- The paper introduces SC-Taxo, a framework that merges LLM-extracted concepts with structural clustering to maintain vertical and horizontal semantic consistency.
- It employs a dual-path initialization and four-round mutual validation process to eliminate hallucinated nodes and enforce robust parent-child and sibling alignments.
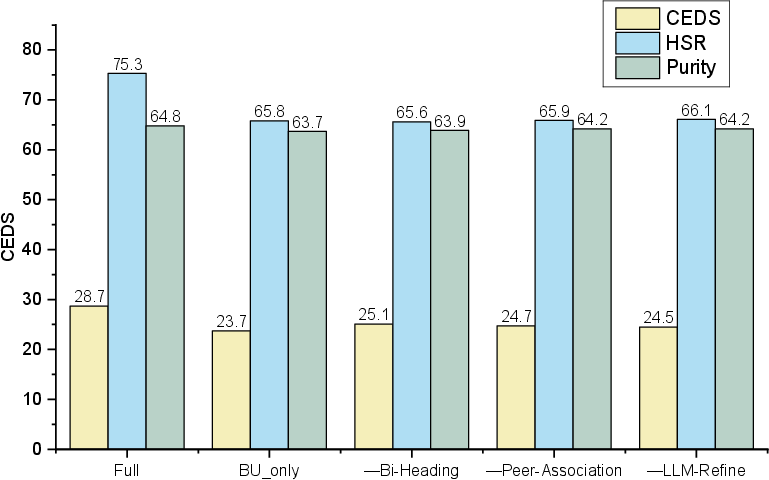
- Empirical validation on TaxoBench shows SC-Taxo achieves superior clustering metrics (Purity 64.8) and hierarchical consistency (CEDS 28.7) compared to traditional methods.
Semantic-Consistent Hierarchical Taxonomy Generation with SC-Taxo
The exponential growth in scientific literature necessitates robust knowledge organization frameworks that support seamless exploration, summarization, and retrieval. Hierarchical taxonomies, which impose explicit parent–child conceptual relations, are foundational to knowledge engineering and annotation tasks. However, most traditional taxonomy induction methods rely either on shallow surface patterns or unsupervised clustering, both of which struggle with context drift and granularity misalignment. Recent LLM-based approaches, while adept at generating node labels, frequently introduce structural hallucinations and lose global context, undermining semantic coherence across hierarchical levels. This paper introduces SC-Taxo, an LLM-integrated taxonomy generation framework explicitly designed to enforce semantic consistency both vertically (across levels) and horizontally (among siblings).

Figure 1: Schematic of the scientific taxonomy generation task—mapping an unstructured paper corpus into a hierarchy of semantic concepts with variable abstraction.
Architectures and Methodological Innovations
SC-Taxo is distinguished by its dual-path initialization and a multi-stage deep fusion process. The pipeline begins with parallel structural (UMAP+BFS clustering) and semantic (LLM-extracted concepts) induction paths, each capturing distinct aspects of the literature corpus. The hierarchical clustering endpoint offers a stable topological backbone, while LLM-driven concept extraction yields rich semantic candidate nodes that may, absent controls, be structurally unstable.
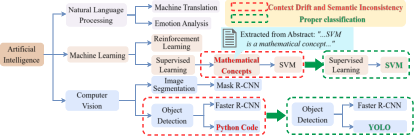
Figure 2: Contrast between errors in traditional approaches (context drift, granularity misalignment) and SC-Taxo’s semantic coherence via cross-level and peer-level constraints.
The two paths are integrated by a four-round mutual validation (Deep Fusion):
- Concept-to-Cluster Validation: Filters out hallucinated or non-grounded nodes by checking if LLM-generated concepts are actually reflected in cluster distributions.
- Cluster-to-Concept Labeling: Assigns validated, highly representative semantic headings to structural clusters based on paper-level concept distribution.
- Bidirectional Parent-Child Alignment: Enforces semantic cohesion by generating child node labels conditioned on both parent context and paper contents, leveraging LLM attention to global and local constraints.
- Sibling Expansion: Ensures granularity and removes redundancy by LLM-guided sibling-aware heading generation, carefully expanding under-abstracted or conceptually overlapped nodes.
A final quality control module performs LLM-driven concept scoring, redundancy detection, and structure validation.
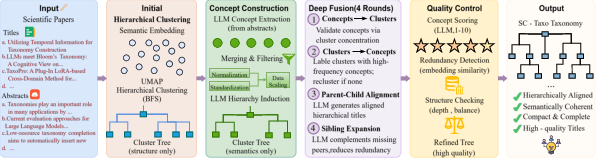
Figure 3: Architecture of the SC-Taxo pipeline, showing dual-path initialization, four-round fusion, and rigorous output checking.
Empirical Validation and Quantitative Analysis
Evaluations on the TaxoBench benchmark and a curated Chinese RL-LLM corpus highlight the empirical strengths of SC-Taxo. Metrics focus on both clustering (NMI, Purity) and hierarchical consistency (Catalogue Edit Distance Similarity—CEDS, Hierarchical Structure Retention—HSR).
Notable findings include:
- SC-Taxo achieves higher Purity (64.8) versus all baselines on English TaxoBench, reflecting superior semantic cohesion at node assignments.
- It establishes a new state-of-the-art in CEDS (28.7), indicating substantially better global structure alignment with manual taxonomies.
- Notably, gains in CEDS and HSR are often accompanied by modestly lower NMI, consistent with a trade-off that prioritizes meaningful abstraction and interpretability over raw flat clustering agreement.
Ablation studies dissect the utility of individual modules:
Qualitative Insights
Case studies further expose the limitations of baseline methods in handling granular research topics (e.g., "Model Compression"). Traditional or LLM-only approaches generate imbalanced, over-fragmented trees and misclassifications. In contrast, SC-Taxo's taxonomy is compact, with well-differentiated categories, collapsed redundant levels, and correct paper assignments—even identifying missing higher-level concepts overlooked by previous systems.
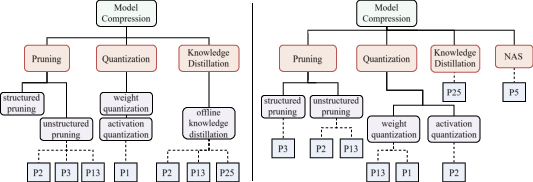
Figure 5: Comparison of generated taxonomies for “Model Compression”—SC-Taxo (right) collapses redundant nodes and corrects granular assignments for coherent structure.
Cross-Lingual Generalization and Limitations
SC-Taxo demonstrates cross-lingual robustness, maintaining high Purity and CEDS on challenging Chinese datasets characterized by terminological ambiguity and weak standardization. The decoupling of semantic induction and structural clustering ensures resilience against language-specific pitfalls, as semantic drift and synonym collision are addressed with embedding-backed grounding and explicit redundancy checking.
However, the framework introduces additional computational overhead due to multi-stage LLM calls and semantic validation. Efficient approximation strategies or dynamic, resource-aware refinement stages are promising directions for optimization.
Theoretical and Practical Implications
The key theoretical contribution is a demonstration that rigid, explicit semantic consistency constraints—both vertical and horizontal—are essential for interpretable, coherent taxonomy generation, especially under the noisy, context-variable conditions prevalent in scientific corpora. LLMs should not be used as uninformed generators; rather, their ability to synthesize abstracted concepts is best leveraged when tightly integrated with data-driven structural anchors and bidirectional alignment protocols. Practically, SC-Taxo enables reliable automation of literature knowledge organization, paving the way for applications ranging from scientific search to meta-analysis pipelines. Its cross-lingual generalization foregrounds its suitability for multi-domain, multi-language information management.
Conclusion
SC-Taxo establishes a new methodological baseline for semantic-consistent hierarchical taxonomy generation. Its dual-path and multi-stage fusion approach addresses semantic drift, granularity misalignment, and structuring errors endemic to both classical and generative-only techniques. Significant numerical gains in Purity and CEDS, as well as qualitative advances in taxonomy compactness and interpretability, validate the efficacy of explicit semantic constraint modeling. Ongoing research should address computational trade-offs and extend the framework toward dynamic graphs and efficiency-aware refinement for broad applicability in AI-enabled knowledge engineering.