- The paper introduces a novel latent-space diffusion method using gradient-boosted trees for synthetic minority oversampling, boosting predictive performance on imbalanced tabular data.
- It presents three implementations—PCAForest, EmbedForest, and AttentionForest—that balance efficiency, privacy, and high recall in downstream tasks.
- Empirical results demonstrate significant improvements in recall and F1 scores with reductions in generation time by up to 95% compared to baseline methods.
Latent-Space Flow-Based Diffusion for Minority Oversampling in Tabular Data
Introduction
Addressing severe class imbalance in tabular datasets is pivotal for achieving robust predictive performance in real-world applications—including healthcare anomaly detection, fraud identification in finance, and rare-event prediction in manufacturing. Traditional generative models such as GANs, VAEs, and neural diffusion have made progress in synthesizing minority-class samples, but have significant drawbacks for tabular data: unstable training, heterogeneity handling, privacy vulnerabilities, and inefficient sampling. This paper presents a novel paradigm that leverages latent-space, tree-driven diffusion methods—specifically coupling Conditional Flow Matching (CFM) with gradient-boosted trees (GBTs)—to generate synthetic minority samples while maintaining tabular structure, reducing computational cost, and preserving privacy.
Methodology
Overview of Proposed Approaches
The framework introduces three main instantiations—PCAForest, EmbedForest, and AttentionForest—each characterized by its approach to latent space encoding and model architecture, ultimately integrated with a GBT-driven flow in latent space. The process operates as follows:
- The minority class is identified and isolated.
- An encoder projects these samples into a compact latent space (using PCA, feed-forward autoencoder, or transformer autoencoder).
- Forest-Diffusion is trained to model a diffusion flow (vector field) in this latent space using GBTs under CFM.
- Synthetic samples are generated via the reverse ODE from Gaussian noise, decoded (if necessary), and used to augment the minority class.
This architecture harnesses the inductive biases of tabular data, increases computational tractability, and enables flexible balancing of utility and privacy.
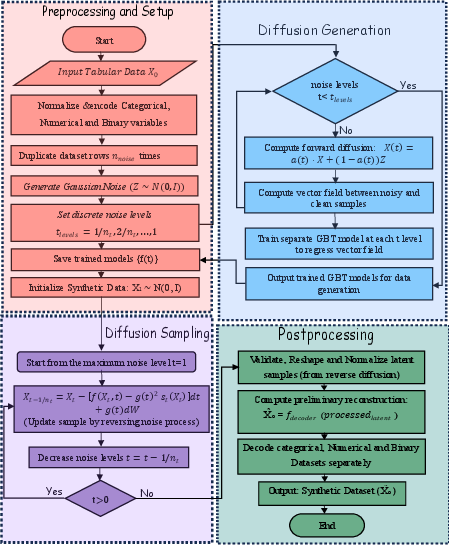
Figure 1: Synthetic tabular data generation schematic showing the combination of latent space encoding and GBT-based flow under the Forest-Diffusion approach.
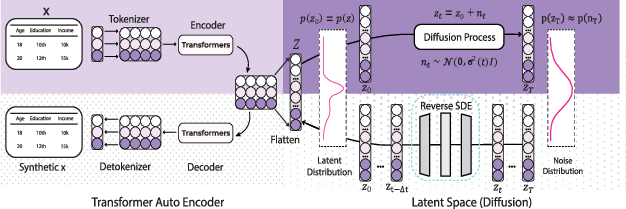
Figure 2: Detailed flowchart illustrating latent space encoding, GBT flow learning, and decoding for synthetic generation in the Forest-Diffusion pipeline.
Latent Encoders and Flow Learning
PCAForest uses linear PCA for dimensionality reduction, offering rapid encoding while retaining maximal variance and enabling fast augmentation.
EmbedForest leverages a feed-forward autoencoder for nonlinear, compact latent manifolds, improving representation flexibility at modest computational cost.
AttentionForest introduces a transformer-based autoencoder to capture higher-order feature interactions via multi-head self-attention, enabling expressive latent representations tailored for structured tabular modalities.
All variants use GBTs rather than neural networks to parameterize the time-varying vector fields in diffusion, aligning modeling strengths with tabular data's structural complexity.
Conditional Flow Matching with Gradient-Boosted Trees
Training is formulated via Conditional Flow Matching, specifically the I-CFM variant, which:
- Interpolates synthetic trajectories between real minority samples and Gaussian noise in latent space.
- Minimizes regression loss between the learned vector field and true flow direction.
- Operates efficiently in lower-dimensional latent representations to speed training and sampling.
Evaluation Protocol
The methods were benchmarked over 11 real-world tabular datasets (including healthcare, finance, and industrial scenarios), using a fixed 30% real-only test split and sweeping augmentation ratios from 25% to 300%. Evaluation focused on downstream utility (recall, precision, F1, calibration), statistical similarity (Wasserstein distance), and empirical privacy (NNDR and DCR). Baseline comparators included SMOTE, CTGAN, and original Forest-Diffusion.
Experimental Results
Downstream Utility
Across random forest and XGBoost classifiers, the latent-space Forest-Diffusion variants consistently delivered superior minority recall and F1 scores relative to baseline augmentation techniques.
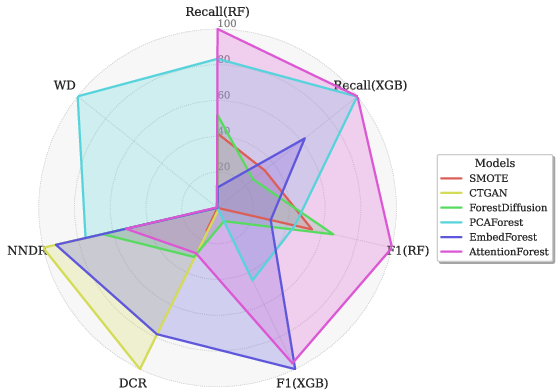
Figure 3: Radar plots of downstream machine learning performance (recall, F1, calibration, statistical similarity) for PCAForest, EmbedForest, AttentionForest, and baseline methods across multiple datasets.
AttentionForest notably achieved the highest average recall and F1 scores, demonstrating robust sensitivity and reliability in imbalanced binary classification. PCAForest offered comparable utility with much lower generation time, while EmbedForest presented strong privacy characteristics and competitive utility.
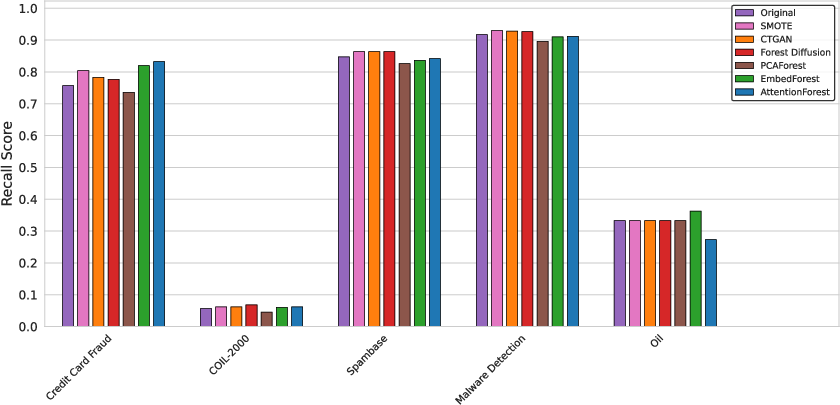
Figure 4: Recall score comparison at 100% augmentation ratio showing substantial gains across diverse benchmarks using latent-space diffusion models.
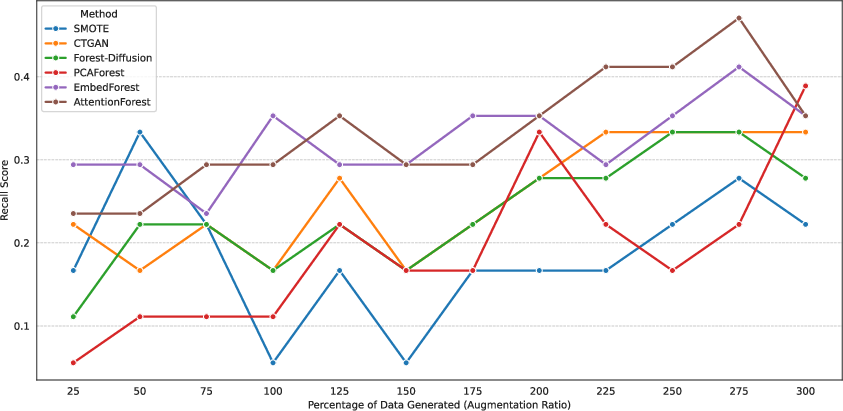
Figure 5: Recall trends across varying augmentation ratios, illustrating stable performance and advantageous scaling properties for transformer-based latent models.
Privacy and Statistical Similarity
Latent-space training led to competitive or higher privacy protection based on DCR and NNDR while maintaining realistic distributional similarity:
- PCAForest demonstrated near-perfect alignment with real data in latent space (low WD) and fast runtime.
- AttentionForest balanced strong downstream utility with competitive empirical privacy metrics.
- EmbedForest improved privacy at the expense of slightly relaxed distributional similarity.
- Compared to neural synthesis baselines, tree-based latent diffusion yielded more stable privacy-utility trade-offs.
Robustness and Ablations
Ablation studies revealed sensitivity mainly to embedding dimension and learning rate:
- Smaller latent embeddings improved generalization and recall.
- High learning rates consistently harmed stability and minority recall.
- Effectiveness of architecture-specific parameters (e.g., attention heads, diffusion steps) was highly dataset-dependent.
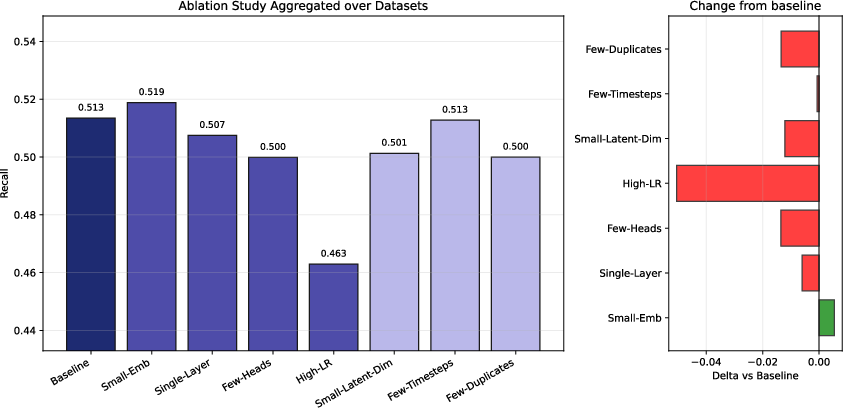
Figure 6: Aggregated ablation impact across seven parameter groups highlighting embedding dimension and learning rate sensitivity in AttentionForest.
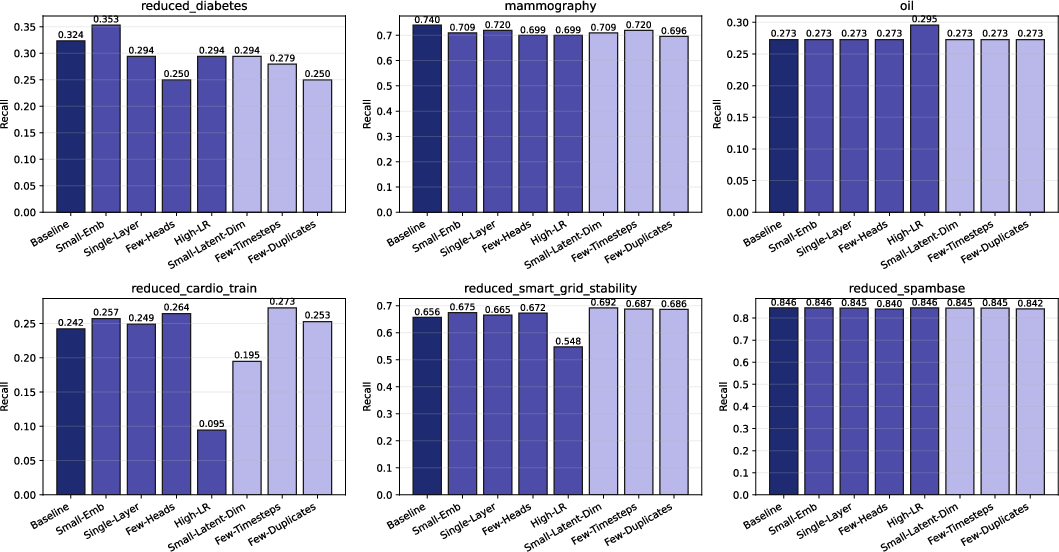
Figure 7: Individual dataset ablation curves for six datasets, illustrating dataset-specific optimal configurations.
Computational Efficiency
PCAForest and EmbedForest achieved substantial reductions in generation time (up to 95% faster than baseline Forest-Diffusion), validating the accuracy-efficiency trade-off for large-scale data augmentation. AttentionForest, though more computationally intensive due to transformer overhead, consistently led in predictive performance where compute budgets permitted.
Implications and Future Directions
Practically, this framework is highly applicable in domains where rare event prediction underpins safety, reliability, and cost: defect detection, financial fraud, industrial risk mitigation, predictive maintenance, and clinical analytics. The ability to generate high-fidelity, privacy-aware synthetic data enables rebalancing for minority sensitivity, data sharing when access is limited, and robust model deployment.
Theoretically, latent-space tree-driven diffusion advances the modeling frontier by connecting tabular structure, efficient representation, and rigorous flow-based generative modeling. Future extensions should explore formal privacy guarantees (differential privacy for boosting), broader modality coverage (mixed-type/multiclass synthesis), and policy-driven joint optimization of augmentation and imputation.
Conclusion
Latent-space Forest-Diffusion—with PCAForest, EmbedForest, and AttentionForest variants—provides a technically rigorous, efficient, and flexible approach to minority-class augmentation for tabular data. Tree-based flow learning in latent representations yields substantial recall and utility gains with tunable privacy and distributional realism. The strong empirical results, hardware scalability, and analytic interpretability mark these methods as advancing both the theory and practice of tabular data synthesis for imbalanced learning regimes.
References
Boosting Predictive Performance on Tabular Data through Data Augmentation with Latent-Space Flow-Based Diffusion (2511.16571)