- The paper demonstrates that the dominant spectral axis of LoRA adapters distinctly encodes training objectives, achieving near-perfect classification (AUC~1.00).
- The analysis reveals a strong link between weight-space geometry and harmful compliance, with dose–response trends correlating training steps and attack success rates.
- The study highlights cross-method generalization challenges, necessitating method-aware classifiers for effective model oversight and safety monitoring.
Spectral Geometry of LoRA Adapters Encodes Training Objective and Predicts Harmful Compliance
Introduction
This work conducts a comprehensive empirical analysis of the spectral geometry of LoRA weight deltas in fine-tuned LLMs, focusing on whether spectral summaries are sufficient to (1) determine the fine-tuning objective applied to the adapter, and (2) predict downstream behavioral safety violations. The experimental protocol is realized on 38 LoRA adapters for Llama-3.2-3B-Instruct, spanning four categories: healthy SFT baselines, DPO with inverted harmlessness, DPO with inverted helpfulness, and activation-steering-derived adapters. Key findings include the robust classification of training objectives in weight-space (AUC~1.00 across all DPO comparisons), a strong geometry–behavior link for harmful compliance, and cross-method generalization failure between DPO and steering-based perturbations.
Spectral Analysis: Geometry Encodes Objective Type
The central contribution is establishing that the dominant axis of variation in LoRA weight-delta space corresponds to the training objective, not training intensity. Principal component analysis of flattened DPO adapters shows that PC1 (explaining 20.6% of variance) separates inverted harmlessness from inverted helpfulness (AUC~1.00), while PC2 correlates with training duration (ρ = 0.589). Thus, otherwise identical optimization regimes diverge primarily in direction rather than magnitude.
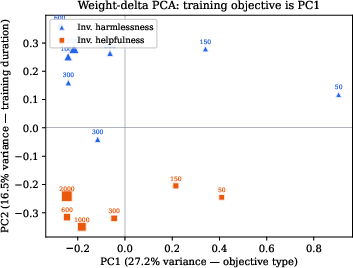
Figure 1: PC1 of weight-delta space perfectly separates DPO objective; PC2 tracks step count, making objective identity the main axis of variation.
Accompanying classifier results indicate that spectral features allow perfect discrimination of all six pairwise objective comparisons (AUC~1.00 in all cases), and near-perfect ordinal severity ranking within each DPO type (ρ ≥ 0.956). Module ablation identifies value-projection weights as diagnostic for objective identity, while query-projection weights track drift occurrence but not its source. This represents substantial evidence that LoRA spectral geometry is an effective fingerprint for the applied objective in DPO-style fine-tuning.
Behavioral Harm Prediction from Weight-Space Geometry
Harmful compliance, operationalized as attack success rate (ASR) on HEx-PHI prompts, correlates strongly with weight-delta-based drift probability for DPO-inverted-harmlessness adapters (ρ = 0.72, p < 0.001). A nearly perfect dose–response curve is observed between DPO step count and ASR, saturating above thousands of steps.
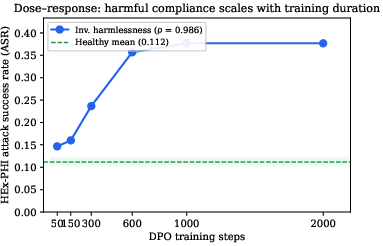
Figure 2: DPO-inverted harmlessness adapters show monotonic ASR elevation with training duration; ρ = 0.986, establishing dose–response.
Deploying a phase-3 weight-delta classifier, adapters can be partitioned into healthy (drift probability near zero, mean ASR 0.112) and drifted (near one, mean ASR 0.266, Δ = +0.154). Within the inverted-harmlessness cluster, Frobenius norm correlates with ASR at nearly one-to-one correspondence (ρ ≈ 0.99), supporting severity estimation once drift type is ascertained. In contrast, adapters subjected to inverted-helpfulness DPO yield negligible ASR elevation, consistent with the specificity of HEx-PHI to harmfulness and not to helpfulness erosion.
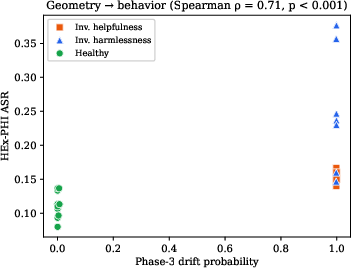
Figure 3: Weight-space drift probability predicts HEx-PHI ASR across adapters, delineating healthy from drifted clusters (ρ = 0.72).
Cross-Method Generalization and Module Specialization
A classifier trained on DPO-drifted vs. healthy adapters in weight space achieves systematic label inversion (AUC = 0.00) when applied to activation-steering-derived adapters. This arises from geometric opposition—steering perturbations are rank-1 and algebraic, occupying directions opposite DPO-induced multi-directional, gradient-accumulated deltas. Notably, steering adapters at tested intensities cause generation collapse rather than interpretable drift, emphasizing the necessity for per-method calibration in real-world adapter monitoring.
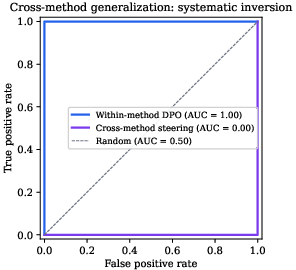
Figure 4: Cross-method classifier achieves AUC = 1.00 on DPO—but AUC = 0.00 on steering adapters, indicating systematic geometric inversion.
Module-level analysis reveals distinct functional roles: query-projection weights excel at drift detection, while value-projection features localize objective discrimination, observable only on tasks hard enough to escape independent module saturation.
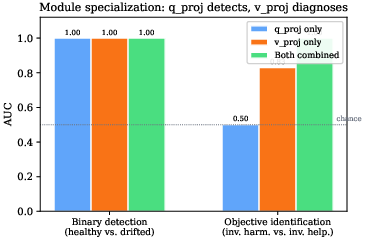
Figure 5: Both attention modules saturate in binary drift detection; only value-projection features discriminate objectives in the hardest classification.
Feature Family Attribution and Signal Disentanglement
Feature attribution experiments show direction features (singular-vector cosine alignment to healthy centroid) are 10×–30× more informative than shape or magnitude for objective classification, confirming that spectral geometry—not just the amount of drift but the direction—is the relevant signal.
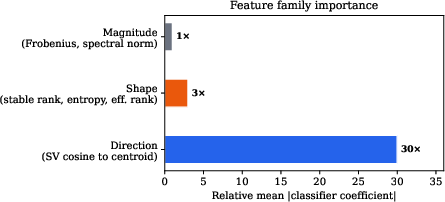
Figure 6: Direction features contribute overwhelmingly to objective detection relative to shape and magnitude.
Magnitude features (Frobenius/spectral norm) increase monotonically with training step count but collapse both DPO types, demonstrating their inability to resolve objective identity.
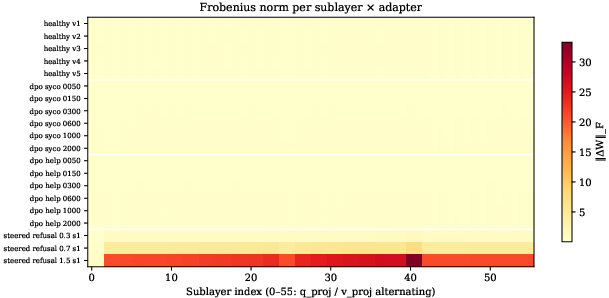
Figure 7: Frobenius norm increases with step count but does not distinguish between objectives, showing magnitude alone is uninformative about the nature of drift.
Activation Space versus Weight Space
Independent analysis in activation-space (linear probes trained on activations) and weight-space (PCA on matrix deltas) both robustly recover objective identity at perfect accuracy. However, the dominant directions in these two spaces are nearly orthogonal (max cosine ≈ 0.098), indicating that geometric signatures of training regime are distributed across non-overlapping subspaces in model computation. This suggests practical complementarity: weight-inspection for upload-time safety, activation probes for inference-time detection.
Safety Classification and Guard Models
Evaluations with Llama-Guard-3-1B and GPT-4o show consistent detection of drifted (DPO) vs. healthy adapters. For steering adapters, generation collapse leads Guard to classify outputs as persistently unsafe (ASR~0.994), while GPT-4o recognizes degenerate output and assigns ASR~0.
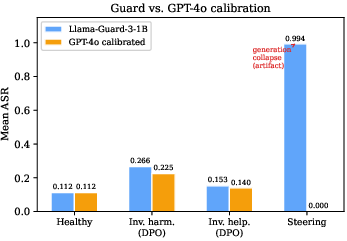
Figure 8: Guard and GPT-4o agree on healthy/DPO adapters, but only GPT-4o correctly recognizes collapse in steering adapters.
Theoretical and Practical Implications
This work demonstrates the existence of high-signal, low-dimensional geometric fingerprints for fine-tuning objectives in LoRA adapters. Within a single fine-tuning regime (DPO), these signatures generalize perfectly, and provide not only detection capabilities but information about drift severity and module specialization. However, geometric properties differ fundamentally across manufacturing methods, mandating method-aware classifiers or fallback anomaly detection.
From a practical perspective, adapter weight-space inspection offers a non-invasive, non-inferential monitoring method for early-warning safety systems, potentially supplementing or replacing expensive behavioral evaluation. Results also provide indirect experimental support for trait selection hypotheses like the Persona Selection Model, suggesting that structured persona axes are major factors in weight-space adaptation. Fine-grained behavioral risk estimation becomes feasible if evaluation instruments are matched to the drift type.
Future research directions include validating early-detection of drift before behavioral divergence is apparent, expansion of the matrix and model family coverage, and exploring multi-head or meta-learned monitoring architectures for diverse fine-tuning protocols.
Conclusion
The spectral geometry of LoRA weight deltas encodes sufficient information to perfectly classify training objectives and to robustly predict harmful compliance within objective-matched evaluation regimes. Objective identity forms the primary geometrical axis in LoRA adapter space, orthogonal to training intensity. Classification generalizes within but not across fine-tuning methods, indicating that production safety monitoring demands per-method detectors or anomaly fallback. These findings refine our understanding of the link between parameter-space perturbations and learned behavior, highlighting spectral geometric analysis as an important tool for model oversight and alignment.

