- The paper introduces MAPLE, a novel framework integrating ViT-based visual embeddings, graph refinement, and adaptive gating for hierarchical multi-label image classification.
- It employs semantic initialization with natural language prompts and graph propagation to effectively leverage taxonomic relationships in structured datasets.
- Experimental results show significant performance gains, especially in few-shot scenarios, with up to 42% AU-PRC improvement in challenging benchmarks.
Multi-Path Adaptive Propagation with Level-Aware Embeddings for Hierarchical Multi-Label Image Classification
Introduction and Motivation
Hierarchical multi-label classification (HMLC) plays a central role in domains with structured taxonomies, such as remote sensing, medical imaging, and fine-grained visual categorization. Flat multi-label methods disregard valuable taxonomic relationships, hindering generalization, semantic coherence, and interpretability, especially in multi-path scenarios where samples may activate several branches of a label hierarchy concurrently. The MAPLE framework addresses critical limitations of existing HMLC models: inability to robustly handle multi-path labelings, inefficiency of network-based designs, insufficient modeling of long-range dependencies in purely loss-driven approaches, and strong reliance on supervised training despite prevalent annotation scarcity.
MAPLE Architecture
MAPLE introduces a hybrid modeling paradigm, integrating hierarchical semantic initialization, Vision Transformer (ViT) based visual embedding, graph-based label refinement, adaptive multimodal fusion, and a level-aware unified classification objective.
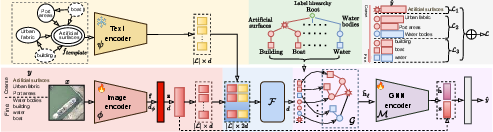
Figure 1: The MAPLE architecture leverages ViT-based image encoding augmented with hierarchy-specific class tokens, graph-based semantic propagation, and adaptive gating to align visual and semantic cues for multi-level classification.
Hierarchical Semantic Initialization
Label node embeddings are instantiated from contextual natural language prompts. Each prompt encodes node identity, parental lineage, and child membership, and is embedded using a pre-trained sentence transformer (all-mpnet-base-v2), linearly projected to the latent space, and L2-normalized. This produces semantically structured initial node features, reflecting taxonomic relations at the onset of training.
Contrasting the standard single-cls-token ViT, MAPLE introduces a dedicated learnable token for each node in the label graph. These tokens attend over the spatial image representation, supporting specialization to semantics at all levels of the taxonomy. The resulting representations provide high-level visual context mapped to the hierarchical label set.
Graph-Based Hierarchical Refinement
MAPLE explicitly conditions learning on the label taxonomy via a two-layer GraphSAGE module. ViT-generated node embeddings undergo graph-constrained message passing, aggregating parent and child features, encoded via residual connections and non-linearities, to achieve robust, hierarchy-aware refinement. This architecture encodes both upward (evidence aggregation) and downward (context propagation) flows in the taxonomy.
Adaptive Multimodal Fusion
To resolve when to trust visual cues versus semantic priors, MAPLE adopts an adaptive gating strategy at node-level granularity. Learnable fusion weights dynamically interpolate between the (refined) graph-based semantic embedding and the visual token, optimizing for semantic coherence and visual discriminability per node.
Unified Prediction Head and Adaptive Loss
MAPLE employs a single linear predictor spanning all hierarchy nodes. During training, an adaptive objective leverages either categorical cross-entropy or (multi-)binary cross-entropy, automatically selected per hierarchy level according to label cardinality. This enables end-to-end, simultaneous supervision at all semantic resolutions, avoiding manual loss balancing or task weighting.
Experimental Validation
Datasets and Hierarchy Construction
Nine datasets, spanning remote sensing, medical imaging, and fine-grained visual categorization, were recast as HMLC tasks via systematic mapping to authoritative taxonomies (CORINE, ICD-10) or existing domain structures, with ambiguous cases resolved through LLM-aided mapping and subsequent human validation. The resulting tasks exhibit a broad range of hierarchy widths, depths, and path multiplicities.

Figure 2: Visual overview of all nine datasets used for evaluation, with hierarchical graph structures illustrating taxonomic label organization from coarse to fine granularity.
MAPLE consistently outperforms flat MLC baselines in mean area under the precision-recall curve (AUPRC) at all taxonomic levels. Reported gains range from 0.56% (MLRSNet) to 3.61% (AID) at the leaf level in EO data, and are more pronounced in data-limited (few-shot) settings—up to 42% AUPRC improvement (AID, 16-shot). SOTA comparisons highlight clear margins over established HMLC architectures across EO datasets and robust superiorities in medical and fine-grained benchmarks (e.g., PadChest +21.9%, ETHEC +10.4%).
Few-Shot Learning Efficacy
MAPLE demonstrates marked label efficiency across all domains; hierarchical propagation regularizes limited supervision, closing the performance gap between low-shot and full-data scenarios.
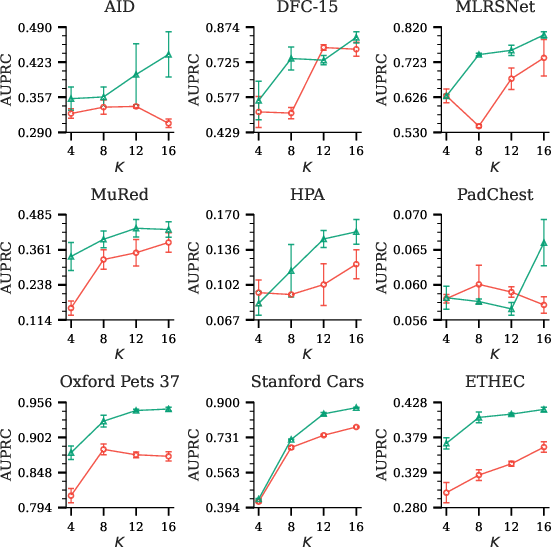
Figure 3: Few-shot performance curves show that MAPLE outperforms flat MLC across all shot regimes, especially in extreme label-scarce settings.
Representation Analysis
Embedding Evolution
Progressive application of semantic initialization, GNN refinement, and visual-semantic fusion leads to well-separated, semantically meaningful clusters in the final node embedding space, as visualized by UMAP. Semantic structure emerges sharply post-initialization, is accentuated via GNN propagation, and achieves optimal class separation after multimodal fusion.





Figure 4: UMAP visualizations track node embedding evolution, revealing emergence of hierarchical structure through training stages.
Error and Confusion Reduction
Leaf-level confusion matrices reveal substantial reductions in semantically challenging misclassifications (e.g., trees→water, buildings→bare-soil in AID). MAPLE reduces total confusion counts by up to 70.7% (Oxford Pets), underscoring improvements in semantic consistency and discriminability attributable to constrained hierarchical modeling.
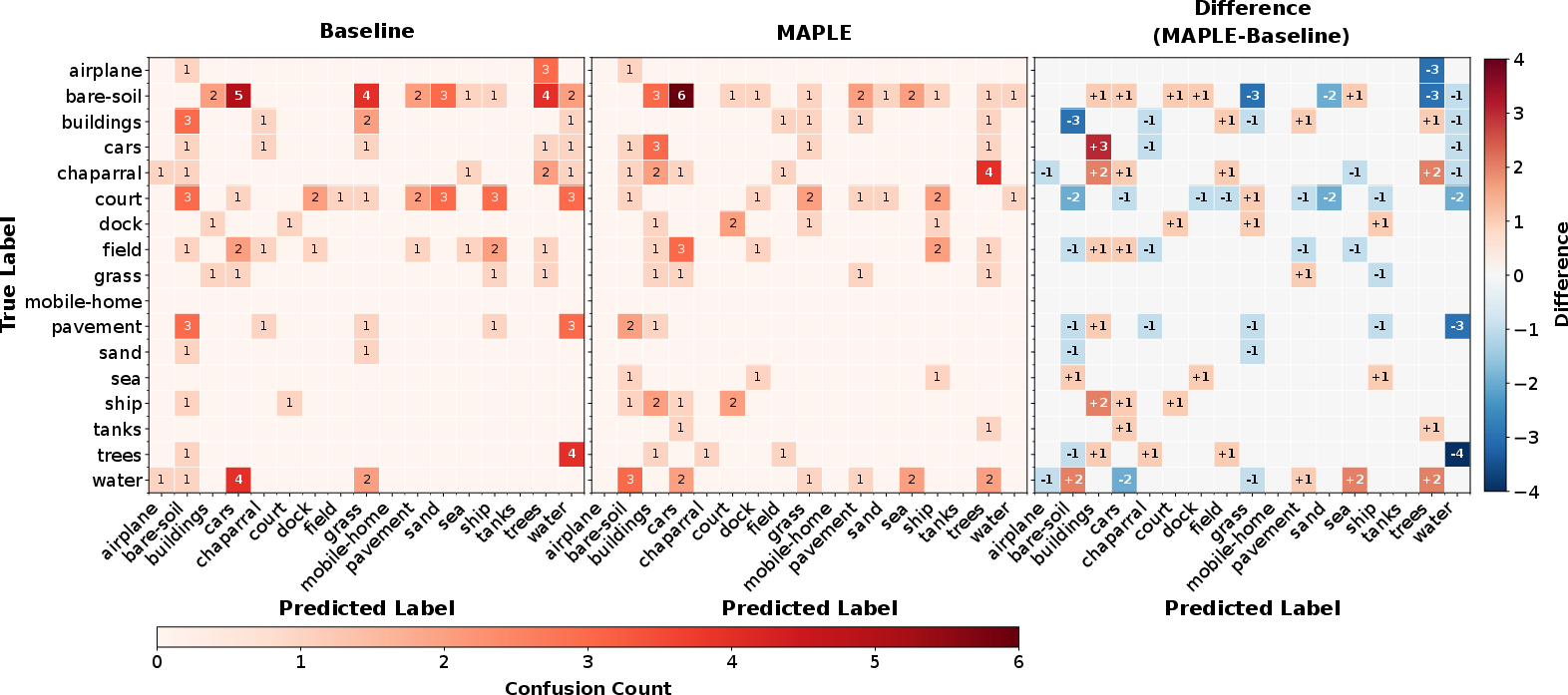
Figure 5: Leaf-level confusion matrix difference (MAPLE vs. baseline) highlights significant reductions in misclassification among similar category pairs in remote sensing data.
Ablation and Component Analysis
- Graph Architecture: MAPLE’s core benefit—hierarchical message propagation—is largely architecture-agnostic; GCN, GAT, and GraphSAGE offer near-equivalent performance.
- Semantic Initialization: Random embedding initialization is competitive with or superior to LLM-derived, Word2Vec, and GloVe embeddings in EO and medical tasks, suggesting that strong vision backbones and graph refinement compensate for lack of semantic priors. Only in certain fine-grained domains (Oxford Pets) are minor gains observed with semantic embeddings.
- Efficiency: MAPLE imposes trivial compute/parameter overhead (2.6%) and minimal latency increase (≤5.3%), making it suitable for scalable deployment under annotation constraints.
Practical and Theoretical Implications
MAPLE’s explicit hierarchical modeling results in:
- Enhanced semantic coherence and interpretability, with predictions constrained to valid taxonomic paths
- Regularization and inductive bias that are invaluable under annotation sparsity
- Improved robustness to spurious correlations and label noise, particularly critical in EO and medical contexts
Practically, this enables broader application of ML in operational remote sensing and clinical workflows, where curated expert taxonomies exist but data scarcity is the norm. The architecture provides a unified foundation for further hybridization with semi-supervised and unsupervised methods, and the label gating/fusion paradigm can generalize to other multimodal and taxonomically structured prediction tasks.
Limitations and Future Directions
MAPLE’s efficacy relies on the fidelity of the input hierarchy; noise or bias in pseudo-taxonomies, especially from LLM sources, may degrade performance. Gains on extremely large or weakly structured datasets are attenuated. Addressing hierarchy discovery, semi/self-supervised learning, and deeper integration of external knowledge embeddings remain fertile areas for future research.
Conclusion
MAPLE establishes a scalable, computationally efficient, and semantically aligned solution for hierarchical multi-label image classification. By operationalizing taxonomic structure via multimodal propagation and adaptive fusion, MAPLE advances predictive performance, label efficiency, and model interpretability across EO, medical, and fine-grained domains. The architecture sets a new empirical baseline for HMLC and offers multiple adaptable components for incorporation into future structured output modeling frameworks.