive or clinically weighted metrics for high-acuity classes.
- Faithfulness vs. similarity: Rationale evaluation relies on BERTScore/BLEU/LLM-judge; add causal faithfulness tests (sufficiency/comprehensiveness, input occlusion, counterfactuals) to ensure explanations truly support predictions.
- Human evaluation: No clinician-in-the-loop assessment; conduct blinded expert studies for correctness, clinical utility, and trust calibration, including inter-rater reliability and sample size justification.
- LLM-as-a-Judge validity: Single-judge, single-family scorer (Qwen-3-8B) risks bias and circularity (also used to generate/summarize rationales); compare multiple judges, calibrate to human ratings, and report agreement statistics.
- Justification of wrong predictions: Task-level scheduled sampling conditions rationales on model-predicted labels, potentially training the model to justify errors; quantify contradiction rates and harm of plausible-but-wrong rationales.
- Confidence-aware conditioning: Scheduled sampling probability is fixed by a linear schedule; explore conditioning decisions based on uncertainty/confidence (e.g., use gold labels when low confidence) and compare schedules (inverse-sigmoid, cosine).
- Capping at 0.9: The 0.9 ceiling is heuristic; perform sensitivity analysis and principled selection (e.g., validation-based or Bayesian optimization) of this cap.
- Loss weighting (αt) heuristic: Warm-up and αt=0.7 are chosen heuristically; optimize and report sensitivity across datasets and model sizes; examine dynamic weighting (e.g., uncertainty- or gradient-norm-based).
- Decoding choices: Only greedy decoding is used for both training (predicted labels) and inference; assess beam search, stochastic decoding, and calibration-aware decoding for labels and rationales.
- Training-time compute and cost: Training overhead is acknowledged but unquantified; report wall-clock time, GPU-hours, memory footprints, and cost comparisons vs. baselines.
- Architectural scope: Only T5 variants are evaluated; assess broader architectures (encoder-only, decoder-only, multimodal EHR models), parameter-efficient tuning (LoRA/adapters), and two-head vs. shared-head variants.
- Comparison breadth: Baselines exclude other exposure-bias mitigations (professor forcing, scheduled sampling variants, data noising), rationale-consistency objectives, or ERASER-style methods; include stronger, diverse baselines.
- Causal effect of rationales on predictions: Inference predicts then explains; investigate architectures where generated intermediate rationales influence/iterate prediction (rationale-then-decide loops) and test causal impact.
- Rationale source quality: While source robustness is tested, no quantitative study of how noise/quality of LLM rationales in Stage-1 affects outcomes; simulate noise, measure degradation, and estimate required quality thresholds.
- Data contamination risks: PubMedQA artificial split and pretrained model corpora may overlap; check for leakage and report contamination analysis.
- Safety and bias: No subgroup fairness or bias analysis (age, sex, socio-demographics) and no harm/risk assessment; evaluate disparities and implement mitigation strategies.
- Adversarial/noisy inputs: No tests for robustness to typos, irrelevant info, or adversarial prompts; evaluate and harden the system against realistic clinical note noise.
- Calibration and uncertainty: No probability calibration or selective prediction analysis; measure ECE, AUROC, abstention strategies, and how rationales affect user trust when the model is uncertain.
- Error analysis and failure modes: Limited qualitative analysis; systematically categorize frequent errors (label confusions, contradiction between rationale and prediction, hallucinations) and tie them to data/model factors.
- Multilingual/generalization across languages: Only English datasets; assess cross-lingual transfer and domain-translation challenges in multilingual clinical contexts.
- Privacy and deployment: Although de-identified data is used, there’s no assessment of privacy leakage in rationales or secure deployment considerations; evaluate PHI risks and mitigation (e.g., redaction).
- Reproducibility and data access: Proprietary triage dataset and LLM-generated rationales limit third-party verification; release synthetic surrogates, detailed prompts, and seeds for stronger reproducibility.
- Downstream clinical impact: No evaluation of how the system affects clinician decisions, workflow time, or patient outcomes; run user studies or simulations to quantify real-world utility.
- Aloe-8B outperformance on BioASQ: The domain-pretrained zero-shot model beats fine-tuned T5 on BioASQ; analyze when domain pretraining outweighs multi-task rationale training and combine both strategies.
- Scaling laws and efficiency: No analysis of performance vs. model/data scale or the cost/benefit of Stage-1 duration; provide scaling curves and early-stopping guidance.
- Metric selection for triage: Macro-F1 is primary but clinical risk may be asymmetric; incorporate clinically meaningful utility metrics and decision-curve analysis.
Practical Applications
Below are practical applications derived from the paper’s findings, methods, and innovations in Reason2Decide, organized by deployment horizon.
Immediate Applications
The following applications can be implemented with existing models, code, and workflows, subject to standard integration and governance practices:
- Clinical triage decision support for nurse call centers (Healthcare) — Description: Integrate Reason2Decide into triage software to provide a recommended disposition plus a label-conditioned rationale aligned to the prediction; use the rationale to improve trust and handovers. — Potential tools/products/workflows: Fine-tuned T5-Base/T5-Large models; “predict → explain” pipeline; audit log of rationales; greedy decoding for determinism; LLM-as-a-Judge scoring for QA. — Assumptions/dependencies: De-identified notes; human-in-the-loop verification; local GPU/CPU capacity; domain calibration to the organization’s disposition taxonomy; compliance with clinical governance.
- Clinical documentation assistant for encounter notes (Healthcare) — Description: Draft clinician-facing rationale snippets that justify recommended actions and capture salient symptoms/findings; clinicians edit/accept before filing. — Potential tools/products/workflows: EHR plug-in generating “disposition + rationale”; staged workflow with mandatory human review. — Assumptions/dependencies: Integration with EHR; style/terminology guidelines; institutional policy on AI-authored text; ability to restrict model output to safe, conservative language.
- Internal quality assurance and audit of reasoning consistency (Healthcare; Policy) — Description: Score explanation quality (coverage, correctness, overlap) on sampled cases to monitor prediction–rationale alignment and identify failure modes. — Potential tools/products/workflows: Automated QA harness using LLM-as-a-Judge; dashboards tracking Macro-F1 and rationale metrics; spot-check workflows for clinical leads. — Assumptions/dependencies: Validated rubrics; periodic human adjudication to calibrate LLM-as-a-Judge; clear escalation procedures.
- Synthetic rationale bootstrapping to cut annotation costs (Healthcare; Academia) — Description: Use LLM-generated rationales for Stage-1 pretraining, then fine-tune with limited human-rationale data in Stage-2; reduce reliance on expensive human annotations. — Potential tools/products/workflows: Prompted rationale generation with Qwen/Llama; staged pretraining pipeline; data governance for synthetic content. — Assumptions/dependencies: Synthetic rationale quality and domain fidelity; prompt safeguards to avoid hallucination; class balance and coverage in training data.
- Biomedical search and QA assistants with aligned explanations (Academia; Healthcare) — Description: Deploy PubMedQA-style yes/no/maybe answering with a concise rationale to support literature triage and clinician queries. — Potential tools/products/workflows: Browser plug-ins, intranet search tools; T5-based fine-tunes on PubMedQA/BioASQ; “predict → explain” UI cards. — Assumptions/dependencies: Domain adaptation to local queries; disclaimers; provenance display of source abstracts/snippets.
- Training and education for nurses and medical students (Healthcare; Education) — Description: Case-based learning tools that present a case, predicted disposition, and a rationale; learners compare/critique and receive feedback. — Potential tools/products/workflows: LMS modules; curated case banks; rationale critique exercises. — Assumptions/dependencies: Educator oversight; alignment to curricula; guardrails against misleading reasoning.
- Resource-constrained on-prem deployments (Software/IT; Healthcare) — Description: Replace large zero-shot LLMs with smaller T5 variants (e.g., 800M) fine-tuned via Reason2Decide to lower inference cost while maintaining explainability. — Potential tools/products/workflows: Containerized microservices; batch inference queues; model cards detailing performance and limitations. — Assumptions/dependencies: Adequate memory/compute; security hardening; monitoring for drift and data shift.
- Explainable classification in regulated domains (Finance; Insurance; Public sector) — Description: Adapt task-level scheduled sampling to produce label-aligned rationales for risk ratings (e.g., claim severity, fraud suspicion) to aid review. — Potential tools/products/workflows: Domain-specific fine-tunes; reviewer dashboards showing “decision + rationale + confidence”. — Assumptions/dependencies: Availability of labeled text and rationales (or synthetic); sector-specific compliance (e.g., fairness and auditability); human review.
- Research baselines and replicability (Academia) — Description: Use the open-source repository as a baseline for rationale-driven multi-task learning; replicate and extend scheduled sampling at task level. — Potential tools/products/workflows: Shared benchmarks; ablation templates; standard reporting (F1, BLEU, BERTScore, LLM-as-a-Judge). — Assumptions/dependencies: Access to datasets; license compliance; reproducible training seeds.
- Policy-aligned audit trails of reasoning (Policy; Governance) — Description: Store rationales alongside decisions to support internal audits and alignment with emerging AI assurance frameworks (e.g., EU AI Act, hospital governance). — Potential tools/products/workflows: Explainability logs; model governance “reasoning trail” review. — Assumptions/dependencies: Legal review of logging practices; retention policies; staff training on interpreting rationales.
Long-Term Applications
These require further research, data, validation, scaling, or regulatory clearance before broad deployment:
- Regulated clinical decision support integrated in EHRs (Healthcare; Policy) — Description: Real-time “predict → explain” recommendations embedded in clinician workflows with prospective validation and post-market monitoring. — Potential tools/products/workflows: FDA/EU MDR-aligned clinical studies; CDS Hooks integration; safety overrides; continuous audit. — Assumptions/dependencies: Clinical trials; strong human oversight; robust performance under distribution shifts; liability frameworks.
- Multi-modal reasoning across text, vitals, labs, and imaging (Healthcare; Software) — Description: Extend Reason2Decide to fuse structured and unstructured inputs and generate rationales referencing multiple modalities. — Potential tools/products/workflows: Multi-modal encoders; rationale schemas linking modalities; UI highlighting evidence spans. — Assumptions/dependencies: Data integration pipelines; annotation of multi-modal rationales; privacy and security controls.
- Standardized rationale quality benchmarks and schemas (Policy; Academia; Industry consortia) — Description: Sector-wide standards for explanation correctness, coverage, and fidelity; certification programs for explainable CDS. — Potential tools/products/workflows: Shared metrics and datasets; third-party auditing services; accreditation programs. — Assumptions/dependencies: Consensus on measures; human-in-the-loop validation; governance bodies.
- Rule-based and Chain-of-Thought rationale integration (Software; Academia) — Description: Combine clinical guidelines or rule engines with CoT-style rationales in Stage-1 to strengthen causal and guideline-based reasoning. — Potential tools/products/workflows: Hybrid “neuro-symbolic” rationale generators; guideline-aware prompts; guardrails to prevent spurious chains. — Assumptions/dependencies: Access to codified guidelines; measurement of causal validity; mitigation of label leakage.
- Continual learning with scheduled sampling in production (Software; MLOps) — Description: Online updates that maintain prediction–rationale alignment under drift, while controlling error amplification. — Potential tools/products/workflows: Drift detectors; shadow models; safe rollout via canary/A-B testing. — Assumptions/dependencies: Data versioning; rollback policy; privacy-preserving updates; explicit error ceilings.
- Domain expansion to radiology, pathology, pharmacy, and public health triage (Healthcare) — Description: Apply the framework to other clinical subdomains with specialized label sets and rationale conventions. — Potential tools/products/workflows: Subdomain datasets; annotator guidelines; specialty-specific UI designs. — Assumptions/dependencies: New labeled corpora; expert-defined rationales; subdomain performance baselines.
- Fairness, safety, and bias auditing via rationales (Policy; Compliance; Ethics) — Description: Use rationales to identify problematic reasoning (e.g., demographic proxies) and trigger review or override. — Potential tools/products/workflows: Explanation audit dashboards; bias detectors that parse rationales; governance workflows. — Assumptions/dependencies: Clear fairness definitions; diverse datasets; escalation paths; stakeholder review.
- Productized Explainable Decision API/SDK (Software; Platforms) — Description: Commercial APIs that return “label + rationale + confidence” with configurable scheduled sampling and evaluation tools. — Potential tools/products/workflows: Managed services; on-prem SDKs; multi-tenant governance. — Assumptions/dependencies: Security, privacy, and SLA guarantees; customer fine-tuning pipelines.
- Advanced educational tutors for biomedical and clinical reasoning (Education) — Description: Tutors that teach structured reasoning with feedback on rationale quality and alignment to correct answers. — Potential tools/products/workflows: LMS integrations; analytics on student rationales; adaptive curricula. — Assumptions/dependencies: Pedagogical validation; content licensing; assessment standards.
- Explainable decision support in finance and insurance (Finance; Insurance) — Description: Credit risk, underwriting, or claim triage decisions with transparent rationales to aid regulators and auditors. — Potential tools/products/workflows: Compliance dashboards; reason codes enriched with natural-language rationales. — Assumptions/dependencies: High-quality labeled corpora; fairness and transparency mandates; sector-specific regulation.
- Human–robot teaming with rationale transparency (Robotics; Safety-critical ops) — Description: Robots and autonomous systems present human-readable rationales for task selection or overrides to increase operator trust. — Potential tools/products/workflows: Operator interfaces; rationale summaries tied to sensor/state evidence. — Assumptions/dependencies: Mapping from system state to textual rationales; safety validation; real-time constraints.
- Operations alarm triage in energy and manufacturing (Energy; Industrial ops) — Description: Explainable classification of alarms/events with rationales to prioritize maintenance and safety actions. — Potential tools/products/workflows: Control-room assistants; ticketing integrations with “decision + rationale”. — Assumptions/dependencies: Domain-specific training data; integration with SCADA/EMS; safety certifications.
Notes on feasibility across applications:
- Human oversight is essential, especially in healthcare and other high-stakes domains.
- Synthetic rationales can pretrain Stage-1, but quality, domain fidelity, and prompt hygiene are critical.
- Performance depends on domain-specific datasets and label definitions; class imbalance may require tailored training.
- The LLM-as-a-Judge evaluation is useful but imperfect; periodic human calibration is needed.
- Two-stage training increases training cost but not inference cost; hyperparameters may need domain-specific tuning.
- Privacy, security, and regulatory compliance (e.g., FDA/EU AI Act) are decisive for real-world deployment.
Glossary
- AdamW optimizer: An optimization algorithm that decouples weight decay from gradient updates for training neural networks. "Training uses AdamW optimizer with learning rate , max input length = 1024, and effective batch size = 64."
- Autoregressive probability: The probability of a sequence computed by generating tokens one at a time conditioned on previous tokens. "denotes the autoregressive probability of the full rationale token sequence."
- BERTScore: A semantic similarity metric for text generation that compares embeddings of candidate and reference texts. "BERTScore (F1 variant): Semantic similarity between generated and gold rationales."
- BioASQ: A biomedical question answering benchmark used in shared tasks and evaluations. "Task: Biomedical question answering dataset from the BioASQ 13 challenge"
- BLEU: A metric measuring n-gram overlap between generated and reference text. "BLEU: N-gram overlap for surface-level quality."
- Chain-of-Thought (CoT) prompting: A prompting technique that elicits step-by-step reasoning in LLMs. "Chain-of-Thought (CoT) prompting demonstrates that step-by-step reasoning can improve complex reasoning"
- Clinical decision support systems: AI systems that assist healthcare professionals in making clinical decisions. "clinical decision support systems face a critical challenge: achieving high predictive accuracy while generating explanations aligned with the predictions."
- Cross-entropy loss: A standard loss function for classification and sequence prediction tasks. "optimized via cross-entropy loss:"
- Curriculum learning: A training strategy that presents tasks in increasing difficulty to improve learning and generalization. "a two-stage training regime, based on insights from curriculum learning"
- Distilling Step-by-Step (DSS): A training approach that distills rationale-guided reasoning from larger models into smaller ones. "Distilling Step-by-Step (DSS): Multi-task training following \cite{hsieh-etal-2023-distilling}."
- Disposition (care pathway): The recommended care pathway or action for a patient in triage settings. "predict a disposition (care pathway) and generate a rationale for the decision."
- Encoder–decoder architecture: A neural model design with separate encoder and decoder components for sequence-to-sequence tasks. "we employ a single encoder-decoder architecture (T5 variants) that handles both tasks."
- Exposure bias: The discrepancy caused by training models on gold contexts but testing on self-generated contexts. "Exposure bias in self-rationalization occurs when models are trained to generate explanations conditioned on gold labels but at inference time must justify their own predictions."
- Fine-tuning (SFT): Adapting a pre-trained model to a specific task using labeled data. "Standard fine-tuning (SFT): Single-task label prediction without rationales"
- Greedy decoding: A decoding strategy that selects the highest-probability token at each step without search. "During inference, we first predict the label via greedy decoding:"
- Knowledge distillation: Transferring knowledge from a larger teacher model to a smaller student model. "Closely related work includes knowledge distillation approaches that use rationales."
- LLMs: High-capacity neural models trained on vast text corpora to perform diverse language tasks. "Despite the wide adoption of LLMs', clinical decision support systems face a critical challenge"
- LLM-as-a-Judge: Using a LLM to assess the quality of model outputs (e.g., rationales). "LLM-as-a-Judge: Following recent work demonstrating strong alignment between LLM and human evaluation"
- Macro-F1: The average F1-score computed across classes, treating each class equally. "we primarily rely on Macro-F1."
- Multi-Task Learning: Training a model on multiple related tasks to improve generalization through shared representations. "Multi-Task Learning aims to improve generalization by leveraging shared representations across related tasks."
- Post-hoc explanation: Explanations generated after prediction by analyzing model internals or inputs. "post-hoc explanation generation by analyzing model internals or feature importance"
- PubMedQA: A biomedical question answering dataset focusing on yes/no/maybe decisions. "two public biomedical QA benchmarks (PubMedQA, BioASQ)."
- Rationale fidelity: The degree to which generated explanations match or justify the associated predictions. "rationale fidelity (BERTScore, BLEU, LLM-as-a-Judge)."
- Rationale-augmented training: Training that includes natural language explanations as additional supervision. "rationale-augmented training have also shown benefits"
- Scheduled sampling: A training technique that gradually replaces gold conditioning with model predictions to reduce exposure bias. "We introduce a scheduled sampling mechanism that gradually transitions from gold labels to predicted label conditioning, mitigating exposure bias in self-rationalization."
- Self-conditioning: Conditioning a model’s explanation generation on its own predicted outputs. "we gradually shift from gold-label conditioning to self-conditioning."
- Self-consistency: An inference-time technique that aggregates multiple reasoning paths to improve reliability. "self-consistency techniques show the value of aggregating multiple reasoning paths."
- Self-explaining models: Models designed to produce predictions and their rationales jointly. "self-explaining models that can learn to generate rationales simultaneously with their predictions."
- Self-rationalization: Training models to generate explanations aligned with their own predictions. "addresses key challenges in self-rationalization, including exposure bias and task separation."
- Teacher forcing: A training method that feeds gold tokens as previous inputs rather than model outputs. "Scheduled sampling addresses the issue by gradual replacement of teacher-forced tokens with model-generated ones."
- T5: A text-to-text transformer model widely used for multi-task NLP. "fine-tuned T5 models to generate explanations by treating them as a separate task."
- Text-to-text format: Framing diverse NLP tasks as text inputs mapped to text outputs. "into a unified text-to-text format."
- Triage (clinical triage): The process of assessing patient urgency and directing care pathways. "The Clinical Triage Dataset is derived from a Canadian provincial health service."
Collections
Sign up for free to add this paper to one or more collections.

