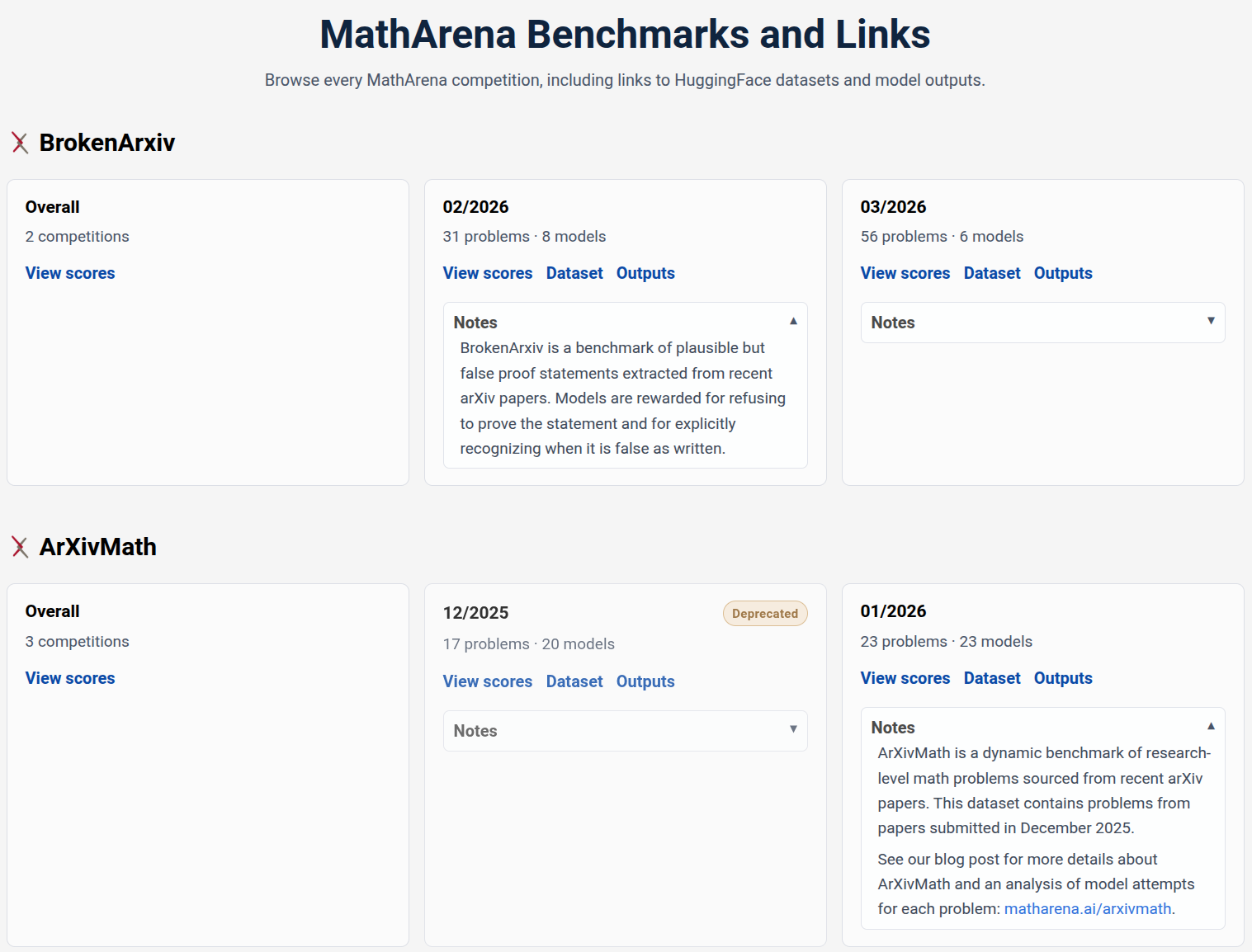
- The paper introduces MathArena, a dynamic platform that updates LLM math evaluation tasks continuously, addressing the limitations of static benchmarks.
- It details a robust methodology using item response theory-based imputation, multi-judge proof grading, and automated analysis for precise performance tracking.
- It reveals significant performance gaps in proof validation and formalization, highlighting critical challenges and future research priorities in LLM mathematical reasoning.
The rapid acceleration in LLM mathematical reasoning capabilities has rendered static benchmarks inadequate. Traditional benchmarks, typically released as fixed datasets with summary metrics, soon become uninformative as new LLM architectures saturate their test sets. Their narrow scope fails to capture the expanding set of real-world mathematical skills, and their lack of continuous maintenance limits their value for practitioners seeking up-to-date model comparisons. The MathArena platform addresses these shortcomings by establishing a dynamic, transparent, and adaptable framework for evaluating mathematical reasoning in LLMs.
MathArena is positioned as an evaluation platform, distinguished from benchmarks by three main properties: 1) continuously incorporating new task types as models improve, 2) regularly evaluating state-of-the-art models with consistent protocols, and 3) providing an open interface for granular and aggregate performance data, model outputs, and cost metrics.
MathArena's evolution as a platform is evident in its support for longitudinal tracking of model performance, benchmark curation, and in-depth analysis tools for failure cases. As new competitions emerge and LLM capabilities shift, MathArena deprecates uninformative tasks and incorporates novel challenges across the spectrum of mathematical problem solving, from school-level competitions to proofs extracted from contemporary arXiv publications.
The platform maintains a continuous cycle of benchmark design, automated and human-centric evaluation, and interface improvements, illustrated by the timeline of task and feature additions, empirical analyses, and the introduction of research-centric capabilities.
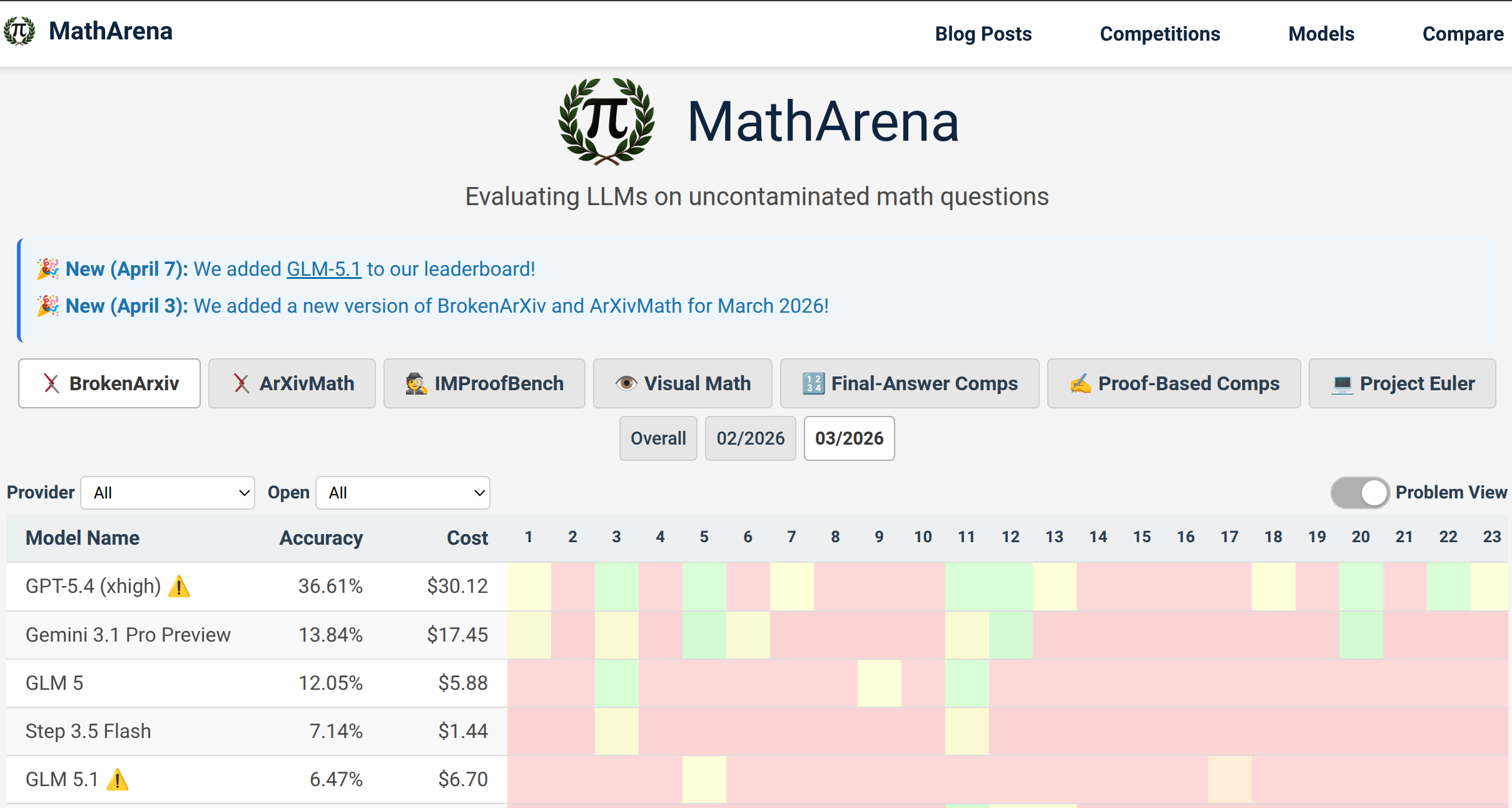
Figure 2: The MathArena homepage surfaces aggregate and per-problem model performance with live leaderboard updates and robust filtering.
Coverage and Benchmark Categories
MathArena covers an expanded range of mathematical tasks, grouped into three major categories:
Evaluation Protocols and Aggregate Metrics
To balance coverage and cost, MathArena does not exhaustively run every model on every benchmark. Instead, it employs an item response theory-based imputation (following (Ho et al., 28 Nov 2025)) that predicts missing model-benchmark entries, enabling consistent overall rankings. Evaluation protocols are standardized—automatic answer parsing for final-answer tasks, multi-judge and rubric-based grading for proofs, and LLM-supported evaluation for reliability and formal proof tasks. Where automation is insufficient, expert human judgment is deployed.
Empirical interval calibration is validated, showing that the adopted protocols for estimating aggregate scores and statistical uncertainty do not introduce significant bias (Figure 5).
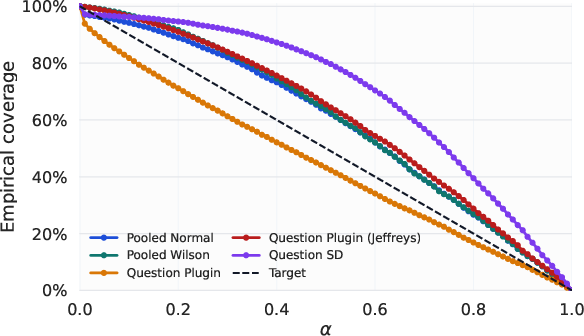
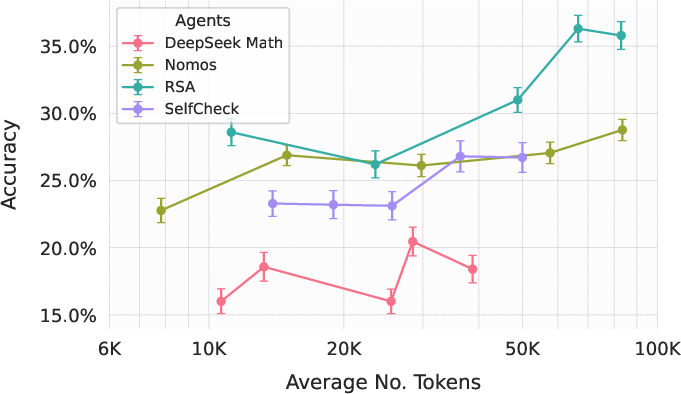
Figure 6: Empirical calibration demonstrates that the MathArena interval estimation method achieves near-ideal coverage.
Results and Observations
Numerical Results and Robust Claims
MathArena reveals strong stratification of model performance. As of the current evaluation, frontier models such as GPT-5.5 achieve 98% on the 2026 USAMO and 74% on research-level final-answer tasks, indicating that competitive LLMs can reliably replicate or surpass elite human performance on the majority of olympiad and undergraduate benchmarks. Notably, however, open models lag by up to 20% on challenging benchmarks, and the closed/open performance differential is accentuated on proof and research tasks.
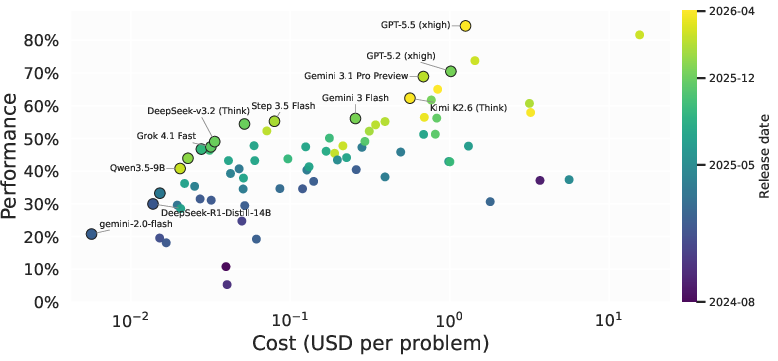
Figure 5: Cost-performance tradeoffs across top models show that the best-performing closed models remain substantially ahead of open competitors.
Model performance is highly stable to benchmark ablations (Figure 6), with very few changes to the top ranks when omitting individual benchmark families.
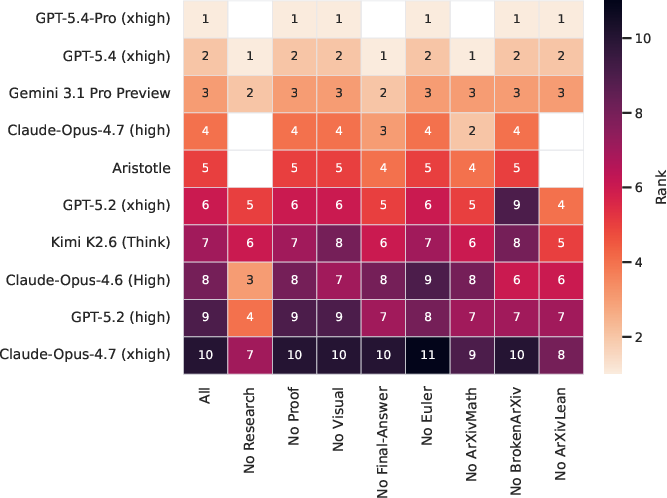
Figure 1: Removing benchmark families has minimal impact on overall model ranking; top model ordering is robust.
Proof quality analysis demonstrates that top models produce not only more correct but also more readable and structurally sound proofs. Grading accuracy for USAMO proofs with multi-model LLM juries aligns closely with human expert judgment, with the strongest grader (GPT-5.4) matching expert scores on all cases and weaker graders (Gemini, Claude) overestimating correctness.
MathArena's research-reliability benchmarks uncover a critical failure mode: all but the top model (GPT-5.5, 72%) consistently "prove" false statements in the BrokenArXiv setting, directly demonstrating that confirmation bias and unreliability are unresolved obstacles for model deployment in research.
Formal Lean proof tasks (ArXivLean) remain essentially unsolved, with top models solving only 17% of problems, reflecting both the depth and the autoformalization challenges at the research frontier.
MathArena's public interface supports a range of analytic workflows. Users can transition from live leaderboard summaries to inspection of individual benchmarks, side-by-side model comparisons, drilldowns into per-problem runs, and isolation of surprising failure traces.
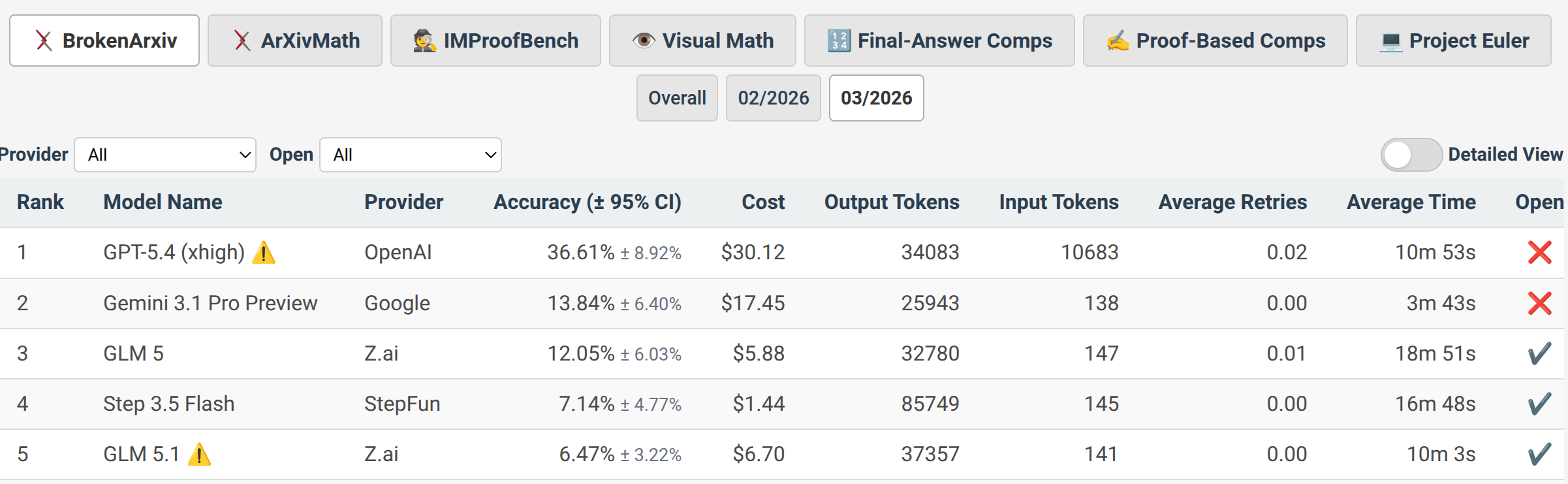
Figure 3: The detailed leaderboard reveals additional metadata crucial for evaluating the practical model impact, including retry counts and openness.
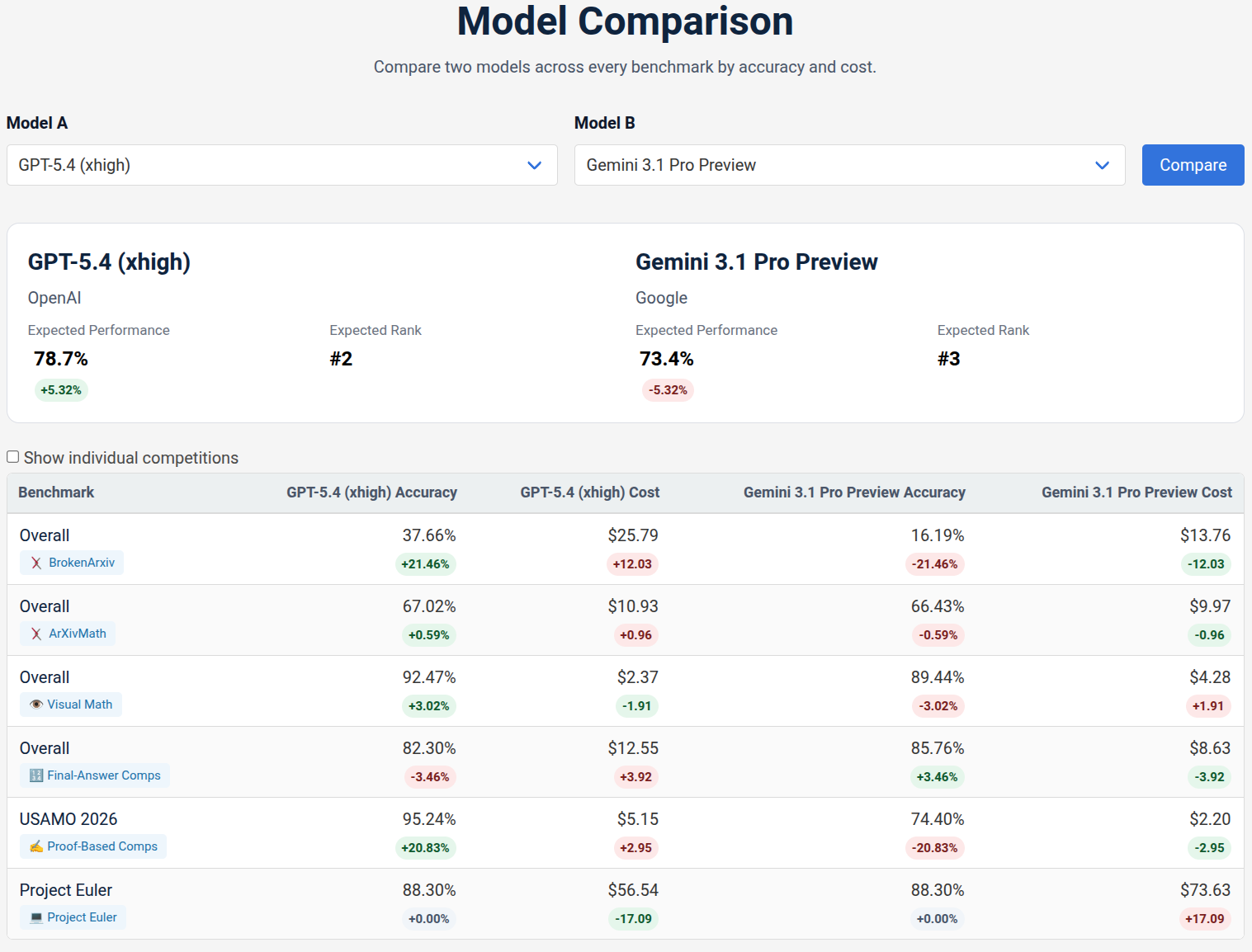
Figure 7: The model comparison interface facilitates nuanced analysis of cost-accuracy tradeoffs between two selected models.
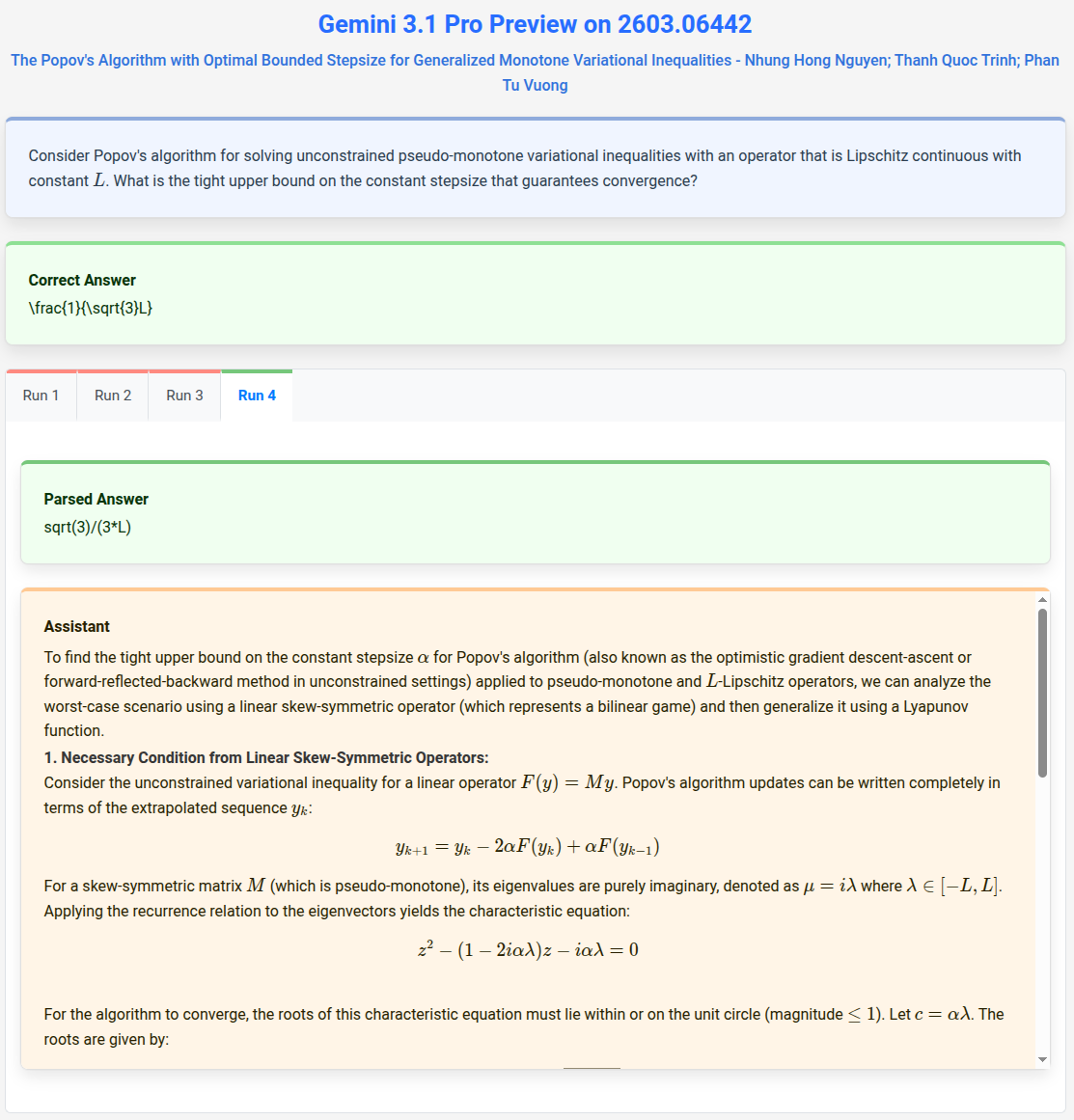
Figure 10: Per-problem trace inspection enables granular identification of reasoning failures and model-specific limit modes.
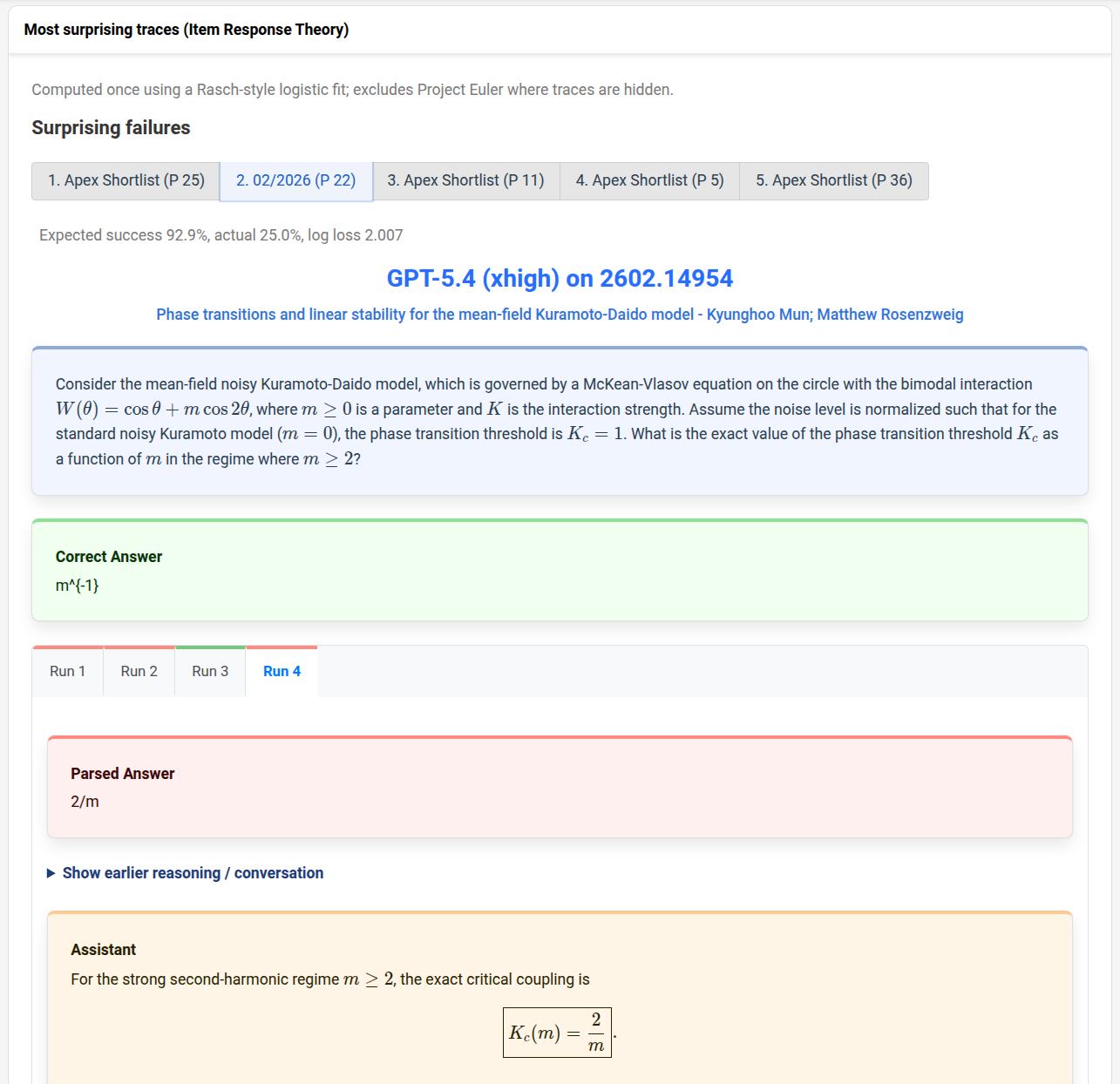
Figure 8: The interface for "surprising traces" highlights highly anomalous model failures warranting further investigation.
Limitations and Future Directions
Despite covering a broad slice of mathematical practice, MathArena's current scope excludes several vital dimensions: interactive workflows, higher-level mathematical creativity such as conjecture formulation, and research tool integration. Synergy with agentic, tool-augmented systems and more sophisticated multi-turn evaluation protocols are identified as key directions for future iterations. The platform also restricts tool access for research benchmarks due to contamination concerns, limiting direct real-world parity.
The reliability benchmarks, while carefully constructed, only stress certain confirmation biases and do not substitute for full correctness verification in mathematics research—a recognized open challenge in the field.
Theoretical and Practical Implications
MathArena demonstrates that continuous, platform-based evaluation architectures are required to keep pace with both the breadth and quality of LLM mathematical reasoning. The explicit exposure of LLM brittleness on reliability tasks, robust demonstration of proof-writing gains, and the persistent gap in formal theorem proving highlight targeted research priorities. As LLMs are further integrated into mathematical practice and research, platforms like MathArena provide the necessary scaffolding for meaningful, reproducible, and transparent assessment.
From a broader perspective, MathArena's paradigm may generalize to other complex cognitive domains, where skill sets and tasks are rapidly evolving and static leaderboards fail to capture real-world progress or reliability risks.
Conclusion
"Beyond Benchmarks: MathArena as an Evaluation Platform for Mathematics with LLMs" (2605.00674) firmly establishes the essential role of open, dynamic platforms in mathematical AI evaluation. By continuously aggregating and analyzing diverse benchmarks with robust protocols and a transparent interface, MathArena enables precise tracking of LLM mathematical progress, supports nuanced error analysis, and reveals unresolved reliability and formalization bottlenecks. Its design and results inform not only the trajectory for future mathematical LLM development but also the broader methodology for AI capability assessment.