- The paper presents a novel methodology that combines in-context learning and prompt chaining for automated hierarchical categorization of scientific texts.
- By deconstructing classification tasks into domain, subject, and topic levels, the approach significantly improves accuracy, especially at the domain level (up to 90.1%).
- Evaluation against baselines showed that LLMs outperform traditional models like BERT and BiLSTM, though challenges remain in achieving high accuracy at the topic level (~50%).
Automated Hierarchical Categorization of Scientific Texts Using LLMs and Prompt-Chaining
Introduction
The paper "Automating Categorization of Scientific Texts with In-Context Learning and Prompt-Chaining in LLMs" (2604.23430) addresses the pressing challenge of managing the exponential growth in scholarly literature. The authors systematically evaluate the efficacy of LLMs for the automatic classification of scientific texts against the hierarchical Open Research Knowledge Graph (ORKG) taxonomy. The study leverages advanced prompt engineering strategies—namely, In-Context Learning (ICL) and Prompt Chaining—while also exploring the impact of the temperature hyperparameter on model performance. Several contemporary open-source LLMs (Gemma, Llama, Mistral-Nemo, and Phi) are rigorously tested using the FORC dataset, comprising nearly 25,000 annotated scientific publications.
Background and Problem Context
Manual classification of research publications remains a critical bottleneck due to the requirement of extensive domain expertise and the complexity inherent in hierarchical taxonomies. Traditional approaches primarily rely on supervised learning (e.g., BERT, BiLSTM), which demand large volumes of labeled data and significant training periods. With the advent of LLMs trained on massive, diverse datasets, the possibility arises for zero-shot or few-shot classification without bespoke fine-tuning.
Taxonomies such as ORKG provide hierarchical frameworks—spanning domains, subjects, and topics—for organizing scientific content. However, challenges include multi-label ambiguity, insufficient coverage in some domains, and the lack of cross-domain representation. The FORC dataset used in this study is annotated at multiple hierarchy levels according to the ORKG taxonomy.
Methodological Pipeline
The authors design a structured five-step methodology:
- Data Collection: Extraction from the FORC shared task dataset, which encompasses 50,441 scientific texts categorized with 123 Fields of Research based on the ORKG taxonomy.
- Data Preprocessing: Removal of extraneous information (URLs, special characters, author names) resulting in 24,911 usable records spanning four domains, 14 subjects, and 40 topics.
- Prompt Engineering: Comparison between In-Context Learning (zero-shot, one-shot, few-shot) and Prompt Chaining. Detailed prompt specifications guide LLM responses tailored to each taxonomy level.
- Classification: Hierarchical categorization—predicting domain, then subject, then topic—via stepwise prompts, in contrast to direct classification.
- Evaluation and Analysis: Assessment via exact match, string distance, and embedding distance metrics to capture both strict and semantically proximate predictions.
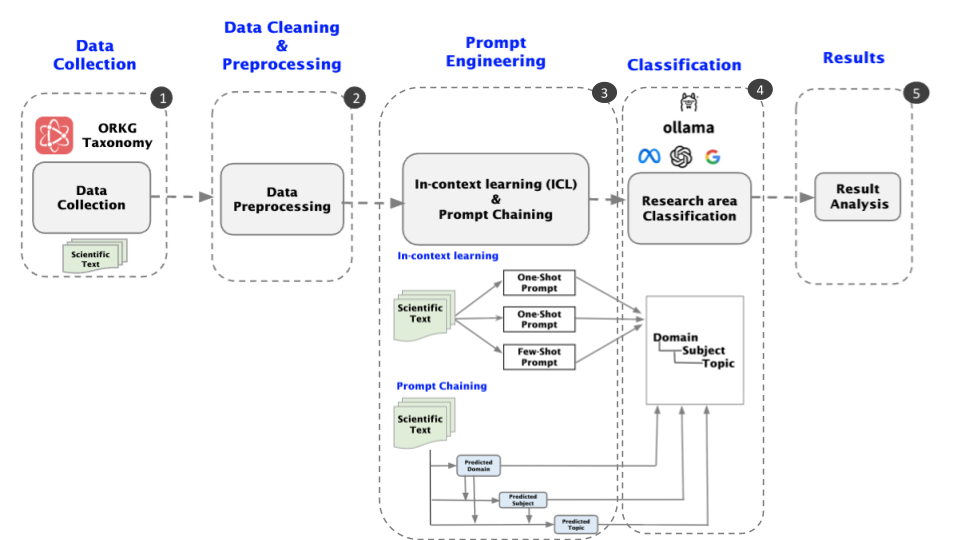
Figure 1: Hierarchical methodology for multi-level research area identification integrating In-Context Learning and Prompt Chaining.
Prompt Engineering Strategies
In-Context Learning
ICL employs zero-shot (just task description), one-shot (single example), and few-shot (multiple examples) prompts to guide the LLMs. As the number of provided examples increases, classification accuracy improves, particularly for broad domain prediction. However, ICL struggles to consistently leverage hierarchical structures for more granular (topic-level) classification.
Prompt Chaining
Prompt Chaining decomposes the task into sequential steps: first identifying domain, then subject (conditioned on domain), and finally topic (conditioned on subject). At each step, the set of possible labels is restricted, which increases accuracy and reduces ambiguity. This strategy aligns closely with the hierarchical nature of taxonomies such as ORKG and enables LLMs to reason more effectively across multi-level classification tasks.
Experimental Design
The study utilizes four LLMs (Gemma 2, Llama 3.1, Mistral Nemo, Phi 3.5) executed on local hardware via Ollama. Each model is tested across varying temperature hyperparameters (T), which modulate response stochasticity. Performance is benchmarked against classical models (BERT, BiLSTM), providing a robust comparative baseline.
Evaluation metrics highlight the importance of capturing not just exact label matches, but also semantically similar predictions via normalized Levenshtein distance and cosine similarity of language embeddings.
Results
- Temperature Analysis: Optimal classification accuracy for LLMs is achieved at T=0.8. Lower or higher values result in diminished performance due to either deterministic rigidity or excessive randomness.
- Model Comparison: Llama achieves the highest top-level classification accuracy, particularly when Prompt Chaining is employed. The results indicate:
- Domain-level prediction: Up to 90.1% accuracy
- Subject-level prediction: Up to 80.5% accuracy
- Topic-level prediction: Only ~50% accuracy with prompt chaining; substantial drop-off in direct ICL settings.
- Baseline Comparison: BERT achieves 74% accuracy for domain classification, while BiLSTM achieves 66%, substantially lower than LLMs at optimal settings.
- Evaluation Metrics: Embedding-based and string distance measures are effective for capturing partially correct classifications, especially when labels are semantically proximate.
Error Analysis
Manual inspection of misclassifications shows recurring issues:
- Publications with short or missing abstracts hinder model accuracy.
- Multi-label instances are often simplified to a single label (e.g., "Hydrology" for "Hydrogeology, Hydrology, Limnology...").
- Coverage limitations in the FORC dataset (e.g., lack of Arts and Humanities subclasses) restrict generalizability to broader library contexts.
Implications and Future Directions
Practical Implications: LLMs, when equipped with prompt chaining, can provide highly effective domain and subject-level classification of scientific publications—far superior to traditional supervised approaches when trained solely on titles and abstracts. Topic-level granularity remains problematic, primarily due to taxonomy complexity, multi-label ambiguity, and data representation gaps.
Theoretical Implications: The integration of prompt chaining and ICL in LLMs opens new avenues for structured reasoning in automated categorization tasks. The dependence on hierarchical constraint at each taxonomy level accentuates the necessity for structured prompt engineering, moving beyond generic zero-shot/few-shot paradigms.
Future Prospects: Advancements in model architecture and the availability of more comprehensive, cross-domain, multi-label datasets will likely improve topic-level classification. Alternative taxonomies (ACM, DDC) and fine-tuned LLMs may provide superior performance, particularly in interdisciplinary or emerging research domains. Deployment in institutional research centers and digital libraries is feasible, contingent on further improvements in model robustness and taxonomy coverage.
Conclusion
The paper rigorously demonstrates that off-the-shelf LLMs, in combination with prompt chaining, are highly effective for automatic hierarchical classification of scientific texts—substantially surpassing traditional models in domain and subject-level categorization. However, performance at the topic level remains limited to approximately 50% accuracy, signaling the need for enhanced datasets, refined taxonomy design, and advanced LLMs. The methodology highlighted—prompt chaining—should be central to future efforts in automated scientific text classification across knowledge-intensive organizations.