BookRAG: A Hierarchical Structure-aware Index-based Approach for Retrieval-Augmented Generation on Complex Documents (2512.03413v1)
Abstract: As an effective method to boost the performance of LLMs on the question answering (QA) task, Retrieval-Augmented Generation (RAG), which queries highly relevant information from external complex documents, has attracted tremendous attention from both industry and academia. Existing RAG approaches often focus on general documents, and they overlook the fact that many real-world documents (such as books, booklets, handbooks, etc.) have a hierarchical structure, which organizes their content from different granularity levels, leading to poor performance for the QA task. To address these limitations, we introduce BookRAG, a novel RAG approach targeted for documents with a hierarchical structure, which exploits logical hierarchies and traces entity relations to query the highly relevant information. Specifically, we build a novel index structure, called BookIndex, by extracting a hierarchical tree from the document, which serves as the role of its table of contents, using a graph to capture the intricate relationships between entities, and mapping entities to tree nodes. Leveraging the BookIndex, we then propose an agent-based query method inspired by the Information Foraging Theory, which dynamically classifies queries and employs a tailored retrieval workflow. Extensive experiments on three widely adopted benchmarks demonstrate that BookRAG achieves state-of-the-art performance, significantly outperforming baselines in both retrieval recall and QA accuracy while maintaining competitive efficiency.
Sponsor

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
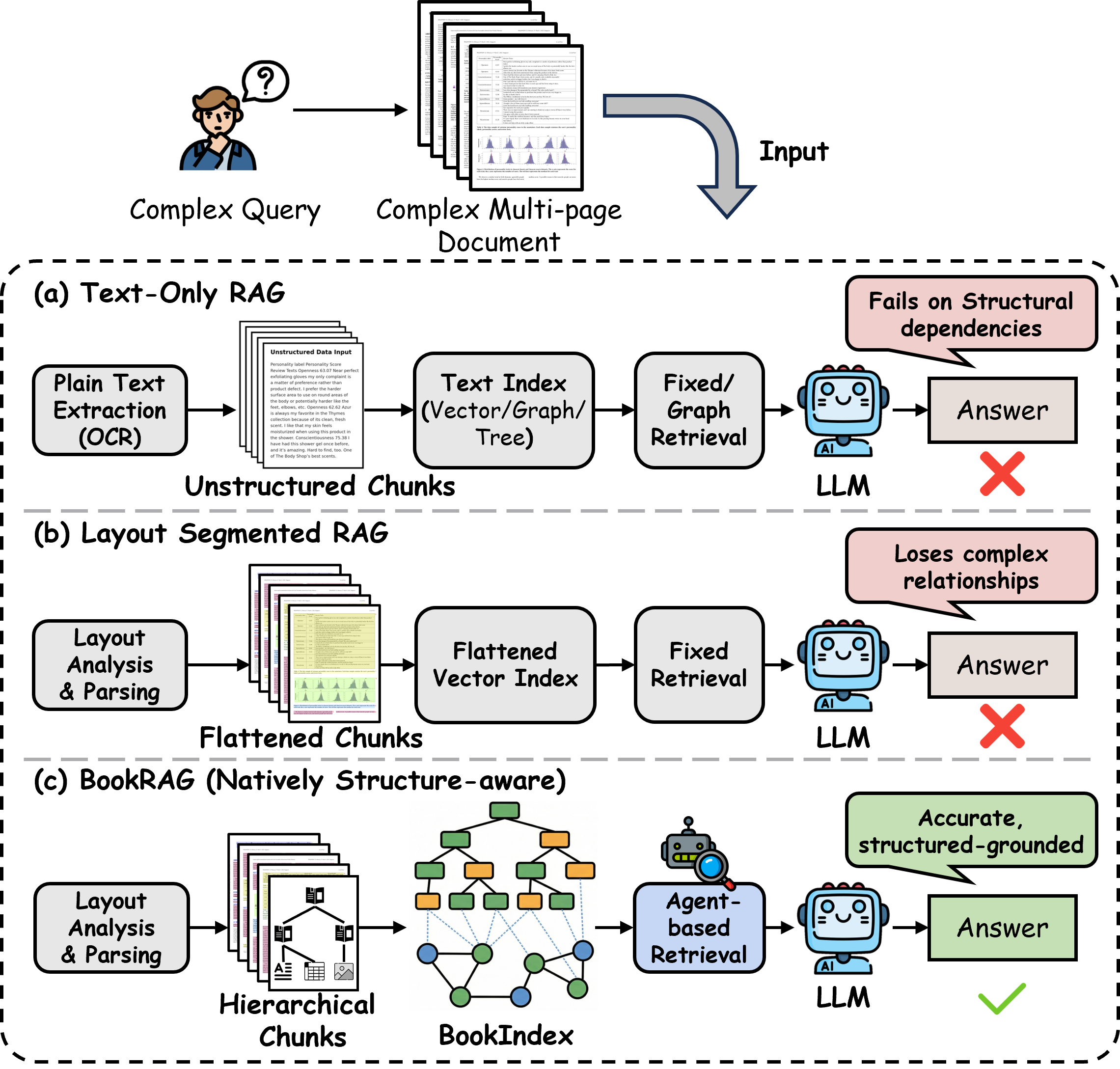
This paper introduces BookRAG, a smarter way for AI to answer questions using long, complex documents like books, manuals, and handbooks. Instead of treating a document as one big blob of text, BookRAG understands the document’s structure (chapters, sections, tables, figures) and the ideas inside it (who or what is mentioned, and how things relate). By combining both, it finds the right information faster and gives better answers.
What questions did the researchers ask?
The researchers wanted to solve two main problems:
- How can an AI better understand and use the natural structure of a document (like a table of contents and sections) when answering questions?
- How can an AI adapt its search strategy to different kinds of questions, from simple lookups to complex ones that need evidence from different parts of the document?
How did they do it?
To make this clear, imagine you’re trying to find answers in a big textbook.
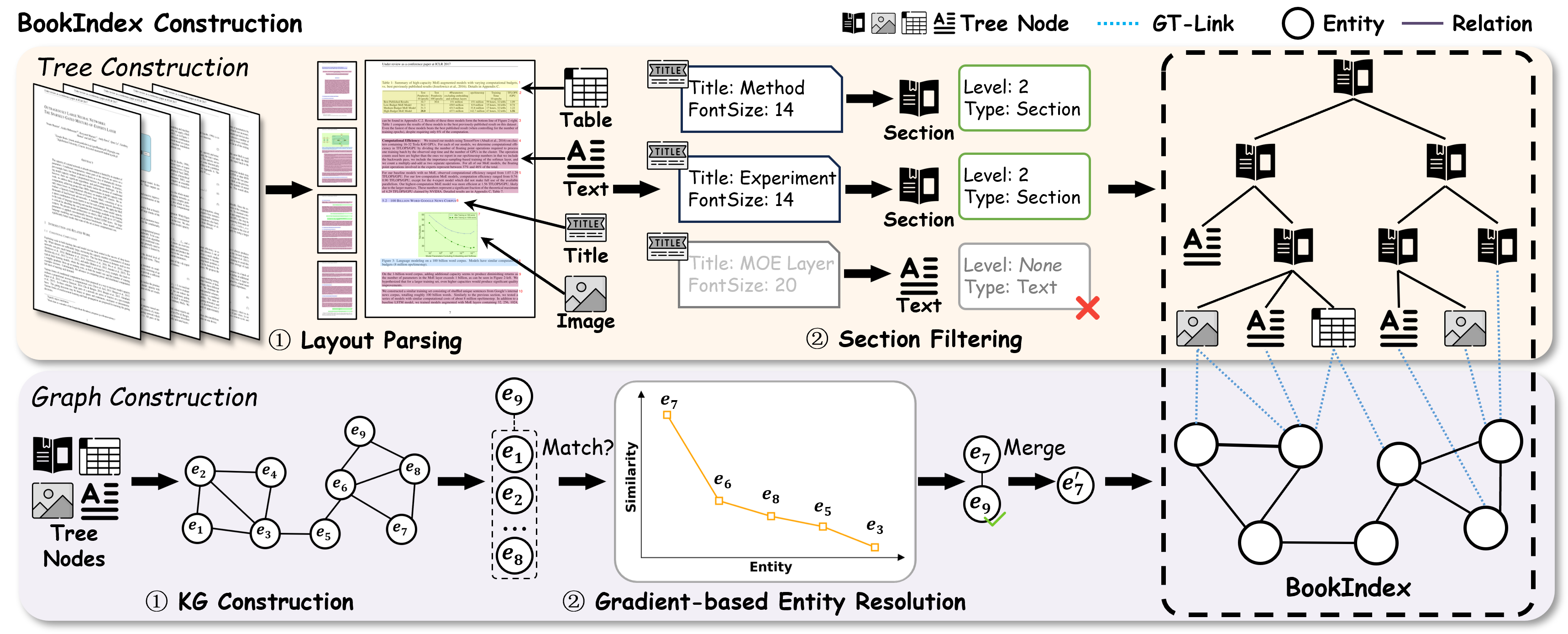
The big idea: BookIndex
BookRAG builds a special “index” called the BookIndex that combines three parts:
- A Tree (like a detailed table of contents): This shows the document’s structure—chapters, sections, and the content inside (text, tables, images).
- A Knowledge Graph (like a concept map): This stores important “entities” (people, tools, terms) and their relationships (e.g., “A uses B,” “C is part of D”).
- GT-Link (a set of links showing where concepts appear): These connect concepts from the graph back to the exact sections or blocks in the tree. Think of them as sticky notes that say, “This idea is explained here.”
Together, these let the AI follow both the layout (where things are in the document) and the logic (how ideas are related).
Understanding the document’s structure
First, the system “parses” the document:
- It identifies blocks like titles, paragraphs, tables, and images.
- With help from a LLM, it fixes mistakes (for example, a big-font sentence that looks like a title but is actually just normal text).
- It builds a clean tree that reflects the document’s real hierarchy (chapters → sections → content blocks).
Building the concept map (Knowledge Graph)
Next, it pulls out key entities and relationships from each block:
- For text, it uses a LLM.
- For images or figures, it uses a vision-LLM.
- For special blocks like tables, it also captures headers and structure, so rows/columns aren’t lost.
Fixing duplicate names: gradient-based entity resolution
Often, the same idea appears under slightly different names (like “LLM” and “LLM”). The system solves this by:
- Comparing a new entity against the most similar existing ones.
- Watching how similarity scores change. If there’s a sharp drop after the top match, it’s likely the same idea; if all scores are low, it’s probably new.
- When several close matches exist, it asks the LLM to choose the correct one. This is like scrolling your contacts: if “Alex G.” is very close to “Alexander Gray,” you merge them; if none look close, you add a new contact.
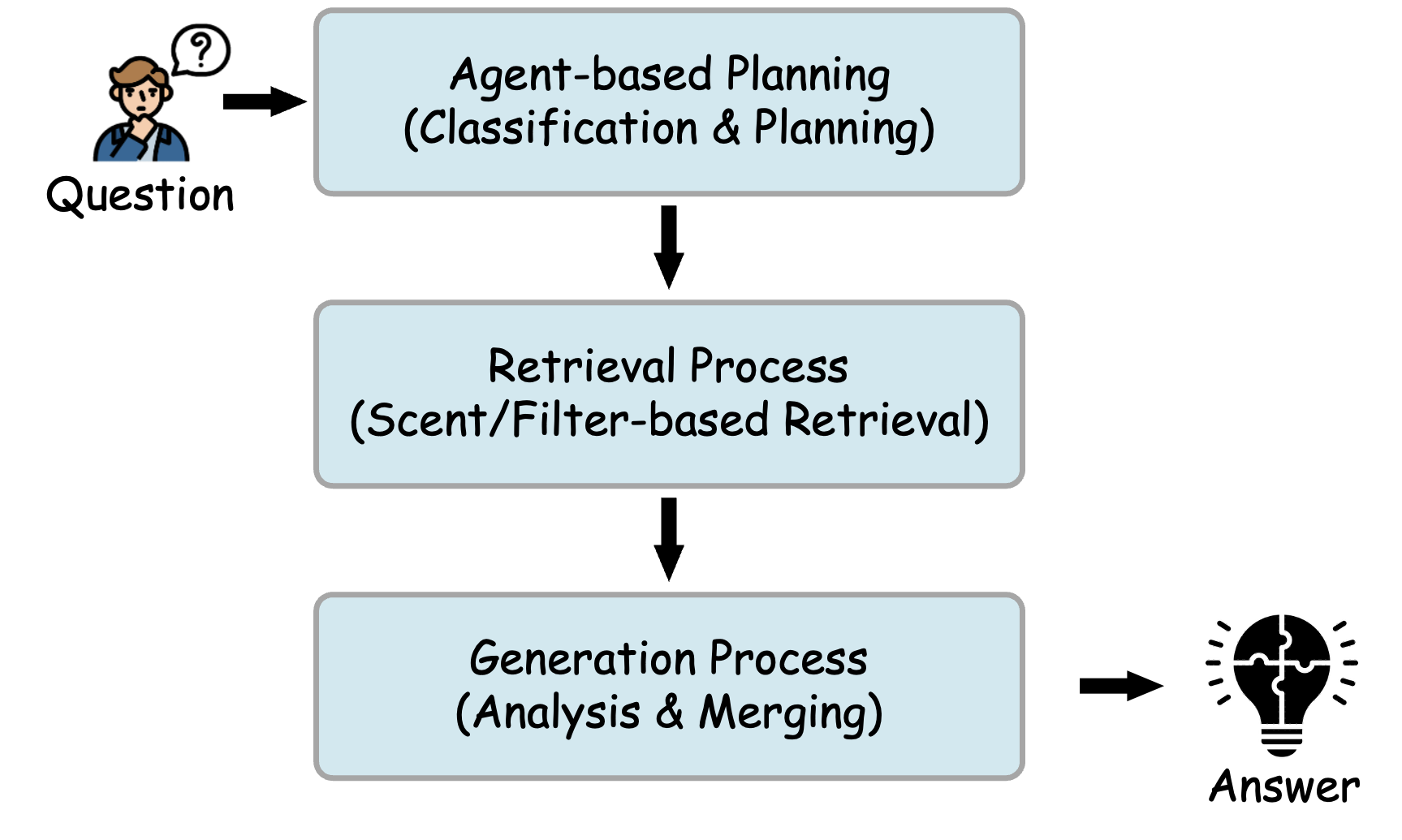
A smart search agent (inspired by Information Foraging Theory)
When you search for information, you follow “information scent”—clues like keywords or section titles—to reach the right “patch” (a helpful part of the document). BookRAG does something similar:
- It first classifies the question:
- Single-hop: one clear place has the answer (“What is the definition of X?”).
- Multi-hop: you need to gather evidence from multiple places (“How does A differ from B?”).
- Global aggregation: you need to count/filter across the whole document (“How many figures in Section 4 are about Y?”).
- Then it plans a custom workflow. For example:
- For Single-hop, it finds the most relevant section or entity and focuses there.
- For Multi-hop, it breaks the question into smaller parts, finds evidence for each, and combines the results.
- For Global aggregation, it filters the whole document (by section, type like tables/figures, etc.) and computes what’s needed.
How the system answers a question
- Selector (find the right patches): It narrows down the search area by following entities or applying filters (like section range or block type).
- Reasoner (make sense within patches): It ranks the most useful blocks using both the graph (which ideas are important and connected) and text relevance (how closely the content matches the question). It keeps only the best “frontier” of evidence using a skyline approach (evidence that is strong in at least one dimension).
- Synthesizer (compose the answer): It analyzes the selected evidence, and if needed, merges partial answers (especially for multi-step questions) into a clear final response.
What did they find and why it matters?
Across three common benchmarks for question answering over complex documents, BookRAG:
- Retrieved more relevant evidence (higher recall).
- Answered more questions correctly (higher accuracy).
- Stayed efficient (fast enough to be practical).
This matters because many real-world documents (like API manuals, legal handbooks, and technical guides) are long and structured. Systems that ignore this structure often miss key connections or fail on multi-step questions. BookRAG’s approach respects the document’s layout and logic, leading to more trustworthy answers.
Why this research is useful
- Better help from AI on complex tasks: It can support professionals in finance, law, engineering, and science who rely on long manuals and standards.
- Fewer mistakes and hallucinations: By grounding answers in the right sections and tying ideas together with the graph, the AI is more reliable.
- Flexible for different question types: Whether you need a quick definition, a comparison across chapters, or a count of items meeting certain conditions, the system adapts its strategy.
- A foundation for future tools: The BookIndex idea—combining a document’s structure with a concept map—can be extended to more kinds of documents and tasks.
In short, BookRAG shows how understanding both “where” information lives in a document and “how” ideas connect can make AI much better at answering questions in real-world settings.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper leaves the following issues unresolved:
- Index construction scalability: No analysis of the computational cost, memory footprint, and latency of building the BookIndex (layout parsing + LLM/VLM extraction + KG + ER) for very long documents or large corpora; unclear whether the approach scales to thousands of pages or multi-document collections.
- Generalization to diverse document types: The layout parsing and section filtering rely on features like font size and LLM judgments; the paper does not test robustness on scanned PDFs, multi-column layouts, non-standard typography, noisy OCR, or non-English documents.
- Hierarchical inference robustness: Section Filtering uses an LLM to assign levels, but there is no error analysis of misclassification rates, propagation effects on downstream retrieval, or strategies for handling missing/implicit hierarchies and inconsistent TOCs.
- Modal coverage gaps: KG extraction from formulas, figures, and complex tables is described but not systematically evaluated; handling of diagrams, code snippets, mathematical expressions, and compound figures remains under-specified.
- Entity extraction fidelity: The paper does not quantify precision/recall of entity and relation extraction from text, tables, and images, nor compare against established IE baselines in technical domains.
- Gradient-based entity resolution (ER) validity: The new ER method lacks a formal justification for the gradient threshold g, sensitivity analysis to g and top_k, and comparative evaluation against standard ER techniques (e.g., blocking + pairwise matching, transitive closure).
- ER failure modes: Unclear how the method handles hard cases—rare aliases, long-tail synonyms, cross-lingual aliases, acronyms vs expanded forms, domain-specific nomenclature, and cases where the true match is outside top_k.
- Reranker and embedding dependence: The ER pipeline depends on vector search and a reranker; the paper does not specify model choices, domain adaptation, calibration, or robustness to embedding drift across domains.
- Accumulation of ER errors: Incremental “clean ER” may accumulate early mistakes; there is no mechanism for global reconciliation (e.g., periodic re-clustering, transitivity checks) or error correction procedures.
- GT-Link completeness: The mapping M from entities to tree nodes is many-to-many, but coverage, ambiguity resolution (entities inferred but not explicitly present), and effects of incomplete links on reasoning are not analyzed.
- Graph reasoning design: PageRank is used for entity importance, but query-aware algorithms (e.g., personalized PageRank, HITS, path-constrained random walks) are not explored; no ablation shows the marginal contribution of graph vs text reasoning.
- Skyline ranking rationale: The choice of Skyline over top-k is motivated qualitatively; no formal properties, efficiency comparisons, or empirical trade-offs (precision/recall, diversity, latency) are provided.
- Query classification reliability: The agent’s classifier for Single-hop, Multi-hop, and Global Aggregation is not evaluated; misclassification rates and their impact on retrieval accuracy and latency are unknown.
- Operator library extensibility: The approach assumes a fixed operator set; there is no method to learn new operators, auto-tune operator parameters, or optimize plans via reinforcement learning or bandit strategies.
- IFT grounding and metrics: The use of Information Foraging Theory is conceptual; the paper does not define measurable “information scent,” patch efficiency, or attention cost, nor conduct user studies to validate IFT-based gains.
- Efficiency claims: “Competitive efficiency” is asserted without detailed latency breakdowns for planning, selection, reasoning, ER, and generation; no cost analyses (token usage, GPU time) or throughput metrics are provided.
- Faithfulness and citation: The generation stage lacks mechanisms to enforce grounded answers (e.g., citation spans, evidence attribution, answer verification), making it hard to assess faithfulness and reduce hallucinations.
- Robustness to ambiguous/contradictory content: The system’s behavior with conflicting evidence across sections or outdated information is not examined; no conflict resolution or provenance tracking is described.
- Domain transfer: Evaluation is limited to three benchmarks (not specified in this excerpt); generalization to high-stakes domains (finance, law, medicine) and cross-domain transfer with domain-adapted extraction/ER is not demonstrated.
- Multilingual support: The pipeline assumes English; handling of multilingual documents, cross-lingual entity resolution, and mixed-language sections remains unaddressed.
- Multi-document and corpus-level QA: BookRAG is designed for single documents; extensions to corpus-level indexing, inter-document GT-Links, cross-book multi-hop reasoning, and deduplication are open.
- Index maintenance: The paper does not discuss incremental updates to BookIndex (document edits, new editions), ER re-validation, versioning, or consistency under evolving content.
- Error propagation analysis: There is no end-to-end paper of how upstream errors (parsing, section levels, KG extraction, ER) affect downstream retrieval and QA, nor methods for uncertainty estimation or confidence scoring.
- Table/figure analytics: Global Aggregation examples are simple counts; support for complex table operations (group-by, joins, unit normalization), figure interpretation, and numerical reasoning is limited.
- Reproducibility and determinism: Agent planning and LLM/VLM components introduce stochasticity; settings (prompts, seeds, model versions) and strategies to ensure reproducibility are not provided.
- Security and privacy: Use of external LLM/VLM services for indexing and retrieval may raise data leakage concerns; no discussion of on-prem deployment, PII handling, or compliance requirements.
Glossary
- Agent-based Retrieval: A retrieval strategy where an autonomous agent classifies queries and dynamically assembles tailored workflows over the index. "implementing an agent-based retrieval."
- Agentic RAG paradigm: A class of RAG systems that use autonomous agents to orchestrate, refine, and reason within the RAG pipeline. "Besides, the Agentic RAG paradigm has been widely studied"
- BookIndex: A document-native index combining a hierarchical tree (layout structure) and a knowledge graph (entities/relations) linked via GT-Link. "We formally define our BookIndex as a triplet B = (T, G, M)."
- BookRAG: A hierarchical structure-aware, index-based RAG method tailored for complex documents with logical hierarchies and entity relations. "We introduce BookRAG, a novel RAG approach"
- Decompose: An operator that breaks a complex query into simpler sub-queries for targeted retrieval and synthesis. "Decompose a complex query into simpler, actionable sub-queries."
- Declarative interface: A user-facing specification style that lets users define processing pipelines at a high level without imperative code. "provides a declarative interface"
- Dirty ER: Batch entity resolution across multiple, noisy sources aiming to find all matching pairs, typically more costly than clean ER. "commonly referred to as dirty ER"
- DocETL: An agentic framework for LLM-based document extraction and transformation pipelines over layout-preserving blocks. "DocETL~\cite{shankar2024docetl}"
- Entity Resolution (ER): The process of identifying and merging multiple mentions that refer to the same real-world entity. "Entity Resolution (ER) process"
- Graph-based RAG: RAG that organizes knowledge as graphs to capture semantics and relations for improved retrieval and reasoning. "graph-based RAG"
- Graph topology: The structural arrangement of nodes and edges in a graph that influences importance and reasoning paths. "such as graph topology and semantic relevance"
- Graph-Tree Link (GT-Link): A mapping from KG entities to their originating tree nodes, grounding semantic relations in document structure. "Graph-Tree Link (GT-Link)."
- GraphRAG: A RAG approach that constructs a knowledge graph and performs community-based summarization for global reasoning. "GraphRAG~\cite{edge2024local}"
- Information Foraging Theory (IFT): A theory modeling information seeking as foraging guided by cues (“scent”) within content clusters (“patches”). "Information Foraging Theory (IFT)"
- Information patch: A cluster of related content (e.g., a section) that users explore for concentrated relevant information. "information patches (e.g., sections in handbooks)"
- Information scent: Cues (e.g., keywords) that indicate where valuable information is likely to be found. "information scent (e.g., keywords or icons)"
- Knowledge Graph (KG): A structured representation of entities and their relations extracted from the document. "knowledge graph (KG)"
- Layout-aware segmentation: Parsing documents into structured blocks (paragraphs, tables, figures) while preserving original layout. "layout-aware segmentation"
- Layout Parsing: Identifying and extracting primitive content blocks and types from document pages using layout analysis. "Layout Parsing"
- Leiden community detection algorithm: A graph clustering algorithm used to detect communities for hierarchical summarization. "Leiden community detection algorithm"
- Map: A synthesizer operator that uses partial retrieved information to produce intermediate answers. "Uses partially retrieved information to generate a partial answer."
- Multi-hop reasoning: Reasoning that chains evidence across multiple blocks or entities to answer complex queries. "multi-hop reasoning"
- OCR (Optical Character Recognition): Converting document images into machine-readable text for text-based processing. "OCR (Optical Character Recognition)"
- PageRank algorithm: A graph-based importance scoring method used to rank entities and propagate scores to tree nodes. "using the PageRank algorithm"
- Pareto frontier: The set of non-dominated items under multiple criteria; used to retain valuable nodes across dimensions. "retains the Pareto frontier of nodes"
- RAPTOR: A method that builds a recursive tree by clustering and summarizing document chunks at multiple levels. "RAPTOR~\cite{sarthi2024raptor}"
- Rerank model: A model that reorders candidate entities or nodes by learned relevance scores after an initial retrieval. "Rerank model R"
- Retrieval-Augmented Generation (RAG): Augmenting LLM generation with retrieved external context to improve factuality and coverage. "Retrieval-Augmented Generation (RAG)"
- Section Filtering: An LLM-guided step that assigns hierarchical levels to title candidates and corrects misclassified blocks. "Section Filtering"
- Scent-based Retrieval: Selection strategy that follows entity-linked cues (scent) to navigate toward promising sections. "Scent-based Retrieval: Retrieve content related to a specific entity or section."
- Select_by_Entity: An operator that selects all tree nodes within sections linked to a specified entity via GT-Link. "Selects all tree nodes () in sections linked to a given entity ()."
- Select_by_Section: An operator that uses an LLM to choose relevant sections and includes all nodes within them. "Select_by_Section"
- Skyline operator: A multi-criteria filtering mechanism that retains only non-dominated items. "Skyline operator"
- Skyline_Ranker: An operator that applies skyline filtering over multiple importance/relevance scores to pick final nodes. "Skyline_Ranker"
- Text_Reasoning: A reasoner that re-ranks tree nodes by semantic relevance of their content to the query. "Text_Reasoning"
- Transitive closure: The closure over all implied matches via transitivity; used to fully confirm equivalences in ER. "finding the transitive closure of all detected matches."
- Vector database: A store of embedding vectors supporting similarity search for candidate retrieval. "vector database DB"
- Vision LLM (VLM): A multimodal model that extracts entities/relations from visual elements (images, tables). "Vision LLM (VLM)"
Practical Applications
Immediate Applications
Below is a concise list of real-world use cases that can be deployed now, drawing on BookRAG’s hierarchical, index-aware retrieval, gradient-based entity resolution, and agent-based query workflows.
- Enterprise knowledge base assistants (software, manufacturing, energy, finance, legal)
- Use case: Chatbots for querying SOPs, operational guidebooks, technical handbooks, and compliance manuals with multi-hop reasoning across sections.
- Tools/products/workflows: BookIndex builder (tree+KG+GT-Link), agent-based planner integrated into existing RAG stacks (e.g., LangChain/LlamaIndex), vector DB + KG (e.g., Milvus/FAISS + Neo4j), skyline ranking for multi-criteria retrieval.
- Assumptions/dependencies: Reliable layout parsing for PDFs/handbooks; domain-tuned extraction prompts; secure access to internal documents; stable LLM/VLM availability.
- API documentation copilots (software/devtools)
- Use case: Developer assistant that answers “How do I authenticate with OAuth 2.0?” by tracing across “Authentication,” “Scopes,” and “Examples” sections and related tables.
- Tools/products/workflows: Document-native BookIndex from API manuals; Formulator+Selector operators (Extract, Select_by_Section/Entity); Graph_Reasoning over linked entities (methods, endpoints).
- Assumptions/dependencies: Clean API docs with consistent headings; entity extraction for functions and parameters; access controls for private repos.
- Regulatory compliance Q&A (legal/policy, finance, energy, healthcare)
- Use case: Retrieve duties, exceptions, and thresholds scattered across nested clauses in regulations, codes, and standards; verify compliance steps.
- Tools/products/workflows: KG capturing obligations/definitions; GT-Link to sections; skyline ranking using semantic and graph importance; audit trails of evidence nodes.
- Assumptions/dependencies: High recall entity extraction for legal definitions; jurisdiction-specific vocabularies; human review for compliance-critical outputs.
- Scientific and technical handbook assistants (academia, industrial R&D)
- Use case: Answer procedural or definitional questions (“What is information scent?”) and perform multi-hop comparisons (“Transformer vs. RNNs for long-range dependencies”) using books/handbooks.
- Tools/products/workflows: Agent-based decomposition (Decompose→Map→Reduce); Section Filtering to preserve logical hierarchy; multi-modal reasoning for figures/tables.
- Assumptions/dependencies: Access to full-text and figures; VLM for images/equations; correct section-level classification.
- Clinical guideline navigation (healthcare)
- Use case: Retrieve care pathways, contraindications, and dosage tables from long-form guidelines; reconcile recommendations across sections.
- Tools/products/workflows: Table-aware entity modeling (table entity + headers); graph-based multi-hop across related clinical entities.
- Assumptions/dependencies: Medical safety guardrails; human-in-the-loop verification; regular updates to guidelines.
- Safety and maintenance assistants (manufacturing, robotics, automotive)
- Use case: Technicians query complex equipment manuals about troubleshooting sequences that span multiple chapters, tables, and wiring diagrams.
- Tools/products/workflows: Layout-preserving tree for sections, images; VLM-backed entity extraction for diagrams; Selector operators for modality filtering (Filter_Modal).
- Assumptions/dependencies: High-quality VLM for schematic interpretation; device-specific terminology; offline deployment options for factory networks.
- Internal audit support (finance)
- Use case: Extract audit procedures and controls across policy manuals; count and aggregate references (“How many exceptions apply in Section 4?”).
- Tools/products/workflows: Global Aggregation workflow (Filter_Range/Filter_Modal→Map→Reduce); KG of controls/exceptions.
- Assumptions/dependencies: Accurate structural parsing of sections; robust deduplication via gradient-based ER; versioning and provenance.
- Education: interactive textbook paper aids (education)
- Use case: Students query definitions, summaries, and cross-chapter relationships; instructors assemble topic packs from selected sections and tables.
- Tools/products/workflows: BookIndex-aware retrieval; Extract for key entities; agent classification into Single-hop vs. Multi-hop questions.
- Assumptions/dependencies: Textbook access; suitable LLMs for pedagogy; content licensing.
- Customer support for consumer products (daily life, retail)
- Use case: Query appliance or vehicle owner manuals (“How to reset filter indicator?”) with section-aware retrieval and image/table grounding.
- Tools/products/workflows: Tree+KG indexing of manuals; modality filters for images; Reduce synthesizes step-by-step instructions.
- Assumptions/dependencies: Accurate OCR/layout models; device-specific variations; multilingual support.
- Policy and procurement handbook navigation (public sector)
- Use case: Staff query procurement thresholds, process steps, and exceptions; reconcile policy updates across versions.
- Tools/products/workflows: GT-Link mapping to sections; skyline ranking for evidence diversity; operator plans for range-limited retrieval.
- Assumptions/dependencies: Version tracking; controlled vocabularies; privacy and records management.
- IP and standards search (legal, engineering)
- Use case: Cross-reference standards clauses and definitions; retrieve figure/table references linked to clause terms.
- Tools/products/workflows: Entity resolution to unify aliases (e.g., acronyms); Graph_Reasoning to traverse normative references.
- Assumptions/dependencies: Accurate alias merging; access to standards repositories.
- Documentation observability and QA (software, enterprise knowledge management)
- Use case: Measure retrieval recall, evidence coverage, and operator effectiveness on complex doc sets; tune prompts/workflows.
- Tools/products/workflows: Telemetry on operator pipelines; skyline vs. top-k ablation; gradient thresholds for ER.
- Assumptions/dependencies: Evaluation datasets; governance for internal documents.
Long-Term Applications
These use cases are feasible with further research, scaling, domain adaptation, or integration maturity.
- Autonomous robotic self-maintenance (robotics)
- Use case: Robots parse component manuals to plan maintenance steps, verifying across images, wiring diagrams, and tables.
- What’s needed: Stronger VLMs for technical schematics; embodied execution validation; fault-tolerant reasoning.
- Assumptions/dependencies: Real-time multimodal interpretation; safety certification; edge deployment.
- Clinical decision support with document-native provenance (healthcare)
- Use case: Decision assistants that trace every recommendation to guideline sections, tables, and evidence graphs.
- What’s needed: Medical-grade validation; clinical ontologies integration; robust provenance UI.
- Assumptions/dependencies: Regulatory compliance (HIPAA, MDR); continuous updates; oversight by clinicians.
- Cross-document multi-hop reasoning across collections (academia, enterprise)
- Use case: Synthesize answers by traversing multiple handbooks, whitepapers, and standards with unified BookIndex across documents.
- What’s needed: Cross-document GT-Link mapping; scalable KG merging; corpus-level community detection.
- Assumptions/dependencies: Deduplication across sources; entity canonicalization; licensing.
- Authoring tools that embed GT-Link and ER at creation (software, publishing)
- Use case: Documentation platforms that auto-build BookIndex and KGs as authors write; readers get structure-aware RAG by default.
- What’s needed: Editor integrations; background ER; section-level semantics markup.
- Assumptions/dependencies: Adoption by publishers; standardization of structural metadata.
- Compliance “diff” and change impact analysis (policy, finance, legal)
- Use case: Detect changes in handbooks/regulations, map impacted entities/processes, and alert stakeholders.
- What’s needed: Version-aware BookIndex; delta-aware KG updates; impact scoring across GT-Links.
- Assumptions/dependencies: Reliable change logs; entity-level version control; auditability.
- Semantic ETL for document-to-database pipelines (data engineering, enterprise IT)
- Use case: Transform structured sections/tables into relational/graph stores with provenance to the document hierarchy.
- What’s needed: Robust declarative operators; schema induction; semantic constraints enforcement.
- Assumptions/dependencies: Agreed target schemas; data quality rules; monitoring.
- Personalized learning companions that navigate textbooks (education)
- Use case: Adaptive tutoring that decomposes questions, selects relevant sections, and cross-links examples and figures.
- What’s needed: Student modeling; pedagogical prompts; feedback loops.
- Assumptions/dependencies: Curriculum alignment; privacy of learner data; multilingual content.
- Domain-specific ER models and ontologies (all sectors)
- Use case: Faster, more accurate entity resolution for heavily acronymized domains (aerospace, finance, medical).
- What’s needed: Domain lexicons; hybrid symbolic + gradient ER; benchmark datasets.
- Assumptions/dependencies: Data availability; expert-curated ontologies.
- Real-time, streaming document updates and incremental indexing (enterprise)
- Use case: Continuous ingestion of evolving manuals/policies; live GT-Link maintenance; low-latency retrieval.
- What’s needed: Incremental BookIndex updates; conflict resolution; monitoring.
- Assumptions/dependencies: Event-driven pipelines; resource scaling; strong MLOps.
- Multi-agent orchestration for complex workflows (agentic RAG at scale)
- Use case: Coordinated agents for classification, decomposition, graph reasoning, multimodal analysis, and compliance checks.
- What’s needed: Planner-evaluator loops; tool use safety; inter-agent communication protocols.
- Assumptions/dependencies: Robust guardrails; tracing across agents; cost control.
General Assumptions and Dependencies
- Document characteristics: Works best on documents with identifiable hierarchical structures (books, manuals, handbooks). Flat or poorly structured documents reduce benefits.
- Extraction quality: Depends on reliable layout parsing (OCR, layout-aware models), LLM/VLM extraction of entities/tables/images, and effective prompts.
- Entity resolution: Gradient-based ER requires sensible similarity scoring and tuned thresholds; domain-specific canonicalization benefits performance.
- Compute and privacy: Enterprise deployment needs secure environments, access controls, and potentially on-prem or edge inference.
- Human-in-the-loop: Critical domains (healthcare, legal, safety) should include review and validation steps.
- Internationalization: Non-English and multi-script documents may require specialized OCR/LMMs and vocabulary adaptation.
- Maintenance: Index refresh and versioning workflows are needed as documents evolve; provenance is essential for trust.
Collections
Sign up for free to add this paper to one or more collections.