- The paper presents a novel RL framework that integrates an Intrinsic Dynamics Head to predict actuator torques, yielding improved compliance and energy efficiency.
- It employs a dynamics reward to penalize unpredictable torques, resulting in smoother actions and enhanced stability both in simulation and on hardware.
- Extensive domain randomization and teacher-student training enable zero-shot sim-to-real transfer on Unitree GO2, demonstrating robust and safe locomotion.
Dynamics-Aware Quadrupedal Locomotion via Intrinsic Dynamics Head: Technical Summary
Motivation and Background
The paper introduces a methodology for improving quadrupedal locomotion by explicitly integrating physical dynamics awareness in reinforcement learning-based controllers. Traditional approaches in RL for quadrupedal robots typically fall into position-based and torque-based control categories. Position-based policies, though simpler to train, are susceptible to safety risks and inefficiency due to their ignorance of actuator dynamics, frequently leading to overreactive behavior and non-compliant gaits. Torque-based approaches, while yielding safer and more compliant motions, are harder to optimize due to complex state-to-torque relationships. The authors hypothesize that optimal locomotion should preserve the task-level reasoning in position space but also incorporate an intrinsic understanding of torque dynamics, paralleling human motor skills. This insight motivates the proposed architecture.
Framework and Methodology
The authors propose a concurrent learning framework comprising a standard RL policy augmented with an Intrinsic Dynamics (ID) Head. The ID Head learns a parametric mapping from state to predicted torques, thereby encoding physical dynamics awareness into the neural architecture. Its training is aligned with the policy optimization through an auxiliary loss that penalizes the prediction error between the ID Head and true torques from simulated actuators.
Additionally, a dynamics reward is formulated to penalize unpredictable torque generation, explicitly encouraging policies whose produced actions yield torques that are more easily predictable by the ID Head. This reward is integrated into the overall objective and regularizes the policy toward smoother, more efficient and stable behavior. Crucially, both the ID Head loss and dynamics reward are tunable, allowing for nuanced control of the state distribution and training convergence.
Domain randomization is performed extensively to facilitate robust sim-to-real transfer, randomizing dynamics, friction, restitution, and sensor noise. Policy optimization leverages privileged learning and teacher-student frameworks, using PPO as the underlying RL algorithm.
Architecture and Implementation
The full architecture (Figure 1) incorporates standard observations and privileged state features for teacher policies, while deployment relies solely on observable inputs. Neural networks include latent encoders for privileged information and temporal convolutional history encoders for student policies to approximate teacher latent features during real-world execution. The policy network consists of multi-layer perceptrons with integrated ID Head, producing both position targets and torque predictions.
Experimental Analysis
Simulation results on the Unitree GO2 robot in the Isaac Gym environment demonstrate that the dynamics-aware controllers preserve primary performance metrics (velocity tracking) while substantially improving auxiliary metrics:
- Energy efficiency: Power consumption reduced by 12–16%.
- Action smoothness: Action rate decreased by 18.6%.
- Torque efficiency: Mean torque reduced by 16.8%.
- Stability: Vertical velocity and angular stability improved.
Figure 2 presents these comparisons, showing that the adoption of the ID Head and dynamics reward achieves superior smoothness and efficiency without sacrificing primary task fidelity.
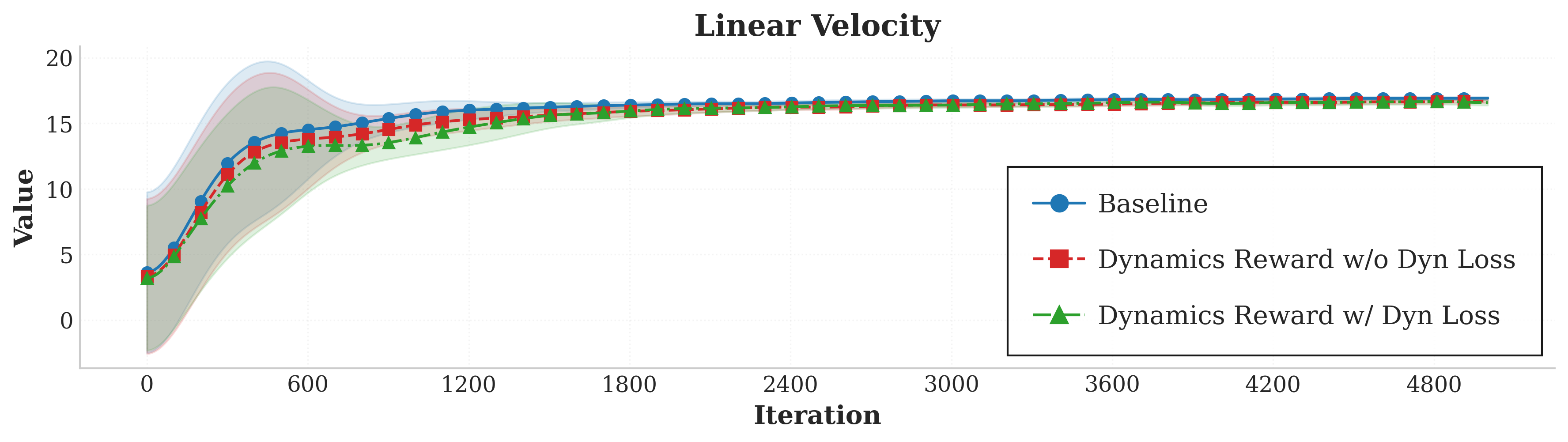
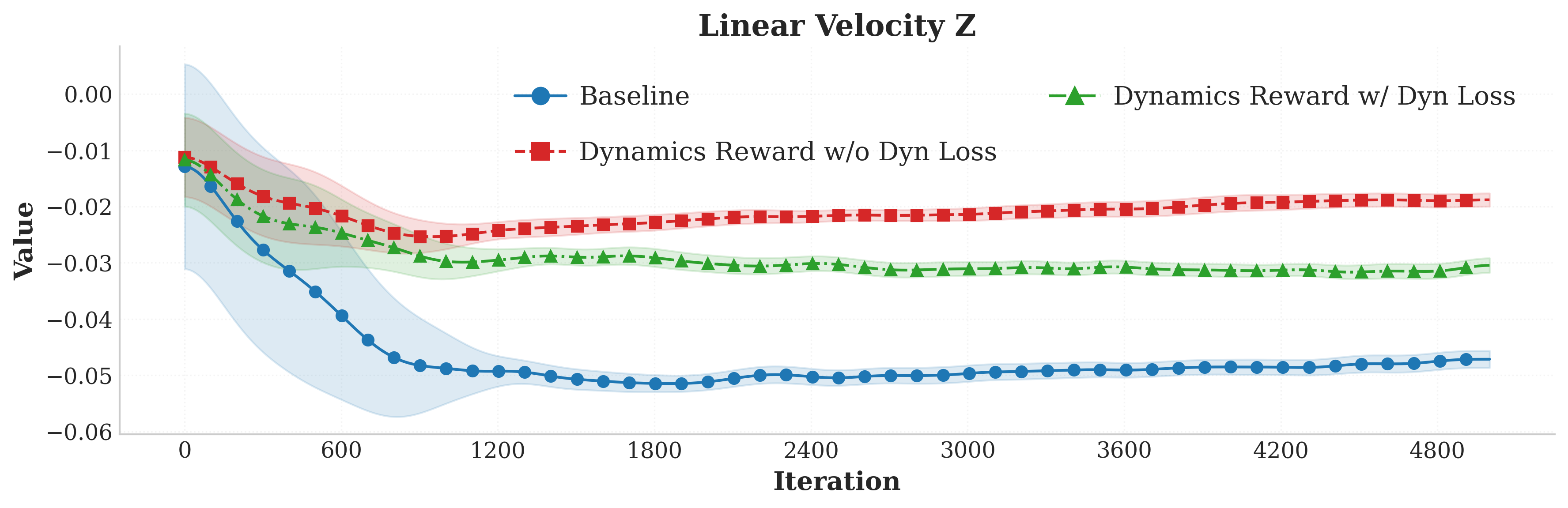
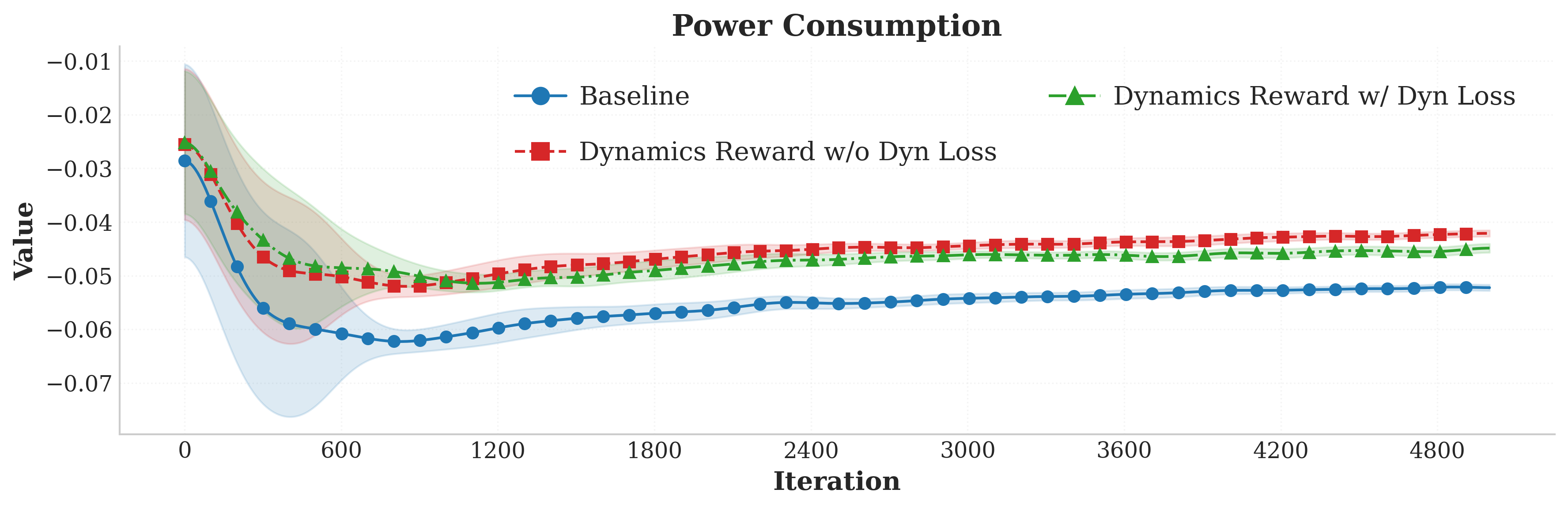
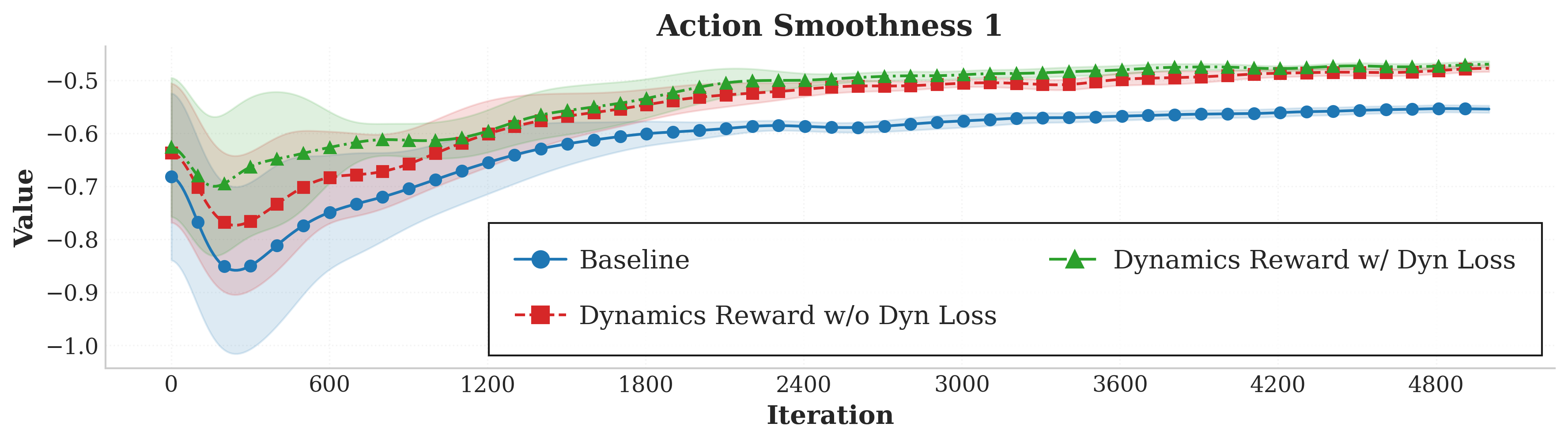
Figure 2: Integration of the Intrinsic Dynamics Head and dynamics reward improves auxiliary metrics (vertical velocity, action smoothness, power consumption) while maintaining primary linear velocity tracking performance.
Zero-shot sim-to-real transfer is validated on a physical Unitree GO2 platform. The learned controllers exhibit improved real-world torque occupancy, action rates, and power consumption (Table 2), with the dynamics-aware policy achieving safer operation (6.4% improvement in safe occupancy zone) and trotting gaits in contrast to erratic bounding associated with baseline policies.

Figure 3: Unitree GO2 Robot utilizing the Dynamics Aware Controller to navigate over curbs in real-world deployment.
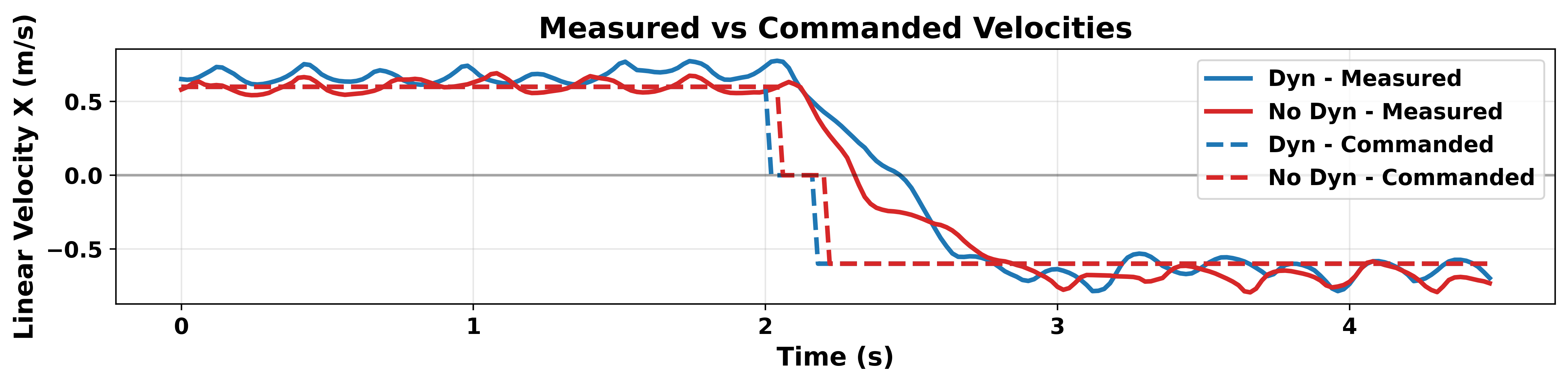
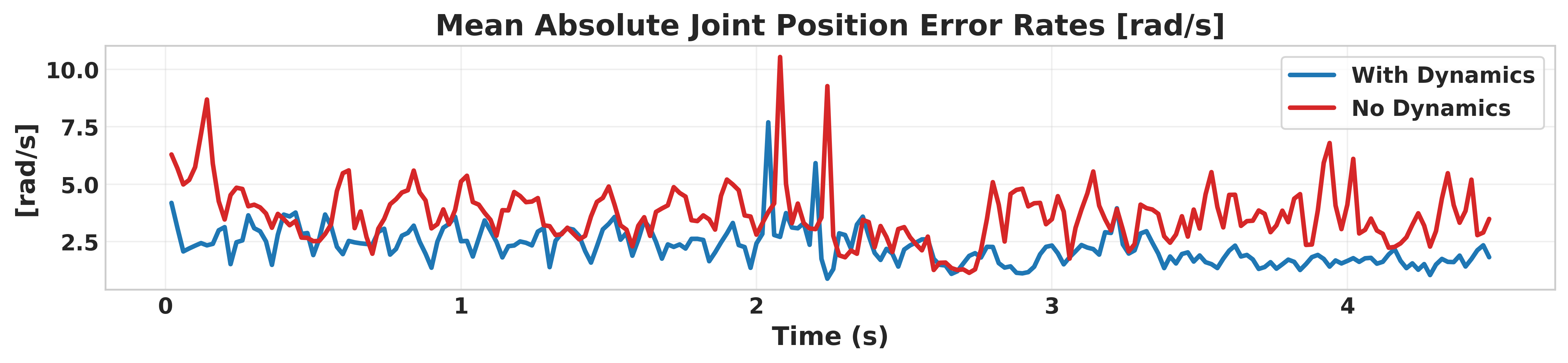
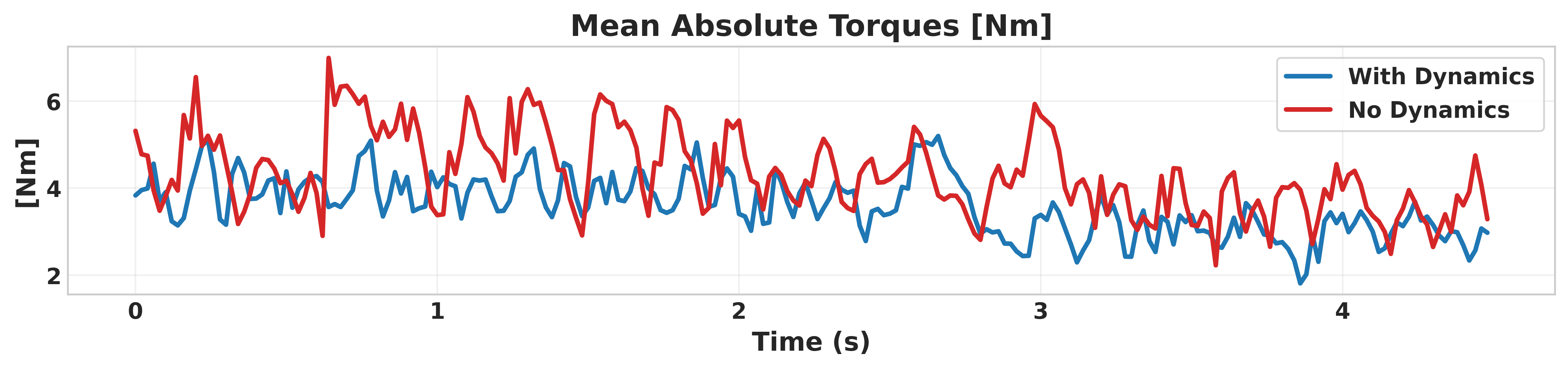
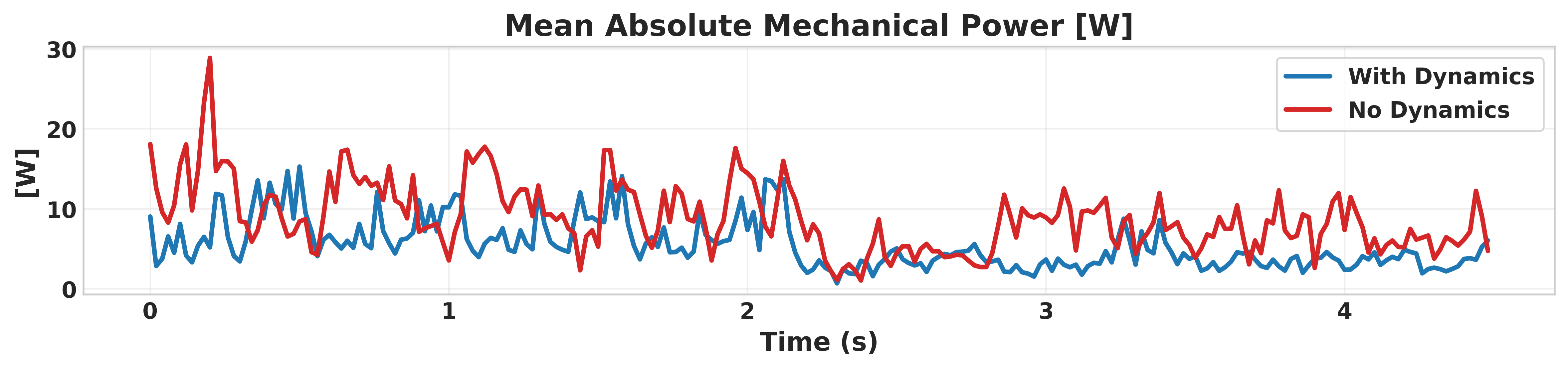
Figure 4: Curb traversal under the proposed controller showcasing stable trotting gait on the Unitree GO2 Robot.
Implications and Theoretical Considerations
The empirical results support the claim that the dynamics reward induces a state distribution shift, leading policies to favor regimes where torque outputs are inherently more predictable and physically plausible. This mechanism parallels curiosity-driven exploration but inverts the objective, penalizing unpredictability rather than rewarding it. The approach proves robust to domain randomization and enables efficient sim-to-real transfer without requiring computational overhead during deployment, as the ID Head is utilized only during simulation.
Practically, this methodology offers a scalable pathway for developing RL-based controllers for quadrupedal robots that must operate under energy constraints and safety-critical requirements. Theoretically, the alignment of policy optimization with physically plausible dynamics signals opens avenues for further exploration of intrinsic modeling synergistic with RL, potentially generalizing to manipulation and bipedal locomotion domains.
Challenges remain in parameter sensitivity; the reward and loss coefficients are tied to the underlying domain randomization settings and actuator network fidelity. Future research may investigate broader generalization, alternative torque modeling sources, and adaptive hyperparameter tuning.
Conclusion
This paper presents a principled approach for incorporating dynamics awareness into quadrupedal locomotion policies via a jointly trained Intrinsic Dynamics Head and dynamics reward. The method yields empirically verified improvements in efficiency, stability, and safety, with robust sim-to-real transfer and no deployment overhead. These results suggest broader applicability to robotics domains requiring both task-level reasoning and intrinsic physical dynamics understanding, paving the way for future generalization in bipedal and manipulation tasks.