- The paper introduces a dynamic benchmark that addresses contamination and synthetic bias by sourcing new theorem statements from post-cutoff arXiv publications.
- It proposes a rigorous seven-stage pipeline that extracts proof sketches and applies logical taxonomy for adversarial, substitution-resistant evaluation.
- Evaluation results show that state-of-the-art LLMs still perform far below human-level reasoning, underlining the need for deeper, deduction-focused models.
LiveMathematicianBench: A Dynamic Benchmark for Research-Level Mathematical Reasoning in LLMs
Motivation and Benchmark Design
LiveMathematicianBench is introduced to address two core deficiencies in existing mathematical reasoning benchmarks for LLMs: the prevalence of synthetic, competition-centric datasets and significant contamination risks due to model pretraining on publicly available standardized problems. These prior benchmarks—such as GSM8K, MATH, OlympiadBench, and RealMath—fail to capture authentic mathematician-level reasoning due to the overrepresentation of calculation-oriented, template-heavy questions, and are increasingly unsuitable for evaluating advanced LLMs whose training data overlap with historical problems.
The benchmark leverages a fully dynamic construction pipeline that exclusively sources theorem statements from post-cutoff arXiv publications within the mathematics category, ensuring that example contamination from pretraining corpora is effectively precluded. The selection protocol is intentionally anchored in research-level, non-routine mathematical questions drawn from current literature, shifting focus from exam-style solution retrieval to hypothesis analysis, logical taxonomy, and genuine abstraction.
The construction protocol consists of seven elaborate stages: from automated arXiv paper retrieval and LaTeX source extraction, through hybrid agentic theorem extraction and context normalization, to logic-driven taxonomy assignment, proof-sketch summarization, adversarial MCQ generation, stem-only triviality filtering, and hardness calibration using frontier models. This multi-stage process is demonstrated in (Figure 1).
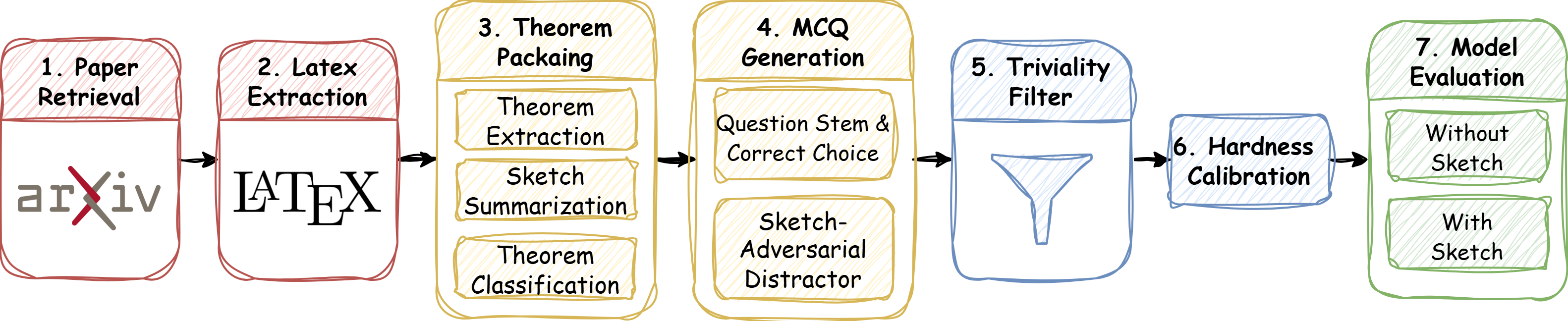
Figure 1: The pipeline for LiveMathematicianBench includes 7 rigorous construction stages, from arXiv retrieval through MCQ filtering and calibration.
Proof sketches—concise, high-level outlines of theorem proof strategies—are systematically extracted and employed in two pivotal roles: as inputs for crafting semantically adversarial distractors and as auxiliary information in dual-mode evaluation settings. Distractor generation is adversarial, leveraging proof constraints to craft plausible but invalid options, thereby inhibiting shortcut strategies such as option substitution and surface matching. A substitution-resistant evaluation mode is further instituted, mandating that models enact authentic deductive reasoning in selecting solutions.
Logical Taxonomy and Benchmark Structure
A fundamental innovation in LiveMathematicianBench is the taxonomy-driven evaluation rooted in a fine-grained categorization of theorem statements by logical form—spanning implication, equivalence, existence, uniqueness, classification/bijection, bound/inequality, and more. This enables systematic diagnosis of logical failure modes across LLMs, revealing structure-specific strengths and weaknesses otherwise invisible in aggregate accuracy metrics.
Analysis of the benchmark's hard split demonstrates comprehensive coverage across all major logical categories, with implication and universal forms most prevalent, and a nontrivial temporal variation in category prevalence (Figure 2).
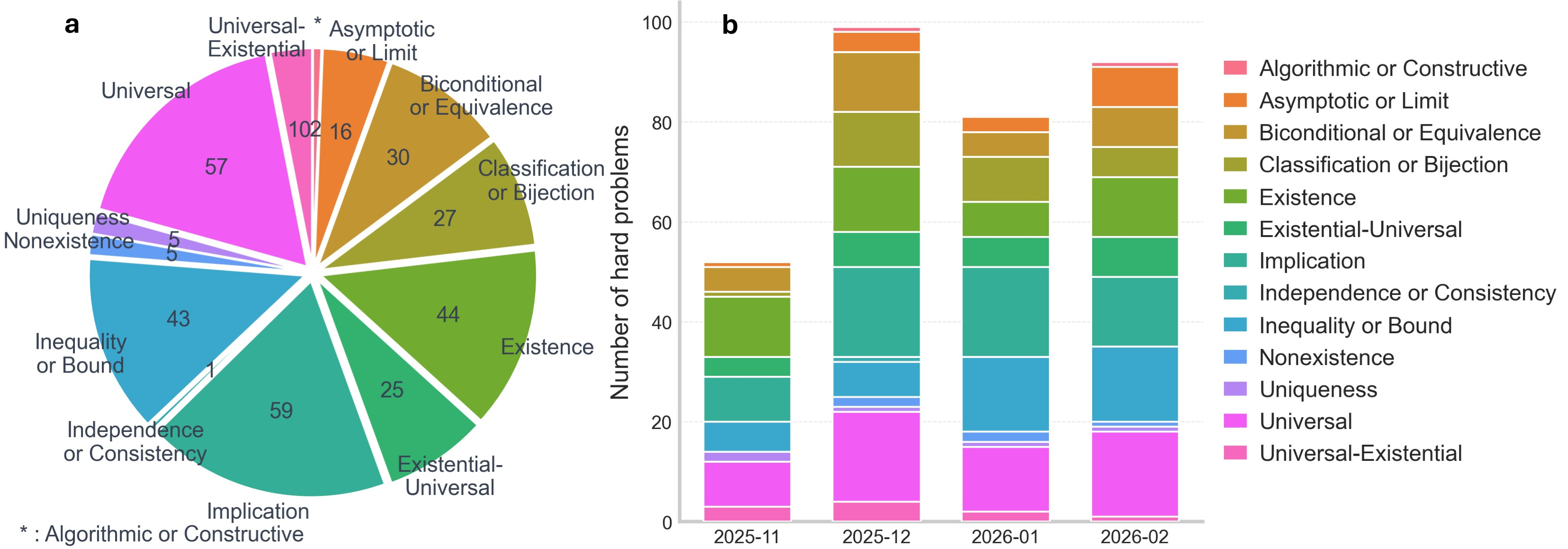
Figure 2: Distribution of logical categories in LiveMathematicianBench, with detailed monthly breakdown tracking the dynamic, contamination-resistant benchmark composition.
Multiple-category membership is common, reflecting the multiplicity of logical dependencies in authentic research mathematics. Such composition ensures that evaluation transcends rote pattern recognition and probes the underlying reasoning capacities of LLMs.
Evaluation Protocol and Results
Frontier LLMs—including Gemini-3.1-pro-preview and GPT-5.4—were evaluated under both standard and sketch-aware protocols, with and without adversarial choice formatting. The performance of all current state-of-the-art models remains substantially below the saturation threshold, with the best model attaining only 43.5% accuracy—more than double the random-guess baseline, yet far from human-level reliability (Figure 3).
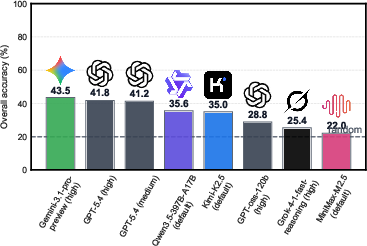
Figure 3: Overall accuracy on LiveMathematicianBench reveals fundamental limitations in advanced LLMs; even the best models are far from near-perfect performance.
Category-specific analysis (Figure 4a) shows marked heterogeneity in model reasoning depending on logical form; for instance, Gemini-3.1-pro-preview dominates biconditional and classification problems, whereas GPT-5.4 excels at implication, universal, and bound-style questions.
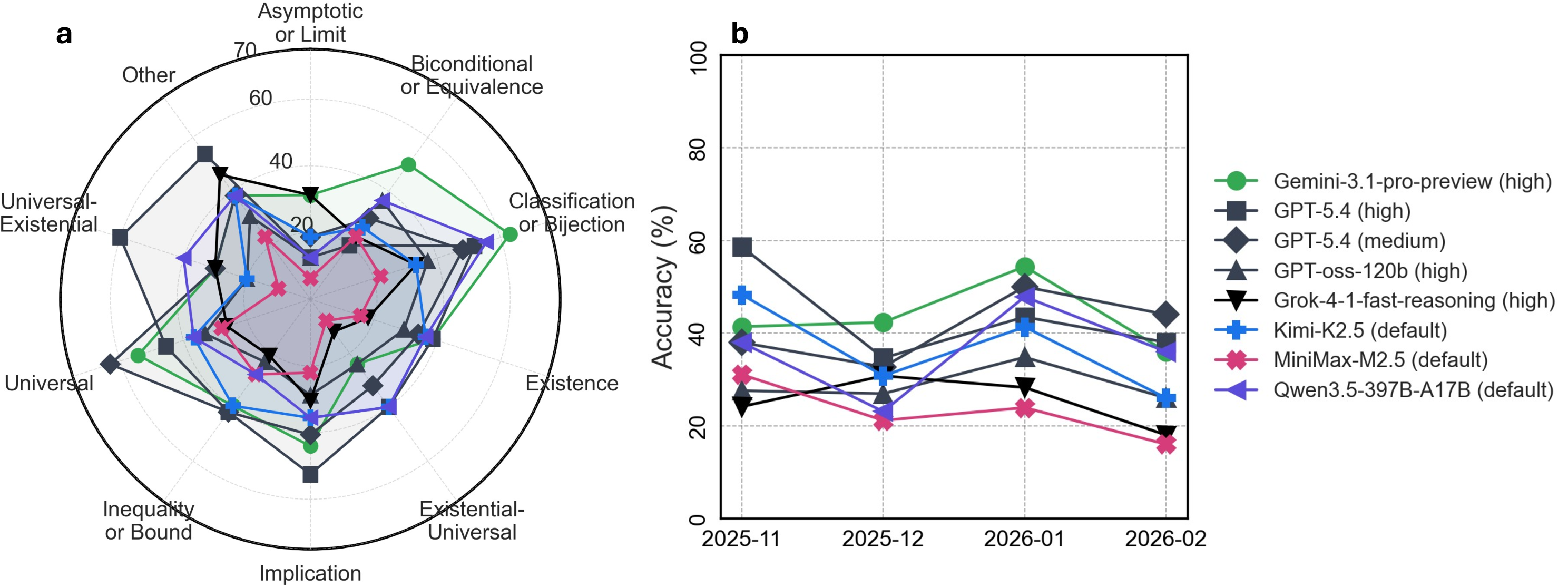
Figure 4: (a) Logical category breakdown of model accuracy reveals distinct weaknesses across different reasoning types. (b) Temporal analysis shows no clear progression toward saturation.
Temporal trajectories (Figure 4b) indicate volatility in model performance across monthly benchmark slices, emphasizing research-level mathematical reasoning as multi-dimensional and unstable even for the strongest models.
Crucially, when substitution-resistant options are introduced, overall accuracy drops precipitously for all models (Figure 5a). For example, Gemini-3.1-pro-preview falls to 17.6% (below random), while GPT-5.4 maintains a modest lead at 30.6%. This dramatic performance degradation signals overdependence on substitution and elimination heuristics; only a subset of models retain fidelity to genuine logical reasoning when stripped of shortcut avenues.
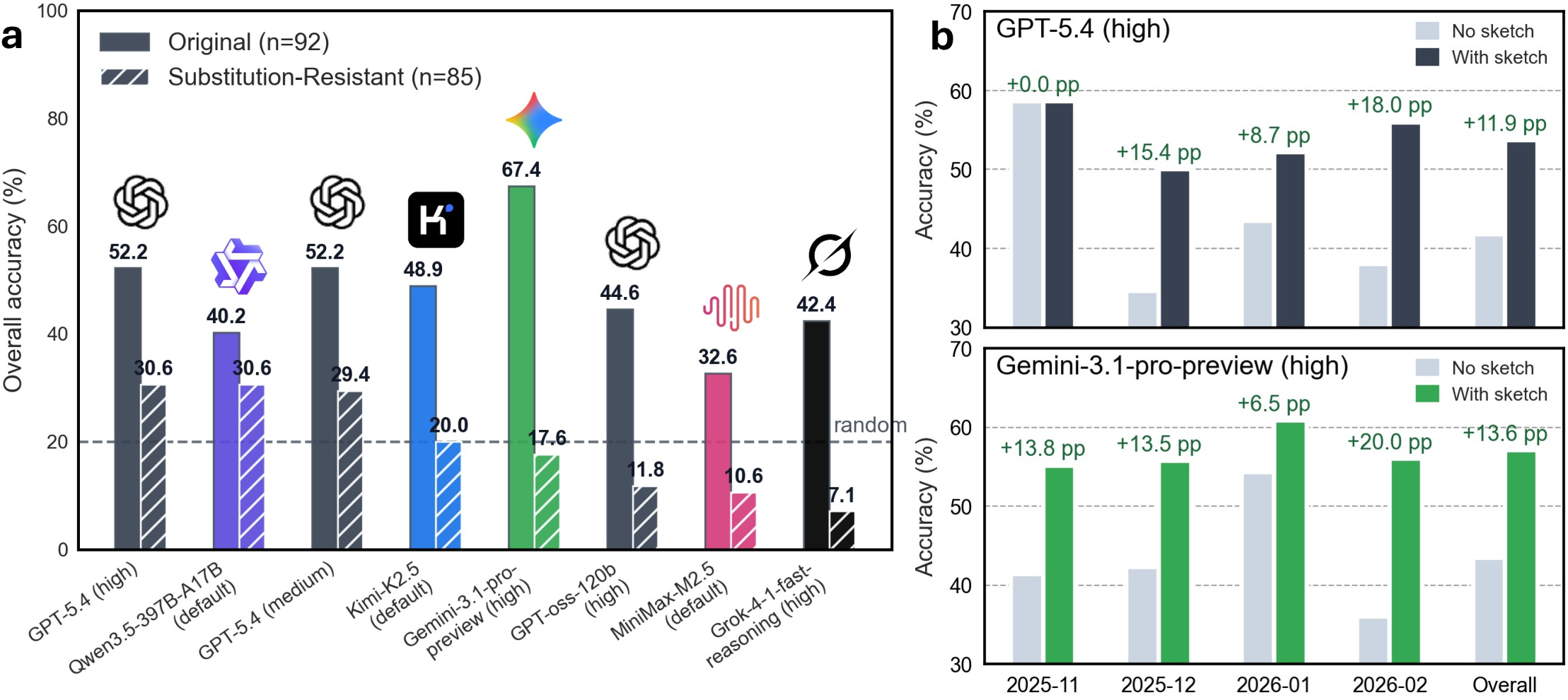
Figure 5: (a) Substitution-resistant choices substantially degrade LLM performance, isolating reliance on authentic deduction. (b) Proof sketches induce robust gains, particularly for advanced models.
Proof-sketch intervention yields consistent, significant improvements in model performance across all protocols (Figure 5b), with Gemini-3.1-pro-preview advancing by 13.6 percentage points. This supports the central claim that high-level strategic mathematical information—short of full proof detail—materially augments model reasoning and selection, especially in adversarial contexts.
Decomposition of sketch-aware gains by choice style (Figure 6) demonstrates that such intervention is especially beneficial for hard, substitution-resistant questions and may help bridge the gap between surface heuristics and substantive deductive skills.
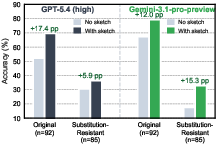
Figure 6: Proof-sketch guidance yields pronounced accuracy gains on the hardest (substitution-resistant) problems, particularly for Gemini-3.1-pro-preview.
Furthermore, the cost-efficiency frontier (Figure 7) analysis shows that GPT-5.4 models can reach near-top accuracy at a substantially reduced token cost, contesting the narrative that token allocation directly correlates with mathematical reasoning prowess.
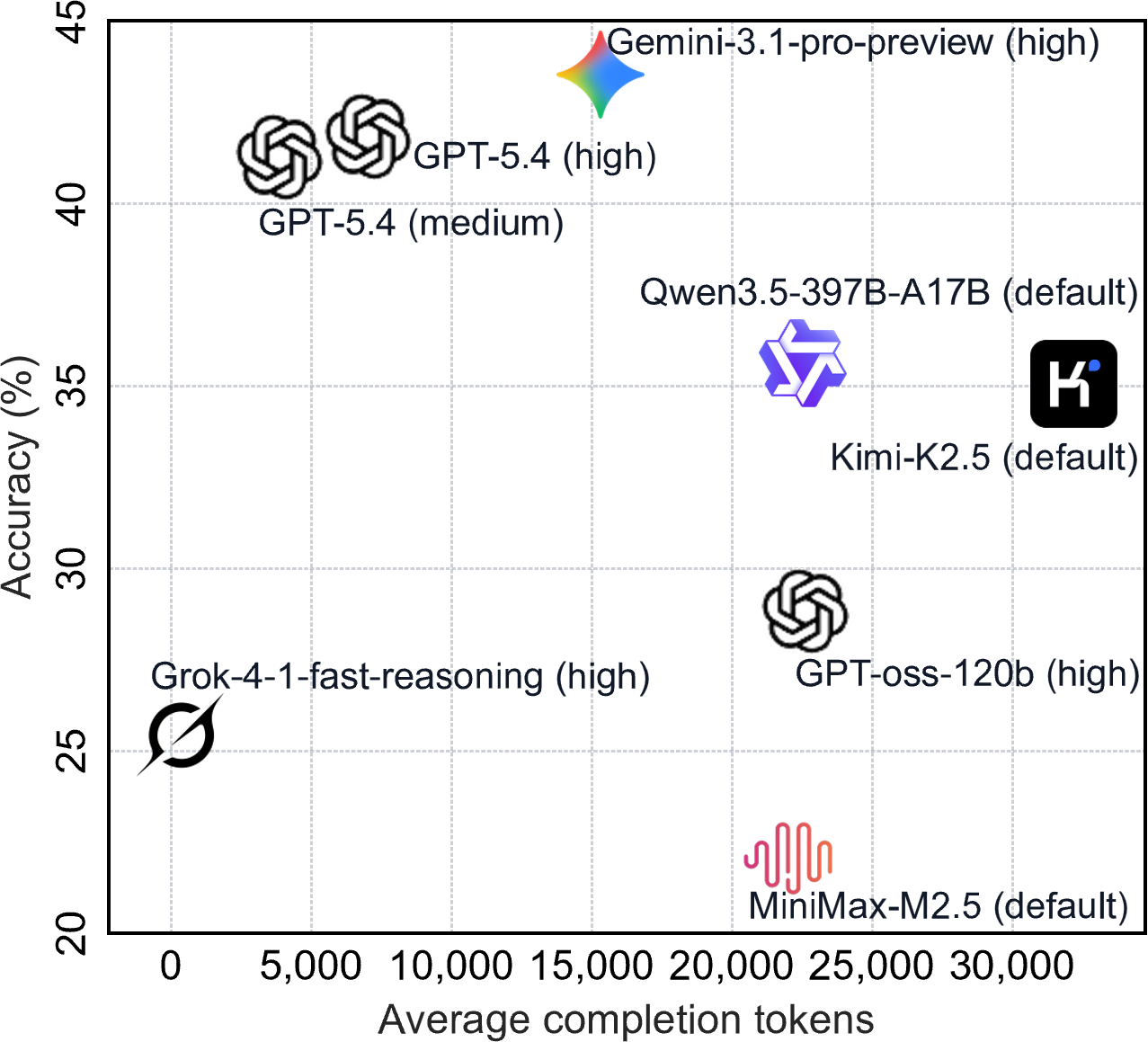
Figure 7: Accuracy-cost tradeoff reveals that high reasoning capability does not require maximal generation length; GPT-5.4 achieves competitive accuracy with parsimonious outputs.
Practical and Theoretical Implications
The presented framework establishes several formal and practical precedents:
- Contamination-resistant evaluation: By construction, the benchmark is immune to training leakage, enabling ongoing, dynamic assessment as LLMs evolve.
- Structural diagnosis: Logical categorization and proof-guided adversarial distractors isolate reasoning typologies, clarifying the multifaceted limitations in current model architectures.
- Proof strategy utilization: Demonstrated consistent gains from proof sketches indicate that LLMs are capable of synthesizing high-level mathematical heuristic guidance—a closer proxy to human research practice.
- Cost-efficient reasoning: Parameter scaling and architecture choices, rather than sheer inference length, dominate the accuracy/cost efficiency frontier among advanced LLMs.
Collectively, these findings underscore that while LLMs have made robust advances, research-level mathematical reasoning—especially deduction under adversarial or logically nontrivial contexts—remains an unsolved challenge. Model performance premised primarily on substitution and elimination is acutely vulnerable to robust adversarial design.
Future Directions
LiveMathematicianBench offers a scalable, contamination-resistant substrate for both static benchmarking and interactive mathematical research workflows. The logical taxonomy formalism provides a platform for probing targeted reasoning abilities, facilitating the development of structure-aware curriculum learning, tuning regimens, and hybrid proof-reasoning architectures. The evidence that proof-sketches materially benefit performance points toward hybrid protocols blending formal statement comprehension and dynamic strategic guidance.
The separation between cost and performance also foregrounds the value of explicitly reasoning-aware architectures and strategic context integration, as opposed to naively scaling model and token budgets. Closing the identified deficit in research-level reasoning will require architectures that more closely approximate the abstraction, context-awareness, and strategy deployment that typify mathematician-level cognition.
Conclusion
LiveMathematicianBench is a dynamic framework for evaluating mathematician-level reasoning in LLMs, systematically solving the critical problems of contamination, logical triviality, and surface matching that undermine traditional benchmarks. By leveraging logical taxonomy, adversarial proof-sketch-guided distractor generation, and resistance to substitution shortcuts, the benchmark offers a rigorous, multi-faceted examination of advanced LLMs. Empirical results highlight both the progress and profound limits of current systems, underscoring the need for genuine architectural innovation before LLMs can reliably support or automate mathematical research at scale.

