Cybersecurity AI: A Game-Theoretic AI for Guiding Attack and Defense
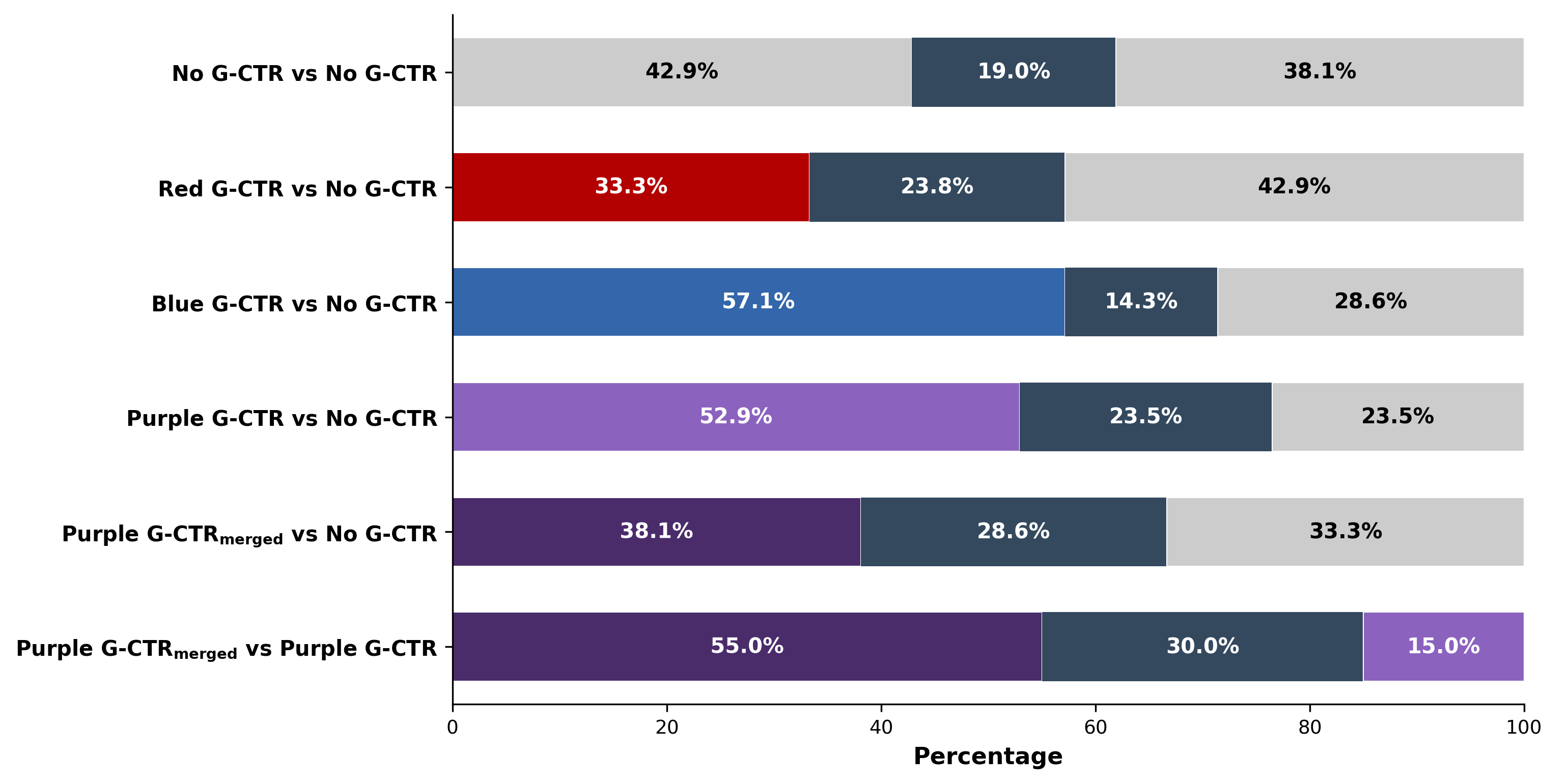
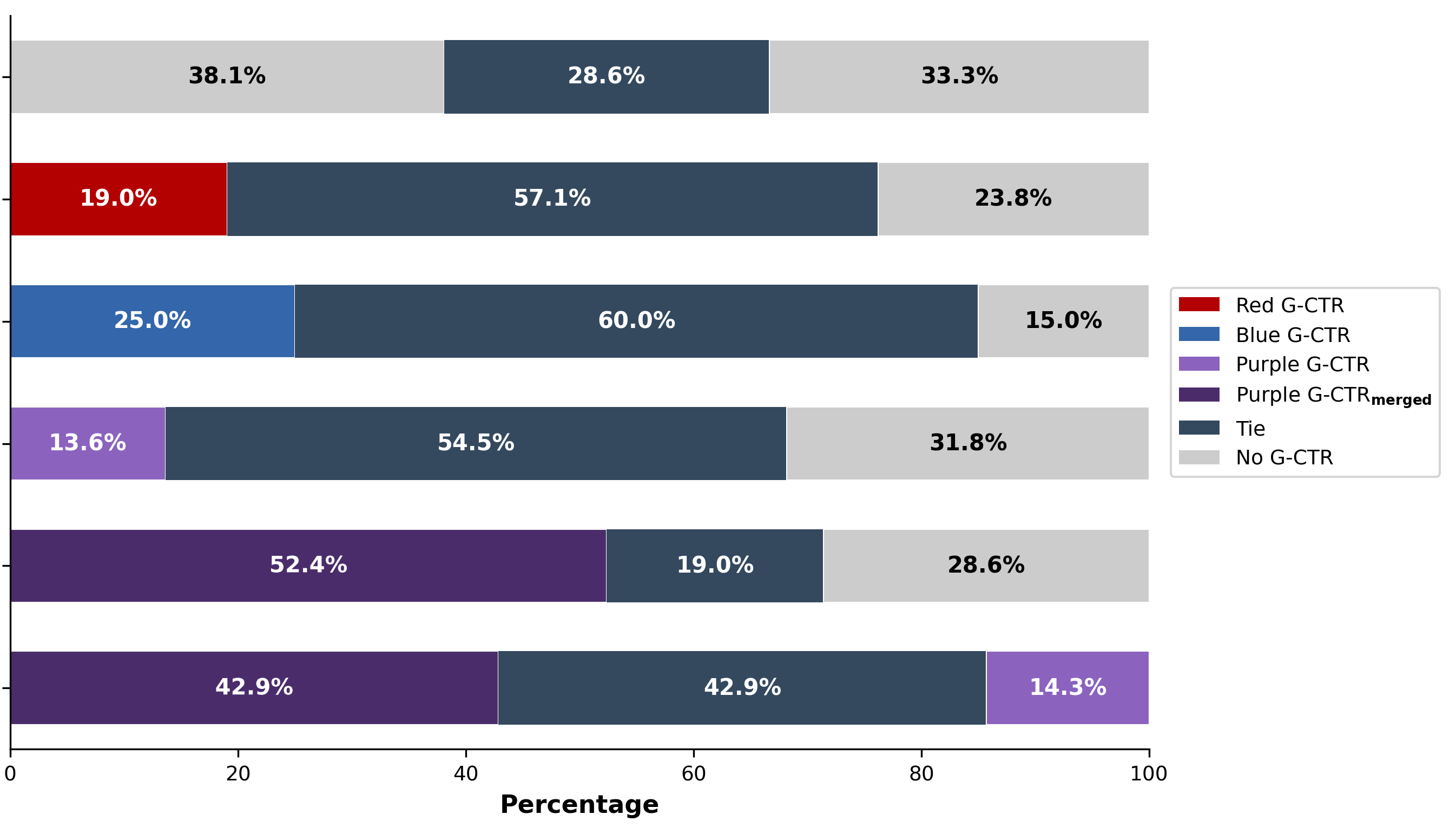
Abstract: AI-driven penetration testing now executes thousands of actions per hour but still lacks the strategic intuition humans apply in competitive security. To build cybersecurity superintelligence --Cybersecurity AI exceeding best human capability-such strategic intuition must be embedded into agentic reasoning processes. We present Generative Cut-the-Rope (G-CTR), a game-theoretic guidance layer that extracts attack graphs from agent's context, computes Nash equilibria with effort-aware scoring, and feeds a concise digest back into the LLM loop \emph{guiding} the agent's actions. Across five real-world exercises, G-CTR matches 70--90% of expert graph structure while running 60--245x faster and over 140x cheaper than manual analysis. In a 44-run cyber-range, adding the digest lifts success from 20.0% to 42.9%, cuts cost-per-success by 2.7x, and reduces behavioral variance by 5.2x. In Attack-and-Defense exercises, a shared digest produces the Purple agent, winning roughly 2:1 over the LLM-only baseline and 3.7:1 over independently guided teams. This closed-loop guidance is what produces the breakthrough: it reduces ambiguity, collapses the LLM's search space, suppresses hallucinations, and keeps the model anchored to the most relevant parts of the problem, yielding large gains in success rate, consistency, and reliability.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper leaves the following items unresolved and open for future investigation:
- Ambiguity in experimental setup for the 44-run cyber range: clarify whether all runs targeted a single challenge (Shellshock) or multiple distinct exercises; provide full numeric results, randomization, and statistical significance tests (e.g., confidence intervals, p-values, power analysis).
- Missing citation and dataset reference for the “shockwave report Cyber Range Challenge”; release the benchmark specification, scenarios, and raw logs to enable replication.
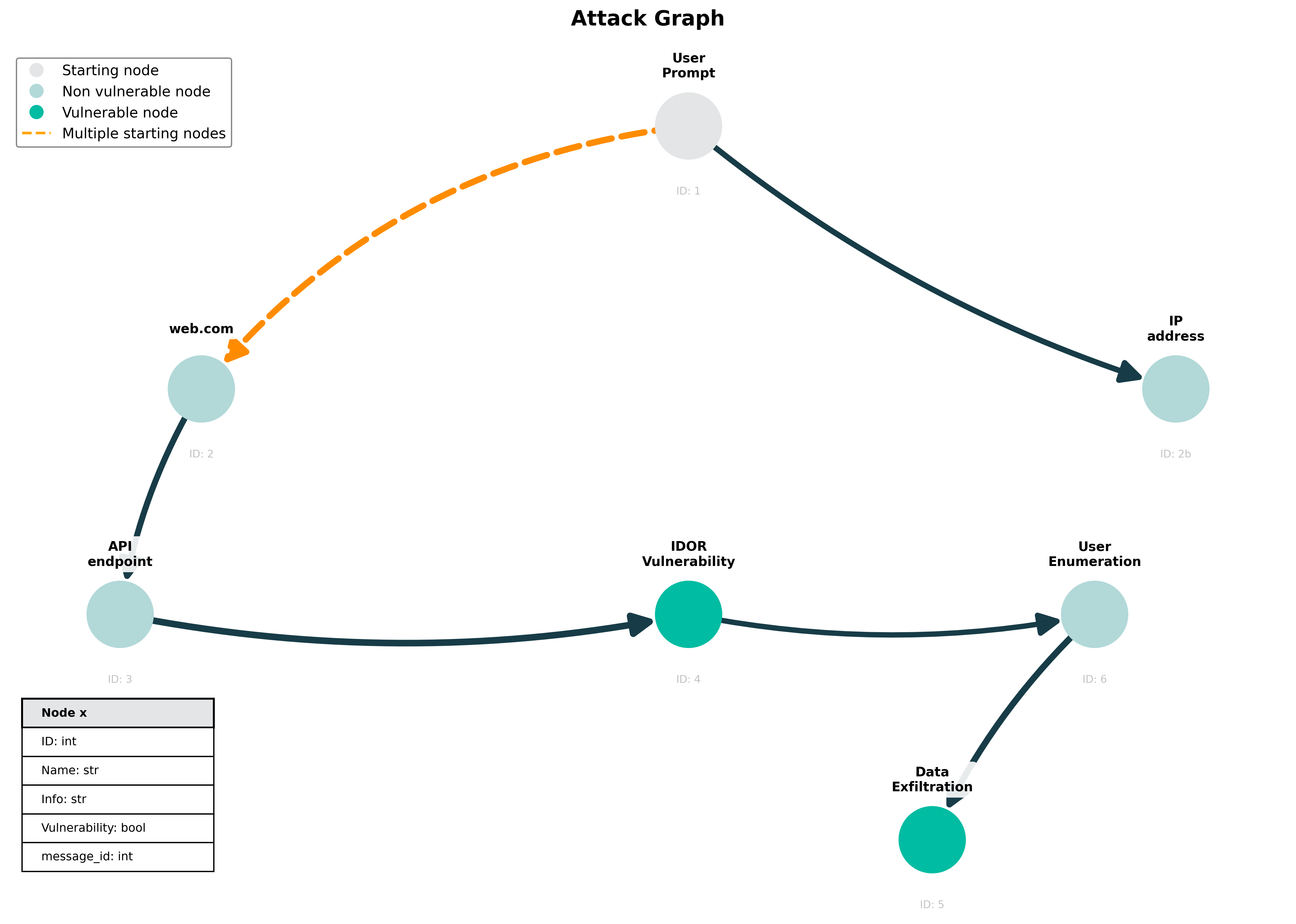
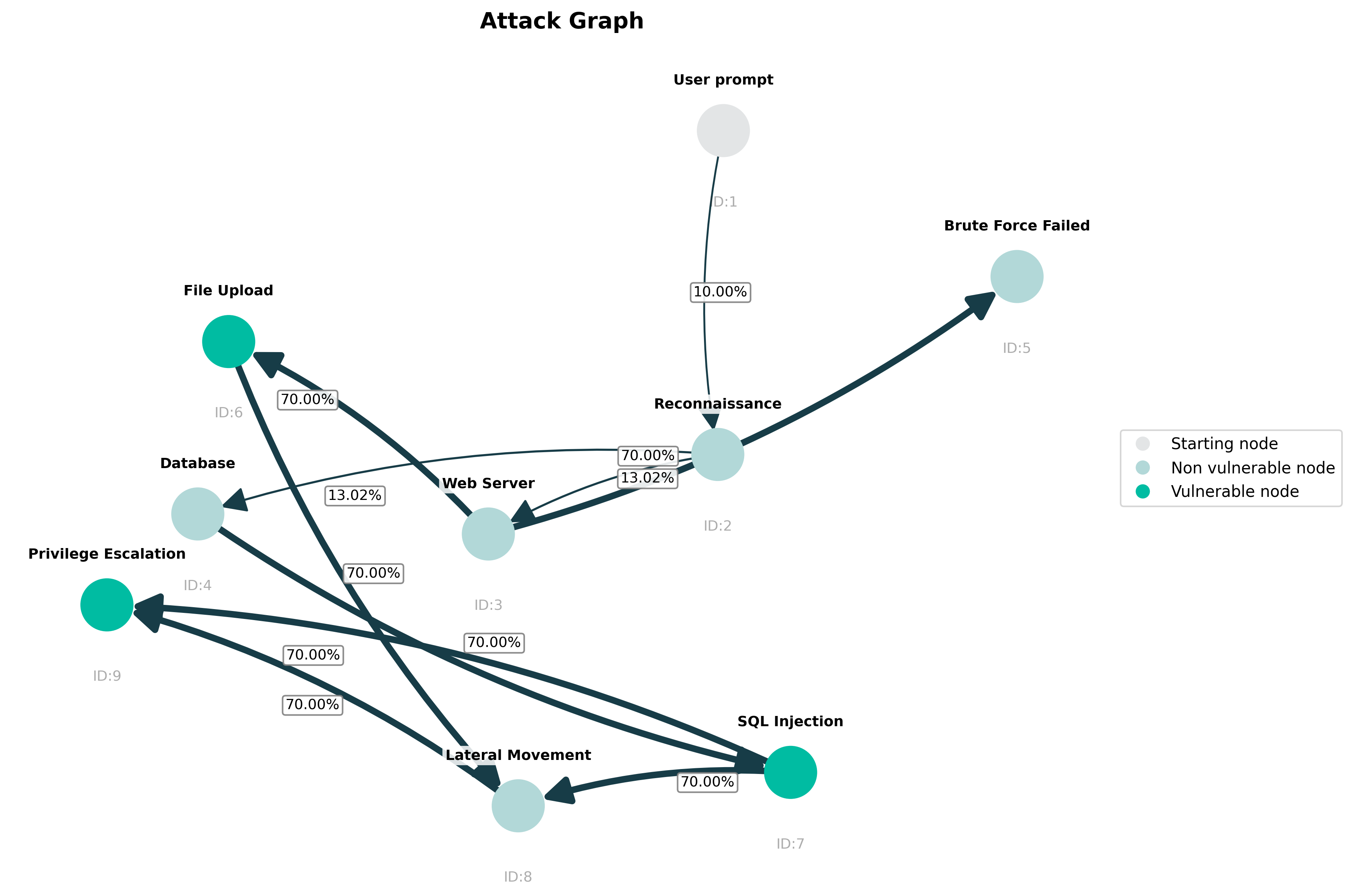
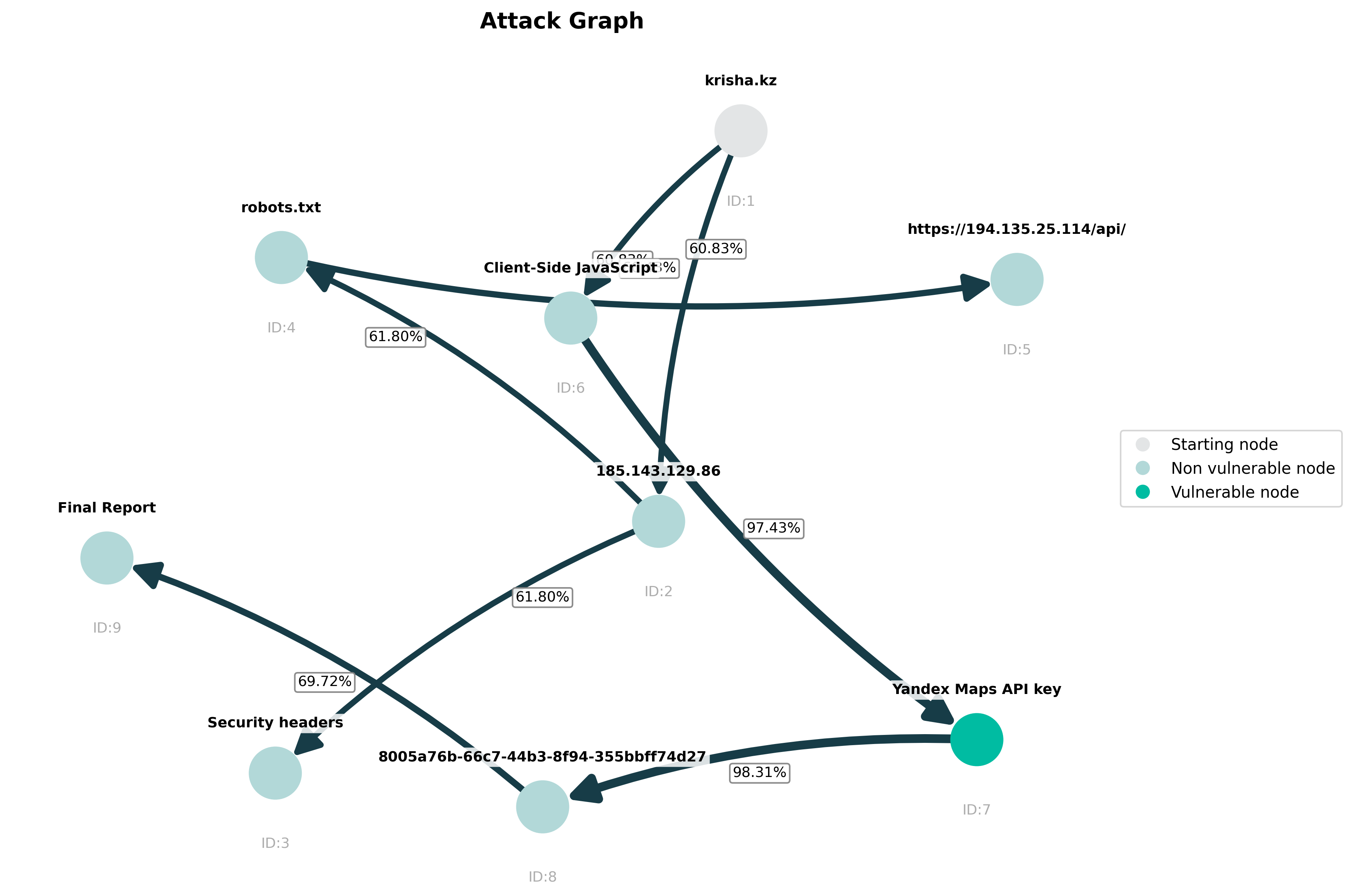
- Limited evaluation scope (five exercises, 6–15-node graphs): assess scalability and fidelity on large, heterogeneous enterprise networks and long-running operations with hundreds–thousands of nodes.
- Absence of edge-level and path-level validation: beyond 70–90% node correspondence, quantify precision/recall for edges, path correctness, and vulnerability marking accuracy; report inter-annotator agreement for expert baselines.
- Unspecified handling of cycles in LLM-generated graphs: define and evaluate cycle detection/removal procedures and their impact on game-theoretic outcomes and graph fidelity.
- Effort-based scoring lacks formal grounding: rigorously justify the mapping from token count, message distance, and cost to probabilities or utilities; perform sensitivity analyses to show how equilibria change with scoring choices and parameter weights.
- CTR model assumptions may not match real operations: evaluate robustness to non-DAG topologies, concurrent actions, feedback loops, time-varying system states, and non–Poisson attacker dynamics; explore alternative stochastic models and partial-information games.
- Fixed attacker rate parameter () is arbitrary: empirically estimate and adapt from observed agent behavior; evaluate performance across varying defender inspection windows and attacker tempos.
- Digest update cadence (every ~80 tool calls) is heuristic: investigate adaptive triggering based on novelty, uncertainty, or risk signals; quantify trade-offs between timeliness, overhead, and guidance quality.
- Lack of ablation studies: disentangle contributions of automated graph extraction, effort scoring, Nash equilibrium computation, and LLM digest interpretation; measure marginal gains of each component.
- No comparison against established attack graph tooling (e.g., MulVAL) or recent ML-based systems: benchmark G-CTR’s graph quality, speed, and cost against baselines across shared datasets.
- Potential susceptibility to log poisoning and prompt injection: analyze adversarial robustness when attackers manipulate logs or context to mislead graph extraction and digest guidance; propose mitigations.
- Control of LLM hallucinations is ad hoc (node caps): design principled validation, uncertainty estimation, and filtering for extracted graph elements; quantify false positive/negative rates and their operational impact.
- Defensive outcomes underexplored: beyond attacker success metrics, measure defender utility (e.g., MTTD/MTTR, incident false positives/negatives, risk reduction), resource usage, and operational feasibility of recommended inspections.
- Information-sharing risks in Purple G-CTRmerged: assess whether a shared digest disproportionately benefits attackers, leaks sensitive defensive posture, or enables strategy overfitting; study conditions where merged guidance harms defense.
- Human factors and interpretability: evaluate how analysts consume the digest, cognitive load, decision quality, and HITL interaction patterns; test UI/UX designs that improve trust and actionability.
- Real-time deployability constraints: quantify compute latency, cost, and throughput under realistic SOC conditions; evaluate performance with constrained budgets and edge deployments.
- Generalization across LLMs: report model-specific dependencies, performance across different LLM families (open/closed), and cost-quality trade-offs; specify prompts, seeds, and temperature settings for reproducibility.
- Formal properties of equilibria with effort-based graphs: prove existence/uniqueness (or characterize conditions) of Nash equilibria under the modified payoff structure; explore mixed-strategy stability and convergence of any solvers used.
- Multi-exercise graph merging risks: define criteria and safeguards to prevent context contamination, erroneous edge creation across unrelated scenarios, and misleading equilibria.
- Evaluation of failure modes: identify cases where G-CTR guidance degrades performance (misprioritization, overfitting to spurious paths), and design fallback strategies or confidence thresholds.
- Economic assumptions for “faster and cheaper”: transparently detail cost models (human rates, compute pricing, LLM billing) and test sensitivity to realistic variability.
- Security and privacy of operational logs: address governance, compliance, and confidential data handling for log ingestion and LLM processing; propose privacy-preserving graph extraction.
- Metrics beyond success rate: incorporate vulnerability severity, exploit reliability, impact, and defender remediation quality to assess strategic value, not just win/loss outcomes.
- Open data/code artifacts: provide public release of annotated graphs, logs, scoring parameters, equilibria outputs, and digest prompts to enable external validation and extension.
Collections
Sign up for free to add this paper to one or more collections.

