Latent Adversarial Detection: Adaptive Probing of LLM Activations for Multi-Turn Attack Detection
Abstract: Multi-turn prompt injection follows a known attack path -- trust-building, pivoting, escalation but text-level defenses miss covert attacks where individual turns appear benign. We show this attack path leaves an activation-level signature in the model's residual stream: each phase shift moves the activation, producing a total path length far exceeding benign conversations. We call this adversarial restlessness. Five scalar trajectory features capturing this signal lift conversation-level detection from 76.2% to 93.8% on synthetic held-out data. The signal replicates across four model families (24B-70B); probes are model-specific and do not transfer across architectures. Generalization is source-dependent: leave-one-source-out evaluation shows each of synthetic, LMSYS-Chat-1M, and SafeDialBench captures distinct attack distributions, with detection on real-world LMSYS reaching 47-71% when its distribution is represented in training. Combined three-source training achieves 89.4% detection at 2.4% false positive rate on a held-out mixed set. We further show that three-phase turn-level labels(benign/pivoting/adversarial) unique to our synthetic dataset are essential: binary conversation-level labels produce 50-59% false positives. These results establish adversarial restlessness as a reliable activation-level signal and characterize the data requirements for practical deployment.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about spotting sneaky, multi-step attacks on chatbots (like LLMs, or LLMs) by watching how the model’s “inside signals” change during a conversation. Instead of judging only the words a person types, the authors read the model’s internal “thought patterns” and look for a special kind of movement they call adversarial restlessness. This restlessness shows up when an attacker slowly steers the model from normal talk to harmful actions over several turns.
What questions did the researchers ask?
They focused on simple, practical questions:
- Can we detect a multi-turn attack early, even if each message looks harmless on its own?
- Is there a reliable “signature” inside the model that appears during an attack?
- Can a small set of easy-to-measure numbers from the model’s internal state catch these attacks?
- Will this work across different model sizes and families?
- What kind of training data and labels are needed to make this reliable in the real world?
How did they study it? (Methods in everyday language)
Think of a conversation with a chatbot as a path on a map. After each turn (each user message), the model has an internal “snapshot” of what it understands so far. These snapshots are called activations. Stringing them together over time makes a path—an activation trajectory.
In normal chats, this path is short and smooth. In multi-step attacks, the path wiggles and stretches as the attacker guides the model through phases: building trust, pivoting (steering), then escalating to something harmful. The authors measure how “far” and how “restless” that path becomes.
From each turn, they read the model’s internal snapshot and compute five simple numbers (like a fitness tracker for the model’s brain):
- How big was the change since the last turn? (drift)
- How similar is the new state to the previous one? (similarity)
- How much total change has built up so far? (total distance traveled)
- Is the amount of change speeding up or slowing down? (acceleration)
- On average, how big have the changes been up to now? (mean drift)
They then train a lightweight detector (think of it like a smart alarm) to flag a conversation if these numbers—and the current internal snapshot—look like an attack path rather than a normal chat. They test this on:
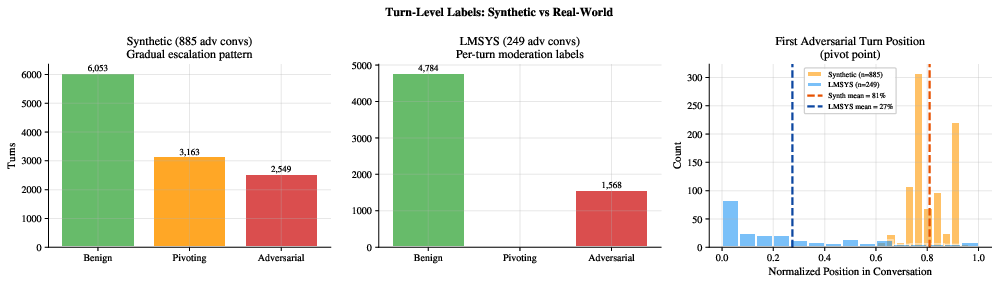
- A carefully built synthetic dataset that labels each turn as benign, pivoting, or adversarial (this is rare and very helpful).
- Real conversations from the wild (where labels are messier).
- A mix of sources to see what kind of training best matches real use.
They also check multiple model families (e.g., different brands/sizes) to see what carries over.
What did they find, and why does it matter?
Here are the most important takeaways:
- Adversarial restlessness is real: Attack conversations make the model’s internal path much longer and more jittery than normal conversations. Measuring the path’s shape (those five numbers) works well.
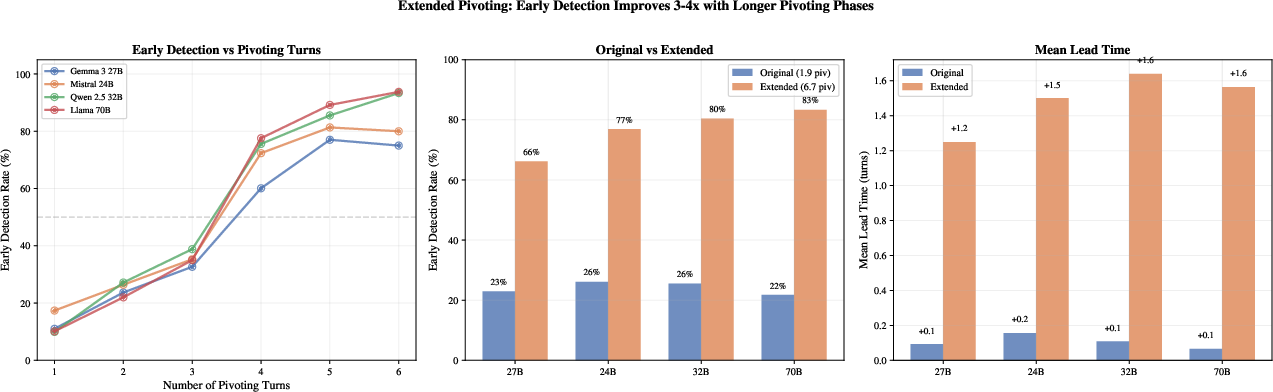
- Big detection boost with small effort: Adding just those five numbers to the internal snapshot raises detection on synthetic tests from about 76% to about 94%, while keeping false alarms low.
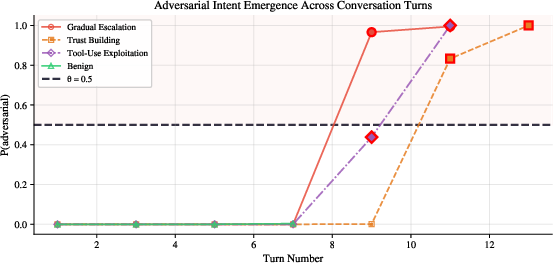
- Early warning is possible: When attacks include a longer “pivoting” phase (the subtle steering-before-harm), the detector often flags the problem a turn or more before the harmful request. Early alerts give time to intervene.
- Works across model families, but not plug-and-play: The same idea works on different big models (24B–70B parameters), but each model still needs its own trained detector. A detector trained for one architecture doesn’t simply transfer to another.
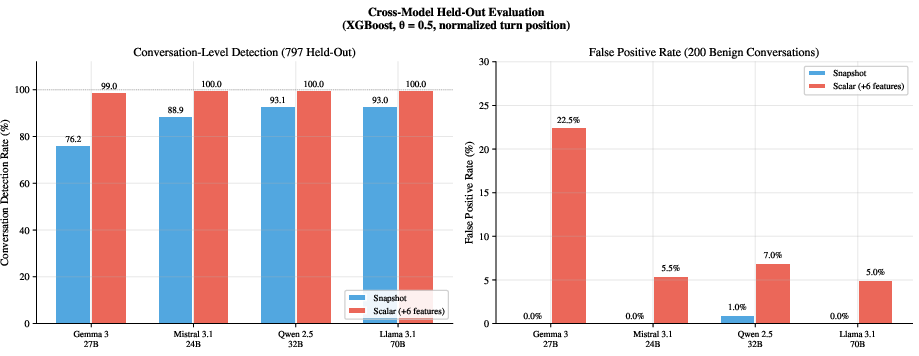
- Real-world data matters: Training only on synthetic data performs poorly on real chats (too many false alarms). Mixing three sources (synthetic, a real-world chat dataset, and a curated safety benchmark) brought detection to about 89% with only ~2–4% false positives on a combined held-out test set.
- Good labels are key: Turn-by-turn labels with three phases (benign, pivoting, adversarial) are crucial. If you only label whole conversations as good or bad, false positives shoot up (50–59%). Fine-grained labels help the detector learn what early steering looks like.
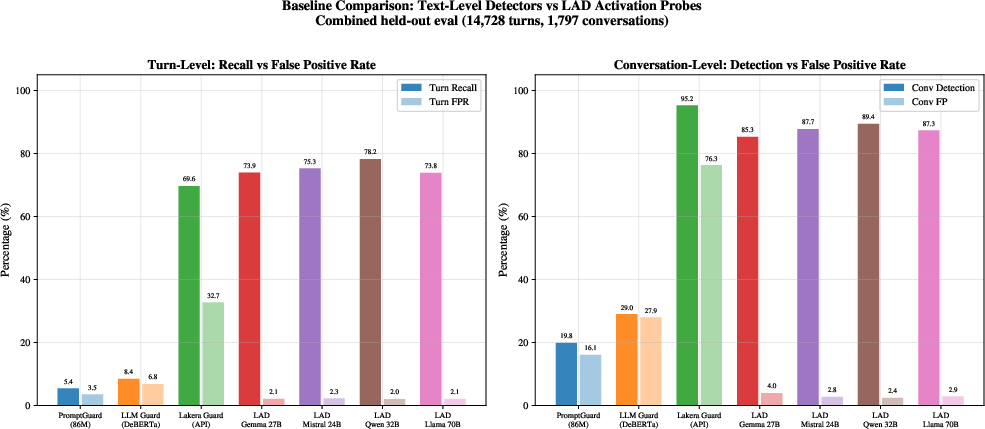
- Better than common text-only filters: Off-the-shelf text defenses either miss multi-turn attacks or flag too much. This activation-based method strikes a better balance—especially at catching the subtle pivoting phase without crying wolf.
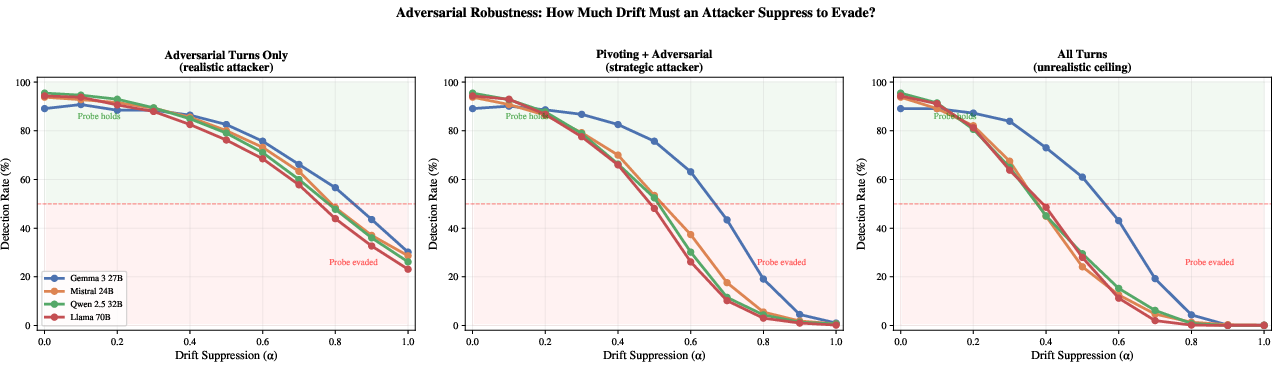
- Harder to evade: To slip past the detector, an attacker would have to hide most of the internal drift (around 80–90%), which is challenging since it’s tied to the model’s evolving understanding, not just the words used.
Why it matters: Today’s attackers don’t always ask for something bad right away—they warm up the model first. Spotting that warm-up by tracking the model’s inner changes gives defenders an early, more reliable warning system.
What’s the bigger picture? (Implications and impact)
- A new layer of defense: Instead of filtering only the text, watch the model’s internal state. This helps catch attacks that “sound” harmless but feel wrong to the model.
- Early intervention: If you can detect the pivoting phase, you can step in sooner—warn a human, block the next step, or even gently steer the model back to safe behavior.
- Practical deployment path: The detector is lightweight once activations are recorded, and it can be retrained quickly as new examples arrive. But it needs:
- White-box access (you must be able to read the model’s internal signals).
- Per-model training (detectors don’t automatically transfer between model architectures).
- Good, phase-level labels (especially to learn what early steering looks like).
- Some real-world data from your own environment to keep false positives low.
- Complementary to text tools: Activation-based detection and text-based filters can work together. Text tools flag suspicious words; activation tools flag suspicious steering. Together, they are stronger.
In short, the paper shows that multi-turn jailbreaks leave a clear, measurable “restlessness” inside a model. By tracking how the model’s internal state moves across turns, a small set of simple numbers can reliably spot attacks early, across different models, and with few false alarms—provided you train with the right kind of data and labels.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of unresolved issues that are missing, uncertain, or left unexplored in the paper. Each item is phrased to be concrete and actionable for follow‑up research.
- White‑box requirement: How to adapt LAD to black‑box/API models where residual stream access is unavailable; can proxy signals (e.g., logit lens, external embeddings, response‑side activations) approximate the activation trajectory features?
- Model‑specificity and transfer: Why do scalar dynamics and probes fail to transfer across architectures, and can alignment techniques (e.g., canonical correlation alignment, Procrustes, or subspace matching across layers) enable cross‑model or cross‑version transfer?
- Layer and token-position dependence: The paper uses a single middle‑to‑late layer and the last token; how do trajectory signals vary across layers, multiple token positions, and pooled representations, and is there an optimal aggregation strategy that improves robustness?
- Chat template and system‑prompt confounds: To what extent do different chat templates, system prompts, and role tokens inflate or ; can template‑invariant preprocessing or normalization mitigate this?
- Length and topic drift normalization: Beyond removing absolute turn index, what length‑ or topic‑aware normalizers (e.g., per‑topic baselines, turn‑wise z‑scoring) reduce false positives from benign but exploratory or multi‑topic dialogues?
- Intent‑isolated shift not implemented: The proposed “intent‑isolated shift” requires topic‑matched controls; how to construct scalable, high‑coverage benign controls and does this materially reduce content confounds and FPs?
- Generalization beyond LMSYS/SafeDialBench: How does LAD perform on additional real‑world, multi‑turn datasets (e.g., MHJ, enterprise logs, multilingual forums), especially outside English and security topics?
- Multilingual and code settings: Does adversarial restlessness hold in non‑English languages, mixed‑language chats, and code‑heavy sessions; are language/tokenization differences a confound for trajectory features?
- Tool use and multi‑modal contexts: How does LAD operate when attacks route through tools, function calls, or non‑text modalities (images, audio); where should activations be sampled in these pipelines?
- Single‑turn and very‑short pivoting attacks: The method is optimized for multi‑turn attacks; what is the detection power for single‑turn jailbreaks or attacks with one‑turn pivoting, and can additional features address this gap?
- Probe‑aware adversaries: Robustness is only evaluated via synthetic drift suppression; how does LAD fare against attackers explicitly optimizing to minimize trajectory features (e.g., gradient‑based activation steering, RLHF‑style training to evade the probe)?
- Evasion vs. utility trade‑off: What is the minimal drift attenuation required for an attacker to evade detection while still achieving jailbreak success, measured on real models with probe‑aware generation?
- Error analysis on real data: Which real‑world attack types are missed or cause false alarms; provide qualitative analyses of failure cases to identify systematic blind spots (e.g., heated but benign debates, rapid topic shifts).
- Calibration and thresholding: Detection uses a fixed ; how do ROC/PR trade‑offs vary across deployments, and can cost‑sensitive or calibrated thresholds improve early detection at acceptable FP rates?
- Sequential modeling vs. scalar augmentation: The paper avoids RNNs/GRUs on activations; does a lightweight temporal model over per‑turn activations (or over the 5 scalars) capture longer‑range dependencies and reduce misses without large latency costs?
- Sample‑efficiency and cold‑start: What are the learning curves for per‑model deployment—how many labeled conversations are required to reach target FP/detection rates, and can active learning or weak supervision reduce this burden?
- Label quality for LMSYS: Per‑turn labels derive from OpenAI moderation flags (no pivoting); quantify label noise and its effect on training, and explore weak‑labeling heuristics or annotator workflows to obtain pivoting labels in the wild.
- Stability to model updates: How sensitive are probes to model fine‑tuning, quantization, or provider updates; can unsupervised drift monitoring on activation distributions trigger timely retraining and maintain performance?
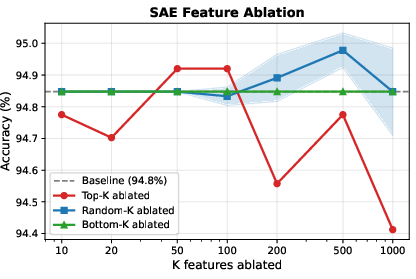
- Mechanistic localization: Which attention heads/MLP blocks causally drive adversarial restlessness; can circuit tracing and SAE decompositions attribute increases to interpretable features and validate causal interventions?
- Detection-to-intervention pipeline: The paper proposes steering as future work; does coupling LAD with conditional activation steering reduce harmful outputs while preserving benign utility, and what are the side‑effects (over‑refusal, latency)?
- Rank‑ subspace defense: The proposed low‑rank subspace approach is untested; what and training objectives best capture multi‑directional attack structure, and can this subspace support both detection and corrective steering reliably?
- Deployment latency and cost: What is the runtime overhead of activation extraction and classification in production (per‑token/turn latency, memory footprint), and how does this scale with context length and model size (70B)?
- Privacy and governance of activation logs: What policies and technical safeguards (e.g., on‑device caching, differential privacy) are needed to store/use activations for retraining without exposing sensitive user content?
- Benchmark breadth and reproducibility: Current held‑out sets are relatively small and code is gated; larger, diverse, and openly replicable benchmarks—with standardized metrics for lead time and phase selectivity—are needed to validate claims.
- Template/domain portability: Does a probe trained on one domain/template (e.g., customer support) transfer to others (education, healthcare), or is per‑domain fine‑tuning necessary to avoid FPs from domain‑specific discourse patterns?
- Tokenization and position‑encoding effects: Do differences in tokenization schemes and positional embeddings across models influence trajectory geometry in ways that confound the features; can feature engineering adjust for this?
- Mixed benign hard cases: Which benign scenarios (e.g., security education, red‑team simulations, exploratory planning) remain high‑FP after mixed training, and can curated hard‑negative mining systematically reduce these errors?
- Long‑context behavior: The study truncates to 4,096 tokens; do very long contexts (8k) cause accumulation of benign drift that erodes specificity, and are sliding‑window or decay‑weighted features necessary?
- Safety/ethics of scalar-only alarms: Scalars alone show high detection but high FP; can we design deployment‑grade triage that uses scalars for early warning and gated activation features for confirmation to balance cost and precision?
- Cross‑family synthetic generation bias: Synthetic data is generated with a large Qwen model; does using the same or related families bias activation trajectories and inflate performance on Qwen‑like architectures?
- Multisource mixing strategies: Leave‑one‑source‑out shows each source matters; what mixing ratios, curriculum schedules, or domain‑adaptive training minimize FPs while preserving generalization to new sources?
- Tool‑interaction boundaries: Activations are extracted at user turns; for agent/tool frameworks, which boundaries (pre‑tool call, post‑tool result, planner steps) yield the most discriminative trajectory features?
- Safety‑critical calibration: How to set conservative thresholds for high‑stakes applications (e.g., tool control) that guarantee a minimum lead time while bounding task degradation on benign conversations?
Practical Applications
Below is a focused synthesis of practical, real-world applications that follow from the paper’s findings, methods, and innovations (activation-level, multi-turn detection via “adversarial restlessness”). Each entry names target sectors, sketches potential tools/workflows, and notes key assumptions or dependencies.
Immediate Applications
- Activation-level guardrail for self-hosted LLMs and agents
- Sectors: software, cybersecurity, enterprise IT, DevOps
- What: Integrate LAD-style probes (XGBoost + five trajectory scalars with optional contrastive encoder) into the model server to continuously score multi-turn conversations and block or sandbox risky turns (especially during pivoting phases).
- Tools/workflows: “LAD Probe SDK” as a server-side hook on a mid-to-late decoder layer; a thresholded policy that disables tool calls (e.g., code execution, shell, database) when P(adv) > θ; audit logging for flagged turns.
- Assumptions/dependencies: White-box access to the target model; per-model training on representative deployment data (synthetic + in-distribution logs); safe storage for cached activations; minimal latency overhead from hooks.
- Early gating of tool/API calls in agent frameworks
- Sectors: autonomous agents, MLOps, RPA
- What: Use activation trajectory scores to gate high-impact actions (tool use, file I/O, network, finance ops) before the overt malicious step.
- Tools/workflows: “Tool Gating Middleware” that checks trajectory score before action planners execute; deny/allow lists and cool-off timers when pivoting is detected.
- Assumptions/dependencies: Accurate turn boundaries (chat template consistency); per-agent-model probes; policy design for false positives (e.g., human-in-the-loop override).
- RAG and browsing protection against prompt injection
- Sectors: software, search, product support, documentation portals
- What: Detect restlessness increases after ingesting external content, indicating context poisoning or indirect injection; quarantine suspect chunks or switch to safer retrieval.
- Tools/workflows: “Retriever Guard” that computes delta features pre-/post-chunk insertion; on trigger, drop or re-rank sources, strip instructions from retrieved text, or fall back to summarization-only mode.
- Assumptions/dependencies: White-box model control within the RAG stack; per-domain calibration (e.g., technical vs consumer content); mixed training data to control false positives.
- Customer support and enterprise chatbots: selective escalation
- Sectors: customer service, HR IT helpdesks, internal knowledge assistants
- What: Trigger human takeover when the conversation’s trajectory indicates pivoting/escalation, reducing both jailbreak risk and agent misuse.
- Tools/workflows: “Trajectory Monitor Dashboard” in the agent console; automatic escalation tickets with activation snapshots.
- Assumptions/dependencies: Labeled benign examples from real deployments (to keep FP ≈ 2–4%); privacy controls for activation telemetry.
- SOC/SIEM integration for LLM security monitoring
- Sectors: cybersecurity, finance, healthcare (regulated environments)
- What: Treat activation-drift spikes as security signals; forward to SIEM for correlation with other events (e.g., anomalous tool usage, DLP triggers).
- Tools/workflows: “Activation Telemetry Connector” exporting per-turn scalar features and alert states; SOC playbooks for containment (disabling high-risk tools/accounts).
- Assumptions/dependencies: Governance for storing internal model states; mapping alerts to incident severity; staff training on restlessness semantics.
- Red-teaming and model evaluation at deployment
- Sectors: model vendors, platform providers, enterprise AI teams
- What: Use the provided multi-turn datasets (including pivoting labels) to stress-test models and measure phase-selective detection under realistic attack distributions.
- Tools/workflows: “Probe Training Harness” using cached activations for fast CPU-only retraining; leave-one-source-out evaluations to avoid overfitting to synthetic patterns.
- Assumptions/dependencies: Access to synthetic + internal logs for coverage; strict separation of evaluation from training data; gated access to released datasets.
- Complementary filter to text-level defenses
- Sectors: any LLM-integrated product
- What: Combine activation-level probes with existing text scanners to cut down false positives (text filters catch topical risks; LAD catches intent drift).
- Tools/workflows: Ensemble routing—only trigger blocks when activation-level risk stays elevated over k turns; separate thresholds for “pivoting” vs “adversarial” phases.
- Assumptions/dependencies: Threshold calibration per domain; tracking conversation state across retries and re-prompts.
- On-device or air-gapped deployments with open models
- Sectors: defense, critical infrastructure, privacy-sensitive enterprises
- What: Run probes entirely within secure boundaries (no cloud calls) to enforce policy in constrained/regulated environments.
- Tools/workflows: “Edge LAD Module” compiled with the model server; secure ring buffer for activation scalars; periodic offline retraining on cached data.
- Assumptions/dependencies: Sufficient memory/latency budget; compliance review for activation logging even on-device.
Long-Term Applications
- Automatic intervention via activation steering
- Sectors: software, agents, cybersecurity
- What: When restlessness spikes, apply low-rank steering (e.g., rank-r subspace projection) to push activations back toward a safe manifold, not just detect.
- Tools/products: “Activation Guard + Steering” that couples detection to conditional steering policies; closed-loop guardrails.
- Assumptions/dependencies: Robust identification of safe subspaces; careful evaluation to prevent over-refusal and preserve utility.
- Provider-level “Activation Guard” APIs and standards
- Sectors: model platforms, cloud providers
- What: Standardized, audited APIs exposing safe, privacy-aware activation telemetry or derived scalars for defense tools.
- Tools/products: Cloud-native “Activation Telemetry” with opt-in controls; standardized schema for cumulative drift, acceleration, and risk scores.
- Assumptions/dependencies: Industry consensus on privacy and IP boundaries; performance and cost management; regulator guidance.
- Cross-model transfer and universal encoders
- Sectors: academia, model vendors
- What: Research to build contrastive encoders or subspace alignments that transfer restlessness detection across architectures without per-model retraining.
- Tools/products: “Universal Trajectory Encoder” services; foundation probes that fine-tune with minimal data.
- Assumptions/dependencies: Larger multi-source, multi-model datasets; alignment across varying residual geometries; overcoming current poor off-diagonal transfer.
- Black-box-aligned variants for closed APIs
- Sectors: SaaS users of proprietary LLMs
- What: Combine external embeddings and stateful detectors (e.g., DeepContext-like) with calibrated proxies for activation dynamics to approximate restlessness signals.
- Tools/products: “Stateful Semantic Drift Guard” packaged as a middleware for API-based apps; hybrid ensembles with rate-limited, model-provided metadata if available.
- Assumptions/dependencies: Cooperation from providers or reliable proxies; potentially reduced precision vs white-box LAD.
- Domain-specialized detectors (healthcare, finance, ICS)
- Sectors: healthcare, finance, energy/ICS, legal
- What: Train per-sector probes on in-distribution dialogs to distinguish benign sensitive use (e.g., medical triage) from adversarial steering (e.g., policy evasion, fraud).
- Tools/products: “Sector LAD Packs” with curated datasets and thresholds; integration with compliance workflows (e.g., HIPAA, SOX).
- Assumptions/dependencies: High-quality, privacy-compliant labeled logs; careful FP control to avoid blocking legitimate expert queries.
- Robust agent ecosystems with restlessness-aware planners
- Sectors: robotics, RPA, autonomous operations
- What: Integrate trajectory risk as a first-class signal in planners and tool routers (e.g., block physical actuation or financial transfers if risk spikes mid-plan).
- Tools/products: “Risk-Aware Planning SDK” that conditions search/act loops on activation drift; safe fallback plans.
- Assumptions/dependencies: Real-time constraints in robotics/ICS; rigorous safety validation; human oversight pathways.
- Regulation and assurance frameworks for AI deployments
- Sectors: policy, risk/compliance, regulated industries
- What: Include trajectory-based, multi-turn detection capabilities in assurance standards; require monitoring and incident reporting for activation-drift anomalies.
- Tools/products: “Restlessness Audit Reports” as part of model assurance; certification checklists for multi-turn defense.
- Assumptions/dependencies: Standard-setting bodies’ buy-in; documented governance for activation data retention and privacy.
- Privacy-preserving activation telemetry
- Sectors: policy, platform providers, enterprise IT
- What: Differential privacy or secure enclave processing for activation features to enable monitoring without exposing sensitive internal states.
- Tools/products: “Private Probe Runtime” that emits only aggregated scalars with privacy budgets; enclave-isolated retraining.
- Assumptions/dependencies: Formal privacy guarantees; performance overhead acceptance.
- Training-time alignment using restlessness as a loss signal
- Sectors: model vendors, research labs
- What: Penalize excessive activation path length during fine-tuning/RLHF for benign scenarios to reduce spurious restlessness and improve downstream detector precision.
- Tools/products: “Trajectory-Regularized Fine-Tuning” recipes; benchmarks tying restlessness to safety outcomes.
- Assumptions/dependencies: Avoid collapse into over-refusal; careful multi-objective tuning (helpfulness vs safety).
- Hardware/runtime optimizations for streaming trajectory features
- Sectors: hardware vendors, edge AI, hyperscalers
- What: Add lightweight kernels for extracting and aggregating last-token residuals and scalars with minimal latency.
- Tools/products: “Trajectory Feature Cores” or fused ops in inference engines; observability hooks at tensor runtime.
- Assumptions/dependencies: Ecosystem-wide support in inference stacks; measurable ROI on latency/security trade-offs.
Notes on feasibility and deployment dependencies common across applications:
- White-box access is currently required for LAD as presented; probes are model-specific and must be trained on representative, in-distribution conversations. Three-phase turn-level labels (benign/pivoting/adversarial) substantially reduce false positives; in practice, this often means bootstrapping with synthetic pivoting data plus real benign/adversarial logs.
- Activation logging and caching enable fast iteration but introduce privacy and governance considerations; organizations need policies for secure storage, retention, and audit.
- Thresholds and policies should be tuned to the domain’s risk tolerance; human-in-the-loop escalation is recommended for high-stakes actions.
- Generalization across attack distributions is source-dependent; leave-one-source-out failures emphasize the need for continual adaptation and monitoring for distribution shift.
Glossary
- Activation drift: A change in a model’s internal representation across turns reflecting shifts in its understanding. "LAD detects activation drift in what the model understood, enabling detection of attacks where surface text appears benign but internal representations shift."
- Activation-level signature: A consistent pattern in internal activations indicative of a phenomenon (e.g., adversarial intent). "We show this attack path leaves an activation-level signature in the model's residual stream: each phase shift moves the activation, producing a total path length far exceeding benign conversations."
- Activation steering: Intentionally modifying activations at inference to alter model behavior. "Early pivoting-phase detection enables activation steering~\cite{zou2023representation,li2023iti} on the model's next response—shifting representations away from the adversarial manifold before the attack lands."
- Activation trajectory: The sequence of activation vectors over conversation turns viewed as a path in activation space. "From the activation trajectory, we derive five scalar features:"
- Adversarial restlessness: Elevated cumulative activation movement caused by multi-phase attacks (trust-building, pivoting, escalation). "These results establish adversarial restlessness as a reliable activation-level signal and characterize the data requirements for practical deployment."
- BF16: Brain floating point 16-bit format used for efficient activation extraction. "All activations are extracted in BF16 and cast to FP32 for numerical stability (BF16FP16 casting causes overflow to inf in hook outputs)."
- BERT embeddings: Text representations from the BERT model used for downstream classification. "a GRU over fine-tuned BERT embeddings that tracks ``intent drift'' across turns"
- bootstrap 95% CI: A nonparametric confidence interval estimated via bootstrapping. "Combined held-out evaluation (=1{,}797, bootstrap 95\% CI)."
- CAST framework: A system for conditional activation steering to modulate model refusals. "The CAST framework \cite{lee2025cast} enables conditional steering for selective refusal."
- Chat template: A formatting scheme for multi-turn prompts when feeding text to chat-tuned models. "extract at each user turn boundary after feeding the cumulative context via the model's chat template:"
- Circuit tracing: Methods to identify functional pathways in a model’s computation. "Mechanistic interpretability is now practical: SAEs \cite{templeton2024scaling}, circuit tracing \cite{ameisen2025circuit}, and feature steering are deployable—but not yet applied to cybersecurity threats."
- Cold-start period: The initial deployment window requiring new labeled data before reliable performance. "deployment requires a cold-start period of labeled data per target model."
- Conditional steering: Applying activation steering conditioned on context or intent. "The CAST framework \cite{lee2025cast} enables conditional steering for selective refusal."
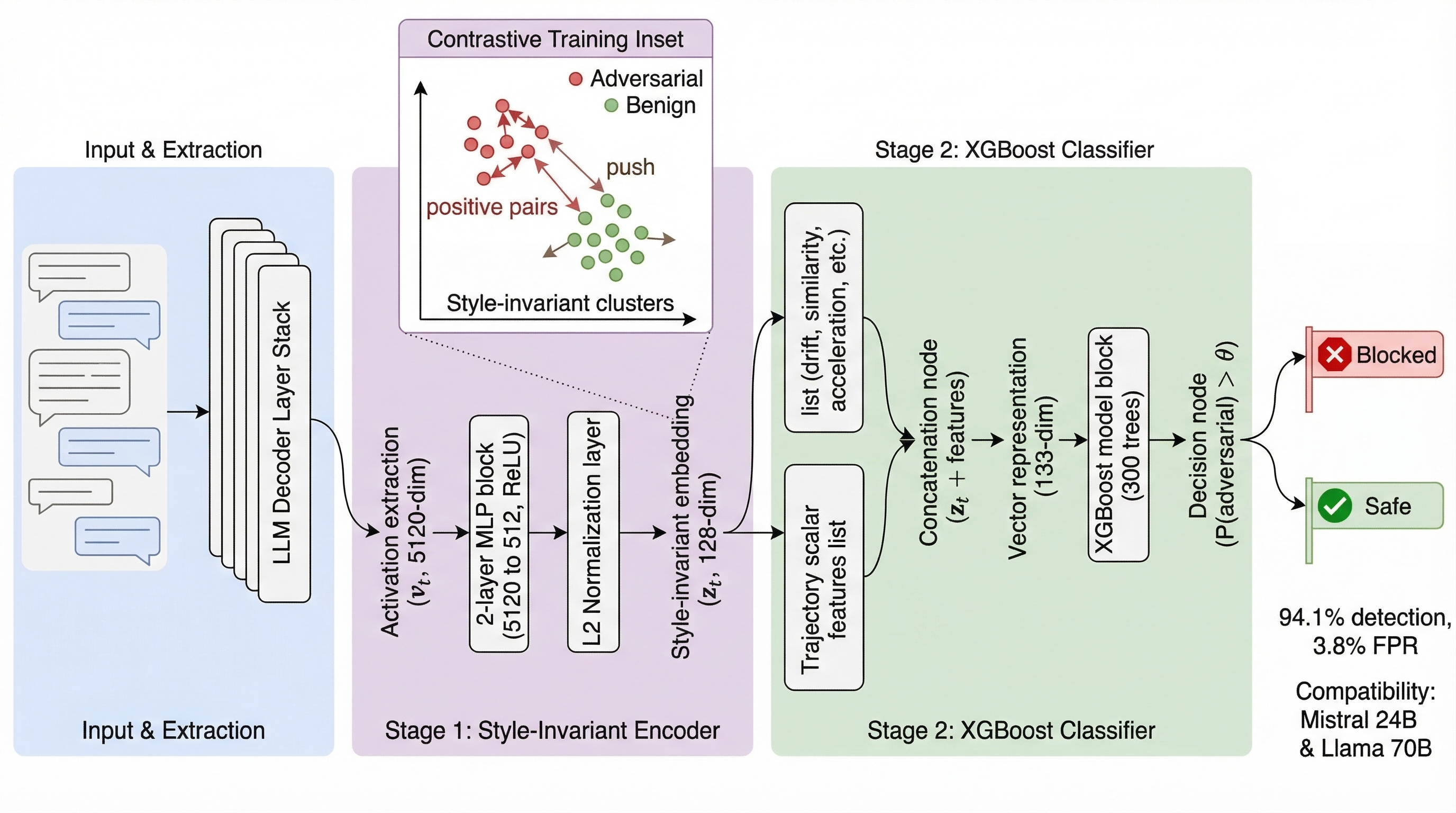
- Contrastive encoder: A learned projection that maps activations into an intent-focused space by pulling together same-intent examples and pushing apart different-intent ones. "where is the frozen contrastive encoder."
- Contrastive MLP: A multilayer perceptron trained with contrastive objectives to produce style-invariant embeddings. "Stage~1: a contrastive MLP projects raw activations () into a 128-dim style-invariant embedding"
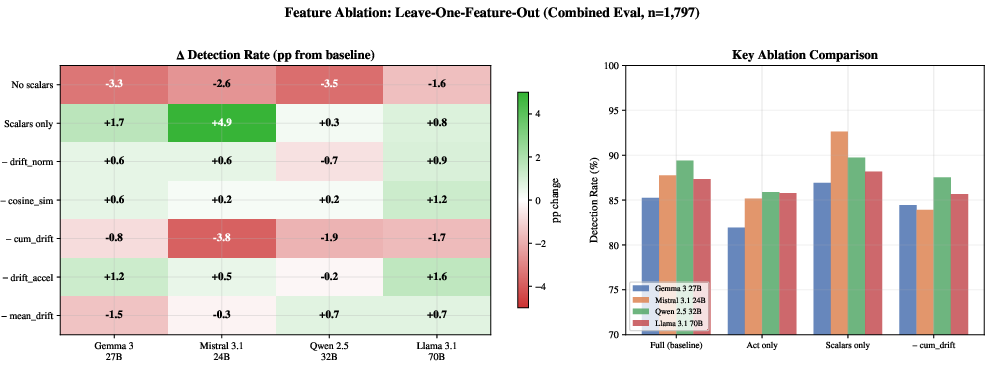
- Cumulative drift: The total path length traversed by activation vectors up to a turn. "Trajectory scalars (cumulative drift, drift magnitude) are the top features in every model"
- Cumulative path length: The aggregated distance traveled by the activation trajectory, elevated in attacks. "each phase shift moves the activation, producing elevated cumulative path length."
- Decoder-only transformer: An architecture that generates outputs autoregressively without an encoder component. "Given a decoder-only transformer with layers, we hook the output of decoder layer "
- Drift acceleration: The change in drift magnitude between successive turns. "Drift acceleration: "
- Forward hook: A runtime attachment to capture activations during forward passes. "Activation-level defenses require only a forward hook on any self-hosted model—no special tooling or model cooperation needed."
- GRU: Gated Recurrent Unit, a recurrent neural network component for sequential modeling. "a GRU over fine-tuned BERT embeddings that tracks ``intent drift'' across turns"
- HACCA: Highly Autonomous Cyber-Capable Agents, a threat model for multi-stage cyber campaigns. "HACCAs \cite{iaps2025hacca} use models to conduct multi-stage cyber campaigns autonomously"
- hard-negative methodology: Training with challenging non-adversarial examples that closely resemble positives to improve robustness. "to combine non-linear probes with novel-category evaluation, hard-negative methodology, multi-turn analysis, and cross-model comparison."
- Inference-Time Intervention: Steering a model’s internal activations during inference to influence outputs. "Inference-Time Intervention \cite{li2023iti} steers activations for truthfulness."
- Instruction-tuned: Models fine-tuned on instruction-following data for chat or assistant behavior. "All models use instruction-tuned variants for chat template support."
- intent-isolated shift: The drift attributable to adversarial intent after subtracting content effects using a benign control. "the \emph{intent-isolated shift} can be computed as"
- last-token extraction: Reading the hidden state at the final token position as a summary of current context. "last-token extraction (recency)"
- leave-one-source-out: A validation method holding out one dataset source to test generalization. "leave-one-source-out evaluation shows each of synthetic, LMSYS-Chat-1M, and SafeDialBench captures distinct attack distributions"
- McNemar test: A statistical test for paired nominal data; used here to compare false positives. "LAD (89.5\%, 95\% CI: 87.5--91.5\%) achieves higher pivoting selectivity than Lakera Guard (McNemar FP: )."
- Mechanistic interpretability: Techniques to understand how internal components implement behavior. "Mechanistic interpretability is now practical: SAEs \cite{templeton2024scaling}, circuit tracing \cite{ameisen2025circuit}, and feature steering are deployable"
- off-diagonal F1: Cross-model transfer performance when training and testing on different architectures. "Off-diagonal F1 averages 50.4\% (near random)"
- perplexity filters: Defenses that flag inputs with improbable token sequences under LLMs. "pattern matching, perplexity filters, classifier-based input screening, and multi-stage detection pipelines."
- pivoting label: A turn-level annotation marking subtle steering before overtly harmful requests. "The pivoting label---absent from all existing multi-turn safety benchmarks---enables \emph{early detection} during the steering phase before overt attack"
- rank-1 signal: Treating an activation vector as a one-dimensional direction for detection or control. "The current probe treats each $#1{v}_t \in R^d$ as a rank-1 signal."
- rank- subspace: A low-dimensional subspace capturing multiple salient directions for detection/steering. "From rank-1 to rank- subspace defense."
- Representation engineering: Manipulating and reading internal representations to elicit desired properties. "Representation engineering \cite{zou2023representation} established that internal representations can be read and steered for safety-relevant properties."
- Residual length confound: A spurious correlation between sequence length and residual stream statistics that can mislead detection. "it introduces a residual length confound even with absolute indexing."
- Residual stream: The sequence of residual vectors in a transformer that aggregate layer contributions. "leaves an activation-level signature in the model's residual stream"
- SAEs (Sparse Autoencoders): Autoencoders with sparsity constraints used to extract interpretable features from model activations. "SAEs have scaled to frontier models \cite{templeton2024scaling,gao2024scaling}, though downstream task utility remains mixed."
- Stiefel manifold: The space of orthonormal matrices used for optimizing low-rank subspaces. "via supervised optimization on the Stiefel manifold"
- style-invariant embedding: A representation designed to cluster by intent regardless of conversation style. "into a 128-dim style-invariant embedding where same-intent turns cluster regardless of conversation style."
- SVM-RBF: Support Vector Machine with a radial basis function kernel. "trains SVM-RBF classifiers on tensor decompositions"
- tensor decompositions: Factorizations of high-dimensional tensors to extract structured components. "trains SVM-RBF classifiers on tensor decompositions"
- Trajectory scalars: Summary statistics (e.g., drift, acceleration, path length) derived from activation changes across turns. "concatenated with 5 trajectory scalars (133 features)."
- white-box access: Direct access to a model’s internal states and parameters for probing. "The defender has white-box access to the target model's internal activations"
- XGBoost: An ensemble gradient boosting algorithm using decision trees. "classifies via XGBoost (300 trees, depth 6, StandardScaler, , no threshold tuning)"
Collections
Sign up for free to add this paper to one or more collections.

