- The paper presents the Alikhanov-XfPINNs framework that integrates high-order Alikhanov discretization with physics-informed neural networks for solving nonlinear fractional PDEs.
- It demonstrates second-order convergence and robust recovery in both smooth and singular initial settings using nonuniform graded meshes and adaptive activation functions.
- The method significantly reduces memory and computational complexity via a sum-of-exponentials kernel, enabling precise forward and inverse problem solutions.
Introduction and Motivation
This work addresses computational and modeling challenges associated with nonlinear fractional partial differential equations (NfPDEs), particularly those exhibiting initial singularities, nonlocal memory, and strong solution irregularities near t=0. Classical numerical solvers for fractional PDEs often incur prohibitive memory and computational costs due to the long-time history convolution present in Caputo derivatives, especially on uniform meshes, and suffer accuracy degradation in the presence of weak initial singularities.
Building on the PINN framework, the paper introduces the Alikhanov-extended fractional PINNs (XfPINNs) architecture. This hybrid combines high-order Alikhanov temporal discretization on nonuniform (graded) meshes with deep neural network surrogates—providing a flexible, mesh-free, and accurate approach for both forward and inverse fractional PDE problems. The framework incorporates adaptive activation functions to accelerate network convergence and embeds physical constraints through hard and soft formulations, improving robustness and efficiency across multi-dimensional and irregular domains.
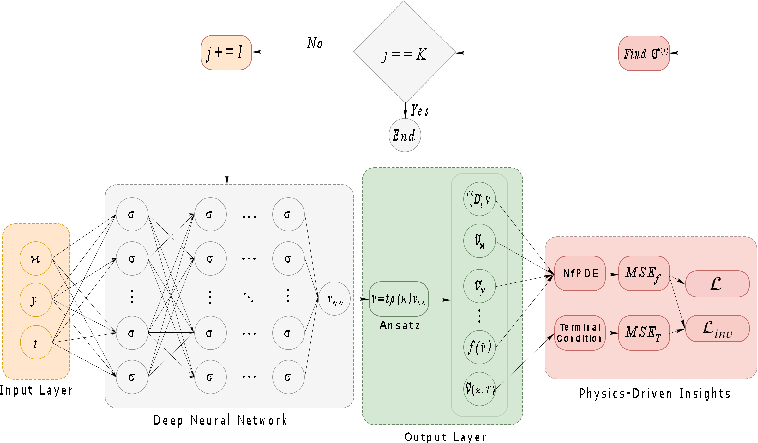
Figure 1: Schematic diagram of the XfPINN architecture illustrating the integration of Alikhanov discretization and physics-informed deep learning.
Methodological Framework
Central to the architecture is an accelerated second-order Alikhanov scheme implemented on graded time meshes. The graded mesh formulation tn=T(n/Kt)γ adapts temporal resolution near t=0, crucial for capturing initial singularity in solutions of time-fractional PDEs with Caputo derivatives. The discretization is proven to satisfy optimal mesh regularity, consistency, and monotonicity properties under bounded step ratio conditions (cf. Lemma in the paper). The sum-of-exponentials (SOE) kernel approximation dramatically reduces computational complexity from quadratic to logarithmic scaling in the history term, enabling scalable simulations.
The PINN structure is constructed with feed-forward fully-connected neural networks parameterized by Θ, with network depth and adaptive activation variants tailored to the problem's complexity. The Alikhanov discretization is embedded as a variational loss term, alongside initial and boundary conditions enforced via hard (direct ansatz embedding) or soft (penalty) constraints, yielding an architecture that systematically separates discretization, optimization, and sampling errors. Optimizations are performed in TensorFlow using Adam, with automatic differentiation for spatial derivatives and efficient CPU/GPU batching.
Adaptive Activation Functions
To enhance convergence, the activation functions are parameterized with trainable slopes (a) and scaling factors (n), following recent advances in adaptive neural architecture optimization. The $\Swish(na\,x)$ function was empirically found to deliver the lowest maximum-norm and relative L2 errors, outperforming standard choices and reducing training epochs.
Time-Marching and Controlled Temporal Convergence
A key methodological innovation is the auxiliary time-marching configuration (Alikhanov-fPINN-M), enforcing residuals sequentially at each time step with frozen snapshots and recursive SOE memory updates. This protocol enables rigorous, auditable temporal-convergence studies and direct disentanglement of discretization error, confirming theoretical rates (min{γα,2}) versus empirical outcomes under controlled tolerances.
Forward Problem: Nonlinear Subdiffusion and Generalized Burgers Equation
Extensive experiments demonstrate the superiority of Alikhanov-XfPINNs in both smooth and singular initial settings. For nonlinear time-fractional subdiffusion and generalized Burgers equations, adaptive activations yielded faster training and improved error metrics. Notably, results confirm:
- Second-order temporal convergence for smooth solutions when grading parameter γ=2/α.
- Robust recovery in the presence of initial singularity using graded meshes, outperforming uniform discretizations across all evaluated fractional orders.
- Superior accuracy and computational efficiency versus standard PINNs and fPINNs.
Absolute errors, predicted fields, and loss trajectories corroborate the quantitative improvements associated with adaptive activation and nonuniform mesh selection.
Forward Problems with Unknown Solutions
In settings with no closed-form exact solution (e.g., fractional Fisher-Nagumo equation), the framework effectively recovers and aligns with known integer-order solutions as tn=T(n/Kt)γ0, demonstrating generalizability for high-dimensional, data-driven scientific computing.
Inverse Problem: Parameter Identification in NfPDEs
For parameter estimation tasks (e.g., time-fractional reaction-diffusion, Allen–Cahn equations), Alikhanov-XfPINNs achieved high-fidelity recovery of fractional order, diffusion, reaction, and mobility coefficients. Nonuniform mesh grading (tn=T(n/Kt)γ1, tn=T(n/Kt)γ2) consistently reduced both relative tn=T(n/Kt)γ3 and maximum-norm errors compared to uniform treatments. Hard constraint embedding of initial/boundary conditions further enhanced accuracy and reduced sample requirements.
Parameter evolution trajectories during training exhibited rapid convergence to ground truth on graded meshes, underscoring the practical value of the approach for inverse modeling and real-data assimilation.
Theoretical & Practical Implications
The Alikhanov-XfPINNs framework substantiates several bold claims:
- Separation of discretization and optimization errors enables transparent convergence analysis, validating theoretical predictions on error rates for graded mesh discretization.
- Adaptive activation functions nontrivially improve learning efficiency and accuracy—quantitatively outperforming fixed variants on all metrics.
- Hard/soft constraint flexibility supports both homogeneous and nonhomogeneous settings, facilitating parameter inference and solution reconstruction in high-dimensional, irregular, and real-world domains.
- SOE-accelerated convolutions transform computational tractability for long-memory PDEs, reducing cost without sacrificing accuracy.
These outcomes extend the utility of PINN-based solvers to broader classes of anomalous diffusion, kinetic, and memory-driven phenomena and open avenues for principled, empirical, and theoretical studies on approximation and generalization in scientific machine learning.
Future Directions
The study lays foundations for several advanced research avenues:
- Extension to variable-order or multi-state fractional operators (e.g., tn=T(n/Kt)γ4 for dynamic memory effects).
- Rigorous theoretical analysis of convergence, stability, and generalization for PINNs with embedded high-order discrete fractional approximations.
- Application to real-world experimental and observational datasets; parameter estimation directly from measurements for scientific model justification.
- Automated mesh grading and adaptive sampling for optimal accuracy versus computational cost trade-offs.
Conclusion
Alikhanov-XfPINNs represent a significant advancement in physics-informed scientific machine learning for fractional PDEs. The combination of accelerated nonuniform Alikhanov discretization, adaptive activation embedding, and rigorous constraint enforcement produces robust, scalable, and highly accurate surrogates for both forward and inverse problems—even in settings with pronounced singularities and incomplete analytical knowledge. Numerical evidence confirms theoretical expectations, and the methodology is poised for impactful application and further development in computational physics, biology, engineering, and data-driven scientific inquiry.

