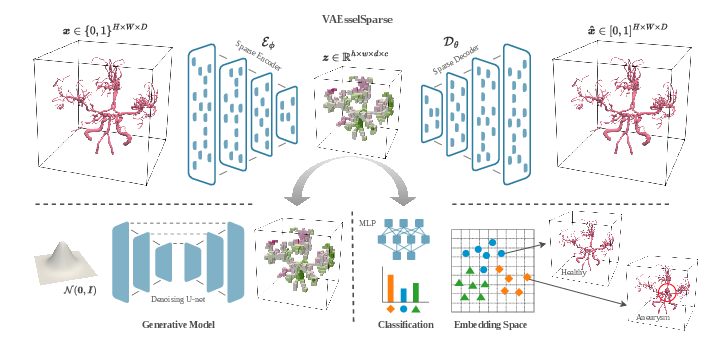
- The paper demonstrates that VAEsselSparse leverages sparse convolutions and transformer attention to efficiently model vessel masks, preserving fine anatomical details.
- It achieves superior reconstruction fidelity and topology preservation compared to dense VAEs, as evidenced by improvements in Dice, clDice, and Betti metrics.
- The discriminative latent space enables robust clinical classification and effective generative modeling, supporting applications in diagnosis and simulation.
Sparse Representation Learning for Vessels: Summary and Analysis of VAEsselSparse
Motivation and Context
Efficient modeling and analysis of vascular networks and other vessel-like anatomical structures are central in medical imaging for diagnosis, risk stratification, and treatment. Traditional generative and representation learning methods, often limited to tree-only or patch-based strategies, struggle to faithfully capture global topology and fine structure at clinically relevant (sub-millimeter) resolution. The inherent sparsity of vessel segmentation masks motivates a paradigm shift toward architectures capable of scaling with sparse volumetric data, ensuring both computational efficiency and preservation of clinically significant structure.
Architecture: VAEsselSparse
VAEsselSparse is presented as an encoder–decoder variational autoencoder that operates directly on sparse vessel segmentation masks, leveraging sparse convolutions and sparse attention mechanisms for both local and global feature abstraction. Unlike dense models, VAEsselSparse computes only over active voxels, achieving computational tractability even for large organ-level volumes.
Experimental Evaluation
VAEsselSparse demonstrates significant improvements in reconstruction fidelity and topology preservation compared to dense VAE baselines and MedVAE. Quantitative metrics (Dice, clDice, Betti errors) underscore superior performance at significantly higher compression and with fewer parameters. Qualitative samples from multiple datasets (COSTA, AIB, PARSE) validate these claims.
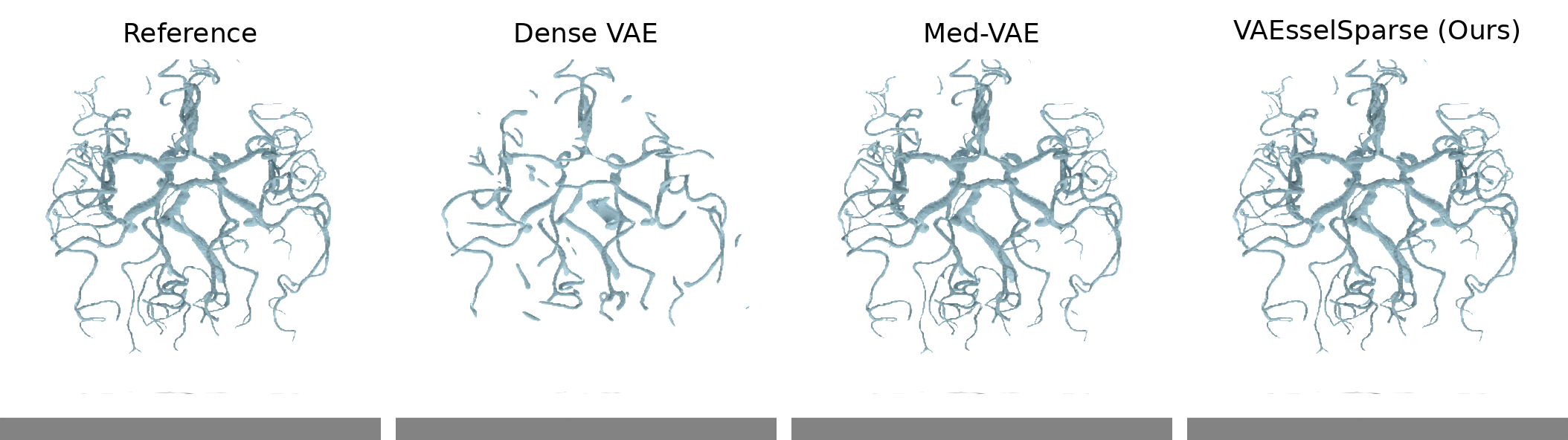
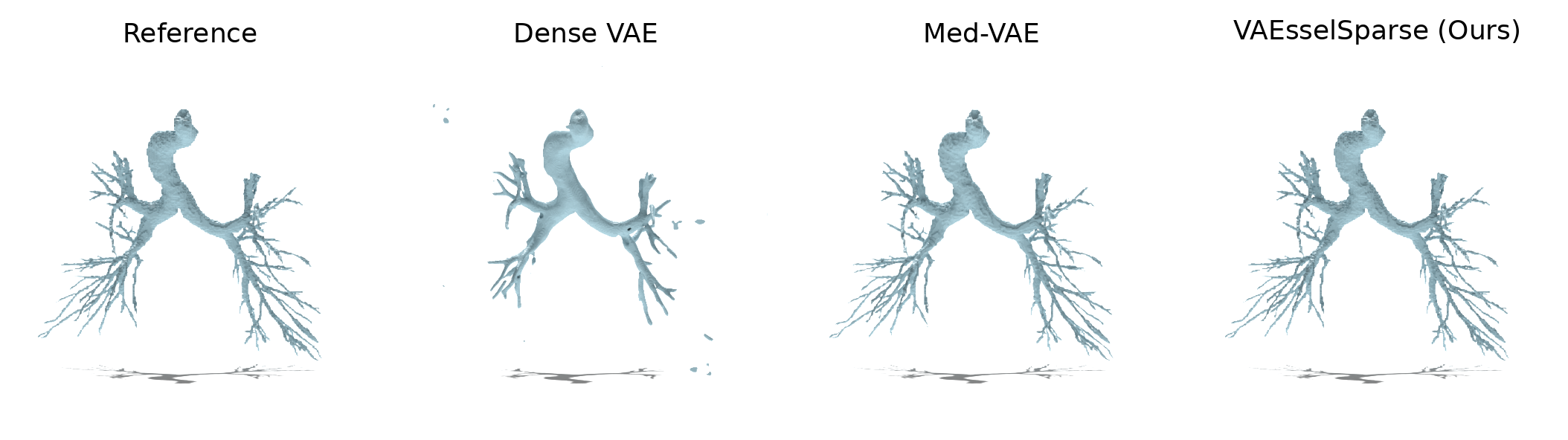
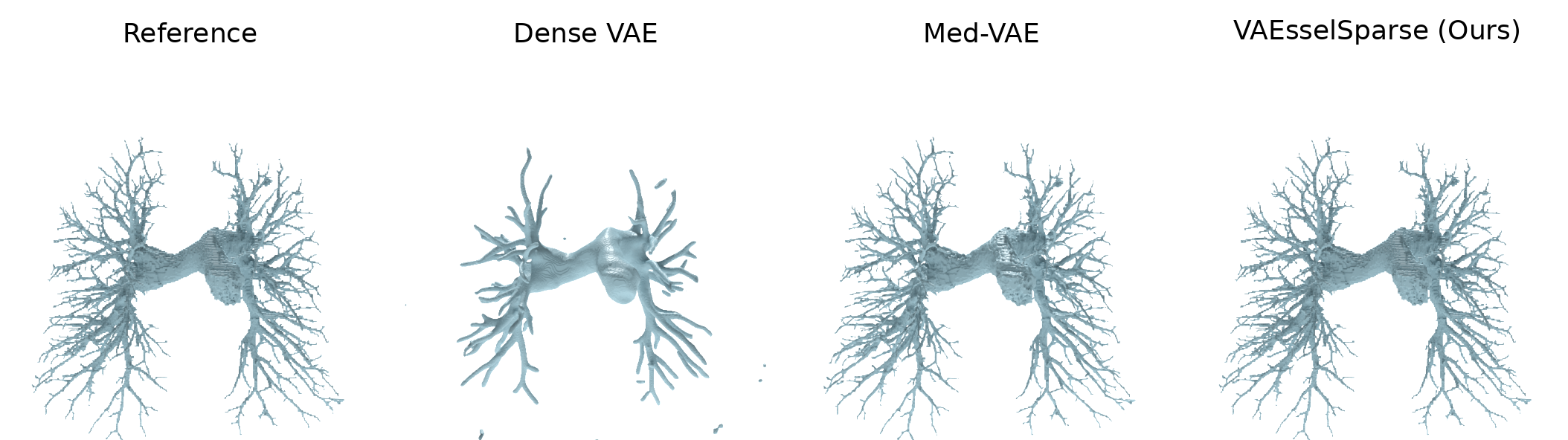
Figure 2: Representative reconstructions for vessel-like structures on various datasets; VAEsselSparse consistently preserves connectivity and details.
Discriminative Latent Space
The latent space produced by VAEsselSparse is probed through classification tasks on unseen datasets (INSTED, TopCoW). The architecture yields strong clinical discriminability, outperforming voxel-space ResNet/ViT as well as dense VAE features. PCA+RF and MLP models applied to VAEsselSparse latents achieve balanced accuracy and macro-F1 scores comparable to or exceeding strong baselines, indicating that the latent space encodes vessel-specific features relevant for disease and variant classification.
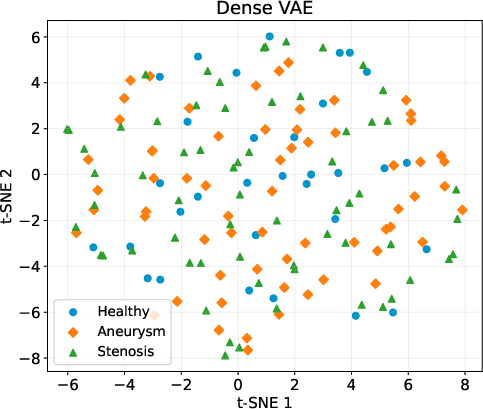
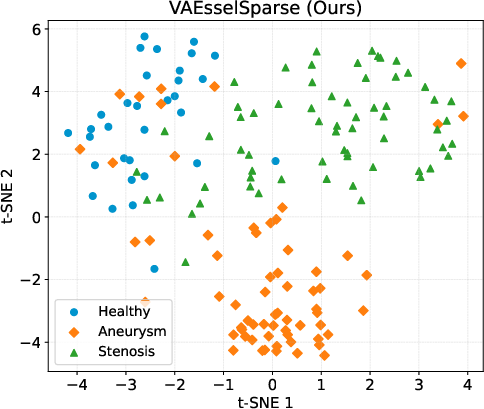
Figure 3: t-SNE visualization reveals well-separated latent clusters correlating with clinical categories (healthy/stenosis/aneurysm) in VAEsselSparse, not present in dense VAE features.
Generative Modeling
VAEsselSparse's latent space functions directly as a prior for generative modeling. A denoising U-Net trained in latent space synthesizes realistic vessel structures, outperforming dense VAE-based models in Minimum Matching Distance, Coverage, and 1-Nearest Neighbor Accuracy. Generated samples from the latent space model exhibit plausible connectivity and fine geometry.
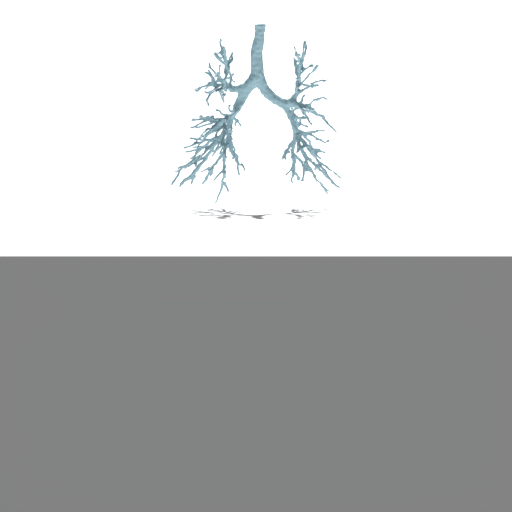
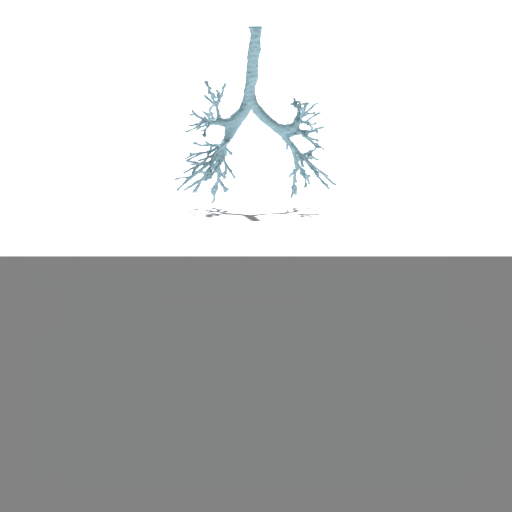
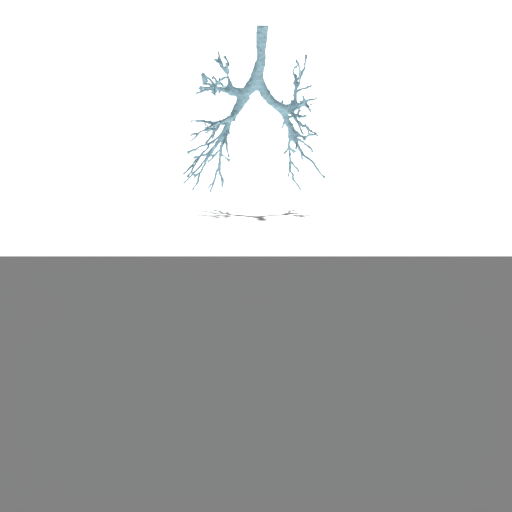
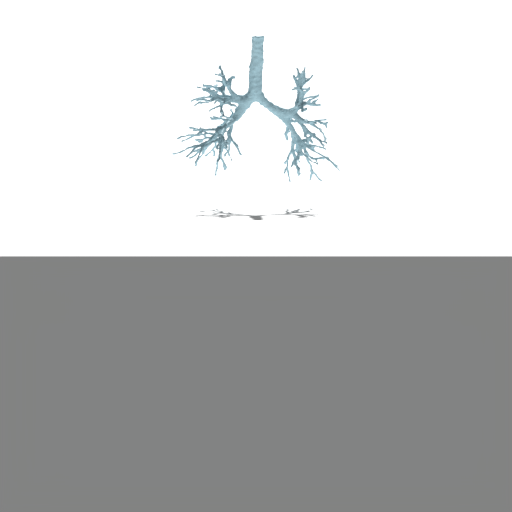
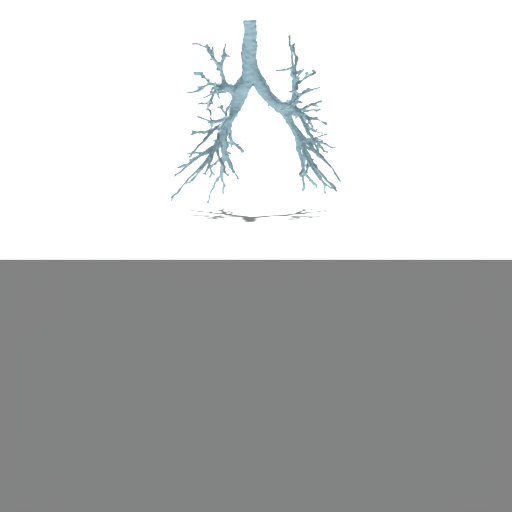
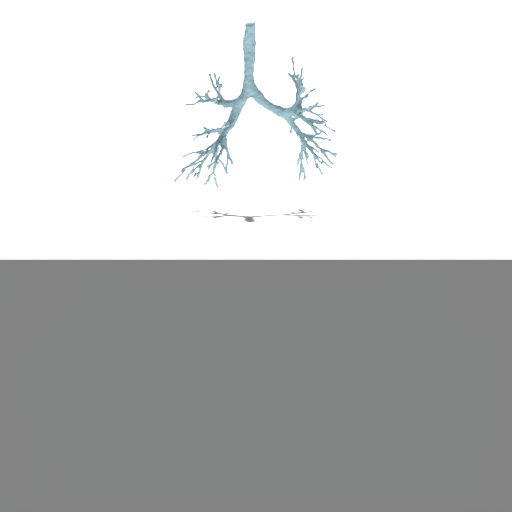
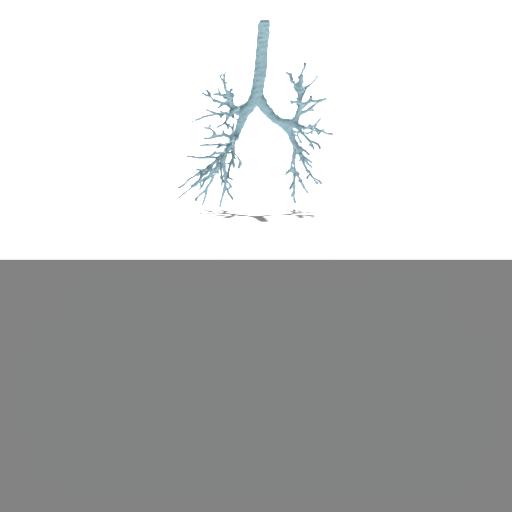
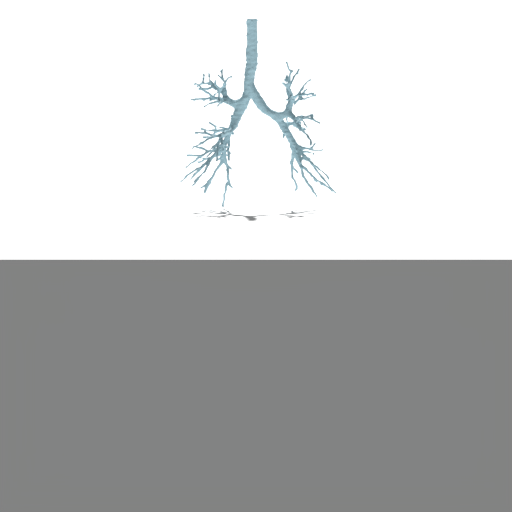
Figure 4: Unconditional samples produced by generative flow-matching in VAEsselSparse's sparse latent space, demonstrating efficiency and structural realism.
Practical and Theoretical Implications
VAEsselSparse advances sparse representation learning by integrating sparse convolution and transformer-based attention within variational modeling, tailored to volumetric biomedical structures. This eliminates the limitations of patch-based and tree-only models, supports organ-level networks at full resolution, and addresses clinical needs for diagnostic precision. The results establish the feasibility of scalable VAEs for high-resolution vascular modeling and open avenues for robust downstream applications such as anatomical variant classification, disease prediction, and simulation-based planning.
From a theoretical perspective, the architecture exemplifies the utility of sparsity-preserving operations for representation learning in domains where dense computation is prohibitive. The observed preservation of topological invariants in both reconstruction and generative tasks highlights the critical role of sparse transformers in capturing global connectivity.
Future Directions
Possible extensions include:
- Scaling to gigascale datasets and other sparse anatomical structures (airway trees, neural fibers).
- Incorporating conditional generative modeling for rare pathologies and anatomical variants.
- Adapting sparse latent priors to enable few-shot or transfer learning across domains.
- Integrating implicit surface priors or graph-based tokenization for hybrid representations.
- Exploring sparsity-induced regularization in diffusion and flow models for improved generation fidelity.
Conclusion
VAEsselSparse sets forth a sparse, attention-enhanced variational autoencoder architecture for vessel representation learning, achieving efficient spatial compression, accurate structure preservation, and robust clinical discriminability in latent space. The integration of sparse convolution and transformer modules specifically targets the computational and structural demands of volumetric biomedical analysis, enabling both reconstruction and generative modeling at scale. These advances expand the methodological toolkit for high-resolution, interpretable modeling in computational anatomy and medical imaging (2605.01382).