- The paper presents a novel structure-aware chunking framework (STC) that uses a hierarchical Row Tree to preserve field-level dependencies in tabular data.
- It employs recursive, token-constrained splitting and greedy, overlap-free merging to reduce chunk count by 40-56% while optimizing token utilization.
- Empirical results on SEC filing data demonstrate enhanced retrieval metrics, with MRR and Recall@1 significantly outperforming baseline methods.
Structure-Aware Chunking for Tabular Data in Retrieval-Augmented Generation
Introduction
Chunking strategies are fundamental to the effectiveness and efficiency of retrieval-augmented generation (RAG) systems, particularly when processing tabular documents common in enterprise pipelines. Existing chunking mechanisms, predominantly designed for unstructured text, exhibit limited alignment with the hierarchical and field-oriented organization of tabular data such as CSV or Excel files. As a result, these strategies often yield fragmented or redundant segments, disrupting semantic coherence and attenuating retrieval quality. The paper "Structure-Aware Chunking for Tabular Data in Retrieval-Augmented Generation" (2605.00318) introduces a novel structure-aware tabular chunking (STC) framework that operates at the row level, utilizing a hierarchical Row Tree to encode each row as a key-value (KV) block. The result is a dense, lossless segmentation approach that enforces token constraints without sacrificing structural fidelity.
Historically, chunking in RAG systems has favored linearized, fixed-size, or sliding-window text spans, often with overlapping windows to hedge against context loss across chunk boundaries. While such techniques suit text-centric inputs, they disregard field-level dependencies inherent in tabular data, fragmenting associated fields and representation—an impediment for both retrieval and reasoning tasks. Prior research such as CAST [cast2025] has shown that structure-aware chunking, leveraging Abstract Syntax Trees for code, increases downstream performance by retaining syntactic coherence. However, analogous methods for tabular datasets—where relationships are multi-dimensional and typically organized by rows—remain underdeveloped. Concurrent lines of work focus on learning representations of tabular data (e.g., TaBERT, TAPAS), yet they presuppose the availability of well-formed, coherently organized inputs, placing further emphasis on the importance of structure-preserving chunking in upstream pipelines.
Structure-Aware Chunking Framework
The core innovation of the STC framework lies in its Row Tree representation and structure-preserving chunk generation strategy. Tabular data is first transformed into a hierarchical tree: each table or sheet becomes a node under the root, with individual rows as leaves. Each row is rendered as a self-contained set of KV pairs, maintaining integrity at the attribute level.
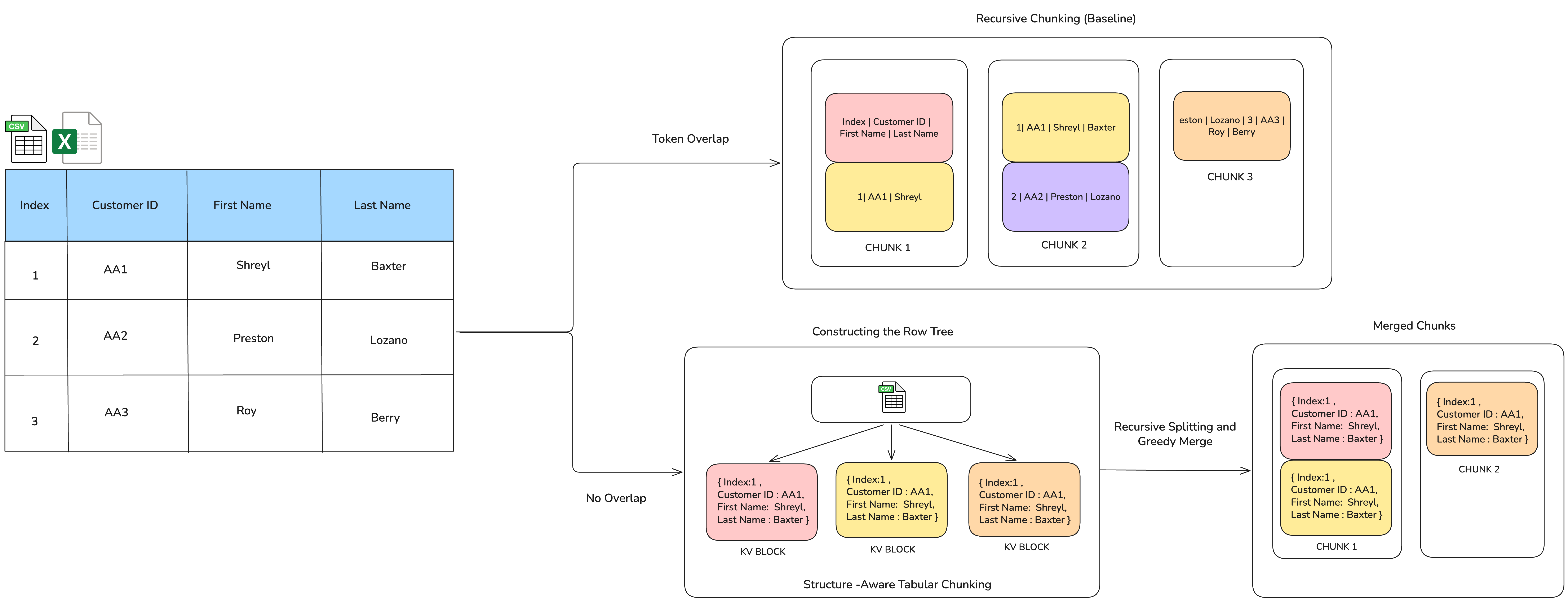
Figure 1: Comparison of conventional recursive token-based chunking (top) versus row-structured chunking in STC (bottom); the former fragments rows and introduces overlap, while the latter yields dense, hierarchical, non-overlapping chunks.
Chunk creation proceeds in two main stages:
- Recursive, token-constrained splitting: The algorithm traverses the Row Tree top-down, segmenting nodes only when their descendant-wise token count breaches the maximum constraint. If an indivisible row exceeds the token limit, an emergency splitting procedure fractures the row into contiguous KV fragments, still respecting field boundaries.
- Greedy, overlap-free merging: Leaf nodes (rows or row fragments) are greedily merged within their parent node, subject to remaining below the token cap, yielding densely packed, non-overlapping chunks inherently aligned with row (and sheet) boundaries.
Notably, this approach consistently eliminates context overlap and redundant tokenization prevalent in traditional chunking, enhances chunk compactness, and upholds inter-field dependencies.
Empirical Evaluation
Evaluation was performed using the MAUD dataset, a legal benchmark composed of highly structured QA pairs derived from SEC filings. Three chunking strategies were compared: standard RecursiveCharacterTextSplitter with overlap (Recursive), recursive splitting applied to KV-formatted data (KV+Recursive), and the proposed STC approach.
Across all data splits and metrics (average chunk size, token utilization, processing speed), STC demonstrated robust advantages:
- Chunk Count Reduction: STC reduced the total chunk count by approximately 40% versus Recursive and 56% versus KV+Recursive.
- Token Utilization: Mean chunk size advanced to 399–402 tokens (of a 512-token budget), a material increase in token efficiency compared to baselines.
- Processing Speed: STC's structure-aware, overlap-free paradigm halved or bettered chunking time, with improvements scaling with dataset size.
These results indicate that STC not only improves token footprint but also accelerates preprocessing, positioning it as a computationally attractive option for large-scale systems.
Chunking efficacy was further scrutinized via controlled retrieval experiments on MAUD. Chunks generated by each strategy were indexed, and retrieval was executed using both a hybrid dense-sparse pipeline (semantic bi-encoder plus BM25 with cross-encoder reranking) and BM25 alone.
Key retrieval metrics, including Recall@k and Mean Reciprocal Rank (MRR), revealed clear gains for STC:
- Hybrid Retrieval: MRR improved from 0.3576 (Recursive) to 0.5945 (STC), with Recall@1 rising from 0.3470 to 0.5390.
- BM25-only: Recall@1 nearly doubled, jumping from 0.3660 (Recursive) to 0.7540 (STC).
These results substantiate that preserving tabular structure and field co-locality not only enhances dense, semantic retrieval but also lexically anchored methods, due to sharper boundary alignment and greater lexical cohesion per chunk.
Practical and Theoretical Implications
The STC framework's preservation of structural boundaries fundamentally alters downstream retrieval and reasoning profiles. For practitioners, superior efficiency, recall, and precision directly translate to more scalable, faithful, and cost-effective RAG deployments—especially when ingesting data lakes or regulatory corpora dominated by tabular, semi-structured formats. On a theoretical axis, the findings reinforce the importance of chunk semantic coherence for both dense and sparse retrieval—highlighting that chunking is not a purely technical pre-processing detail but a critical axis for RAG system performance.
The architecture is agnostic to domain and applicable to a broad range of structured inputs, including but not limited to spreadsheets, logs, and database tables. By upholding row- and attribute-level relationships, it is poised to enable future RAG systems that handle rich, multi-relational data beyond traditional text.
Future Directions
Limitations of the evaluation include a fixed token budget and retrieval metrics grounded in heuristic, not human, relevance. Future research could explore adaptive token budgeting, extension to multi-relational joins and group-bys, and integration with end-to-end generation evaluation. Broader application across non-legal, more heterogeneously structured datasets would clarify generalizability. Additionally, coupling STC with domain-adapted retrievers or generation modules could further amplify its impact.
Conclusion
This work formalizes the need for structure-aware chunking in tabular RAG pipelines, introducing a Row Tree–based framework that yields dense, non-overlapping, and semantically faithful chunks. STC substantially improves both preprocessing efficiency and retrieval efficacy across multiple metrics and retrieval regimes. Its design principles—structural alignment, token-budgeted greedy merging, and field-preserving splitting—set a new standard for chunking strategies in structured document processing. The approach is likely to see rapid adoption as RAG use cases increasingly intersect with structured enterprise data.