- The paper’s main contribution is a controlled evaluation of 10 LLM-based query reformulation methods, highlighting reproducibility gaps across retrieval paradigms and datasets.
- Methodologically, it standardizes experimental protocols using QueryGym to compare keyword-level, document-level, and corpus-grounded strategies with metrics like nDCG@10.
- Results indicate that reformulation benefits are highly contingent on dataset, retrieval method, and LLM configuration, emphasizing significant interaction effects and stability challenges.
Introduction and Motivation
The paper systematically investigates LLM-based query reformulation within Information Retrieval (IR), specifically focusing on reproducibility and comparative effectiveness across heterogeneous evaluation configurations. LLMs have been increasingly deployed for query reformulation and expansion, promising improvements in retrieval effectiveness. However, prior studies lacked consistent experimental protocols, confounded variables including LLM backbone, parameter scale, retriever paradigm, and dataset choice, and hence made it difficult to assess which gains are reproducible or generalizable.
This work introduces a controlled evaluation of ten representative reformulation methods using a unified toolkit, QueryGym, across two LLM families (GPT-4.1 and Qwen2.5) at two parameter scales, three retrieval paradigms (BM25, SPLADE, BGE), and nine benchmark datasets (TREC Deep Learning and BEIR). The study holds decoding, prompting, and retrieval configurations constant, enabling head-to-head comparisons disentangled from hidden implementation variance.
Methodological Coverage and Evaluation Setup
The reformulation strategies evaluated span three major methodological families:
- Keyword-Level Expansion: Methods (GenQR, GenQREnsemble, Q2K) prompt LLMs for additional keywords or phrases to augment the query, typically zero-shot with no corpus feedback.
- Document-Level Expansion: Approaches (Query2Doc zero-shot (ZS), few-shot (FS), chain-of-thought (CoT), QA-Expand, MUGI) synthesize pseudo-documents, answer passages, or concatenations of generated sub-answers, enriching the semantic query signal.
- Corpus-Grounded Expansion: Techniques (CSQE, LameR) anchor expansions in corpus-specific evidence (e.g., retrieval feedback, collection distribution) to align with dataset vocabulary and topical distribution.
Experiments are conducted via QueryGym, ensuring identical token limits, temperature, and sampling parameters for all models and methods. The evaluation leverages BM25 for lexical retrieval, SPLADE for learned sparse retrieval, and BGE for dense retrieval, all via Pyserini.
Under strictly controlled conditions (e.g., GPT-4.1 with BM25), document-level and corpus-grounded expansion strategies demonstrate substantial improvements in nDCG@10 and recall across TREC DL and BEIR datasets, outperforming classical expansion (RM3) and keyword-level approaches. Notably:
- Document-level methods (e.g., MUGI, Q2D (FS)) consistently achieve highest nDCG@10, especially on challenging queries (DL-HARD) and domain-diverse datasets.
- Chain-of-thought prompting does not yield further improvement and sometimes degrades performance, underscoring the importance of guided rather than unconstrained reasoning in expansion generation.
- Corpus-grounded methods provide stable performance, particularly on adversarial or ambiguous queries, indicating domain-sensitive robustness.
Cross-Retriever Analysis and Paradigm Sensitivity
LLM-driven reformulation exhibits pronounced retriever-dependence:
- Lexical Retrieval (BM25): Reformulation methods consistently produce significant gains in ranking metrics, both nDCG@10 and recall.
- Learned Sparse Retrieval (SPLADE): Gains are reduced, with some expansion methods occasionally yielding negligible or negative changes. This reflects SPLADE's inherent neural expansion, which absorbs much of the benefit of explicit query-side enrichment.
- Dense Retrieval (BGE): Surface-level lexical augmentations often fail to translate into meaningful embedding space improvements, and expansion can degrade performance on datasets where dense semantic encoding excels.
BM25 with effective LLM-based reformulation frequently achieves comparable effectiveness to state-of-the-art dense retrievers on unexpanded queries, offering a cost-effective alternative without vector index overhead.
Domain Robustness and Dataset Sensitivity
Effectiveness gains from reformulation vary markedly across datasets, query difficulty, and retriever configurations. Reformulation provides the largest improvements on DL-HARD and underspecified queries, but less robust gains or even regressions on certain domain-specific collections (FiQA, COVID).
LLM Backbone, Scale, and Stability
The impact of architectural lineage and parameter scale is nuanced:
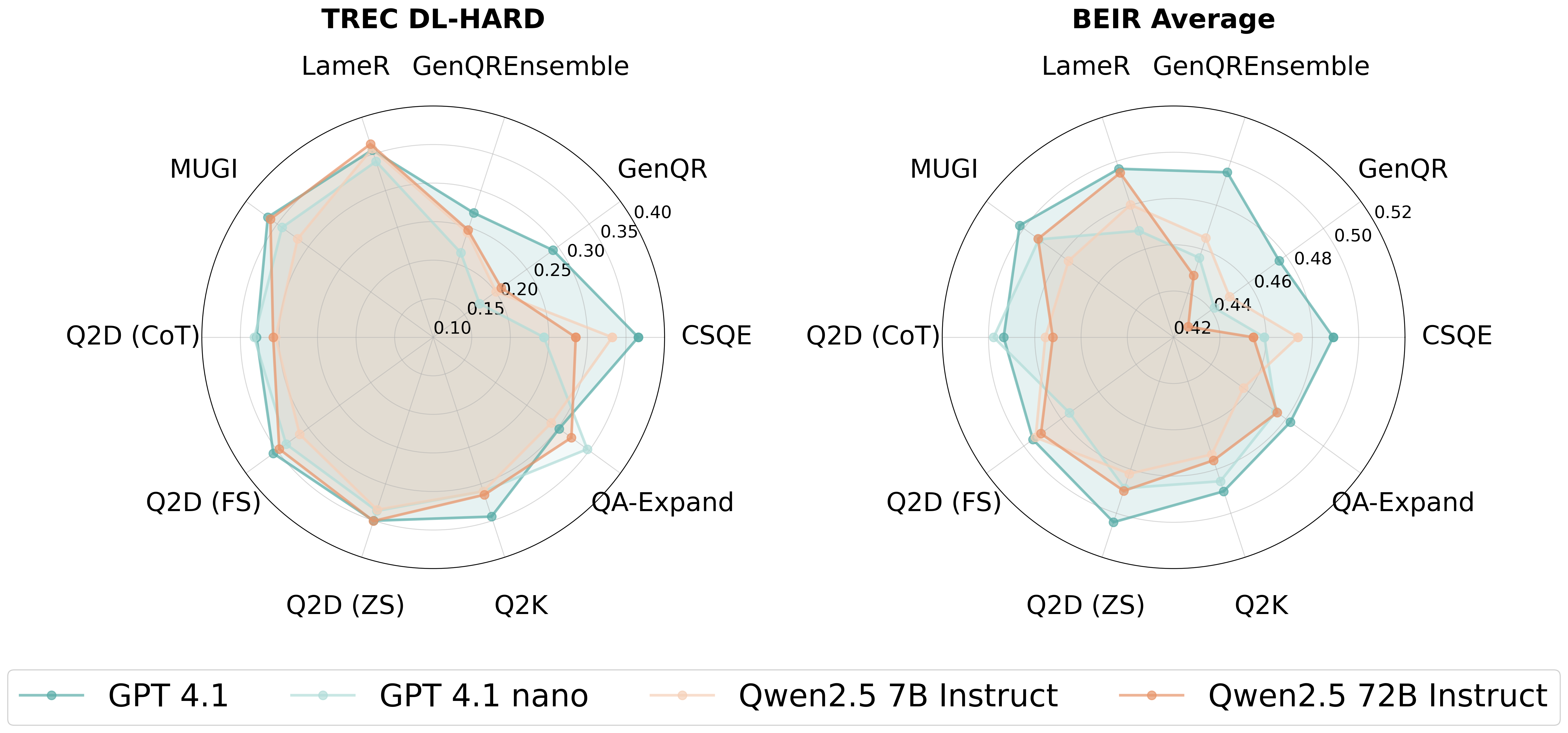
- Within the GPT-4.1 family, both nano and full variants produce similar cross-domain profiles, with modest within-family scale sensitivity.
- Qwen2.5 demonstrates greater scale-dependent variability, with Qwen2.5-72B outperforming Qwen2.5-7B by larger margins on several datasets.
Radar charts and Spearman rank correlations evidence that method ranking is not preserved across LLM backbones or scales: comparative claims about reformulation effectiveness are not portable unless scoped to the exact LLM configuration.
Practical and Theoretical Implications
These findings clarify key constraints for reproducibility in LLM-based query reformulation:
- Gains reported under lexical retrieval cannot be assumed to generalize to learned sparse or dense retrieval; paradigm-specific evaluation is essential.
- Method effectiveness is highly conditional on dataset and query granularity, requiring multi-domain benchmarking.
- The relationship between model scale and reformulation utility is method- and domain-dependent; increasing LLM capacity does not guarantee uniform benefit.
- Comparative benchmarking is only valid per retrieval and LLM configuration, and must be contextualized given substantial interaction effects.
Practically, the study advocates for more rigorous standardization in evaluation pipelines, encourages open-source artifact release (QueryGym), and recommends reporting both aggregate effectiveness and cross-dataset stability (e.g., RankCV) for actionable reproducibility claims.
Conclusion
This controlled reproducibility study demonstrates that LLM-based query reformulation effectiveness is intricately conditioned on retrieval paradigm, dataset domain, LLM backbone, and method design. Substantial gains are possible but are not reliably portable across heterogeneous evaluation settings. Future IR research must incorporate controlled cross-paradigm and cross-domain protocols, validate comparative claims across multiple LLM scales and architectures, and report not only mean effectiveness but stability metrics. Open-source toolkits and leaderboards such as QueryGym are critical for transparent benchmarking and ongoing methodological development.