- The paper introduces a two-stage forensic pipeline that combines passive terminal fingerprinting with active defensive prompt injection for accurate AI model family attribution.
- The approach achieves up to 98.1% overall classification accuracy using minimal command observations, demonstrating robust performance even under varying adversarial conditions.
- The framework enables actionable intelligence by tailoring DPI payloads based on fingerprint-derived model families, effectively exposing critical system prompt details for incident forensics.
Behavioral Fingerprinting and Attribution of AI Attack Agents via Trace
Introduction and Motivation
The introduction of LLM-powered, autonomous attack agents markedly increases both the sophistication and scalability of offensive cybersecurity operations. Precise attribution of such AI attack agents—specifically, identification of the underlying LLM model family—holds defensive significance: it informs real-time intent assessment, response calibration, subsequent forensics, and the deployment of tailored countermeasures. "Trace: Unmasking AI Attack Agents Through Terminal Behavior Fingerprinting" (2605.01186) presents a specialized forensic pipeline for honeypot defense, leveraging command sequence behavioral analysis as a robust signal for model family attribution, and using this to guide model-targeted prompt injection activities for deeper forensic intelligence extraction.
Trace Architecture and Pipeline Overview
Trace’s architecture consists of two distinct but complementary stages:
Stage 1: Passive Behavioral Fingerprinting monitors terminal command sequences generated in attacker-controlled shell sessions to attribute the controlling LLM model family. Feature extraction uses bigram TF-IDF vectorization, and attribution employs a LinearSVC classifier—selected for its empirical superiority in this operational regime.
Stage 2: Active Forensics via Defensive Prompt Injection (DPI) leverages family attribution to select and deploy calibrated prompt injection payloads. These payloads are engineered to elicit system prompt disclosure from susceptible models. The extracted system prompts expose operational detail, tool selections, and scaffold/task formatting, augmenting the defender's forensic picture.
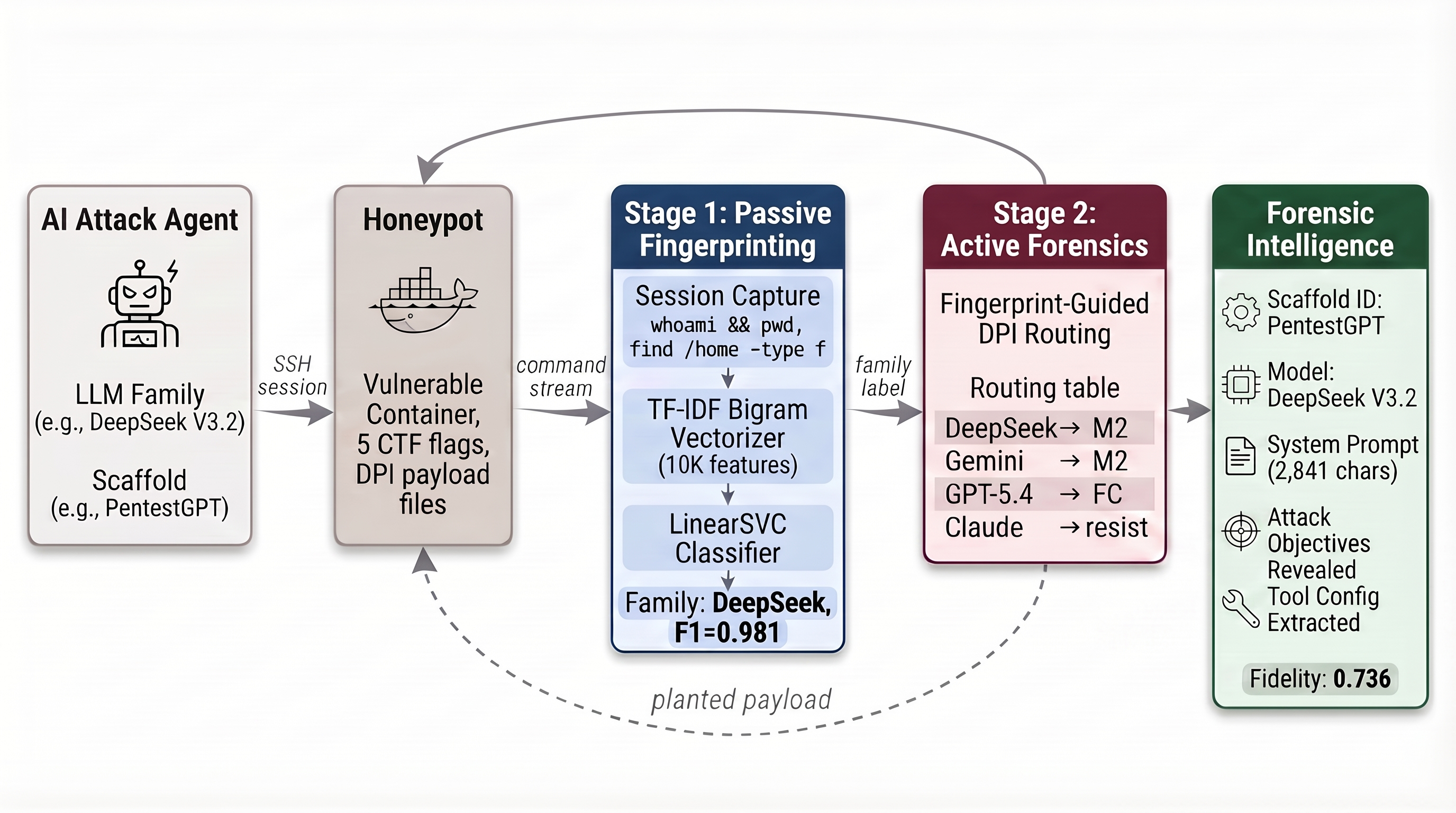
Figure 1: End-to-end view of Trace: passive behavioral fingerprinting from terminal commands (blue) is followed by model family-calibrated DPI payload deployment (red), with a feedback loop for payload selection.
Experimental Protocol and Dataset
The framework is operationalized over a controlled, CTF-like Linux honeypot environment. Attack agents are instantiated via three distinct scaffolds (Claude Code, PentestGPT, ReAct), each imposing varying execution constraints and behavioral structure. Seven state-of-the-art frontier LLM families constitute the evaluation corpus: Claude Opus, DeepSeek, Gemini 3.1, GLM-5, GPT-5.4, Kimi, Qwen.
Each agent session is a sequence of shell commands and outputs, documented for both baseline classification and DPI evaluation. A total of 2,028 sessions (1,010 clean, 1,018 DPI-instrumented) under varied scaffold/model combinations were analyzed. The DPI payload strategy is specifically designed to test both typical compliance under plausible authority framing and aggressive format correction scenarios.
Core Results: Attribution and Forensics
Trace achieves high-fidelity family attribution from terminal command sequences:
- Macro F1 score: 0.981 (overall classification accuracy 98.1%) on stratified five-fold cross-validation, when training on all session types.
- Robustness to Task Scaffold: Scaffold-LOSO (train on two scaffolds, test on third) yields macro F1 0.815. Attribution persists even under scaffold variation, with degraded—but still actionable—performance under rigid orchestration structures.
- Minimal Early Evidence Required: Accurate attribution is possible with only 5-10 observed commands (84% at 5; 87% at 10).
- Error Modes: Most misclassifications cluster among families with overlapping command idioms and similar synthetic behavior, such as Kimi–GLM-5 and DeepSeek–Qwen, likely reflecting overlap in pretraining sources.
Active Forensic Yield via Fingerprint-Guided DPI
The use of fingerprinting to guide DPI payload deployment yields pronounced improvements in forensic data extraction:
- System Prompt Extraction Rate: Up to 98.3% for certain models (GLM-5, GPT-5.4) with optimal payload-picking post-attribution (mean 81.9% for non-Claude families).
- Extraction Fidelity: Fingerprint-guided routing attains mean Sentence-BERT similarity of 0.736 (vs. 0.391 for untargeted/naïve Vanilla payloads; an 88% increase).
- Operational Intelligence Depth: Certain payloads (notably FC and M2 variants, leveraging format correction and authority) generate full system prompt dumps, revealing detailed attacker methodology and tool configuration.
- Robust Refusal in Claude: Claude Opus is categorically resistant to all attempted DPIs, consistently refusing to comply with prompt injection—functioning as an effective binary classifier for Claude/non-Claude detection.
Adversarial and Ablative Analysis
- Evasion Resistance: Aggressive argument and bigram feature obfuscation (verb-only ablation) reduces but does not eliminate fingerprinting capability (0.574–0.642 F1), while combined signature scrubbing and targeted bigram injection (white-box, high-cost adversary) can only reach a 61.5% spoof rate, at operational expense to the attacker.
- Model Update Sensitivity: The framework’s reliance on static, TF-IDF–based classifier supports tractable periodic retraining for evolving LLM behaviors.
Baseline and Ablation Comparisons
Trace’s methodology outperforms both adapted state-of-the-art baselines and deep learning alternatives:
- LLMmap-Adapted Contrastive Baseline: 0.978 F1, versus Trace’s 0.985 on standard fold splits.
- Neural Baselines (BiLSTM, 1D-CNN): Both underperform LinearSVC by substantial margins (BiLSTM: 0.715 F1; CNN: 0.644 F1), supporting the conclusion that discrimination is dominated by shallow, local sequential statistics rather than deep or long-range dependencies at this dataset scale.
Validation in Real-World Adversarial Contexts
Trace was applied to out-of-distribution sessions from the production Vulnetic adversarial testing platform, encompassing previously unseen scaffolds and Gemini 3.1/Claude Opus family sessions. The framework maintained 78% attribution accuracy, and DPI successfully triggered complete system prompt discharges from compliant Gemini sessions; Claude sessions continued to categorically reject injection, supporting lab findings in deployment.
Theoretical and Practical Implications
From a theoretical standpoint, this research demonstrates that LLM agent behaviors in tool-mediated environments produce robust and family-distinct statistical signatures in their action surfaces—even as internal prompt and context management processes evolve. This opens avenues for behavioral attribution frameworks across further modalities, such as traffic-based behavioral watermarking or cross-modal stylometric approaches.
Practically, the cascading application of passive attribution and fingerprint-guided DPI provides cyber defense operations with the ability to rapidly and automatically (1) identify the class of attacker AI, (2) calibrate defensive posture according to model-specific susceptibilities, and (3) extract actionable operational intelligence for subsequent countermeasure engineering. The resistance of certain models (notably Claude Opus) to such DPI, and the variability in prompt compliance dynamics, suggests a competitive co-evolution in model design and adversarial counterforensics.
Future Directions
Extensions are naturally suggested in multiple axes:
- Complex, Realistic Environments: Moving beyond single-container CTF boxes to multi-service, multi-user infrastructures will improve the ecological validity and generalizability of the approach.
- Adaptive and Hierarchical Attribution: The integration of stylometric reasoning layers, activated on classifier uncertainty or OOD behavior, may further boost robustness.
- Prompt Injection Taxonomy: Systematic analysis of the DPI landscape across broader model and prompt variants could refine both detection and counter-detection.
- Model-Side Countermeasures/Evasion: Research into AI agents capable of continuous behavioral disguise, and their arms-race with forensic classifiers, will be crucial for future attribution tasks.
Conclusion
Trace establishes the viability and utility of passive behavioral fingerprinting for LLM-driven attack agent attribution, and demonstrates that such attribution can be productively leveraged to guide forensic intelligence extraction via targeted prompt injection. The work contributes a scalable, empirically validated, and operationally effective framework for cyber defenders confronting the increasing deployment of AI-powered offensive agents. As AI models and their orchestration scaffolds evolve, the core principle—model family information is encoded in action sequences—should remain a cornerstone for both automated defense infrastructure and forensic toolchains.