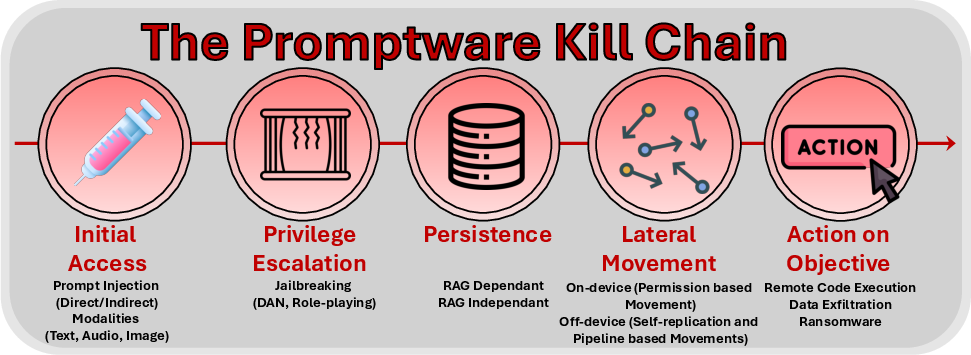
The Promptware Kill Chain: How Prompt Injections Gradually Evolved Into a Multi-Step Malware
Abstract: The rapid adoption of LLM-based systems -- from chatbots to autonomous agents capable of executing code and financial transactions -- has created a new attack surface that existing security frameworks inadequately address. The dominant framing of these threats as "prompt injection" -- a catch-all phrase for security failures in LLM-based systems -- obscures a more complex reality: Attacks on LLM-based systems increasingly involve multi-step sequences that mirror traditional malware campaigns. In this paper, we propose that attacks targeting LLM-based applications constitute a distinct class of malware, which we term \textit{promptware}, and introduce a five-step kill chain model for analyzing these threats. The framework comprises Initial Access (prompt injection), Privilege Escalation (jailbreaking), Persistence (memory and retrieval poisoning), Lateral Movement (cross-system and cross-user propagation), and Actions on Objective (ranging from data exfiltration to unauthorized transactions). By mapping recent attacks to this structure, we demonstrate that LLM-related attacks follow systematic sequences analogous to traditional malware campaigns. The promptware kill chain offers security practitioners a structured methodology for threat modeling and provides a common vocabulary for researchers across AI safety and cybersecurity to address a rapidly evolving threat landscape.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper explains a new kind of computer threat that targets AI systems like chatbots and AI assistants. The authors argue that many “prompt injection” attacks are not just one-off tricks—they’re more like multi-step malware campaigns. They introduce a simple five-step model (a “kill chain”) to describe how these attacks work from start to finish, and they propose a new name for this kind of threat: “promptware.”
What questions are they asking?
The paper tries to answer:
- Are attacks on AI systems really just “prompt injections,” or are they more complicated?
- Can we describe these attacks in clear stages so defenders know where and how to stop them?
- How do recent real-world examples fit into this step-by-step view?
How did they study it?
Instead of running a lab experiment, the authors:
- Reviewed real incidents and demos where AI systems were tricked or misused.
- Noted that these attacks often followed a pattern: first getting in, then breaking rules, then sticking around, then spreading, and finally doing harm.
- Built a five-step framework (inspired by traditional cybersecurity “kill chains”) to map and compare these attacks.
Think of it like analyzing a heist: even if each robbery is different, many follow the same stages—scouting, breaking in, disabling alarms, moving through the building, and stealing valuables. They did this mapping for AI attacks.
What did they find?
The main finding is that attacks on AI systems often unfold in predictable stages, similar to classic malware campaigns. The authors call the overall threat “promptware,” because the “payload” isn’t a traditional program—it’s natural language (or images/audio with hidden instructions) given to an AI.
Here are the five stages, explained simply:
- Initial Access: Getting in. The attacker slips sneaky instructions into something the AI reads (like a webpage, email, document, or even an image). This is commonly called “prompt injection.”
- Privilege Escalation: Breaking the rules. The attacker “jailbreaks” the AI—tricks it into ignoring safety guidelines it normally follows.
- Persistence: Sticking around. The attacker plants instructions in places the AI reuses later, like its memory or a searchable database, so the trick keeps working.
- Lateral Movement: Spreading. The attack moves to other users, apps, or systems—like a rumor that jumps from person to person through shared documents or messages.
- Actions on Objective: Doing harm. The attacker finally uses the AI’s powers—stealing data, sending phishing messages, controlling smart devices, spending money, or running code.
Why this matters:
- Today’s AI systems can read emails, browse the web, run code, control smart home devices, and move money. That makes the final step potentially serious.
- Guardrails (filters and safety training) help, but the authors argue they can be bypassed because the AI can’t perfectly tell “instructions” from “regular information.” If malicious instructions are hidden inside normal-looking content, the AI may follow them.
Why does this matter?
Treating everything as “prompt injection” oversimplifies the problem. Defenders need to think about each stage:
- Even if attackers get in, can you stop them from jailbreaking the model?
- If they jailbreak, can you block them from saving anything that sticks around (persistence)?
- If something sticks, can you stop it from spreading to other apps or users?
- If it spreads, can you limit what damage it can do?
By naming and separating the steps, teams can plan specific defenses for each one, rather than relying only on general-purpose filters.
What could happen next?
Implications for building safer AI:
- Limit permissions: Give AI assistants only the access they need (not full control over email, files, devices, or money by default).
- Keep humans in the loop for sensitive actions: Require approvals for risky steps like sending payments or accessing private files.
- Watch the AI’s memory and knowledge bases: Prevent or detect poisoned entries that could make bad instructions “stick.”
- Segment systems: Don’t let one compromised tool automatically control everything else.
- Monitor and respond by stage: Assume attackers might get initial access; focus on stopping later stages where real damage happens.
In short, the paper reframes “prompt injection” as just the first step in a larger, malware-like process. By seeing these attacks as “promptware” with a five-step kill chain, researchers and engineers can better spot, block, and limit the harm from AI-targeted attacks.
Knowledge Gaps
Below is a single, concise list of the paper’s unresolved knowledge gaps, limitations, and open questions to guide future research.
- Formalization gap: no rigorous, formal threat model for “promptware” and its five stages; unclear criteria for stage boundaries and automated stage classification.
- Architectural uncertainty: no formal proof or explored alternatives for enforcing an instruction–data separation inside LLMs (e.g., typed context channels, capability tokens, DSL-based execution).
- Quantitative validation missing: the kill-chain framework is demonstrated on a small set of anecdotal incidents; lacks large-scale empirical evaluation across diverse models, agents, sectors, and integrations.
- Benchmarking void: no standardized multi-stage promptware benchmarks, red-teaming protocols, or reproducible testbeds to compare defenses and measure progress.
- Stage-specific defense efficacy: lacks concrete, measurable mitigations per kill-chain stage and comparative analysis of their effectiveness, costs, and failure modes.
- Guardrail metrics absent: no standardized metrics to evaluate guardrails (bypass rates, false positives/negatives, transferability of jailbreaks) across models and versions.
- Multimodal injection underexplored: limited coverage of image/audio/video attack vectors; need robustness studies, preprocessing defenses (OCR/ASR hardening), and cross-modal transferability analysis.
- Persistence mechanisms: insufficient treatment of memory architectures (agent memories vs RAG vs caches); need detection, integrity checks, sanitization, and safe memory management policies.
- Prompt-based C2 detection: no techniques or indicators to discover, disrupt, or sinkhole persistent remote command channels embedded in prompts or memories.
- Provenance and lineage: missing mechanisms to track prompt provenance within context windows, attribute actions to specific sources, and provide auditable causal chains for agent behavior.
- Telemetry and forensics: lack of logging standards for context windows, memory writes/reads, tool invocations, and retrieval events to support incident response and evidence preservation.
- RAG trust policies: no protocols for content provenance (e.g., signed documents), trust scoring, or retrieval-time enforcement to prevent poisoning and indirect injection.
- Lateral movement taxonomy: incomplete enumeration and modeling of pathways (cross-user, cross-application, cross-tenant, pipeline-based, permission-based) and their risk drivers.
- Integration graph modeling: missing methods to automatically map agent permission surfaces and integration graphs to predict lateral movement and constrain blast radius.
- Least-privilege at scale: no automated approaches for permission minimization, dynamic capability gating, and fine-grained sandboxing of tools and APIs across heterogeneous agent ecosystems.
- Human-in-the-loop trade-offs: unstudied effects of approvals and reviews on stopping propagation vs enabling exploitation (e.g., social engineering of confirmations), and UX impacts.
- Delayed tool invocation defenses: no specific detection and mitigation strategies for time-shifted payloads that trigger in future inferences.
- Network egress controls for agents: absent frameworks to monitor and restrict agent-initiated outbound communications, especially for covert exfiltration and C2 fetches.
- Transferability and universality: limited analysis of black-box vs white-box attacker models and universal jailbreak transfer across vendors, versions, and modalities.
- Economic/physical impact quantification: no sector-specific risk models (finance, healthcare, ICS/smart homes) or empirical quantification of expected losses and safety impacts.
- Formal verification/runtime enforcement: lack of verified policies or runtime guards for tool invocation, capability boundaries, and action safety constraints in agents.
- Compliance and privacy: underexplored implications of memory poisoning, cross-tenant leakage, and exfiltration for regulatory compliance and user privacy.
- Incident response playbooks: no stage-mapped response guidance (containment, eradication, recovery) tailored to LLM systems and agent workflows.
- Epidemiological modeling: no models (e.g., R0, propagation dynamics) for wormable promptware to inform preventive controls and thresholds for intervention.
- Model update dynamics: missing continuous evaluation frameworks tracking attacker–defender co-evolution, patch cycles, and regression risks in defenses and guardrails.
- Plugin/MCP supply-chain risk: no standards for plugin vetting, permission isolation, and runtime attestation across agent marketplaces and enterprise integrations.
- Multitenant/SaaS boundaries: lack of systematic study of cross-tenant lateral movement in shared SaaS and identity meshes, including mitigations for shared indexes and pipelines.
- Standardization and governance: no vendor-agnostic norms for agent permissions, logging, attestations, and security baselines aligned with the proposed kill-chain perspective.
Practical Applications
Immediate Applications
Below are actionable applications that can be deployed now, drawing directly from the paper’s Promptware Kill Chain (Initial Access → Privilege Escalation → Persistence → Lateral Movement → Actions on Objective) and the concrete incidents it analyzes.
- LLM threat modeling and design reviews grounded in the Promptware Kill Chain (software, finance, healthcare, education)
- Use the five stages to structure security design reviews, architecture diagrams, and integration approvals; add kill-chain checkpoints to AI threat models beyond generic “prompt injection.”
- Tools/products/workflows: threat-model templates, design review checklists, MITRE-style mapping for LLMs, Jira/Confluence templates; add a “kill-chain exposure” section to PRDs and security design docs.
- Dependencies/assumptions: access to accurate system inventories; buy-in from product/security leads; ability to enumerate LLM tools, permissions, data stores, and egress paths.
- SOC detection content and incident response playbooks mapped to kill-chain stages (software, enterprise IT)
- Instrument logging around memory writes, RAG retrievals, tool invocations, egress calls; add SIEM/EDR rules (e.g., “external HTTP fetch immediately after retrieval,” “unexpected memory write from summarization flows,” “tool invocations without prior user confirmation”).
- Tools/products/workflows: agent activity logs schema, SIEM rulesets, SOAR runbooks for agent kill-switch, memory purge, RAG reindex, token revocation.
- Dependencies/assumptions: sufficient telemetry from LLM apps; centralized logging; ability to revoke tokens, reset memories, and rebuild indices.
- Red-team playbooks and tabletop exercises using known multi-step scenarios (industry, academia, policy exercises)
- Emulate Morris II-like self-replication via email, calendar-invite initial access with delayed tool invocation, and pipeline-based exfiltration via ticketing-to-IDE flows.
- Tools/products/workflows: curated promptware attack packs, lab environments (“AI purple-team labs”), tabletop materials for executives and engineering teams.
- Dependencies/assumptions: safe sandboxes; executive sponsorship; legal/ethics approvals for internal testing.
- RAG and memory hygiene controls to prevent persistence (software, healthcare, education)
- Introduce write-approval for memory, periodic memory purge, retention limits; RAG source allowlists, signed/attested content ingestion, retrieval auditing dashboards; canary prompts to detect untrusted retrieval.
- Tools/products/workflows: “memory firewall” middleware, allowlist/denylist gates, content provenance checks, dashboards showing top retrieved documents and their origins.
- Dependencies/assumptions: app supports memory governance APIs; ability to gate retrieval and memory writes; content provenance available for key sources.
- Permission and automation hardening to constrain lateral movement and actions on objective (finance, IoT/robotics, enterprise)
- Enforce least-privilege tool scopes, per-task permission prompts, rate limits, time-bounded tokens; disable auto-run for high-risk tools (code/shell, finance APIs, email send); separate service accounts by data domain.
- Tools/products/workflows: policy-as-code for tool access, approval workflows, transaction whitelists, “dry-run” modes for financial agents, API egress proxies.
- Dependencies/assumptions: granular tool/permission controls; human-in-the-loop UX; support from platform vendors to disable/limit auto-run.
- Lateral-movement mapping and “AI blast radius” assessments (software, enterprise IT)
- Build dataflow diagrams tracing how external content flows into RAG/memory, and how agent outputs feed other systems; identify cross-user/application/device spread paths.
- Tools/products/workflows: integration inventory, data lineage visualizations for AI pipelines, risk scoring per chain stage.
- Dependencies/assumptions: accurate integration catalogs; cooperation from platform owners; visibility across SaaS/IDP.
- Procurement and policy guardrails aligned to the kill chain (policy, industry)
- Add contract clauses requiring logging, egress controls, permission scoping, memory governance, and jailbreak resistance benchmarks; forbid “fully autonomous” modes in production without approvals.
- Tools/products/workflows: RFP questionnaires keyed to each kill-chain stage; vendor attestation forms (e.g., memory write controls, egress auditability).
- Dependencies/assumptions: procurement leverage; standardized questions; vendors willing to disclose controls.
- End-user and developer training specific to promptware (daily life, enterprise)
- Teach risks of indirect injection via emails/docs/webpages; how to review/clear assistant memory; caution with calendar invites; use of untrusted content in AI assistants; disable unnecessary integrations.
- Tools/products/workflows: microlearning modules; quickstart guides for safe assistant settings; “clear memory” job aids.
- Dependencies/assumptions: accessible settings in assistants; organizational comms channels; user willingness to adopt hygiene.
- CI/CD and developer workflow defenses against pipeline-based attacks (software)
- Scan synced tickets/issues/PRs for obfuscated instructions; require human confirmation for AI IDE tool runs that access secrets; restrict local FS search; mask secret patterns in agent context.
- Tools/products/workflows: pre-commit hooks, MCP/IDE policy plugins, secret scanners integrated with AI assistants, contextual redaction filters.
- Dependencies/assumptions: extension points in IDE/agent; secret pattern catalogs; developer acceptance.
- Sector-specific controls
- Finance: pre-trade simulation, value caps, destination whitelists, mandatory multi-sig for agent-initiated transfers; anomaly detection on “agent-originated” transactions.
- Healthcare: PHI egress proxy, domain allowlists, disallow external link fetching when PHI present, memory writes disabled or supervised in EHR assistants.
- Education: AI tutors ingest only curated repositories; disable persistent memory; logs for parent/administrator review.
- IoT/Smart home/Robotics: default deny for actuator control, time windows for actions, safety interlocks (e.g., no heater/window commands without second factor).
- Dependencies/assumptions: domain APIs support gating/whitelisting; regulatory and privacy requirements integrated into app design.
Long-Term Applications
These applications require additional research, vendor support, scaling, or ecosystem standardization before widespread deployment.
- Architectural separation of instructions and data for LLMs (software, academia)
- Dual-channel tokenization, typed contexts, capability-aware decoding, or enforcement layers that guarantee instruction/data boundaries at inference time.
- Tools/products/workflows: model architectures and runtimes with verifiable separation; policy-enforced decoding.
- Dependencies/assumptions: advances in model design; platform adoption; measurable guarantees.
- Agent EDR/IPS platforms with quarantine and C2 detection (software, enterprise)
- Runtime policy enforcement on tool calls; sandboxed execution for high-risk tools; detection of beaconing to attacker-controlled URLs; memory quarantine and rollback.
- Tools/products/workflows: “Agent EDR” suite, allowlisted tool brokers, anomaly models for agent behavior, kill-switch APIs.
- Dependencies/assumptions: stable agent telemetry standards; hooks from commercial assistants; organizational SOC maturity.
- Memory-safe and zero-trust RAG architectures (software, healthcare, finance)
- Signed memory entries; per-source compartments and taint tracking; write policies requiring provenance; retrieval constrained by trust levels; automatic decay and review queues.
- Tools/products/workflows: cryptographic attestation (e.g., C2PA) integrated into RAG; memory governance services.
- Dependencies/assumptions: provenance adoption across content platforms; performance overhead acceptable.
- Standardized ATT&CK-style knowledge base for promptware (academia, policy, industry)
- Community-maintained techniques, tactics, procedures (TTPs) for each kill-chain stage; mapped detections and mitigations; CVE-like identifiers for promptware patterns.
- Tools/products/workflows: public matrix, sigma-style rules, shared test corpora.
- Dependencies/assumptions: cross-vendor collaboration; disclosure processes.
- Benchmarking ranges and datasets for multi-step promptware (academia, industry)
- Open “Promptware Range” with realistic pipelines (email, ticketing, IDE, browsers) to evaluate defenses; datasets of indirect injections and multimodal payloads.
- Tools/products/workflows: reproducible labs; challenge leaderboards.
- Dependencies/assumptions: safe red-team infrastructure; legal frameworks for testing.
- Multimodal sanitization and provenance pipelines (software, media platforms)
- Robust defenses for image/audio/video-borne prompts, including OCR-aware filters, adversarial detection, and cryptographic content provenance in retrieval.
- Tools/products/workflows: multimodal content firewalls, “safe decoding” layers, provenance-aware retrievers.
- Dependencies/assumptions: research progress on multimodal adversarial robustness; platform support for provenance.
- Formal methods for agent workflow verification and least-privilege policies (academia, safety-critical sectors)
- Model checking of agent plans; provable constraints on tool invocation sequences; typed capabilities that statically limit actions on objective.
- Tools/products/workflows: policy languages for agents; verification toolchains.
- Dependencies/assumptions: tractable abstractions for agent behavior; developer adoption.
- Regulatory and certification regimes for agentic systems (policy, regulators, insurers)
- Sector-specific controls (e.g., finance, healthcare) certified against kill-chain exposures; minimum logging/egress/memory standards; labeling for autonomy levels.
- Tools/products/workflows: audit criteria, conformance tests, “AI Agent Safety Level” certifications.
- Dependencies/assumptions: consensus on standards; enforcement mechanisms; international coordination.
- Hardware/OS co-design for agent privilege separation (software, robotics/IoT)
- OS-level mediation specific to AI tools; secure enclaves for agent execution; hardware-backed attestation of tool calls and dataflow provenance.
- Tools/products/workflows: “Agent OS” primitives, TEE-integrated agent runtimes.
- Dependencies/assumptions: vendor ecosystem changes; performance trade-offs.
- Financial and economic safeguards for AI-driven transactions (finance)
- Typed financial capabilities, programmable risk budgets, AI-specific multi-sig with human or rule-based co-signers, post-trade surveillance that understands agent contexts.
- Tools/products/workflows: policy engines for trading/treasury agents; compliance analytics.
- Dependencies/assumptions: integration with custodians/exchanges; regulatory acceptance.
- Consumer-grade “AI firewall” and memory manager (daily life)
- Local or browser-based guard that strips or flags suspicious instructions from retrieved content, monitors assistant memory writes, offers one-click memory scrub and per-app permission gating.
- Tools/products/workflows: desktop/mobile agents; browser extensions; companion apps for smart assistants.
- Dependencies/assumptions: assistant APIs for telemetry and control; UX that balances safety with usability.
- Safety frameworks for physical-world integrations (energy, smart buildings, robotics)
- Rate limiters, physical interlocks, safety envelopes that prevent hazardous sequences requested by LLMs; mandatory secondary confirmations for critical actuations.
- Tools/products/workflows: safety PLCs/guards mediating AI commands; policy orchestration across IoT hubs.
- Dependencies/assumptions: retrofit feasibility; vendor openness; alignment with existing safety standards (e.g., IEC/ISO).
Notes on overarching assumptions
- The paper assumes the architectural limitation that LLMs cannot reliably separate instructions from data; defenses therefore emphasize containment across the kill chain.
- Feasibility improves with: rich telemetry, fine-grained tool permissions, controllable memory/RAG layers, and organizational readiness (process and culture).
- Multimodal defenses depend on advances in adversarial robustness and provenance standards.
- Many long-term applications require vendor-level changes, ecosystem standards, and regulatory clarity.
Glossary
- Actions on Objective: Final phase of an attack where the adversary achieves their goals (e.g., data theft, fraud, physical impact). Example: "Actions on objective represent the final phase of the promptware kill chain:"
- Adversarial suffixes: Optimized token sequences appended to prompts to bypass safety mechanisms across multiple models. Example: "Researchers used gradient-based optimization to automatically discover universal jailbreaks in the form of adversarial suffixes that are effective against ChatGPT, Bard, Claude, and other major models"
- Agentic frameworks: Software architectures that enable LLMs to use tools or sub-agents autonomously to perform tasks. Example: "With the integration of agentic frameworks into chatbots, developers have started to add architectural mitigations to contain the damage in the case of poisoned context."
- Agentic systems: LLM-driven applications with tool access and autonomy that can execute complex sequences of actions. Example: "Agentic systems with access to terminals, code interpreters, or development environments can be manipulated to execute attacker-supplied code."
- Alignment: Safety training that guides LLMs to refuse harmful or policy-violating requests. Example: "Modern LLMs incorporate safety training designed to refuse harmful requests (alignment), and applications often deploy additional security measures such as input/output filtering."
- Command and Control (C2): A mechanism allowing attackers to remotely update and direct a compromised agent over time. Example: "Command and Control (C2)"
- Command-and-control channel: A persistent instruction path that fetches and executes attacker-controlled commands on each interaction. Example: "This, in effect, establishes a command-and-control channel between the attacker and the agent."
- Context window: The sequence of tokens (instructions and data) visible to the model during inference. Example: "Prompt injection achieves initial access: The attacker's payload enters the LLM's context window via direct or indirect prompt injection;"
- Cyber Kill Chain: A staged model for analyzing cyberattacks, adapted here to LLM-based threats. Example: "Our framework draws on the Cyber Kill Chain,"
- Data exfiltration: Unauthorized extraction of sensitive data from a system or application. Example: "Traditional malware actions on objective include data exfiltration or destruction,"
- Delayed tool/agent invocation: A technique where instructions cause tools or agents to execute later, often after a trigger in a future inference. Example: "In parallel, new techniques of delayed tool/agent invocation techniques appeared in promptware, causing agents to output data that contains instructions to execute a payload given a trigger in a future inference"
- Direct prompt injection: An attacker crafts input directly into an LLM application to subvert it. Example: "In direct prompt injection, the attacker is the user interacting with the LLM application directly, crafting input designed to bypass its guardrails."
- Guardrails: Application-layer defenses (filters, classifiers, hardened prompts, safety tuning) intended to block harmful behavior. Example: "Guardrails represent the primary defensive response to this threat."
- Indirect prompt injection: An attacker embeds malicious instructions in external content that the LLM later retrieves. Example: "Indirect prompt injection inverts the threat model and turns the user of the LLM application into the victim."
- Initial Access: The first stage of an attack where malicious input enters the LLM’s context. Example: "Initial Access (prompt injection)"
- Jailbreaking: Techniques that bypass an LLM’s safety training, inducing it to perform otherwise refused actions. Example: "Jailbreaking constitutes the privilege escalation phase of promptware."
- Kill chain: A structured sequence of attack stages used for analysis and defense. Example: "The promptware kill chain offers security practitioners a structured methodology for threat modeling"
- Lateral movement: Propagation of an attack across users, applications, devices, or systems after initial compromise. Example: "Lateral movement refers to techniques by which promptware spreads from its initial point of compromise to other applications, users, or systems."
- Lethal Trifecta: Three conditions enabling data exfiltration: sensitive data access, exposure to untrusted content, and external communication ability. Example: "Simon Willison has characterized the preconditions for data exfiltration in LLM-based applications as the 'Lethal Trifecta': access to sensitive data, exposure to untrusted content, and the ability to communicate externally."
- Long-term memory: Persistent agent storage incorporated into every subsequent interaction. Example: "A stronger form of persistence targets the agent's own long-term memory rather than external data stores."
- Memory and retrieval poisoning: Corruption of persistent stores (memories, RAG databases) to maintain malicious influence. Example: "Persistence (memory and retrieval poisoning)"
- Multimodal LLMs: Models that process multiple modalities (text, images, audio, video) natively. Example: "As LLMs evolve into Multimodal LLMs that can natively process images, audio and video alongside text, the attack surface expands correspondingly."
- Permission-based movement: Lateral movement that leverages an agent’s broad or unified permissions to act across services. Example: "Permission-based movement occurs when promptware exploits an agent's elevated or unified permissions."
- Persona-based attacks: Jailbreaking prompts that instruct the model to adopt an unconstrained persona. Example: "One example is persona-based attacks, such as the 'Do Anything Now' prompt, which instructs the model to adopt an alternate persona unconstrained by safety guidelines"
- Pipeline-based movement: Traversal along integrated data flows where one system’s output becomes another’s input. Example: "Pipeline-based movement occurs when promptware traverses data flows, exploiting the fact that the output of one task becomes the input of another."
- Privilege boundary: The conceptual limit imposed by safety training on what a model will do. Example: "These constraints function as a privilege boundary: The model can perform certain tasks but will not."
- Privilege Escalation: Stage where attackers gain elevated capabilities by bypassing constraints. Example: "Privilege Escalation (jailbreaking)"
- Prompt injection: Malicious natural-language input that subverts LLM behavior by entering its context as instructions. Example: "This class of attacks---where LLM-based systems are targeted by malicious 'prompts' written in natural language---is commonly labeled as 'prompt injection',"
- Promptware: A class of malware comprising malicious inputs to LLM-based applications that trigger harmful activity. Example: "Attacks on LLM-based systems constitute a new class of malware, which we term promptware"
- Remote code execution: Execution of attacker-supplied code on a target system via an agent’s tooling or environment. Example: "Remote code execution represents perhaps the most severe outcome."
- Reinforcement Learning from Human Feedback (RLHF): A safety alignment method that trains models to follow human-preferred behavior. Example: "reinforcement learning from human feedback (RLHF)"
- Retrieval-augmented generation (RAG): An approach where external documents are retrieved and injected into the model’s context to inform responses. Example: "other data sources accessed via retrieval-augmented generation (RAG)."
- Retrieval-Dependent Persistence: Persistence that reactivates only when poisoned content is retrieved by RAG. Example: "Retrieval-Dependent Persistence"
- Retrieval-Independent Persistence: Persistence that injects malicious memory into every interaction regardless of retrieval. Example: "Retrieval-Independent Persistence"
- Role-play attacks: Jailbreaking prompts that frame prohibited actions as fictional role-playing. Example: "Another example is role-play attacks, which frame prohibited requests as fiction, asking the model to respond 'as a character' who would comply."
- Self-replicating movement: Propagation where compromised agents embed the payload in outgoing content to infect others. Example: "Self-replicating movement occurs when promptware forces a compromised agent to embed copies of itself in outgoing content."
- Self-replicating payloads: Malicious instructions engineered to copy themselves into agent outputs for propagation. Example: "adversarial self-replicating payloads that were engineered to force the LLM to include a copy of the malicious instructions in its output."
- Semantic similarity: The measure used by retrieval systems to surface context relevant to a user query. Example: "Retrieval depends on semantic similarity between the user's query and the stored content, and retrieval functions typically prioritize recency."
- Universal jailbreaks: Jailbreaking prompts effective across multiple models without modification. Example: "Research has demonstrated that 'universal' jailbreaks exist:"
- Vision-LLM: Models that integrate visual and textual understanding to execute prompts from images. Example: "An image containing embedded text instructions, for example, can be processed by a vision-LLM and executed,"
- Zero-day prompt injection: Previously unseen injection techniques that evade existing defenses due to lack of signatures. Example: "This creates conditions for zero-day prompt injection:"
Collections
Sign up for free to add this paper to one or more collections.

