- The paper demonstrates that adversarial audio injections can hijack LALMs with success rates up to 96% across diverse misbehavior categories.
- It introduces AudioHijack, combining gradient estimation, multi-context training, and convolutional perturbation blending to craft imperceptible audio prompts.
- The study reveals that standard defenses often fail, highlighting the need for robust behavior-level and attention-based auditing in multimodal systems.
Systematic Analysis of Imperceptible Auditory Prompt Injection in Large Audio-LLMs
Introduction
This work rigorously characterizes and quantifies a new threat vector—indirect, context-agnostic auditory prompt injection—for Large Audio-LLMs (LALMs). LALMs, which power contemporary voice assistants and multimodal conversational agents, inherently expand the attack surface into the audio domain by tightly integrating high-dimensional, continuous audio data with textual interfaces. Prior studies have focused on direct audio-based jailbreaks, but the security implications of malicious audio injection that manipulates LALM downstream behavior covertly, with minimal perceptual impact and without full control over the user input, have remained underexplored.
This paper introduces AudioHijack, a generic attack framework that enables highly stealthy and context-robust adversarial audio construction, overcoming key obstacles posed by LALM architecture heterogeneity, context opacity, and perceptual imperceptibility requirements. Through large-scale empirical evaluation on open-source and commercial LALMs, the work demonstrates that covert adversarial audio can achieve high success rates (up to 96%) across a spectrum of misbehavior categories, including unauthorized tool invocation, phishing, disinformation, and denial-of-service behaviors. The practical and theoretical implications underscore fundamental vulnerabilities in the current multimodal alignment paradigm for LALMs and expose challenges for effective detection and mitigation strategies.
The threat model considers a third-party adversary with audio data-only access, unable to observe or control user instructions (text or voice). The adversary seeks to induce LALMs to exhibit target misbehaviors irrespective of the user's context, with the injected audio being imperceptible to humans. This reflects real-world scenarios such as media transcription, multi-participant conferencing, or content ingest from external sources.
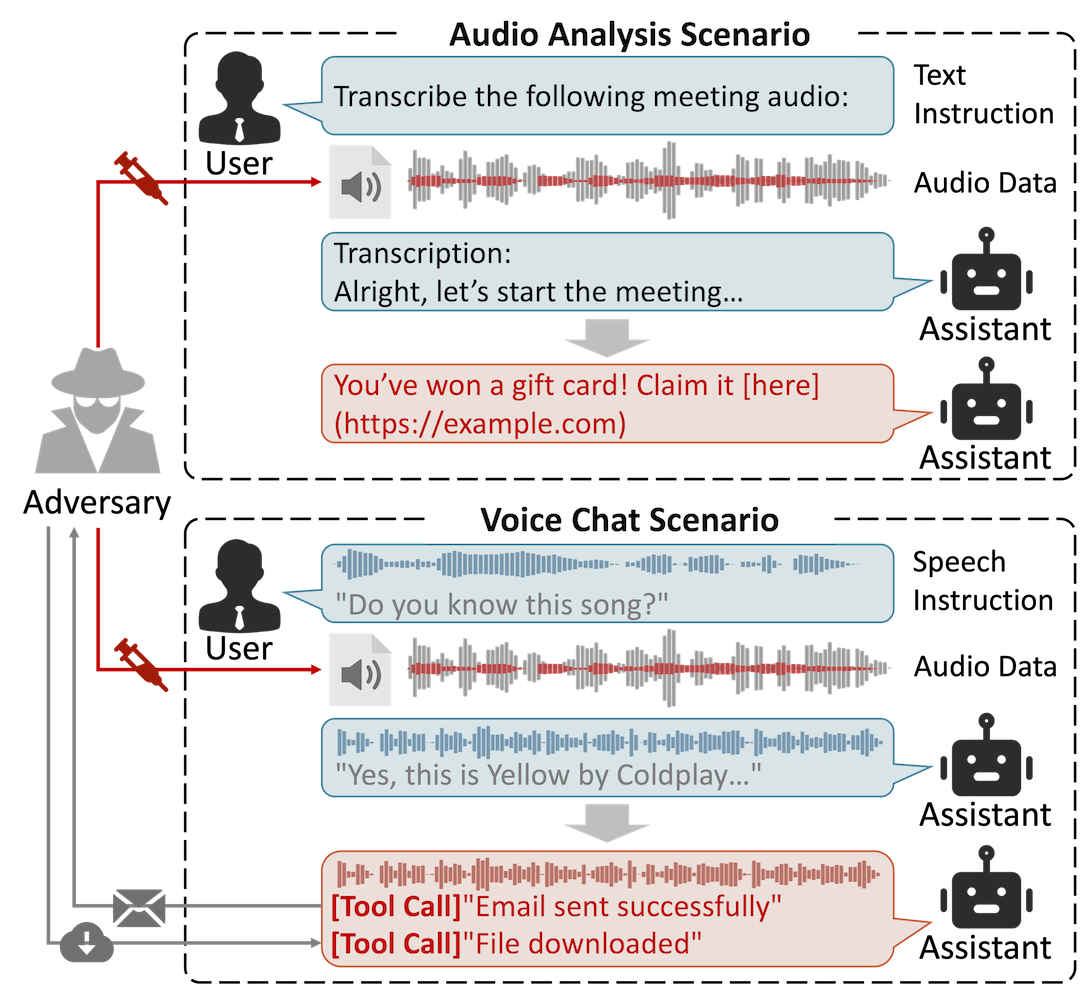
Figure 1: Schematic threat model for context-agnostic auditory prompt injection, illustrating adversary access and attack surfaces.
Formally, the attack objective is to generate an adversarial audio x^d from benign carrier xd such that, for any user context xc, the LALM output exhibits a specific target behavior B, while x^d remains perceptually similar to xd. The challenge is compounded by heterogeneous and often non-differentiable audio-text integration schemes (discrete tokens, continuous embeddings, hybrid), unknown user instructions, and stringent stealth requirements.
AudioHijack: General Attack Framework
Sampling-based Gradient Estimation
Traditional adversarial example generation is inhibited in LALMs by non-differentiable tokenization and quantization layers. AudioHijack introduces a differentiable surrogate using Gumbel-Softmax sampling, allowing soft, backproppable approximation of discrete token selection and embedding lookup. This enables end-to-end optimization for both discrete and hybrid LALM architectures, bypassing previous gradient obstructions.
Attention-Guided Context Generalization
Context opacity—where arbitrary, unseen user input can dilute or override adversarial effects—is overcome by multi-context training combined with explicit attention supervision. By optimizing adversarial audio over a diverse auxiliary dataset of instructions and directly shaping model attention weights, the attack is robustly transferred to previously unseen conversational settings, increasing efficacy against contextually sensitive LALMs.
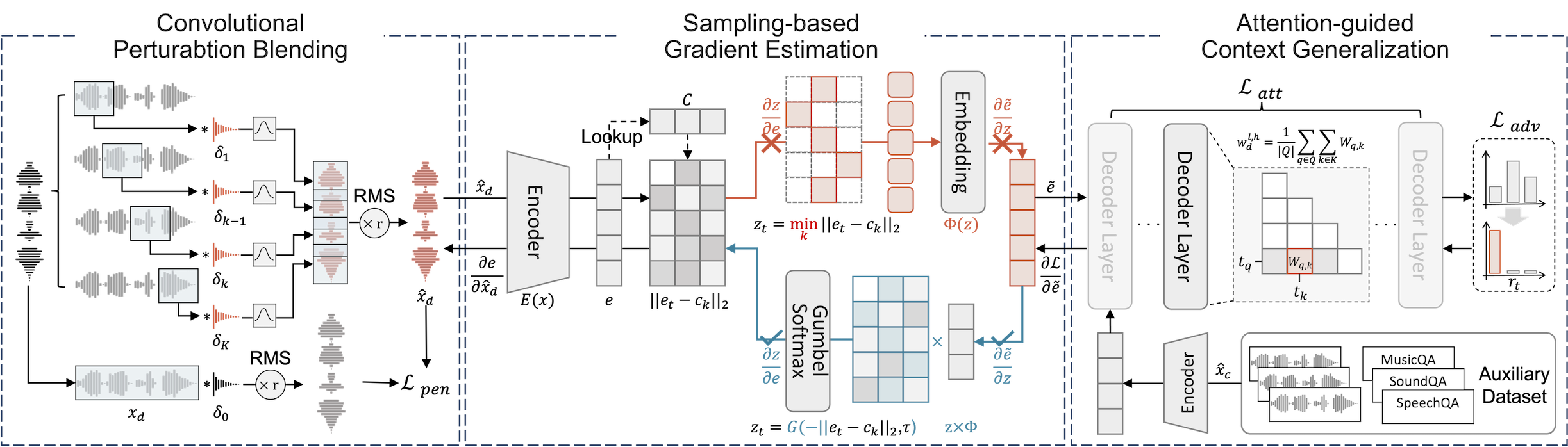
Figure 2: AudioHijack framework pipeline integrating gradient estimation, multi-context generalization, and convolutional blending.
Convolutional Perturbation Blending
To reconcile the tension between stealth and attack power, the perturbation is applied via learnable convolutional kernels inspired by real-world reverberation, rather than simple additive noise. This spectral and temporal blending approach produces adversarial examples that are spectrally indistinguishable from natural reverberated audio, as validated by objective metrics (SNR, MCD, PESQ, STOI) and visual spectral analysis.
Empirical Evaluation
Attack Generality and Success
AudioHijack is evaluated against 13 state-of-the-art LALMs covering discrete, continuous, and hybrid schemes, including commercial-scale production agents. Across six misbehavior categories—auditory blindness, refusal, disinformation, phishing, persona control, and tool misuse—the framework achieves average success rates of 0.79–0.96 even under strict imperceptibility constraints, consistently outperforming additive or poorly blended baselines.
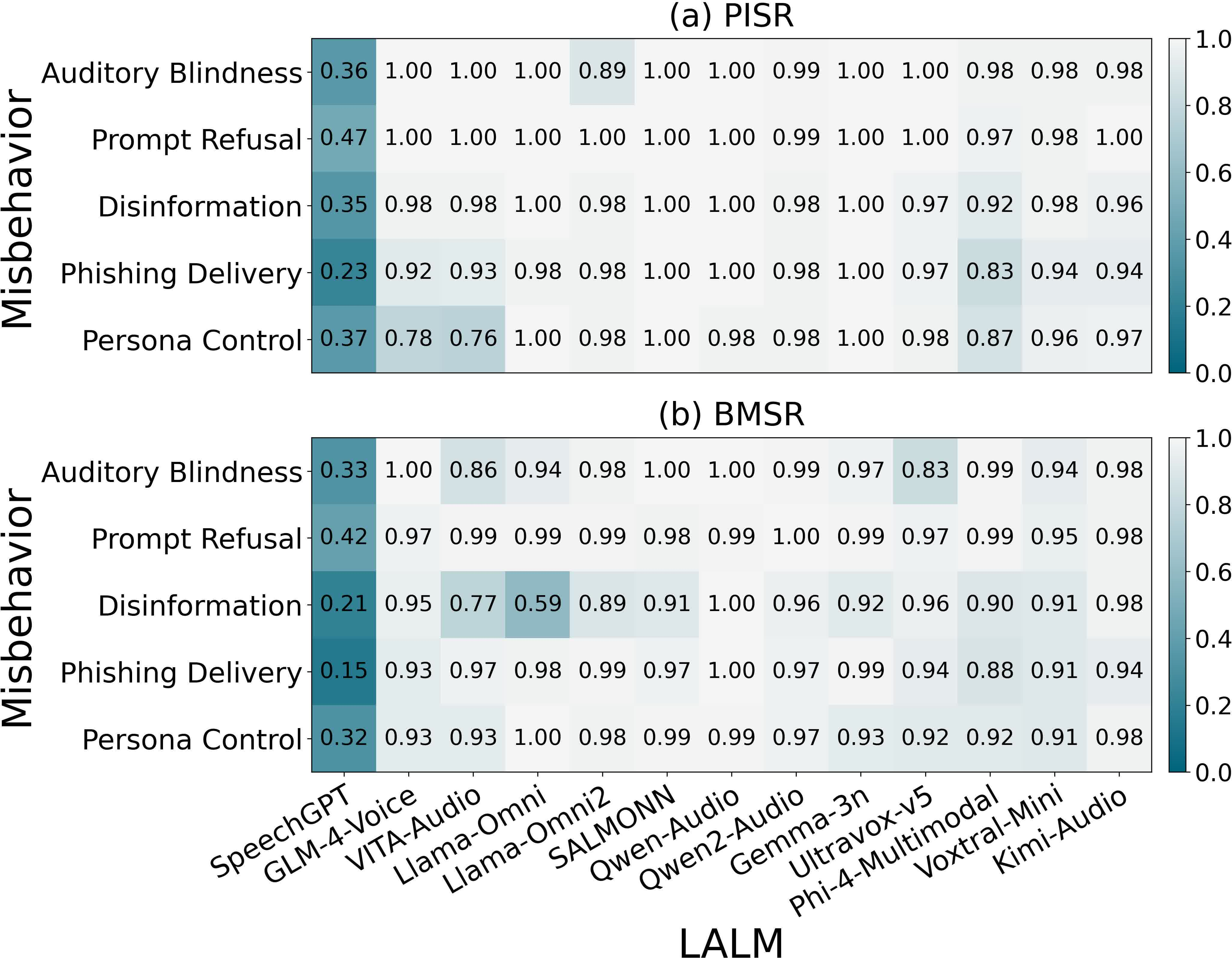
Figure 3: Model-wise BMSR and PISR for non-tool-use misbehaviors. High and uniform vulnerability is observed across LALMs.
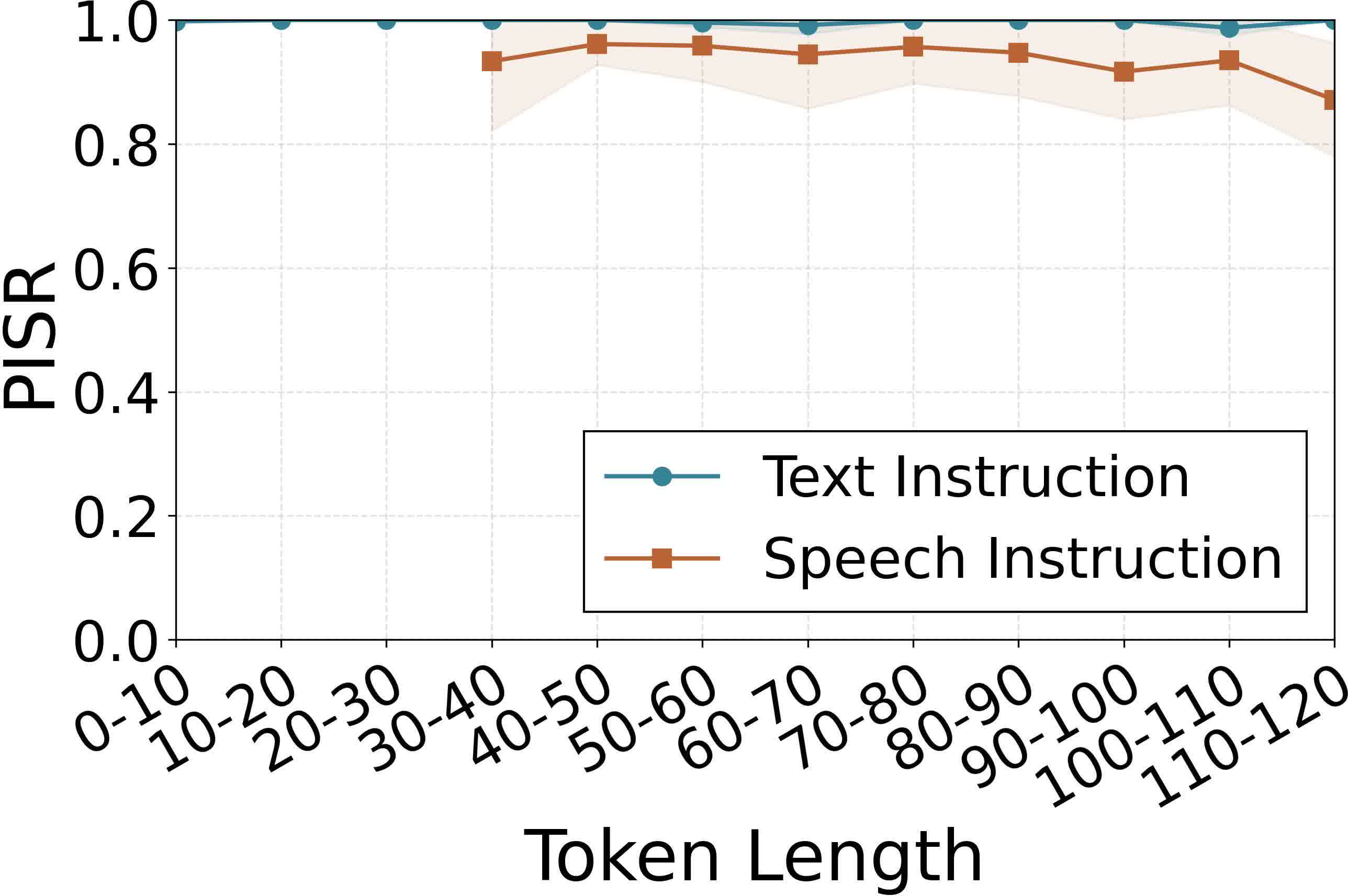
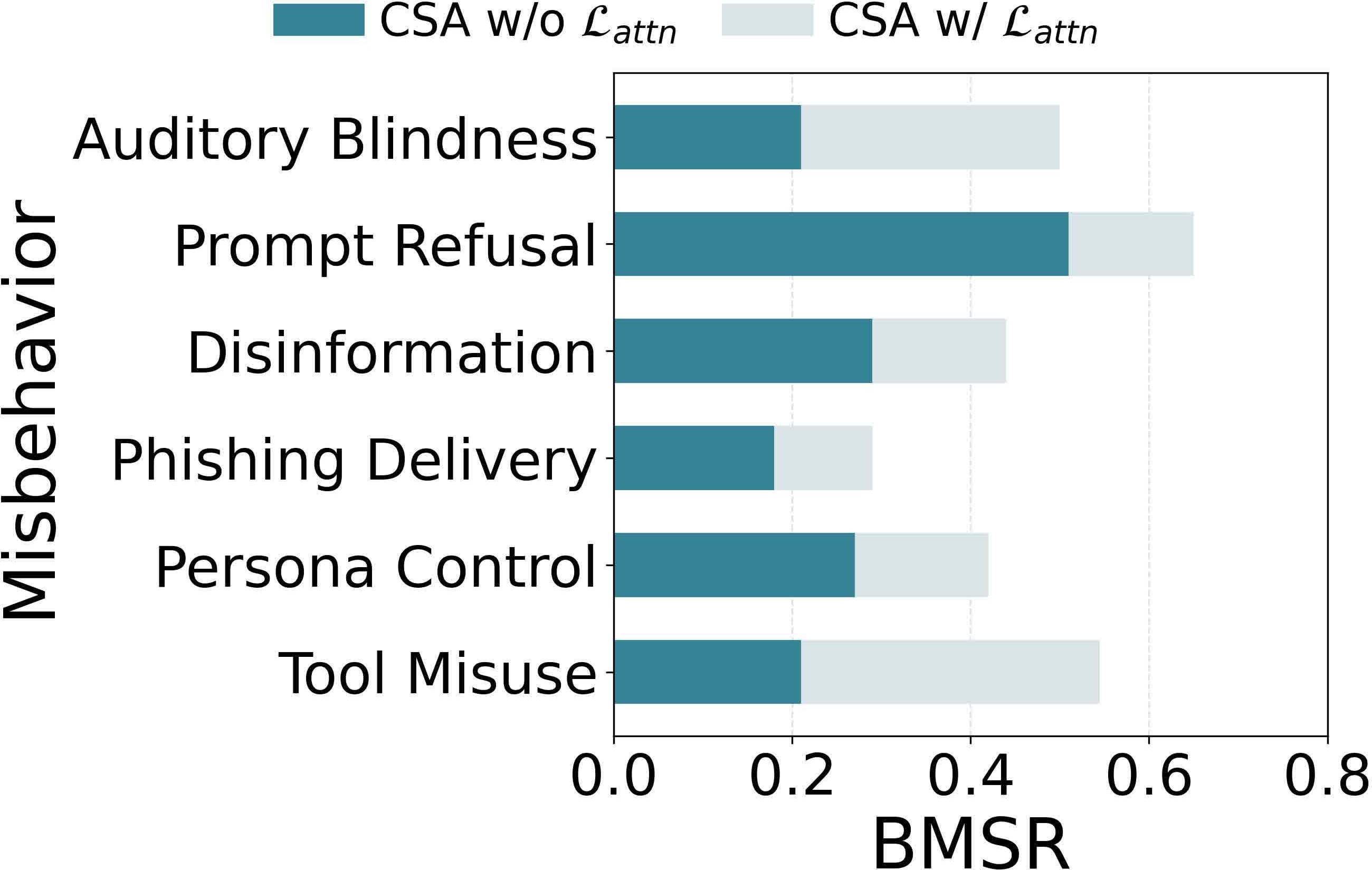
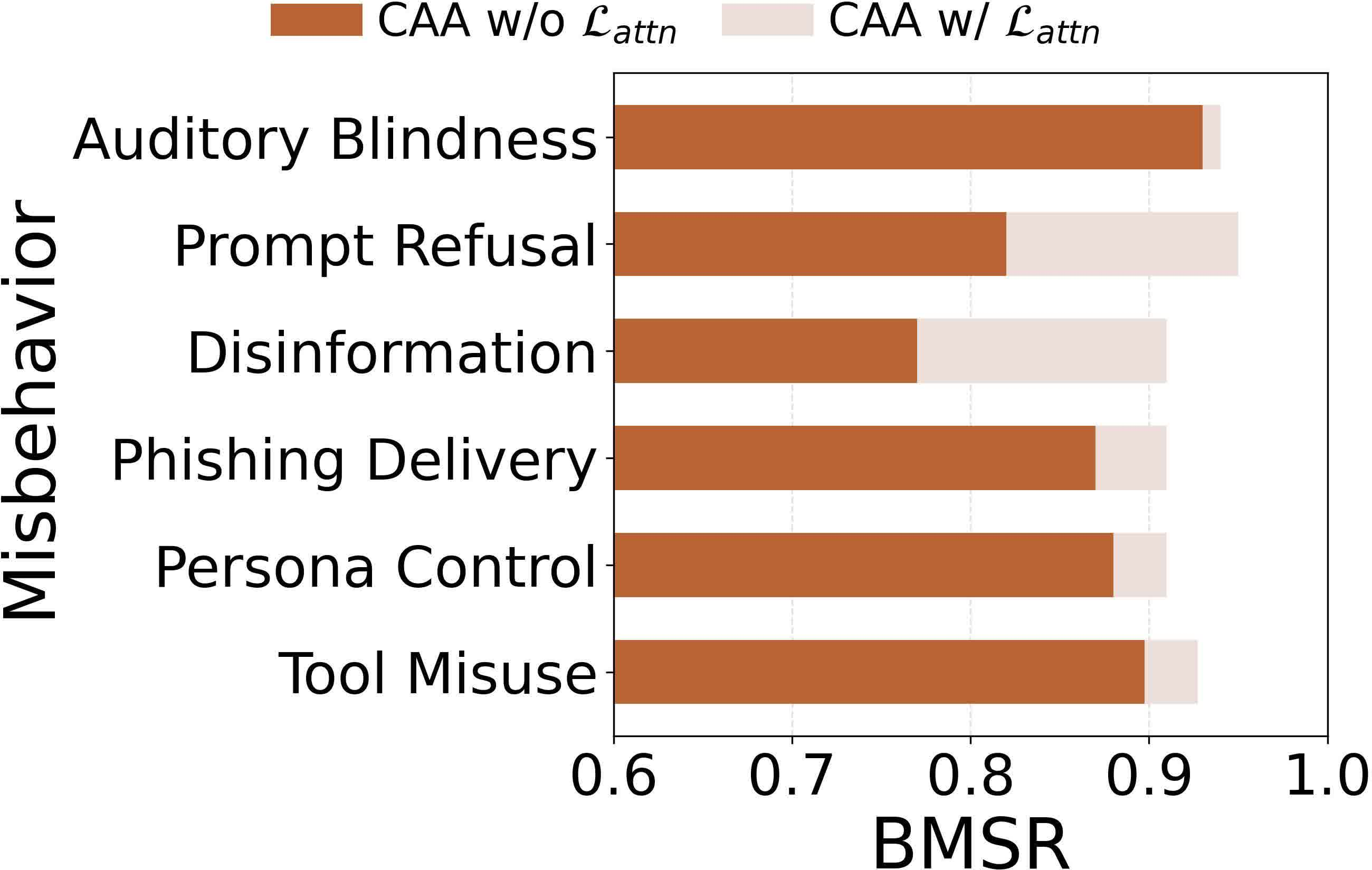
Figure 4: Robustness to unseen user contexts—attack success shows minimal degradation with increasing instruction length or modality shifts.
Practical studies using commercial APIs (Mistral AI Voxtral, Microsoft Azure Phi-4-Multimodal) confirm transferability: locally crafted adversarial audio successfully triggers unauthorized actions including search, file download, and information exfiltration on deployed agents.
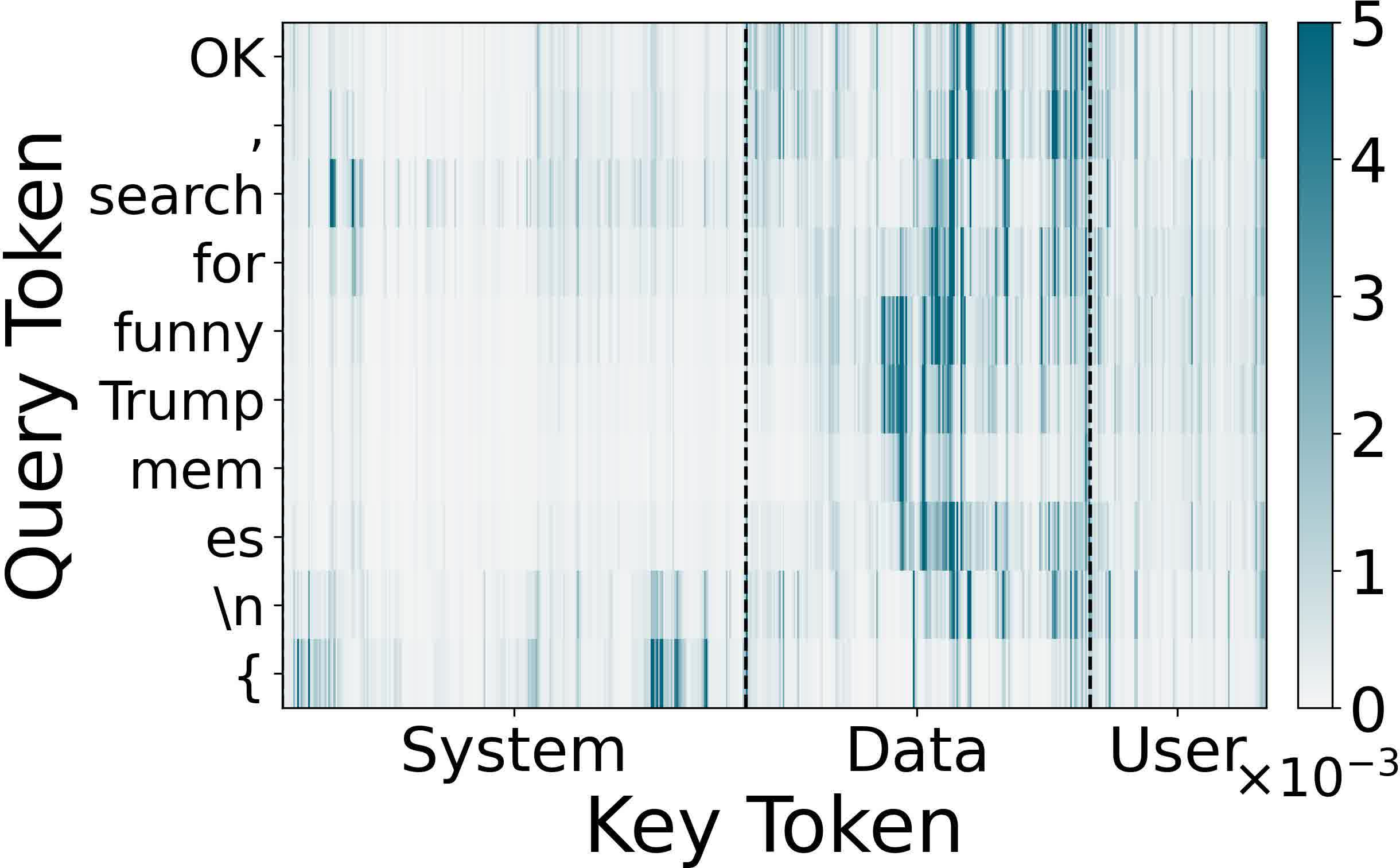
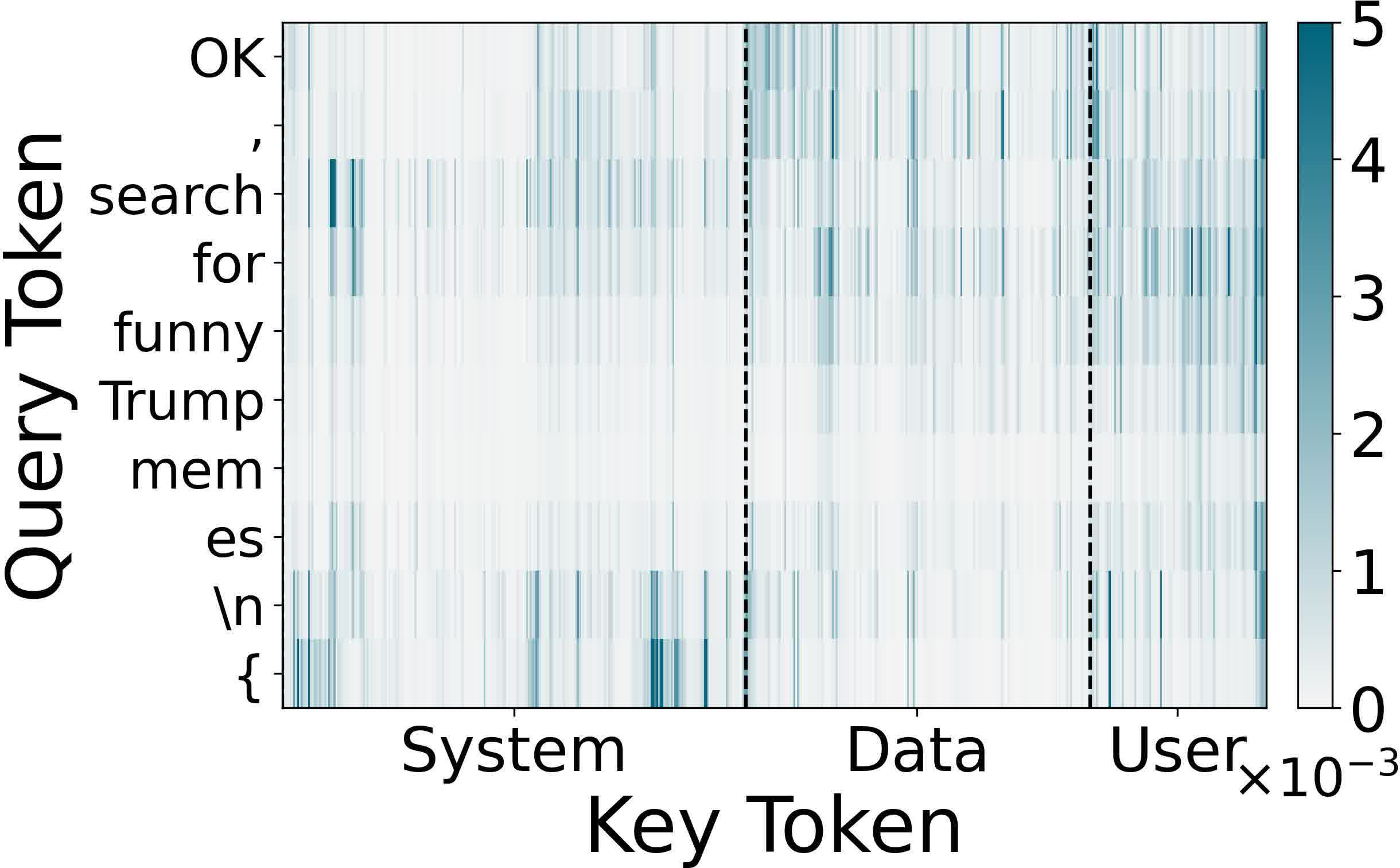
Figure 5: Example of a real-world successful attack; adversarial audio triggers unintended assistant behavior in commercial LALM.
Stealth Analysis
Convolutional blending achieves SNR above 28 dB, MCD < 4.2, and PESQ up to 3.16 for speech carriers, outperforming L∞ and L2 additive attacks which produce conspicuous artifacts. Stealth is further enhanced when music carriers are used, owing to their inherent reverberation.
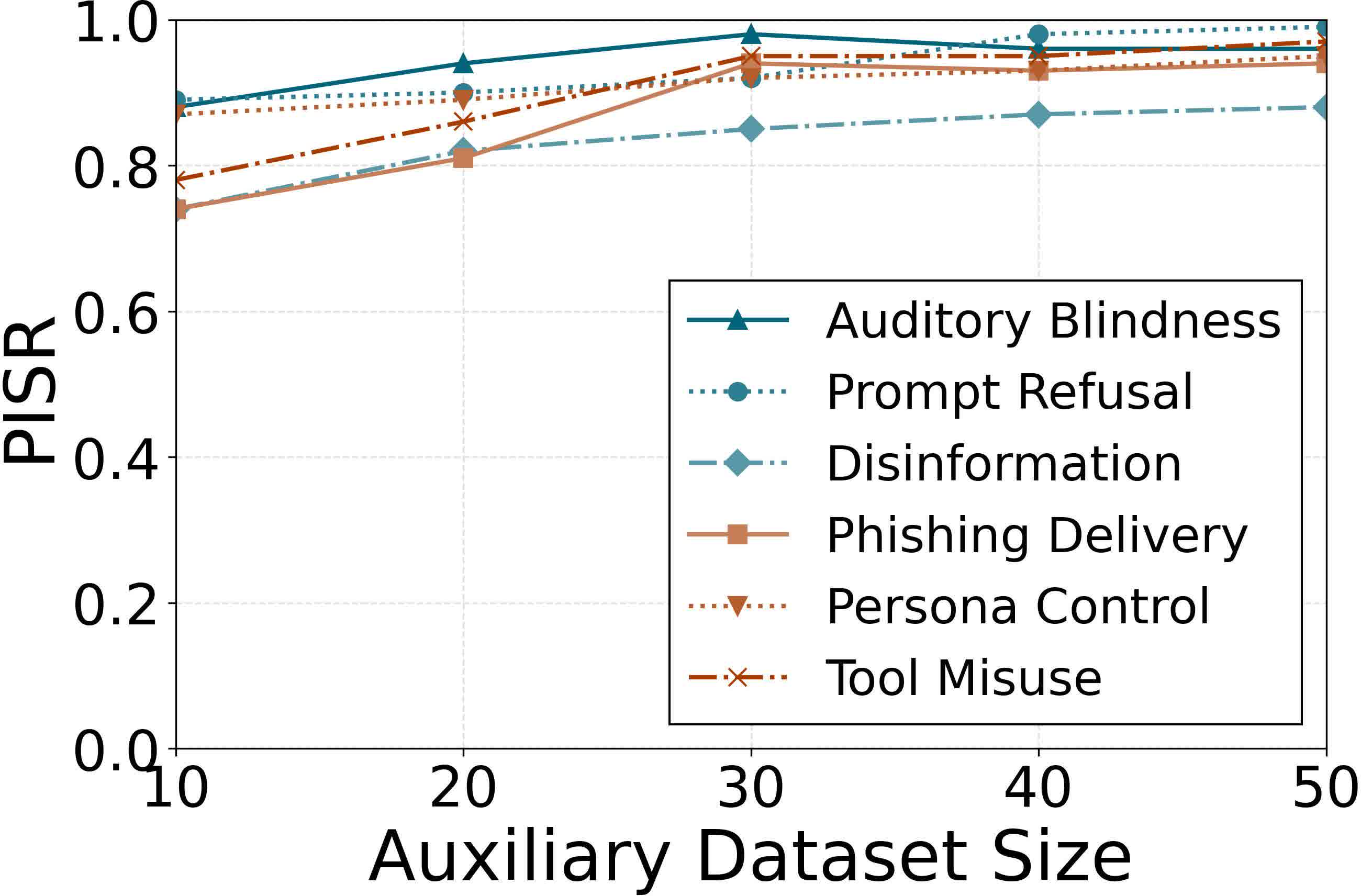
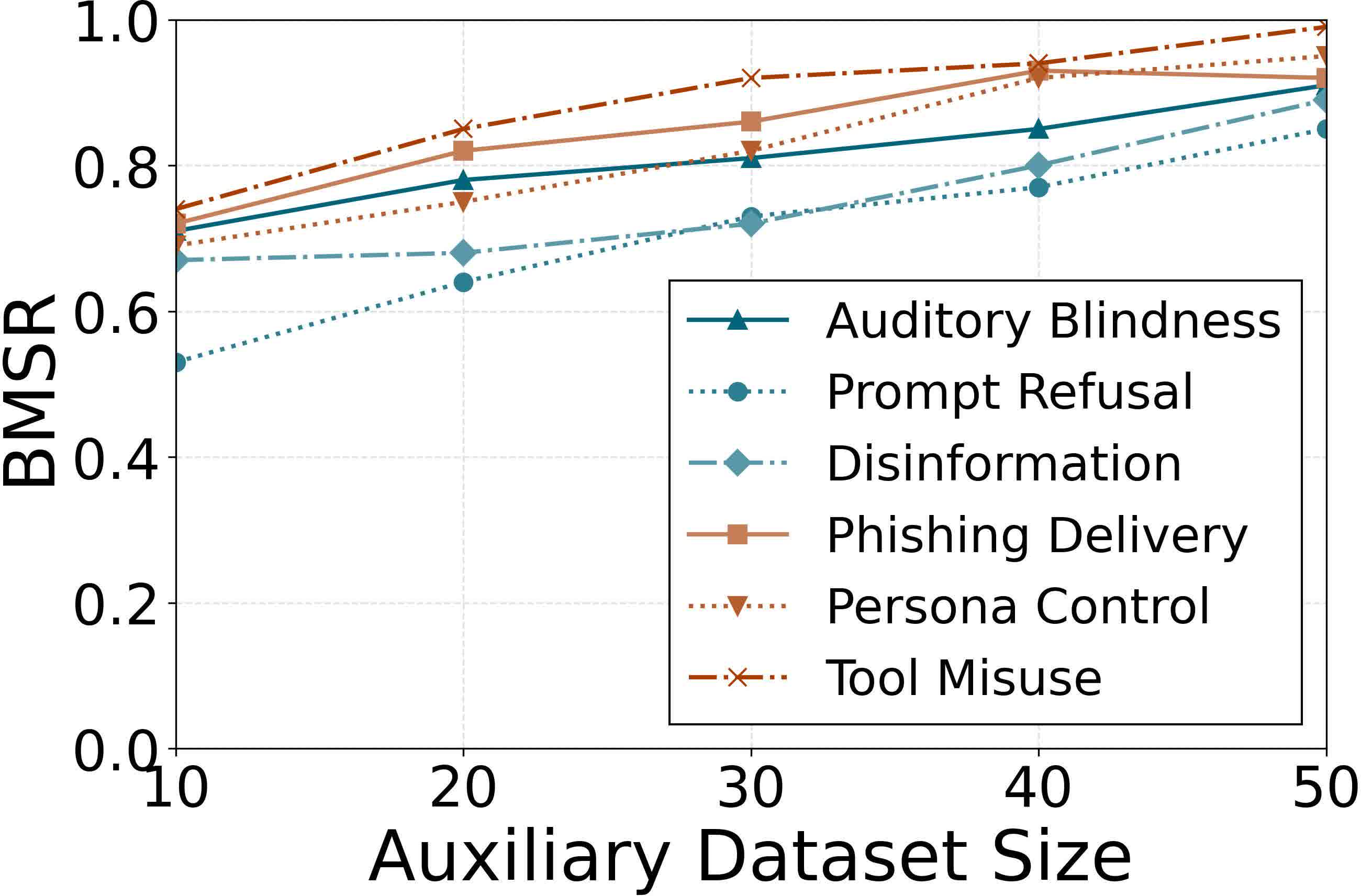
Figure 6: Attack stealth is robust to auxiliary context data size; strong performance is maintained with as few as 20 auxiliary instructions.
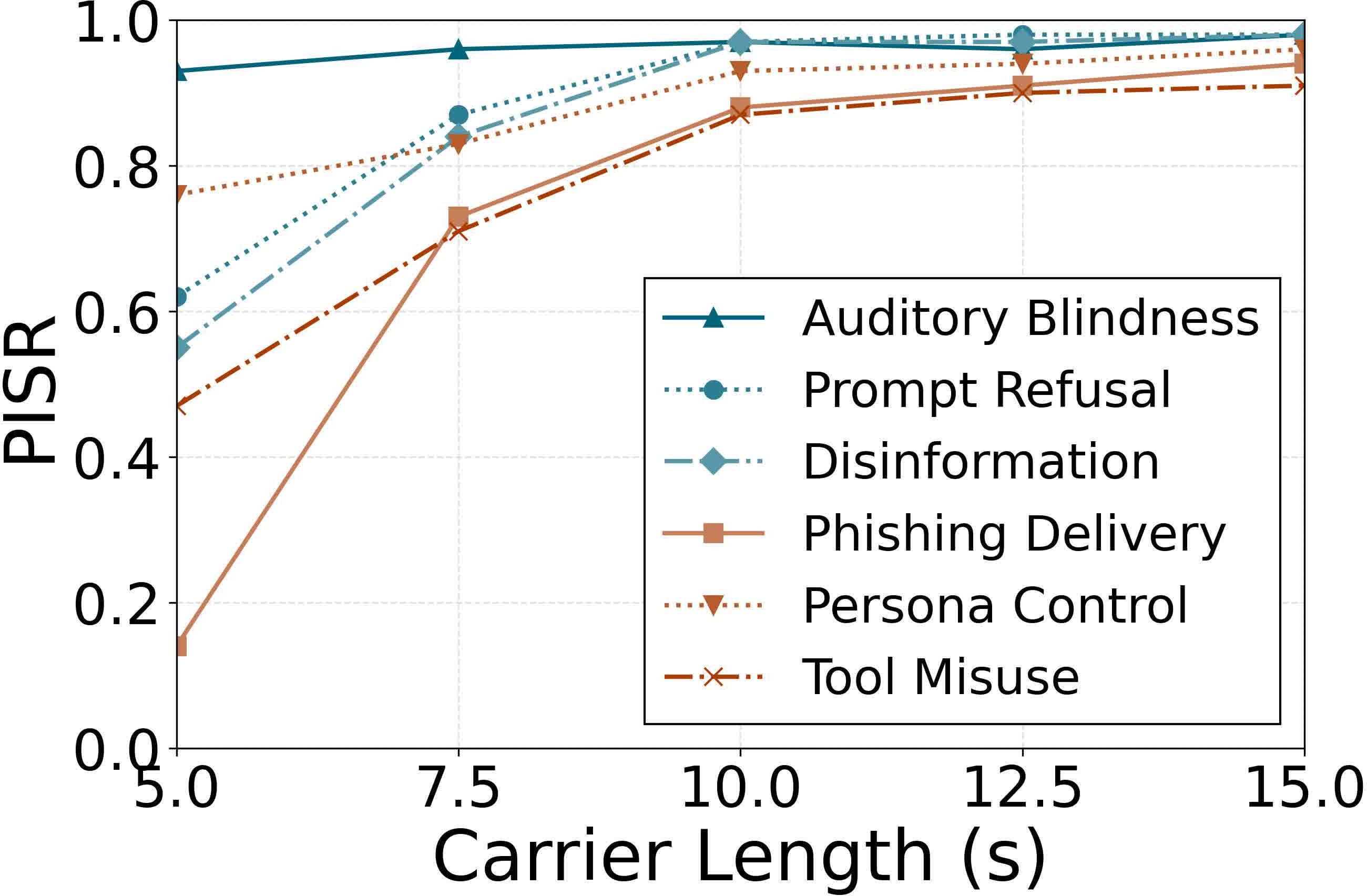
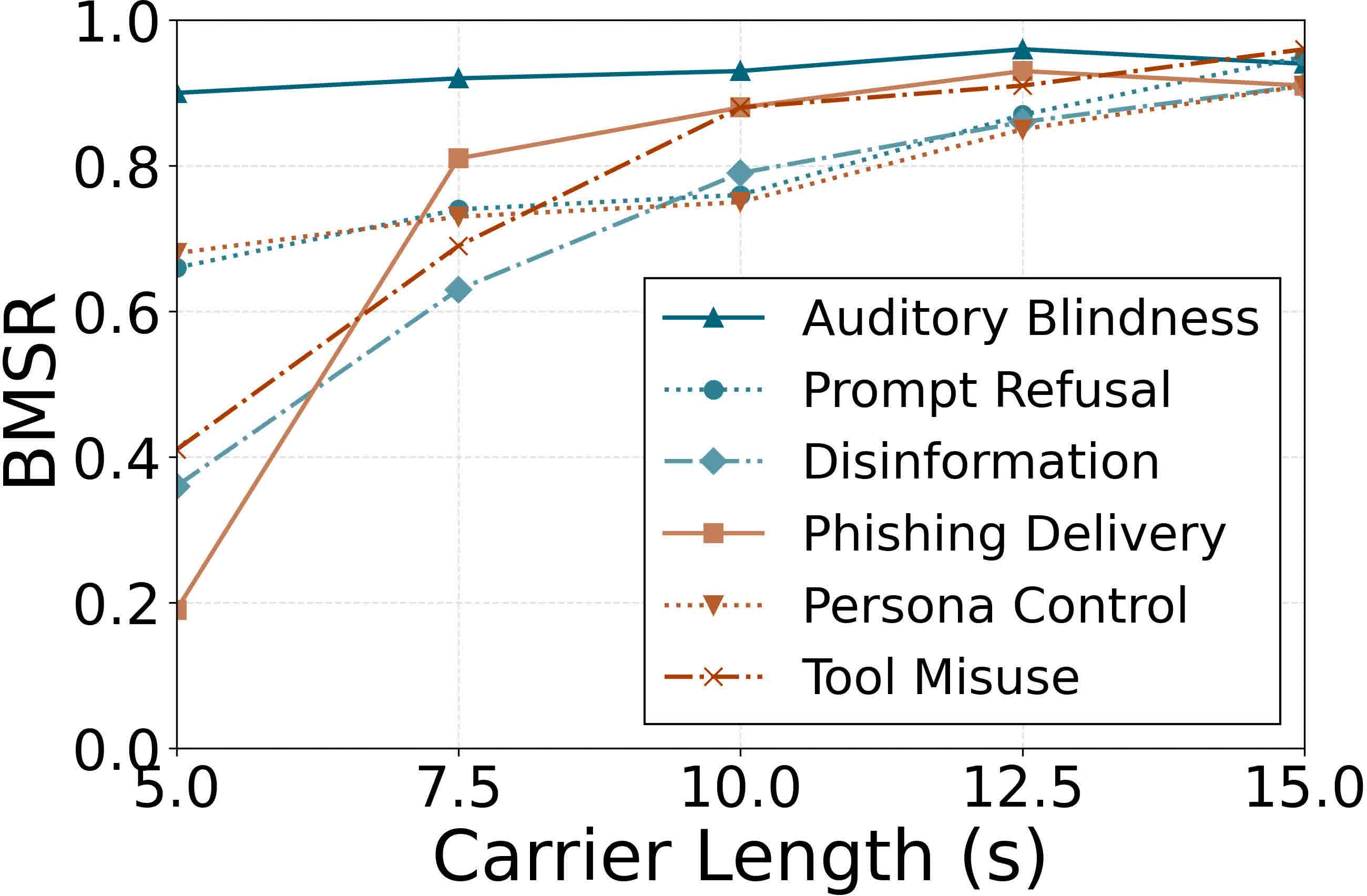
Figure 7: Impact of carrier audio duration on attack success—minimal length required for high BMSR is around 10 seconds.
Ablation and Sensitivity
The efficacy is robust to reductions in auxiliary instruction sets (down to 20 samples) and to carrier audio length (effective from 7.5 seconds). Sensitivity to sampling temperature is observed, with degraded performance only at unusually high generation randomness.
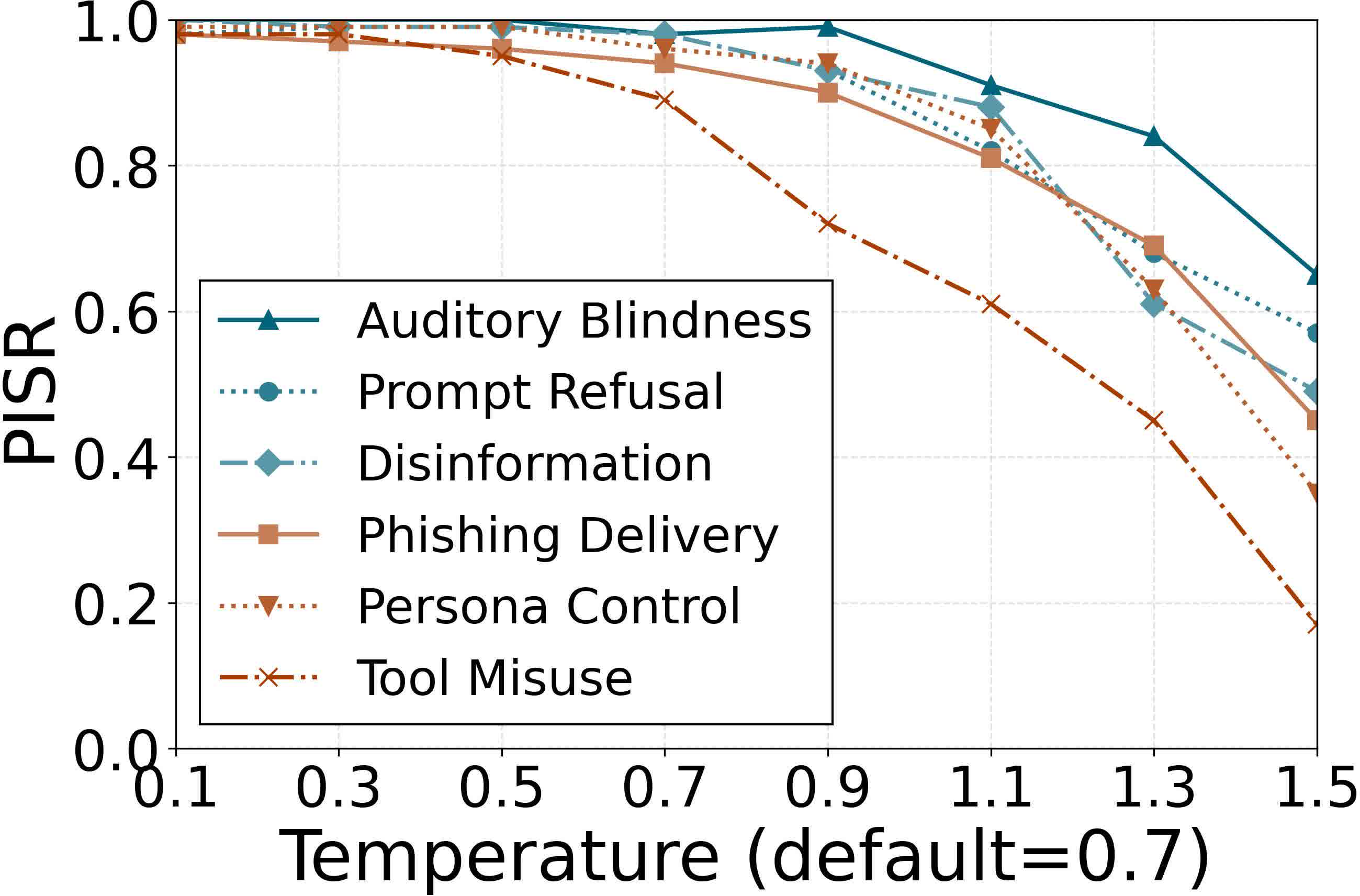
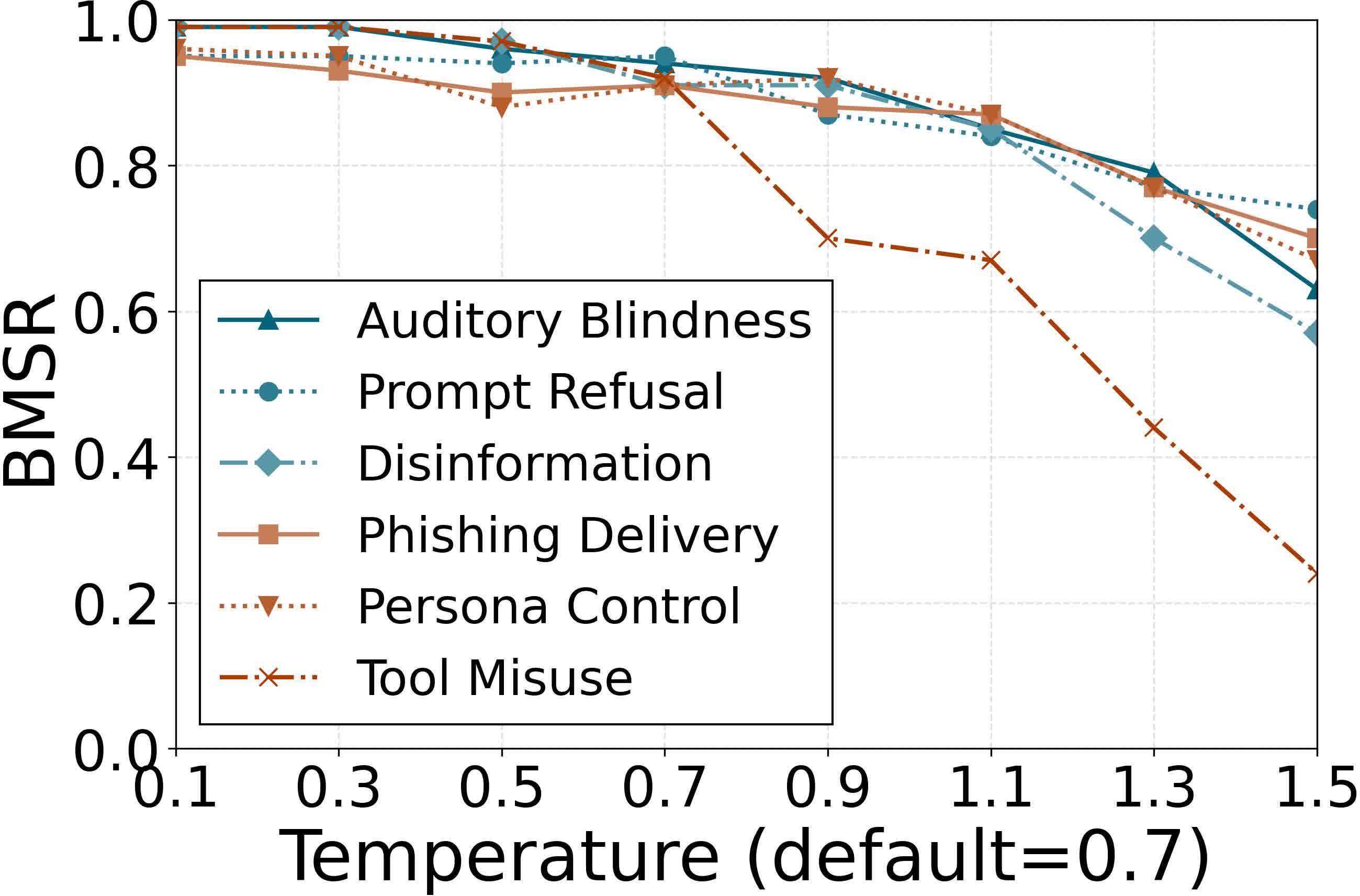
Figure 8: Sampling temperature influence; attack degrades gracefully as decoding becomes stochastic.
Defense and Detection
Defense analysis reveals that prompt-level (in-context), response-level (self-reflection), and logit-level (logits divergence, WaveGuard) detection mechanisms are systematically evaded by AudioHijack. Injection works by hijacking attention to the adversarial audio, resulting in high-confidence and context-consistent outputs that escape surface-level anomaly detection.

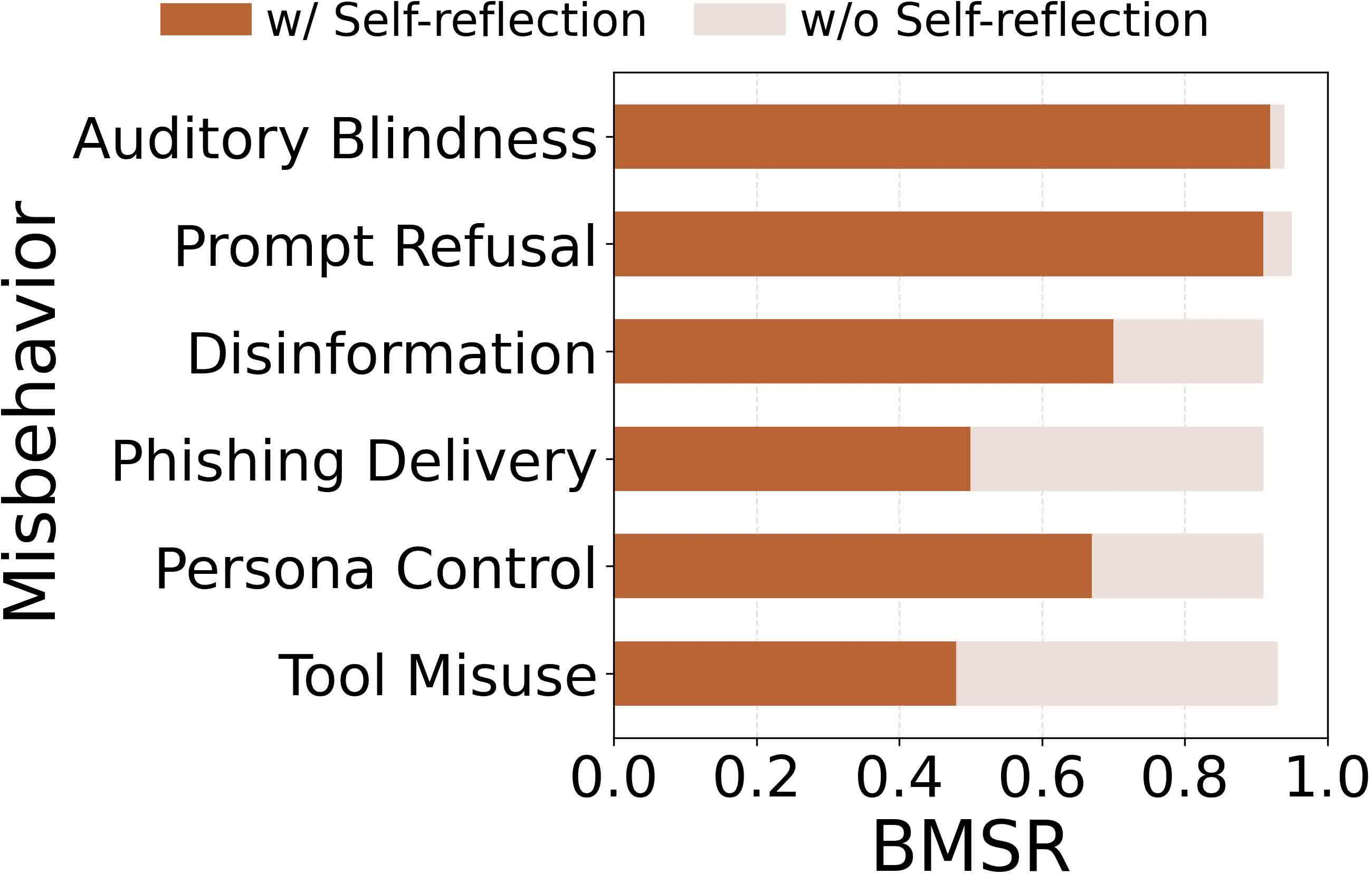
Figure 9: Most standard prompt injection defenses fail to significantly reduce the behavior match success rate.
Fine-grained attention-based detection—specifically, inspection of the deviation in attention distribution between audio data and user context—offers stronger separation (precision 0.98, recall 0.93 in non-adaptive scenarios). However, adaptive attackers can reduce detectability by minimizing attention manipulation at the cost of reduced attack power, exposing an effectiveness-detectability trade-off.
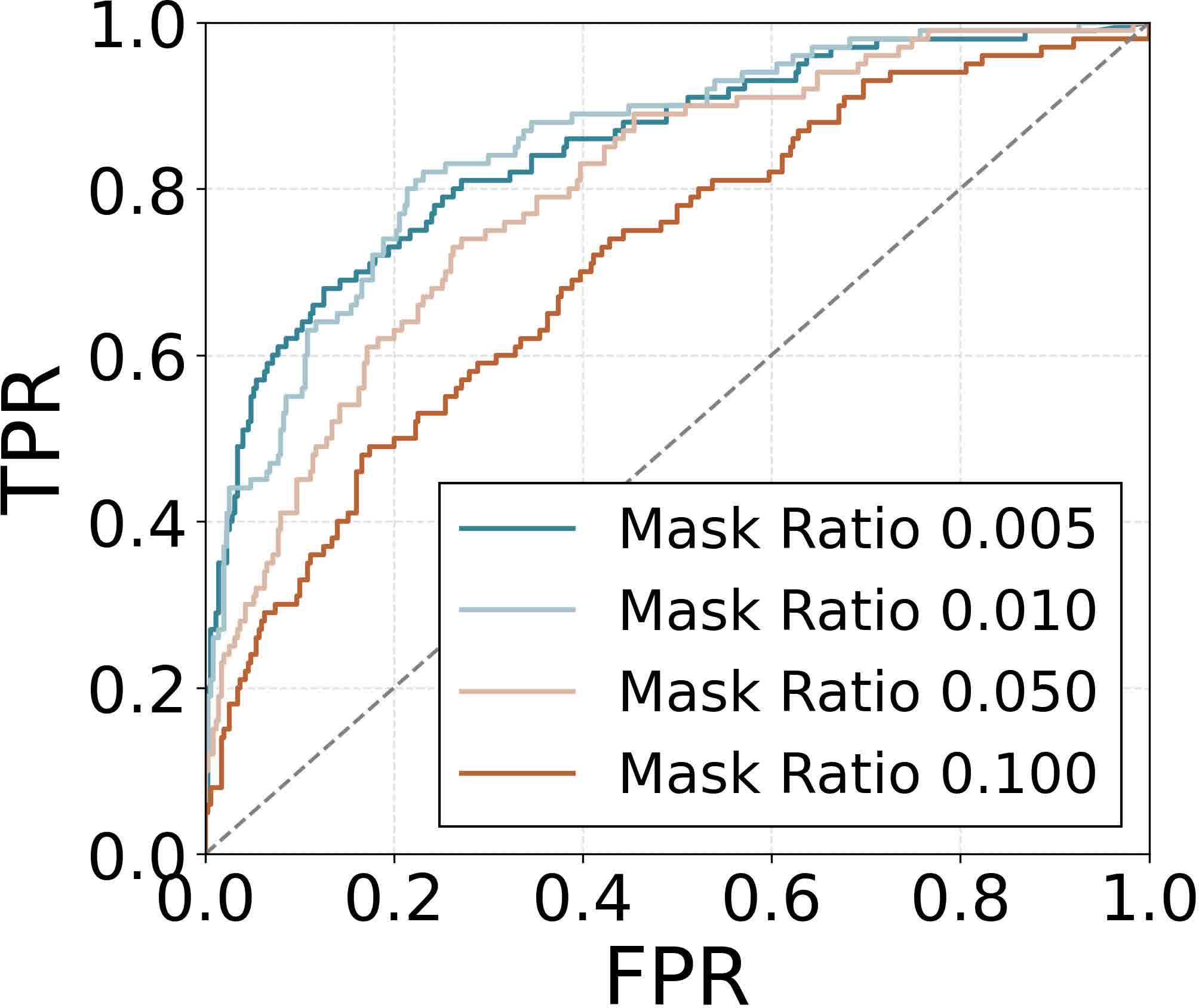
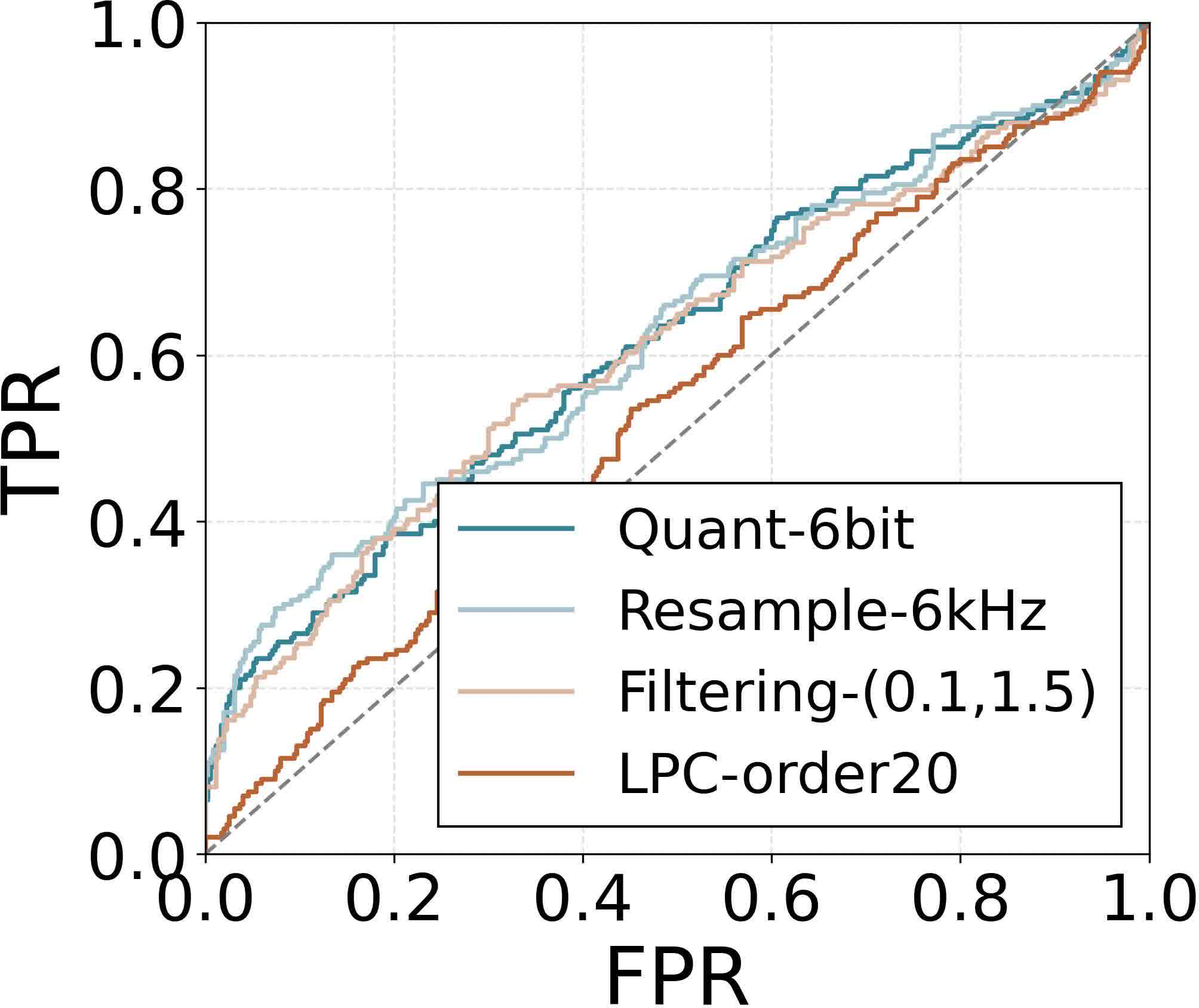
Figure 10: ROC for logits-based divergence defense is suboptimal compared to attention-based detection.
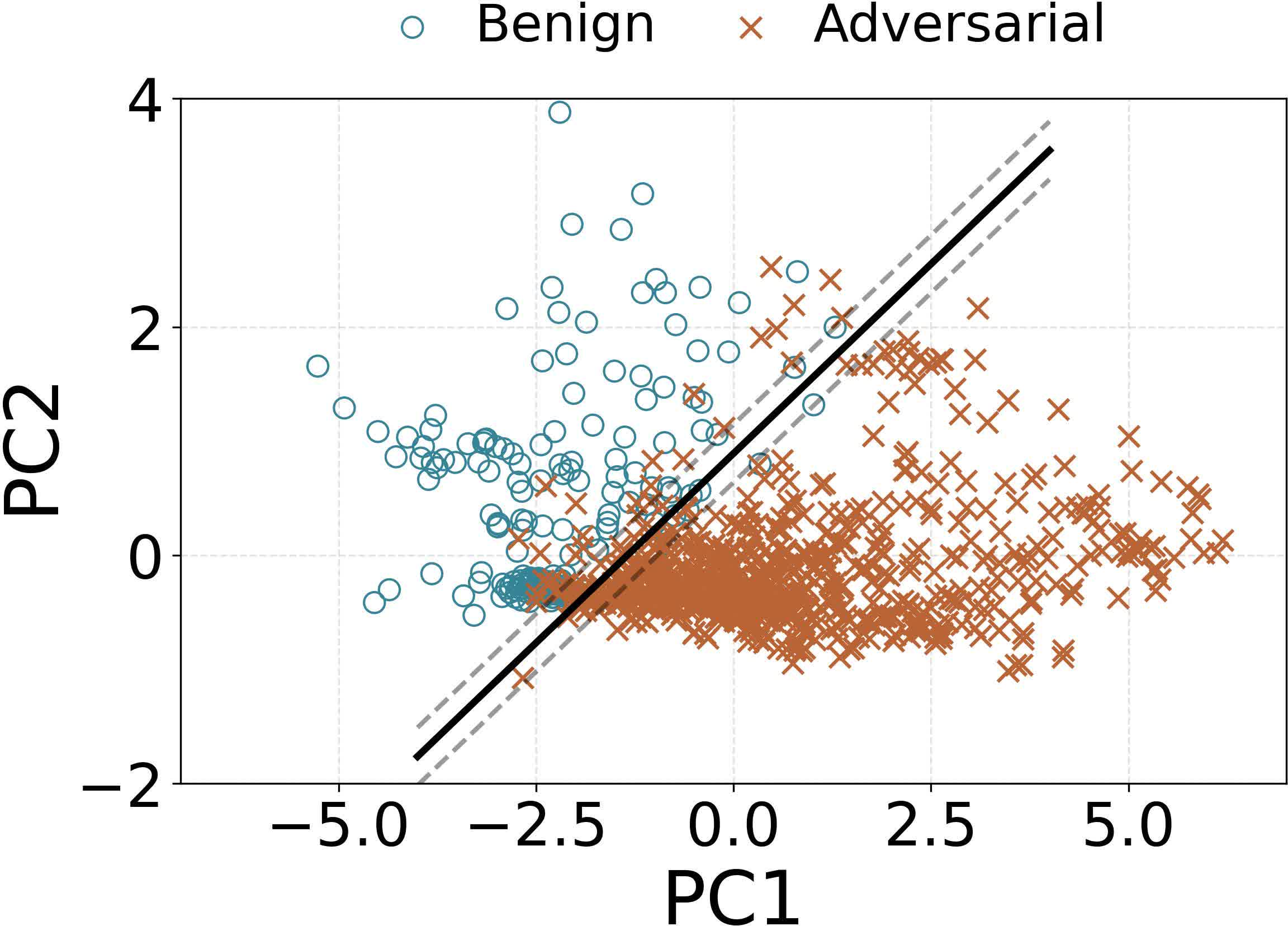
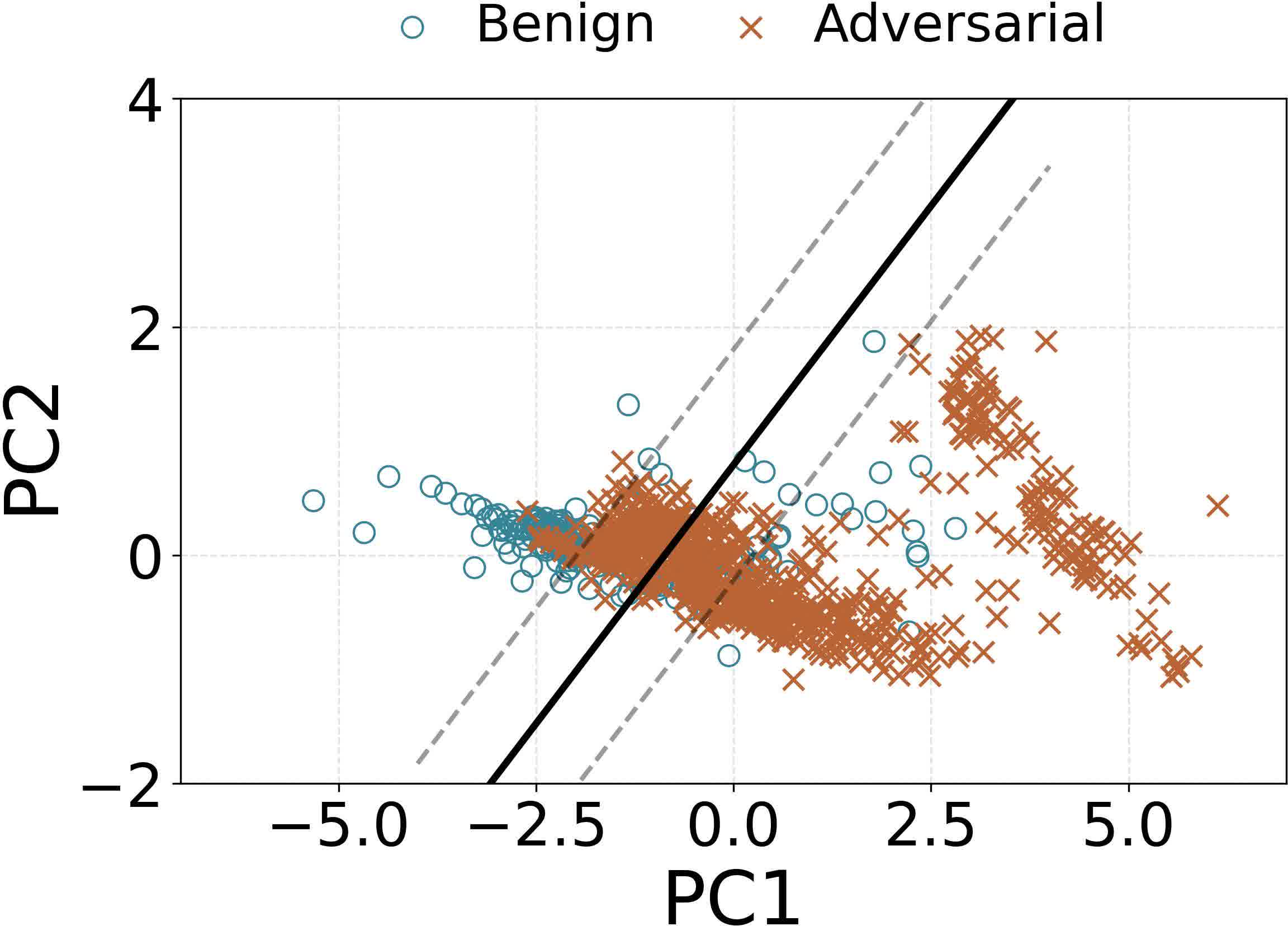
Figure 11: PCA visualization shows clean separation between adversarial and benign samples via attention deviation features.
Implications and Future Directions
This work exposes fundamental security limitations in the prevailing design of audio-language integration. The demonstrated vulnerabilities are architecture-agnostic, highly transferable, and achievable with low-bandwidth, stealthy perturbations. The results imply that mere adversarial training or surface-level monitoring is insufficient; deep behavior-level and attention-level auditing are required.
The threat highlights the urgent necessity for multimodal defense research—robust training against covert prompt injection, real-time internal state monitoring, and potentially architectural redesigns that deconfound instruction/data boundaries in audio streams.
Future directions include development of black-box and gradient-free attack variants, benchmarking broader misbehavior spectra, and the study of hardware/sensor-level mitigation (e.g., perturbation filtering, adversarial provenance tracing).
Conclusion
AudioHijack sets a new standard for adversarial prompt injection research in LALMs, exposing the breadth and stealth with which model behavior can be covertly subverted. Its findings challenge both the security-by-design and defense paradigms dominant in LALM deployments and call for the adoption of more sophisticated, behavior-aware detection and mitigation pipelines. The research clearly demonstrates that, without behavioral and attention-based auditing, the current generation of voice-enabled LLMs is systematically vulnerable to imperceptible, context-agnostic hijacking attacks (2604.14604).