- The paper presents a novel hybrid agentic language that uses control constructs like IF, GOTO, and FORALL to enable deterministic execution of natural language plans.
- It details a structured three-module architecture—Initialization, Compiler, and Executor—that dynamically selects between LLM reasoning, tool invocation, and code generation.
- The framework demonstrates effective constraint extraction and enforcement, achieving an 81.1% exact match accuracy on Calendar Scheduling tasks.
RunAgent: Interpreting Natural-Language Plans with Constraint-Guided Execution
Introduction
RunAgent presents a comprehensive solution to the persistent challenge in plan execution by LLM-driven agents: bridging the expressive flexibility of natural language plans with stepwise, deterministic, and verifiable execution typical of programming frameworks. Most tool-augmented LLM agents struggle to reliably follow multi-step workflows unless tightly constrained, and often fail to consistently enforce constraints or adapt to dynamic exceptions within a plan. RunAgent proposes an agentic language with explicit control constructs (IF, GOTO, FORALL), a suite of verification and constraint generation methods, and a robust multi-module execution architecture capable of dynamic choice among LLM reasoning, tool invocation, and code generation.
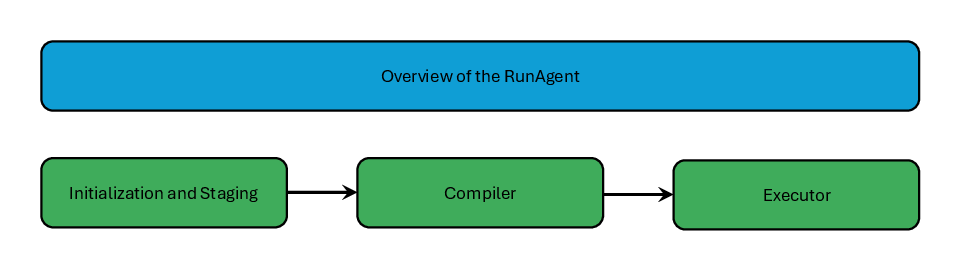
Figure 1: An overview of RunAgent, highlighting its three main modules.
Agentic Language and Control Constructs
A central innovation in RunAgent is its hybrid agentic language, designed to preserve the adaptability of natural language instructions while enabling deterministic execution through a limited set of reserved, compositional keywords. The IF, GOTO, and FORALL constructs support branching, jumps, and comprehensive iteration—addressing LLM limitations in reliably enumerating elements in a set or following conditional workflows. Each plan step can be explicitly prefixed with execution modality modifiers (LLM, PYTHON, TOOL), granting both users and the system granular control over execution pathways. Notably, RunAgent interprets these constructs directly, extracting and expanding steps and sub-steps as needed, rather than relying on the LLM to parse or enforce control flow.
Architecture and Workflow
RunAgent’s execution pipeline is structured around three core modules: Initialization and Staging, Compiler, and Executor.
Initialization and Staging
This module registers tools—encapsulated as Python functions—and encodes their metadata for dynamic retrieval. Critically, it also aggregates and derives atomic constraints from both user input and the plan’s context using specialized LLM prompts. These constraints include both explicit requirements and implicit assumptions, each decomposed to ensure unambiguous satisfaction conditions.
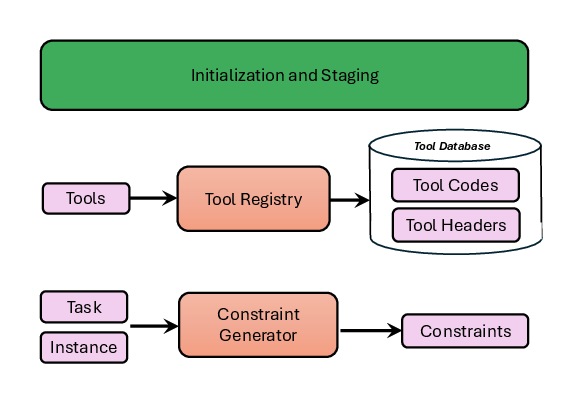
Figure 2: The Initialization and Staging module responsible for tool registry setup and constraint generation.
Compiler
The Compiler parses the natural language plan into a structured intermediate representation, detecting agentic keywords and generating the requisite internal control flow and sub-steps, particularly for FORALL and conditional IF branches. Each plan step is transformed into a machine-readable format with annotated reasoning hints for downstream execution.
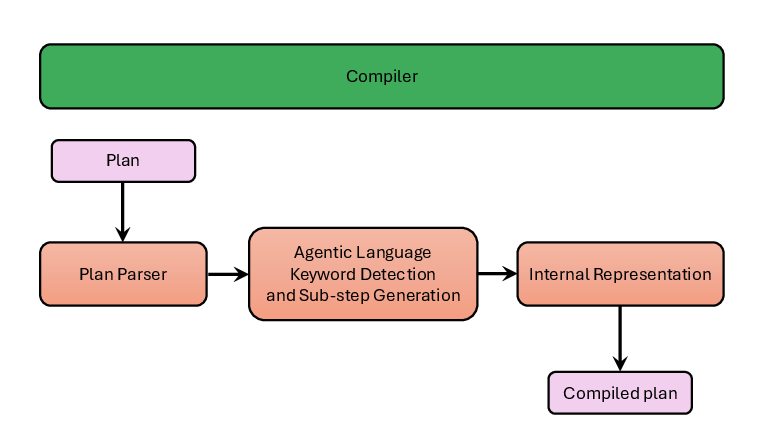
Figure 3: The Compiler module parses plans, identifies keywords, and structures sub-steps and control flow.
Executor
The Executor orchestrates the plan execution, handling each step’s interpretation, modality selection, logging, context state maintenance, and constraint/rubric validation. The Interpret Step submodule determines appropriate execution pathways, leveraging the tool registry, dynamic code generation, or LLM direct calls as appropriate. Sanity checks, constraint enforcement, and rubric-based grading are performed at each step, with fallback mechanisms ensuring robustness if errors or constraint violations persist after a threshold number of retries.
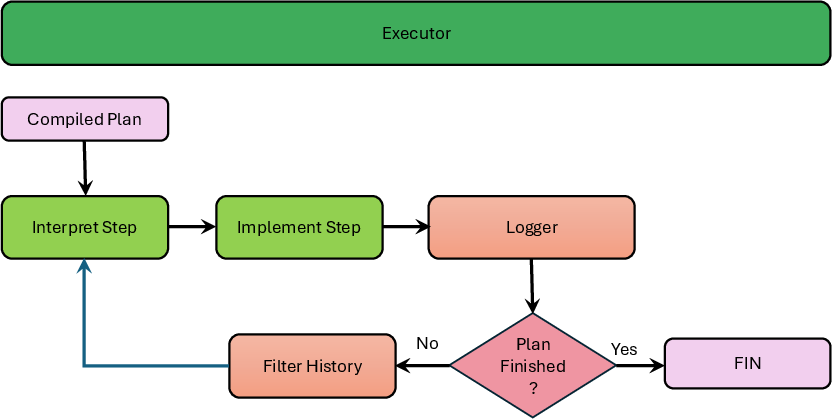
Figure 4: The Executor module implements plan steps, context management, and constraint checking.
Step Interpretation and Implementation
The Interpret Step module evaluates whether a step requires LLM response, code execution, or tool invocation. For code generation steps, a loop of code synthesis, validation by LLM-based code checking, and print-statement injection ensures generated code meets the specification before execution. Error states and constraint violations from each attempt are logged and injected into the prompt history for error-aware retries.
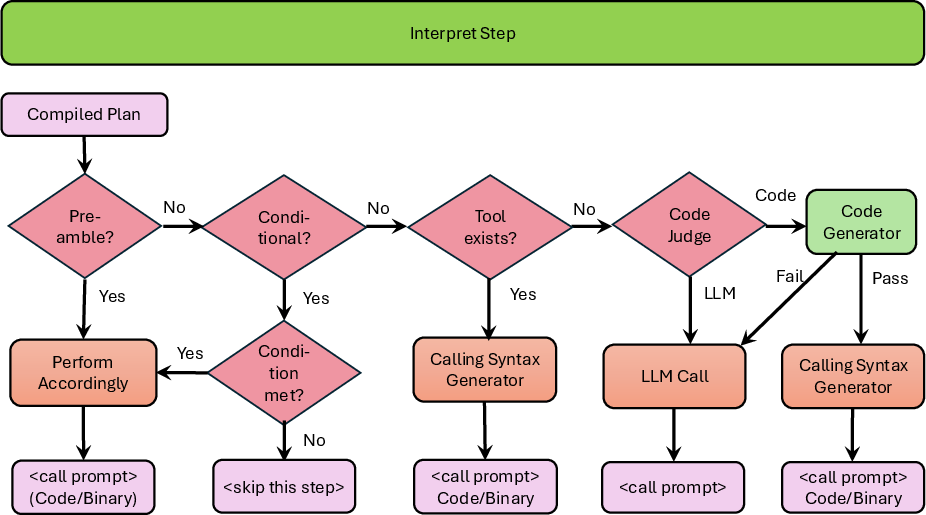
Figure 5: Interpret Step module decides execution modality and manages branching and iterative constructs.
Implementation uses the provided call prompt to execute the step, verifies output format and semantics, conducts constraints and rubric checking, and manages error-driven retries or fallback.
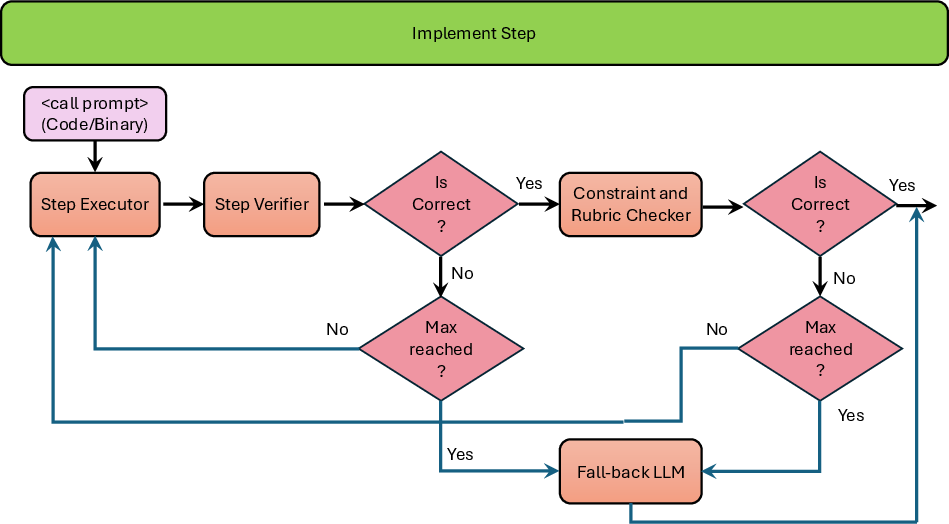
Figure 6: Implement Step executes the determined action, handling validity and retry logic.
Code Generation Flow
Instrumented code generation is iterated with LLM-driven syntax/error analysis until passing both structural and contextual checks.
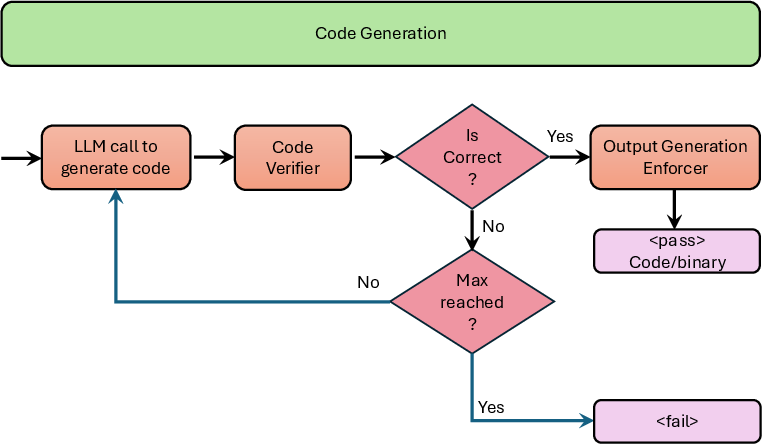
Figure 7: Code generation algorithm iteratively synthesizes and validates code modules for execution steps.
Constraint and Error Handling
Each step output is subject to atomic constraint checking using two-stage LLM validation, separating reasoning and final judgment to avoid ambiguous acceptance or spurious violations. Error correction amends the execution context with error rationales and constraint violation messages, steering further attempts to avoid repeated failures. If errors persist, the system reverts to LLM-based step completion to maintain plan progress.
Empirical Evaluation
RunAgent was evaluated on the Natural-plan Calendar Scheduling and Trip Planning datasets, as well as the SciBench Stat, Calc, and Diff datasets. Baselines included GPT-4o and SoTA PlanGEN methods. Results demonstrate RunAgent’s stepwise execution with constraint validation yields the highest exact match (EM) accuracy (81.1%) on Calendar Scheduling, exceeding PlanGEN BoN (best-of-N, 68.9%) and substantially surpassing all GPT-4o and Gemini compositional or plan-driven baselines. An ablation removing constraint checking reduced RunAgent’s EM to 75.4%, highlighting the material role of automatic constraint enforcement.
RunAgent consistently outperformed both direct LLM solution attempts and LLM-driven plan executions not backed by RunAgent’s verification and stepwise enforcement, especially on complex, multi-modal reasoning tasks. Performance degrades only gradually as problem complexity increases, with error analysis showing a further upward correction in accuracy after accounting for multiple viable solutions missed by strict exact matching.
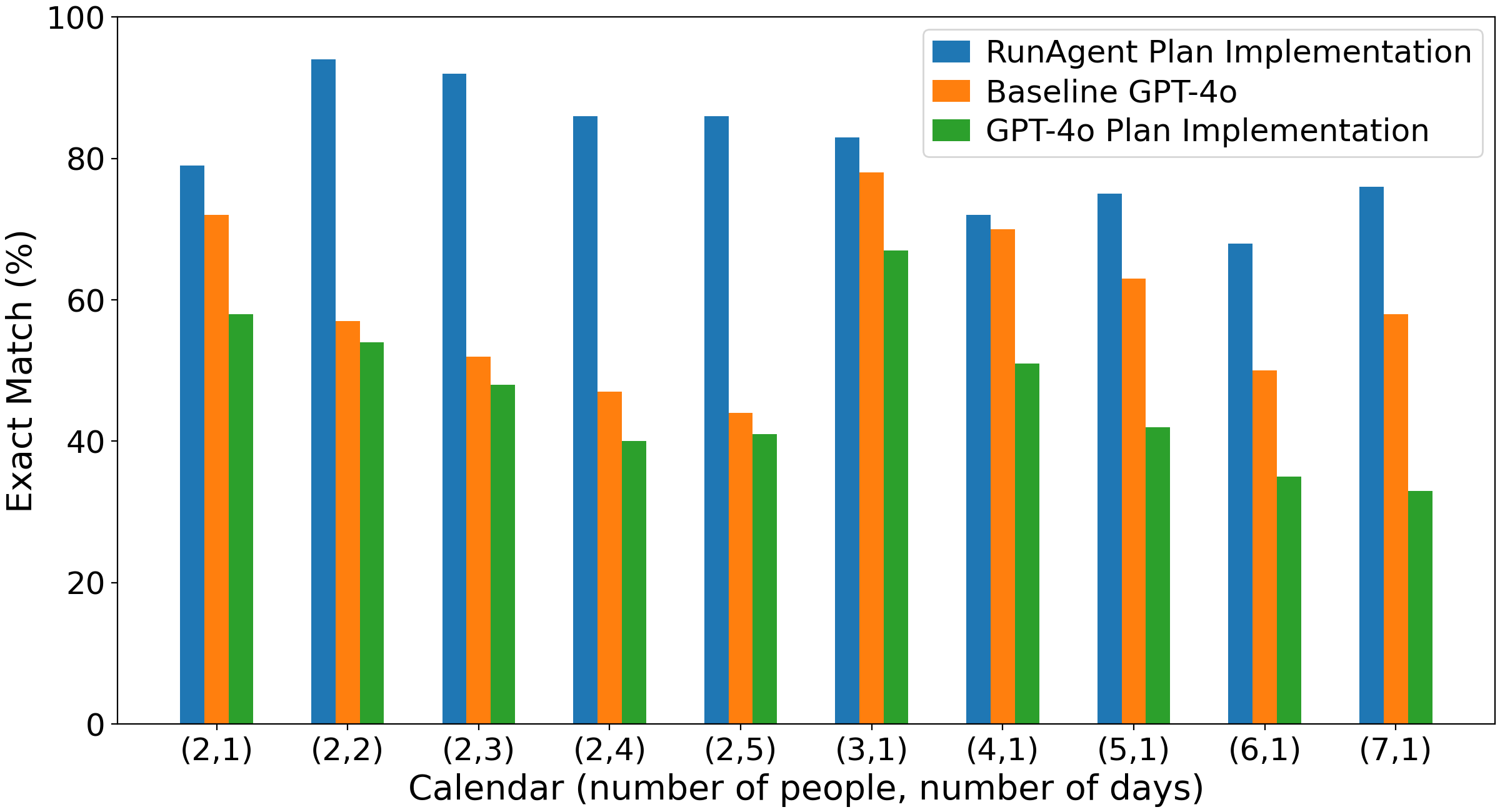
Figure 8: Accuracy for different problem complexities in Calendar Scheduling, demonstrating robustness across difficulty.
Statistical analysis using bootstrapping and McNemar’s test confirmed a significant superiority for RunAgent vs. GPT-4o plan implementation (p-value 5.29×10−56).
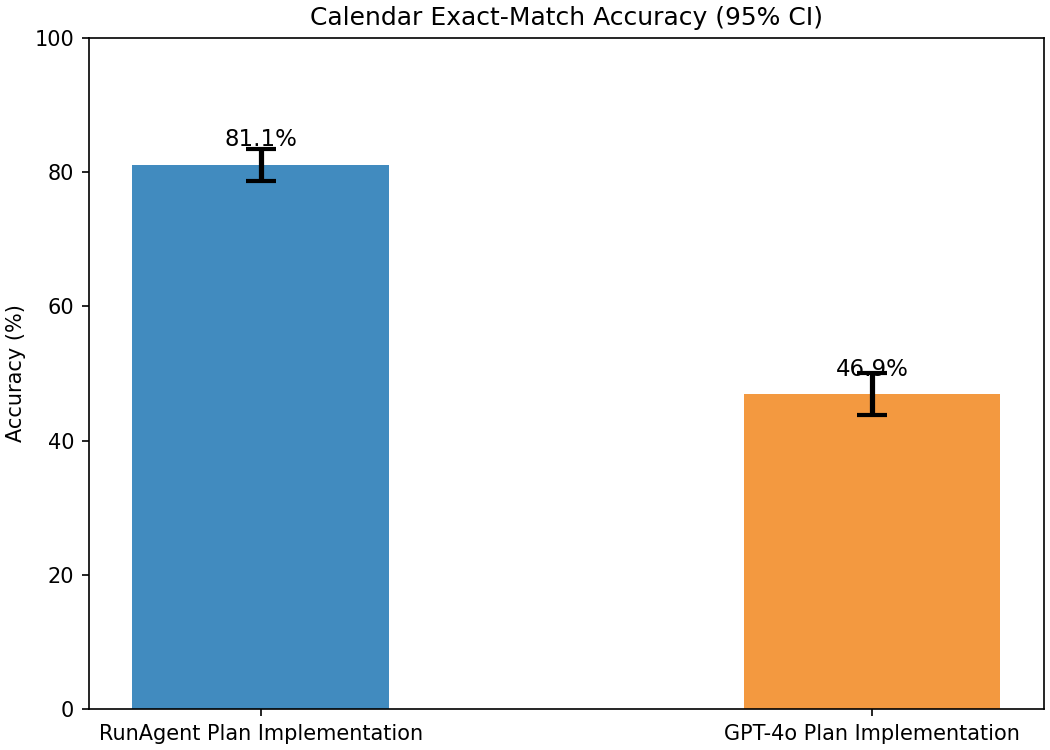
Figure 9: 95% Confidence intervals for Calendar Scheduling, validating the significance of RunAgent’s performance gain.
Implications and Future Directions
The RunAgent framework demonstrates that agentic languages with minimal but robust control constructs, coupled with LLM-based dynamic constraint extraction and enforcement, yield substantial improvements in reliable plan execution. The practical implications are immediate for workflow automation, scientific inquiry, scheduling, and domains requiring mixed reasoning modalities. The generalized design—separating plan generation from execution, using modular LLM components, and supporting HITL involvement—facilitates adaptation to domains demanding both flexibility and formal guarantees.
Theoretically, RunAgent exposes the limits of current LLMs in reliably following stepwise plans absent explicit architecture-level execution enforcement. This highlights the necessity of hybridized frameworks where agentic control constructs, dynamic tool registries, and constraint-derived verification complement LLM capabilities.
Looking forward, future developments may target (1) broader agentic language extension for richer control flow, (2) adaptive learning from user feedback/facts during plan execution, (3) tighter integration with external knowledge bases, and (4) end-to-end differentiable execution-planning architectures. Robust error propagation, runtime optimization across modalities, and more advanced context-filtering for efficiency and privacy also remain influential research vectors.
Conclusion
RunAgent establishes a principled blueprint for constraint-guided, verifiable plan execution in LLM agentic systems. By integrating explicit control language, atomic constraint synthesis, and dynamic execution selection, it achieves verifiable reliability and superior empirical performance on benchmarked reasoning tasks. This delineates a clear pathway for future agent design: explicit structure, robust mid-execution verification, and adaptability anchored in a hybrid of natural and formal specification paradigms.