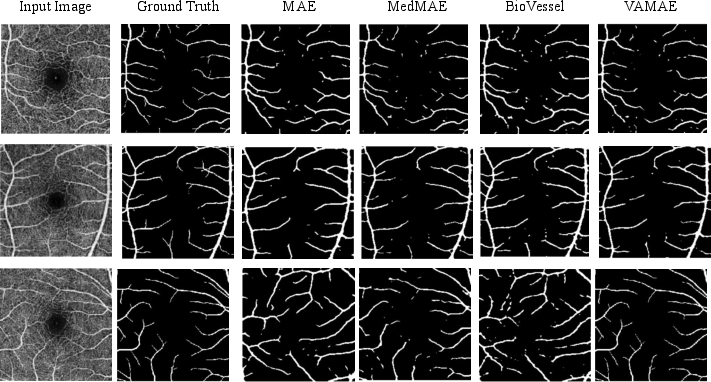
- The paper demonstrates VAMAE's main contribution: a novel vessel-aware masking strategy that prioritizes vessel-rich regions to improve vascular representation and connectivity in OCTA.
- The methodology incorporates multi-target reconstruction by jointly predicting intensity, vesselness, and skeleton maps, yielding superior Dice scores on vessel segmentation benchmarks.
- Experimental results show that VAMAE achieves high label efficiency and robust performance across varying disease severities, outperforming conventional MAE and supervised methods.
Vessel-Aware Masked Autoencoders for OCT Angiography: Technical Summary and Analysis
Motivation and Problem Context
Optical Coherence Tomography Angiography (OCTA) is instrumental in visualizing retinal microvasculature and providing crucial biomarkers for pathologies such as diabetic retinopathy and glaucoma. OCTA images are characterized by sparse, filamentary vessel structures embedded within predominantly homogeneous backgrounds. Segmentation and analysis require the preservation of vascular topology, continuity, and accurate delineation of features such as branching patterns and the foveal avascular zone (FAZ). Conventional self-supervised learning (SSL) methods—including masked autoencoders (MAE)—are biased toward the dense, texture-rich domains of natural images, employing uniform masking and pixel-level reconstruction. This paradigm is inherently misaligned with OCTA's sparse, geometry-centric anatomy, resulting in poor vessel representation and fragmented predictions.
Vessel-Aware Masked Autoencoder Framework
The paper introduces VAMAE, a vessel-aware masked autoencoding architecture, specifically designed for self-supervised pretraining on OCTA images. The framework incorporates two essential innovations:
- Vessel-Guided Masking Strategy: The masking operation is adaptive, guided by Frangi vesselness responses and skeleton-derived importance scores. Patch-wise structural priors are computed to localize vessel-rich regions and prioritize them for masking, forcing the encoder to reconstruct vascular connectivity instead of trivial background. (Figure 1)

Figure 1: Vessel-aware masking strategy leveraging vesselness and skeleton-based priors to prioritize vessel-rich regions for pre-training.
- Multi-Target Reconstruction Objective: Instead of pixel-wise intensity reconstruction, the decoder jointly predicts the intensity image, vesselness maps, and vessel skeletons, enforcing learning of appearance, morphological, and topological cues. This multi-headed supervision captures hierarchical vascular information and thematic connectivity. (Figure 2)
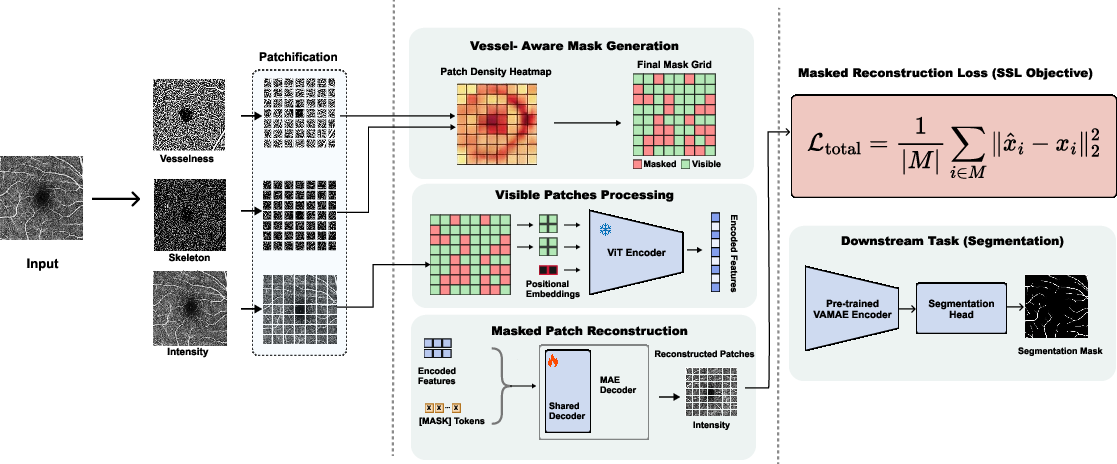
Figure 2: VAMAE architecture with vessel-aware masking and multi-target reconstruction, integrating intensity, vesselness, and skeleton targets.
The encoder is a Vision Transformer (ViT) variant, handling visible patches for computational efficiency, while the decoder reconstructs masked regions via three dedicated MLP heads, each targeting one of the triplet modalities.
Experimental Results and Numerical Evidence
Evaluation is performed on the OCTA-500 benchmark, which encompasses multiple vessel segmentation tasks under limited supervision scenarios. VAMAE demonstrates pronounced improvements over standard MAE, medical SSL baselines (MedMAE, BioVessel-Net), and supervised architectures (U-Net, CS2-Net). Notable outcomes include:
Theoretical Considerations
The superiority of vessel-aware masking is analytically justified through increased information density and entropy per masked patch. In OCTA, random masking predominately targets background, wasting representational capacity. Vessel-aware masking, parametrized by α=0.6, shifts the masking distribution toward vessel-rich regions, amplifying task difficulty and promoting encoder learning of discriminative vascular features.
Multi-target reconstruction further promotes hierarchical representation learning: intensity encodes appearance-level features; vesselness enforces morphological structure; skeleton targets ensure topological regularity and connectivity. The information-theoretic rationale and empirical ablation studies validate this approach.
Practical Implications and Future Directions
VAMAE’s design implies significant reductions in annotation costs while achieving or exceeding performance of specialized supervised methods. The geometry-informed SSL approach generalizes across vessel scales, anatomical structures, and varying disease severities. The framework also provides a strong foundation for topology-preserving medical image analysis, potentially extendable to other modalities involving sparse anatomical structures.
Future avenues include:
- Pathology-Aware Priors: Adaptation of vesselness and skeleton extraction mechanisms for severe pathology cases.
- Integration of Preprocessing: Embedding vesselness and skeletal computation within the architecture for streamlined pretraining.
- 3D Volumetric Extensions: Extending the methodology to volumetric OCTA for depth-aware vascular analysis.
Conclusion
VAMAE establishes vessel-aware masked autoencoding as an effective self-supervised pretraining strategy for OCTA analysis. The combination of anatomically informed masking and multi-target reconstruction achieves state-of-the-art vessel segmentation with minimal labeled data. This approach presents a domain-adaptive paradigm for SSL in medical imaging, supporting robust downstream tasks and setting a precedent for integrating structural priors into representation learning architectures.