Trees to Flows and Back: Unifying Decision Trees and Diffusion Models
Abstract: Decision trees and diffusion models are ostensibly disparate model classes, one discrete and hierarchical, the other continuous and dynamic. This work unifies the two by establishing a crisp mathematical correspondence between hierarchical decision trees and diffusion processes in appropriate limiting regimes. Our unification reveals a shared optimization principle: \emph{Global Trajectory Score Matching (GTSM)}, for which gradient boosting (in an idealized version) is asymptotically optimal. We underscore the conceptual value of our work through two key practical instantiations: \treeflow, which achieves competitive generation quality on tabular data with higher fidelity and a 2\times computational speedup, and \dsmtree, a novel distillation method that transfers hierarchical decision logic into neural networks, matching teacher performance within 2\% on many benchmarks.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper shows that two very different-looking machine learning tools are actually two sides of the same coin:
- Decision trees: the “20 questions” style models that split data into boxes.
- Diffusion models: the “un-blurring” models that turn noise into images, sounds, or data by following a smooth path.
The authors prove a clean connection between them and introduce a shared training principle called Global Trajectory Score Matching (GTSM). They then build two practical tools—TreeFlow and DSM-Tree—that combine the strengths of both worlds and work especially well on table-like datasets.
The Big Questions
The paper asks three simple questions:
- Can a step-by-step decision tree be turned into a smooth, continuous process like a diffusion model?
- Can a diffusion model be turned back into a tree-like hierarchy?
- Is there one common “best way to learn” that explains both decision trees and diffusion models?
How It Works (Explained Simply)
Turning trees into flows
- Imagine walking down a staircase (a tree makes step-by-step splits). Now imagine making those steps so thin and frequent that the staircase turns into a ramp. That’s the idea here.
- A decision tree groups data into regions in steps. If you insert more and more tiny splits between the original ones, the “stepped” process becomes a smooth path.
- In math terms, the tree’s stepwise averaging becomes a “probability flow” ordinary differential equation (PF-ODE)—a fancy way of saying “a smooth rule that tells you how to move from a simple start to the real data, without extra randomness.”
Why deterministic (no randomness)? Because averaging within tree boxes doesn’t add noise; it just reshapes what you already have.
Turning flows into trees
- Think of gradually adding blur to a picture. At first, you can see different objects clearly. As you blur more, similar objects start looking the same and “merge.”
- A diffusion model does something similar when it moves from structured data toward noise. The authors track when groups of data become indistinguishable as time passes.
- Recording the order in which groups merge gives you a neat family tree (a hierarchy). So a flow (smooth dynamics) gives you a tree (hierarchical structure).
A shared training principle: GTSM
- Picture a long road trip from a starting point (simple noise) to your destination (real data). There are two ways to be correct: 1) plan the whole route perfectly, or 2) make sure every tiny step you take is in the right direction.
- GTSM is the second view. It says: if you get every tiny step’s direction right, the whole journey will be right.
- Diffusion models learn one big function to get all tiny steps right at once.
- Gradient boosting (building a forest of trees one by one) greedily fixes the biggest mistakes step by step—and the authors show this greedy strategy is actually optimal in an ideal setting for the GTSM objective.
Main Findings
- Tree ↔ Flow correspondence:
- Any decision tree can be seen as a smooth, continuous “flow” when you refine its splits enough.
- Any suitable diffusion process naturally defines a hierarchy of clusters as it moves toward noise.
- One unifying goal (GTSM):
- If your model’s tiny-step directions are always correct, you match the true entire path from noise to data.
- The authors prove that minimizing this “sum of small step errors” perfectly matches the true process.
- They also show that gradient boosting is an optimal way to solve the discrete version of this objective.
- Two practical tools:
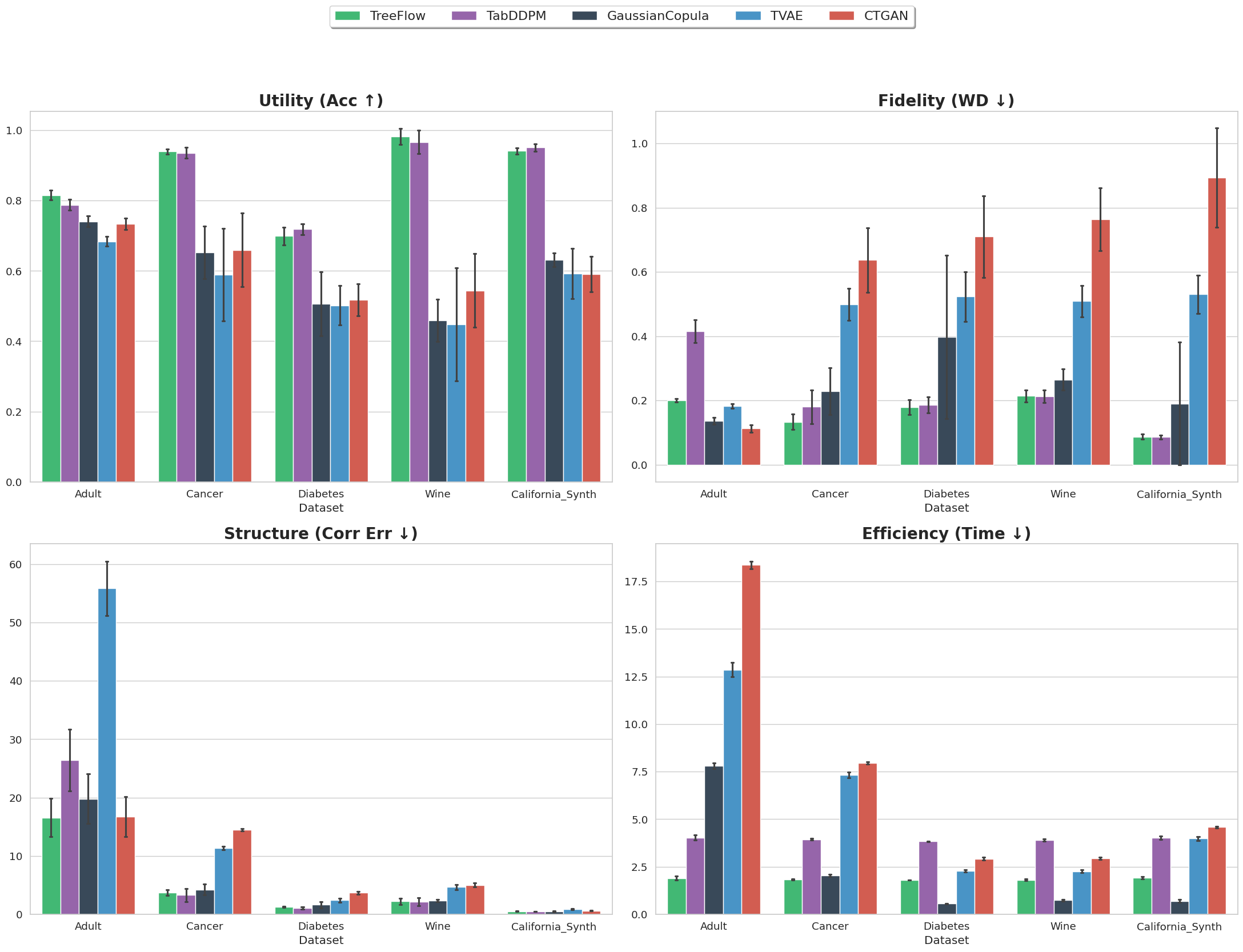
- TreeFlow: a generative method for tabular data that uses a tree’s structure to guide a flow model. It generates realistic samples with higher fidelity on many benchmarks and is about 2× faster than a strong diffusion baseline.
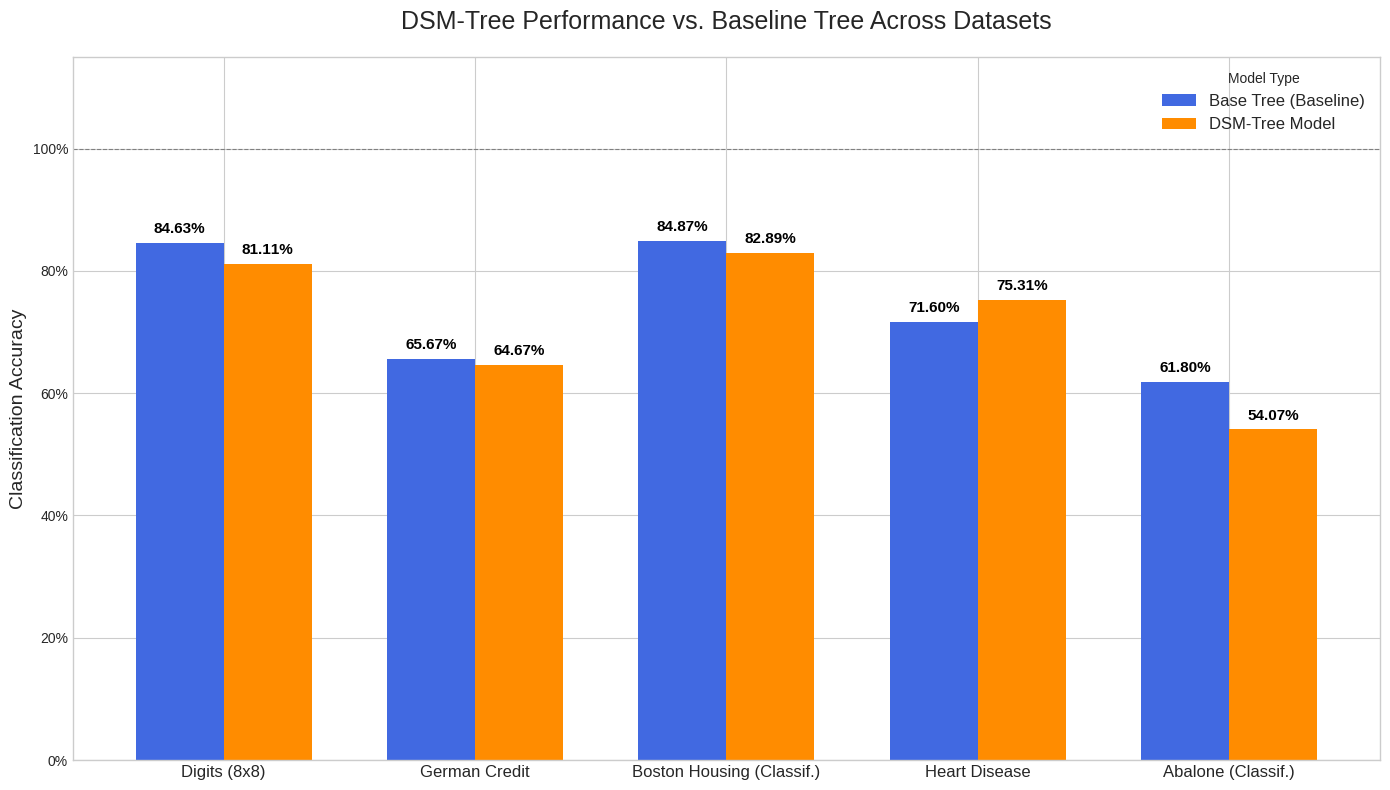
- DSM-Tree: a way to “distill” the full decision logic of a tree into a neural network. Instead of copying only the final leaf prediction, the network learns every decision along the path. It matches teacher performance within about 2% on most datasets and even beats it on one.
Why This Matters
- Unifies two powerful ideas: It shows decision trees and diffusion models aren’t opposites; they’re different views of the same process—one in steps (tree), one smoothly (flow).
- Better models for tabular data: Diffusion models often struggle with tables. TreeFlow brings tree structure into smooth generative models, improving quality and speed.
- More faithful distillation: DSM-Tree moves not just “answers” but the whole “thinking process” of a tree into a neural network, combining interpretability with flexibility.
A Bit More on the Two New Tools
These short descriptions summarize the tools introduced:
- TreeFlow
- What it does: Uses a decision tree to split the data space into regions and trains a smooth “velocity field” that depends on which region you’re in.
- Why it helps: The model learns different “paths” for different kinds of data, guided by the tree’s structure. This speeds up training and improves sample quality on tables.
- DSM-Tree
- What it does: Teaches a neural network to imitate every split in a tree, level by level—not just the final prediction.
- Why it helps: The network picks up the tree’s simple, effective rules, leading to strong performance with the flexibility of neural nets.
Final Takeaway
This paper connects decision trees and diffusion models by showing they can be translated into each other and trained using the same big idea: get every tiny step right, and the whole journey is right. From that insight, the authors build fast, high-quality generators for tabular data (TreeFlow) and a new way to transfer full tree logic into neural networks (DSM-Tree). This blend of discrete structure and smooth dynamics opens doors to more accurate, interpretable, and efficient machine learning models.
Knowledge Gaps
Unresolved Knowledge Gaps, Limitations, and Open Questions
Below is a concrete, actionable list of the main open issues that remain unaddressed or only partially addressed in the paper.
Theoretical foundations and assumptions
- Formalize and verify the “scale consistency” and “local refinement” assumptions used in dyadic refinement, including necessary and sufficient conditions on trees/partitions under which these assumptions hold for real-world (non-axis-aligned, categorical, missing-data) splits.
- Provide explicit rates of convergence (in e.g., total variation/Wasserstein) from the discrete tree-induced Markov chain to the limiting continuous-time process, alongside stability bounds with respect to tree perturbations.
- Specify and prove uniqueness of the limiting generator and PF-ODE: under what topologies and function spaces (e.g., Sobolev, BV) is the generator well-defined and unique given a sequence of refinements?
- Make Pawula-based truncation precise: rigorously establish when higher-order jump moments vanish and when the diffusion term must be exactly zero for typical tree refinements; characterize counterexamples where second-order terms persist.
- Clarify measure-theoretic conditions under which Girsanov-based arguments apply for CGTSM, especially when comparing deterministic PF-ODEs (zero diffusion) to SDEs (non-zero diffusion) and ensuring absolute continuity/equivalence of path-space measures.
- State explicit conditions (e.g., Novikov/Kazamaki-type integrability) required for the CGTSM optimality result to imply equality of path-space measures in the proposed settings.
- Extend the framework to discontinuous dynamics (e.g., Lévy-driven processes or rough paths) with precise assumptions and convergence guarantees, rather than only citing these as future directions.
Tree → Flow correspondence
- Constructive formula for the velocity field v(x, t): provide an explicit, computationally realizable mapping from a given tree’s partitions and leaf densities to the PF-ODE drift field and quantify how it depends on split geometry.
- Address non-homogeneous trees: characterize when time-invariant vs time-varying generators arise for practical trees with inhomogeneous refinements and what this implies for the induced flow.
- Categorical and mixed-type features: define how the tree-to-flow mapping handles discrete/categorical splits and whether the limit exists in spaces with hybrid topologies.
- Randomness in tree construction: characterize how subsampling, feature-bagging, and stochastic boosting alter the diffusion term (beyond a footnote), and derive the effective diffusion tensor D(t) in such ensembles.
Flow → Tree correspondence
- Relaxation of entropic homogeneity: many forward processes (e.g., VE SDEs) are non-stationary or lack monotone entropy; clarify how the merger-time tree construction adapts to such SDEs and whether it yields a forest or a different hierarchical object.
- Sensitivity of moment-based mergers: analyze how the choice of moment order n and threshold ε affect the induced hierarchy; provide consistency guarantees and robustness bounds to these hyperparameters.
- Non–well-separated modes: extend the merger construction beyond well-separated initial modes; quantify failure modes and define approximate hierarchies with guarantees under partial mode overlap.
- Noise schedule and non-Gaussian diffusions: examine whether ultrametric properties and the induced tree persist under different noise schedules and non-Gaussian diffusion processes.
GTSM framework and optimality claims
- Finite-sample and approximation bounds: derive non-asymptotic generalization/sample-complexity guarantees for CGTSM/DGTSM minimization and relate CGTSM error to downstream generation/classification metrics.
- Weighting function design: analyze how choices of w(t) affect optimization and path matching; derive theoretically motivated or optimal weightings for common SDEs/PF-ODEs.
- Robustness to model misspecification: quantify how deviations from the ideal score/diffusion model affect CGTSM minimization and the induced trajectory; provide error propagation bounds.
- Practical conditions for “greedy optimality” in boosting: the proof assumes a rich weak-learner class and continuous limits; provide regret or suboptimality bounds for finite-depth trees, shrinkage, regularization, and common boosting losses (e.g., logistic/exponential).
Algorithmic instantiations (TreeFlow and DSM-Tree)
- Path encoding design and invariance: specify and test how path encodings are constructed, how randomness in tree training affects them, and whether encodings are stable across runs or robust to tree perturbations.
- Mixed-type tabular data: detail how TreeFlow handles categorical variables, missing data, and feature scaling; evaluate impact on performance and convergence guarantees.
- Computational complexity: analyze how TreeFlow’s conditioning cost scales with tree depth and feature dimension; provide asymptotic and empirical runtime/space complexity.
- Mode coverage and bias: assess whether TreeFlow’s partition-conditioned flows risk mode fragmentation or collapse; provide diagnostics and mitigation strategies.
- DSM-Tree exposure bias: quantify error accumulation when predicting decisions level-by-level at inference; explore beam search, scheduled sampling, or hierarchical consistency losses to mitigate compounding errors.
- Baselines for DSM-Tree: compare against strong distillation methods (e.g., soft targets, soft decision trees, neural additive models) and ablate the effect of depth, teacher choice, and per-level supervision.
- Convergence guarantees for DSM-Tree: clarify and make explicit the assumptions (e.g., separability, network capacity, calibration) under which the cited finite-sample guarantee holds; provide rates and failure cases.
- Interpretability trade-offs: articulate how distillation into a neural network affects interpretability and whether tree-logic can be reliably extracted back from the student model.
Experimental validation and scope
- Statistical significance and robustness: report confidence intervals and statistical tests for the reported gains (e.g., “2× faster,” “highest TSTR on 3/5”), and analyze sensitivity to seeds, hyperparameters, and tree depth.
- Breadth of evaluation: expand beyond small synthetic 2D and a handful of tabular datasets; include larger, heterogeneous, or imbalanced datasets, and mixed continuous/categorical regimes to test claimed generality.
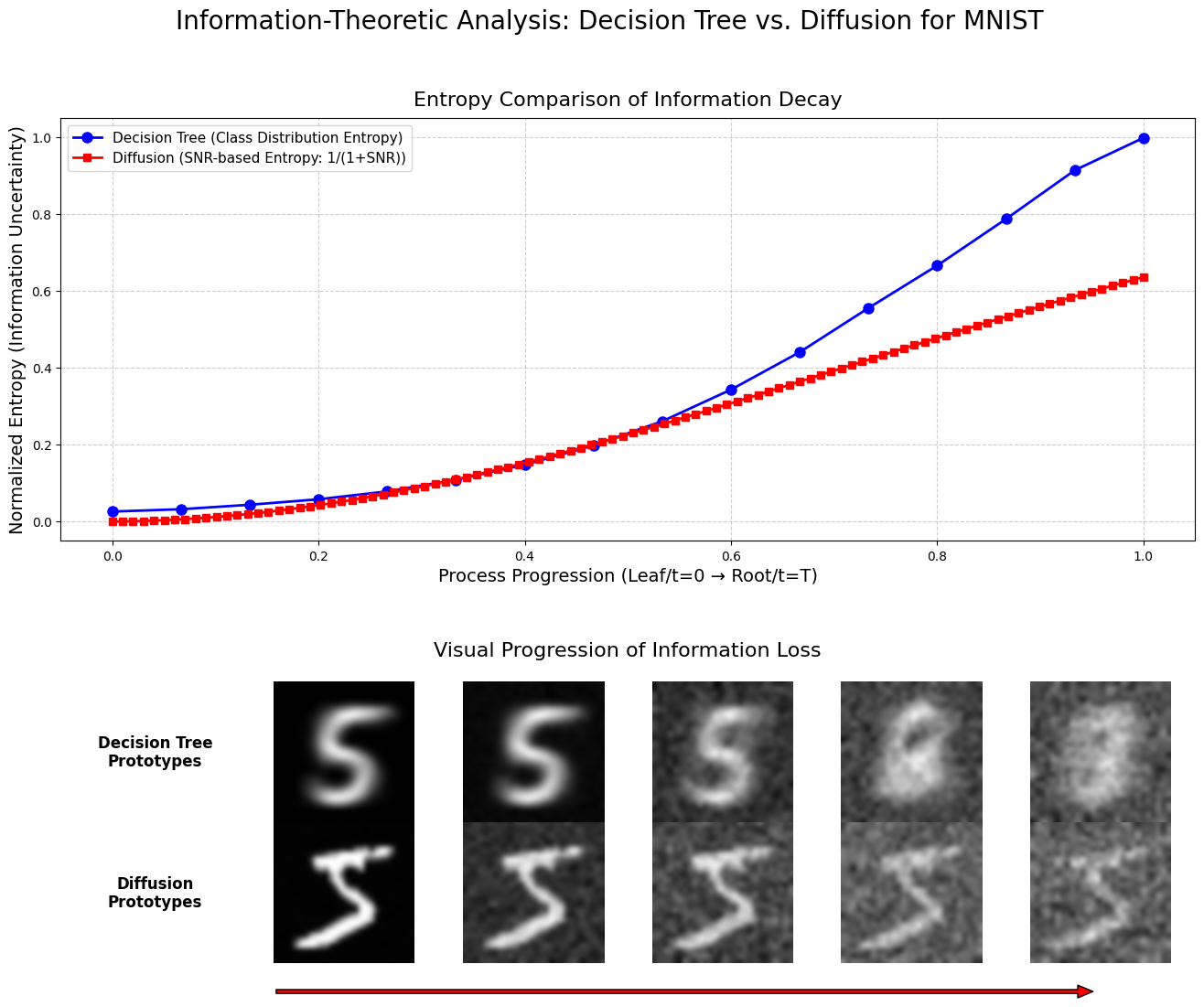
- Validation of theoretical proxies: justify the entropy proxy 1/(1+SNR) with theory or alternative information measures; assess whether the observed sigmoidal trends hold broadly.
- Reproducibility and ablations: provide ablations on path encoding, tree depth, noise schedules, network architectures, and training loss weightings to substantiate causal claims about the Tree–Flow prior.
- Extension beyond tabular: evaluate whether the unification yields practical gains on sequential or multimodal data, as suggested in the discussion of future foundation models.
Broader applicability and safety
- Distribution shift and OOD: analyze how the induced flows/trees behave under covariate shift or domain transfer and whether GTSM solutions degrade gracefully.
- Privacy and memorization: assess whether TreeFlow/DSM-Tree memorizes sensitive records in tabular data and establish privacy-preserving variants (e.g., differential privacy guarantees).
- Fairness and bias: study whether hierarchical conditioning amplifies or mitigates bias across subpopulations defined by the tree; propose fairness-aware conditioning or regularization.
Practical Applications
Below are practical applications derived from the paper’s findings, methods, and innovations. Each item lists target sectors, potential tools/workflows, and key assumptions/dependencies that may affect feasibility.
Immediate Applications
- Synthetic tabular data generation with TreeFlow
- Sectors: healthcare, finance, retail/e‑commerce, energy/utilities, public sector
- Use cases: privacy‑preserving data sharing; data augmentation for rare classes; sandboxing/QA for analytics pipelines; benchmarking ML workflows; preserving correlations and marginal distributions in tabular data
- Tools/workflows: integrate TreeFlow as an SDV-like plugin; “partition‑targeted” generation to produce samples from specific tree regions (e.g., rare disease subgroups); evaluation with TSTR, Wasserstein distance, and correlation error; 2× faster generation than TabDDPM per reported benchmarks
- Assumptions/dependencies: current evaluation emphasizes continuous features; performance depends on quality/depth of the learned tree; categorical handling may need encoding or specialized splits; privacy is not guaranteed by default—additional DP or disclosure risk checks are required
- Privacy‑preserving analytics and data sharing
- Sectors: healthcare (EHR, claims), finance (transactions, credit), education (student records), government statistics
- Use cases: share high‑utility synthetic datasets with external researchers/vendors; internal prototyping without exposing PII; create public “safe” versions of sensitive datasets
- Tools/workflows: TreeFlow generation + quantitative risk assessments (e.g., membership inference tests, attribute disclosure risk); governance checklists tying dendrogram-based audits to release criteria
- Assumptions/dependencies: synthetic data utility/faithfulness vs. privacy trade‑offs; data licensing/IRB constraints; requires robust privacy evaluation beyond fidelity metrics
- Fast deployment by distilling trees into neural networks (DSM‑Tree)
- Sectors: mobile/edge IoT, ad‑tech, fintech, healthcare edge devices
- Use cases: compress decision trees (or small ensembles) into compact NNs for faster inference and smaller memory footprint; deploy on devices that lack tree-runtime libraries; unify model stack for GPU/accelerator execution
- Tools/workflows: “Tree‑to‑NN” converter that supervises internal decisions across all levels; export to ONNX/TensorRT; post‑training quantization/pruning
- Assumptions/dependencies: reported ≤2% accuracy gap on many benchmarks; may need re‑distillation when trees evolve; requires access to original training data or pseudolabeled samples from a teacher
- Differentiable pipelines with tree logic preserved
- Sectors: MLOps/ML platform, recommender systems, risk scoring
- Use cases: integrate a differentiable surrogate of a tree into end‑to‑end gradient‑based training (e.g., combining learned embeddings with the distilled model); backprop through decision logic for multi‑objective optimization (accuracy + calibration)
- Tools/workflows: DSM‑Tree‑based student network as a drop‑in module in PyTorch/JAX graphs; joint training with other differentiable components; regularizers that preserve hierarchical decisions
- Assumptions/dependencies: needs level‑wise supervision signals; care with covariate shift if the distilled module is later fine‑tuned jointly with other components
- Interpretability and audit of diffusion models via induced trees
- Sectors: regulated industries (healthcare, finance, insurance), internal audit/compliance, model risk management
- Use cases: convert a trained diffusion model’s forward process into a canonical hierarchy; explain how modes merge over time; detect mode collapse or unintended biases; sanity‑check generator behavior
- Tools/workflows: Flow→Tree tooling that computes moment‑based merger times and renders dendrograms; link tree levels to time steps/entropy; audit reports connecting clusters to business segments
- Assumptions/dependencies: relies on entropically homogeneous, stationary SDE assumptions and well‑separated modes; may be sensitive to choice of moments/thresholds; complements, not replaces, formal interpretability guarantees
- Targeted scenario and edge‑case generation
- Sectors: finance (stress testing), insurance (underwriting/scenario testing), QA for analytics platforms
- Use cases: generate edge cases by sampling specific tree regions (e.g., high‑risk customer segments); augment datasets for rare but critical scenarios (e.g., fraud, rare failures)
- Tools/workflows: retrieve path encoding from the tree; condition TreeFlow on specific paths/labels; maintain a library of “scenario partitions” as a test suite
- Assumptions/dependencies: adequate coverage in training data for targeted partitions; potential overfitting to the learned tree structure if partitions are too fine
- Tabular data imputation with tree‑conditioned flows
- Sectors: healthcare (EHR gaps), finance (missing transactions), industrial IoT (sensor dropouts)
- Use cases: imputing missing values by running reverse PF‑ODE sampling conditioned on observed features and partition encodings; better local structure preservation than global models
- Tools/workflows: mask‑aware conditioning; optional multiple imputation to quantify uncertainty; evaluation via reconstruction error and downstream model performance
- Assumptions/dependencies: missingness mechanism (MCAR/MAR vs. MNAR) affects validity; categorical variables require careful treatment; calibration needed to avoid biased imputations
- AutoML and training curriculum design for tabular generative models
- Sectors: ML platform teams, enterprise data science
- Use cases: use the GTSM perspective to choose time‑weighting schedules, match trajectories to tree refinements, and allocate capacity across partitions; pick between TreeFlow vs. alternative generators per dataset profile
- Tools/workflows: automated pipeline that builds a tree, derives a refinement schedule, and configures flow‑matching settings; early‑stopping criteria based on per‑partition score errors
- Assumptions/dependencies: requires robust metrics for per‑partition convergence; may need dataset‑specific heuristics
Long‑Term Applications
- Hybrid foundation models for heterogeneous/tabular‑centric domains
- Sectors: healthcare (EHR + imaging/text), finance (structured + text/time series), retail (catalog + behavioral logs)
- Use cases: integrate tree‑guided structure with diffusion/flow dynamics to handle multimodal, irregular, or sparse schemas at scale
- Tools/workflows: tree‑conditioned flows extended to categorical/time‑series modalities; hierarchical conditioning interfaces; distributed training
- Assumptions/dependencies: theory currently assumes continuous features; broader adoption may need Lévy/rough‑path extensions for inherent discontinuities; substantial engineering for scale
- Causal and policy simulation with partition‑aware generators
- Sectors: public policy, healthcare policy, economics
- Use cases: simulate counterfactual outcomes within semantically meaningful partitions (e.g., policy‑relevant subgroups); stress‑test interventions by targeted generation
- Tools/workflows: combine TreeFlow with causal graphs/stratifications; use partition encodings as proxies for strata; validate with quasi‑experimental designs
- Assumptions/dependencies: causal identification is orthogonal and must be established separately; risks of spurious inference if partitions are not causally coherent
- Formal robustness/safety assessment for generative systems
- Sectors: medical device software, banking model risk, autonomous systems
- Use cases: map diffusion dynamics to an induced tree to derive conservative bounds on failure regions; certify coverage of critical modes; detect non‑monotonic entropy behavior
- Tools/workflows: Flow→Tree audit suite with ultrametric checks; conformance tests that tie time‑indexed mergers to specification thresholds
- Assumptions/dependencies: requires stronger theory/metrics to translate tree properties into formal guarantees; depends on stationarity and entropy monotonicity in practice
- Hierarchical RL and robotics via Tree↔Flow priors
- Sectors: robotics, logistics, industrial automation
- Use cases: extract skill hierarchies (Flow→Tree) from trajectory diffusion models; plan with trees, execute with flows for smooth control; structure exploration and option discovery
- Tools/workflows: trajectory‑level PF‑ODEs; decision‑tree abstractions over state‑action space; policy distillation from trees into differentiable controllers
- Assumptions/dependencies: extension from tabular to sequential/continuous control; stability and safety constraints; requires domain‑specific reward shaping
- Digital twins and grid/energy scenario generation
- Sectors: energy/utilities, smart grids, building management
- Use cases: generate realistic grid states/load profiles by partition (e.g., region, asset class) to stress‑test demand response and outage scenarios
- Tools/workflows: TreeFlow with hierarchical partitions aligned to physical/topological segments; targeted scenario libraries for resiliency testing
- Assumptions/dependencies: non‑stationarity and seasonality must be modeled; rich historical data; regulatory oversight for synthetic twin use
- Education and workforce analytics with privacy‑preserving synthesis
- Sectors: education technology, HR analytics
- Use cases: share synthetic student/employee records for research and A/B testing; generate partition‑targeted cohorts for fairness and efficacy analyses
- Tools/workflows: TreeFlow generation, Flow→Tree fairness audits, downstream evaluation via TSTR and bias metrics
- Assumptions/dependencies: fairness constraints and governance frameworks; careful handling of sensitive attributes in partitions
- Fairness‑aware generative pipelines
- Sectors: finance (credit underwriting), insurance, hiring
- Use cases: use explicit partitions along protected attributes to monitor, constrain, or rebalance generation; diagnose disparate impact through merger timelines
- Tools/workflows: joint optimization of GTSM with fairness regularizers at per‑partition level; group‑aware sampling schedules
- Assumptions/dependencies: access to protected attributes; risk of encoding or amplifying bias if partitions reflect historical inequities; policy compliance requirements
- Tree‑informed schedulers and curricula for diffusion model training
- Sectors: core ML research/engineering, applied ML teams
- Use cases: set time‑weighting w(t) and curriculum phases according to discovered tree hierarchies (earlier focus on coarse partitions, later on fine refinements); adaptive training that mirrors merger times
- Tools/workflows: automated merger‑time estimation from preliminary runs; dynamic reweighting of score‑matching loss across time and regions
- Assumptions/dependencies: needs reliable estimation of merger timelines; potential interaction effects with optimizer dynamics and architecture
In sum, the paper’s Tree↔Flow correspondence, the Global Trajectory Score Matching (GTSM) framework, and the concrete TreeFlow and DSM‑Tree algorithms open immediate pathways for synthetic tabular data generation, privacy‑preserving sharing, model deployment/compression, and diffusion auditability, while setting the stage for long‑term advances in hybrid foundation models, safety/robustness analysis, and structured learning in complex domains.
Glossary
- Agglomerative clustering: A hierarchical clustering method that merges clusters iteratively based on a linkage criterion. Example: "time-domain agglomerative clustering."
- Bellman equation: A recursive optimality equation in dynamic programming relating the value of a decision problem at one time step to the next. Example: "The Bellman equation \citep{bertsekas2012dynamic} relates the value at stage to the value at stage ."
- Conditional Flow Matching (CFM): A training objective for learning continuous-time generative flows by matching conditional velocities along interpolations between data and noise. Example: "Conditional Flow Matching (CFM) \citep{lipman2023flow}"
- Continuous Global Trajectory Score Matching (CGTSM): An integral objective that matches the score (gradient of log-density) of a model to that of a target process across all times and states. Example: "the CGTSM objective is:"
- Dendrogram: A tree diagram that records the sequence and timing of cluster merges in hierarchical clustering. Example: "the discovered hierarchical structure (dendrogram) obtained by tracking the forward SDE trajectories"
- Differential entropy: A measure of the uncertainty of a continuous probability distribution. Example: "the differential entropy is a monotonically non-dec(inc)reasing function of ."
- Diffusion Models (DMs): Generative models that learn to reverse a diffusion (noising) process using score estimation and stochastic differential equations. Example: "score-based generative models, or Diffusion Models (DMs) \citep{ho2020denoising,song2021scorebased}"
- Diffusion tensor: The positive semidefinite matrix that determines the covariance of infinitesimal noise in an SDE. Example: "the diffusion tensor is given by "
- Discrete Global Trajectory Score Matching (DGTSM): A discrete-time analogue of CGTSM that sums score-matching errors across stages, suitable for boosting. Example: "The discrete GTSM objective is the sum of score-matching losses:"
- Entropically homogeneous (process): A process whose (differential) entropy is monotonic over time, indicating uniform directional change in uncertainty. Example: "We call the process entropically homogeneous if the differential entropy is a monotonically non-dec(inc)reasing function of ."
- Filtration (probability): An increasing sequence of sigma-algebras capturing accumulated information over time or hierarchy. Example: "This induces a filtration "
- Fokker–Planck equation: A partial differential equation describing the time evolution of the probability density of a diffusion process. Example: "Hence, the expansion truncates exactly to the Fokker-Planck equation:"
- Girsanov's theorem: A result that relates measures of stochastic processes with different drifts via a Radon–Nikodym derivative, often used to express pathwise KL divergence. Example: "By Girsanov's theorem \citep{oksendal2013stochastic}, the KL divergence between path-space measures,"
- Global Trajectory Score Matching (GTSM): A unifying principle that frames learning generative trajectories as minimizing score mismatch along entire paths. Example: "We introduce the Global Trajectory Score Matching (GTSM) framework"
- Kramers–Moyal expansion: An infinite series expansion expressing the time evolution of a Markov process’s density via jump moments; truncates to Fokker–Planck under certain conditions. Example: "The time evolution of its density is described by the Kramer--Moyal expansion"
- Kullback–Leibler (KL) divergence: A measure of discrepancy between two probability distributions (including path-space distributions). Example: "the KL divergence between path-space measures"
- Liouville equation: A first-order PDE describing the evolution of densities under deterministic dynamics (no diffusion). Example: "This reduces the Fokker-Planck equation to a first-order Liouville equation,"
- Markov chain (discrete-time): A stochastic process where the next state depends only on the current state, evolving in discrete steps. Example: "this sequence forms a discrete-time Markov chain"
- Markov process (continuous-time): A stochastic process with the memoryless property evolving in continuous time. Example: "a continuous-path Markov process"
- Moment-based merger time: The first time at which conditional moment tensors of two clusters become statistically indistinguishable, used to define hierarchical merges. Example: "the -merger time is the first time at which their -th order conditional moment tensors become statistically indistinguishable"
- Net decision tree: An abstraction that aggregates an ensemble’s partitions into a single refined hierarchy whose leaf values sum the ensemble’s predictions. Example: "we introduce the net decision tree abstraction."
- Path-space measures: Probability measures over entire trajectories (paths) of a stochastic process. Example: "the KL divergence between path-space measures"
- Pawula's theorem: A theorem stating that if any jump moment beyond second order in the Kramers–Moyal expansion vanishes, all higher moments must vanish, yielding a Fokker–Planck equation. Example: "Pawula's theorem \citep{pawula1967approximation} states that if any jump moment is zero, all higher moments must also be zero."
- Probability Flow Ordinary Differential Equation (PF-ODE): A deterministic ODE whose flow shares marginal distributions with a given diffusion process. Example: "Probability Flow Ordinary Differential Equation \citep{song2021scorebased} (PF-ODE)"
- Reverse-time drift: The drift term of the SDE governing the reverse (denoising) direction, expressible via the score of the intermediate distribution. Example: "Since the reverse-time drift is a function of the score,"
- Score function (in diffusion models): The gradient of the log-density, guiding the reverse dynamics to denoise data. Example: "the score function specifies the optimal direction for the next infinitesimal step of the reverse process."
- Score matching: A training principle that fits a model to the score (gradient of log-density) rather than the density itself. Example: "score-matching losses"
- Sigma-algebra (σ-algebra): A collection of sets closed under complement and countable union, representing events under uncertainty. Example: ""
- Stationary distribution: An invariant distribution to which a stochastic process converges in the limit of infinite time. Example: "possesses a stationary distribution"
- Stochastic Differential Equation (SDE): A differential equation driven by stochastic noise (e.g., Brownian motion) that models continuous-time random dynamics. Example: "stochastic differential equations (SDEs)"
- Total variation (TV) distance: A metric on probability measures capturing the maximum difference in probabilities assigned to events. Example: "$\lim_{t \to \infty} \|p_t - p_\infty\|_{\text{TV} = 0$"
- Tower property: A law of iterated expectations stating that conditional expectations can be nested consistently. Example: "By the tower property \citep{durrett2019probability}, the transition operator"
- Ultrametric inequality: A strong triangle inequality where the distance between any two points is at most the maximum of the other two pairwise distances; implies hierarchical structure. Example: "these merger times obey an ultrametric inequality."
- Value function: The optimal expected cost-to-go from a given state in a sequential decision problem. Example: "the optimal cost-to-go, or value function ."
- Wasserstein distance: An optimal transport-based distance between probability distributions measuring the cost of moving mass. Example: "lowest Wasserstein distance on 4/5 benchmarks"
- Weak learner: A base model with limited capacity used in boosting, combined iteratively to form a strong predictor. Example: "weak learners (decision trees)"
Collections
Sign up for free to add this paper to one or more collections.