- The paper reveals substantial gains in retrieval effectiveness using LLMs, noting up to 20% improvement in nDCG@10 on Robust04 and 8.8% on DL20.
- It employs a comprehensive meta-analysis of 143 studies to highlight metric shifts from MAP to nDCG@10 and challenges arising from baseline comparisons.
- The study identifies significant data contamination risks with up to 41% leakage, questioning the generalizability and validity of current benchmarks.
Introduction
LLMs have become ubiquitous in recent Information Retrieval (IR) pipelines, influencing benchmark evaluations and IR methodology. "The LLM Effect on IR Benchmarks: A Meta-Analysis of Effectiveness, Baselines, and Contamination" (2604.05766) provides a systematic meta-analysis of 143 papers evaluating the TREC Robust04 and TREC Deep Learning 2020 (DL20) passage retrieval benchmarks, focusing on longitudinal effectiveness gains, baseline selection, metric shifts, and the risk of data contamination. The paper delineates the so-called "LLM effect": recent LLM-incorporating systems report substantial gains in retrieval effectiveness, but these results exist in a context of metric shifts and potential benchmark leakage, raising sharp questions about the provenance and generalizability of observed improvements.
Longitudinal Trends in Retrieval Effectiveness
The study provides a granular longitudinal view of reported effectiveness metrics for Robust04 (2005–2025) and DL20 (2020–2025):
- Robust04: MAP and nDCG@10 are the primary metrics. Notably, while MAP remained largely stagnant for neural models after initial surges, there is a pronounced jump in nDCG@10 for LLM-based systems post-2023, reaching up to a 20% improvement over 2023 baselines. The best Robust04 nDCG@10 is achieved by CoDime (0.734) using LLM reranking, compared to a 2023 best of 0.536.
- DL20: LLM-based systems since 2023 exceed the previous best TREC 2020 result by up to 8.8% nDCG@10. Multiple LLM systems now surpass strong baselines such as SpladeV3 (nDCG@10 = 0.752) and TREC 2020 (nDCG@10 = 0.803).
The upward drift in effectiveness—though at times modest in magnitude—is robust across both benchmarks, despite noise caused by metric proliferation and experimental heterogeneity.
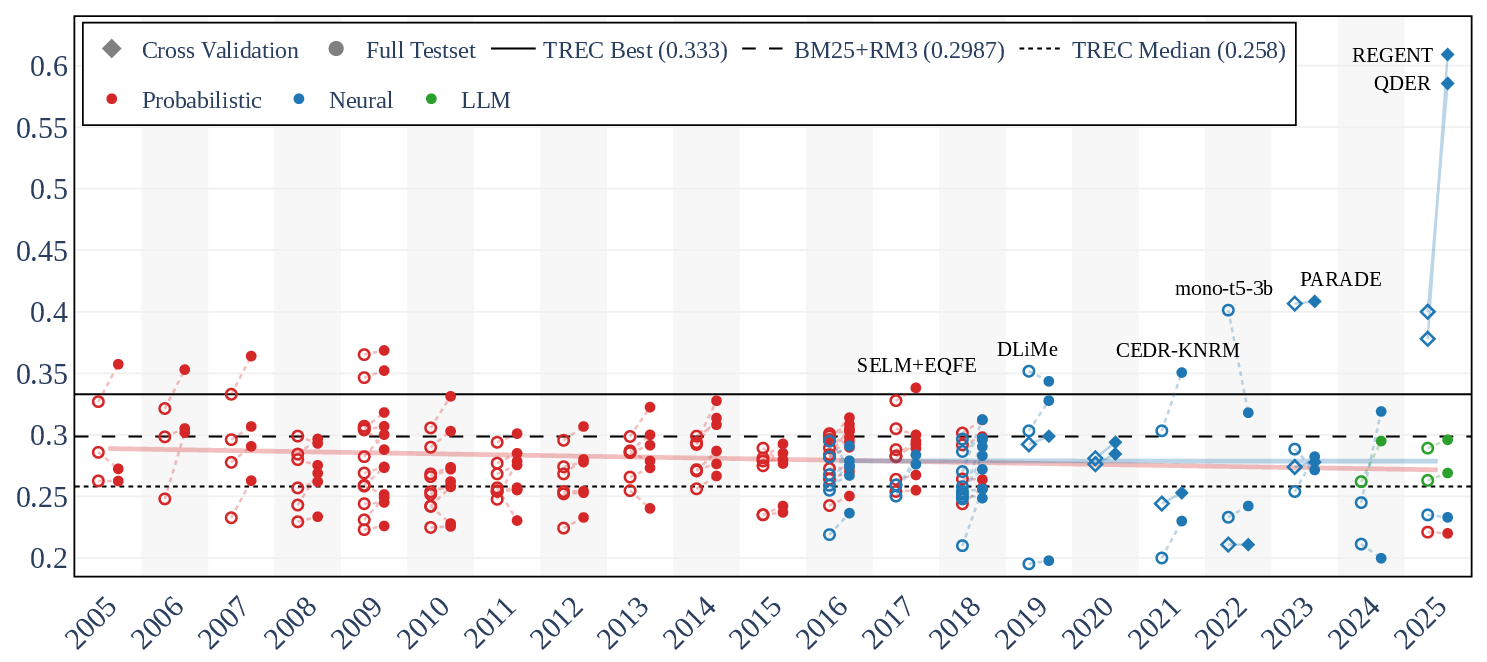
Figure 1: Robust04 MAP results (2005–2025) demonstrate accumulated improvements corresponding to model and metric shifts, with the LLM era showing new state-of-the-art scores above historical bests.
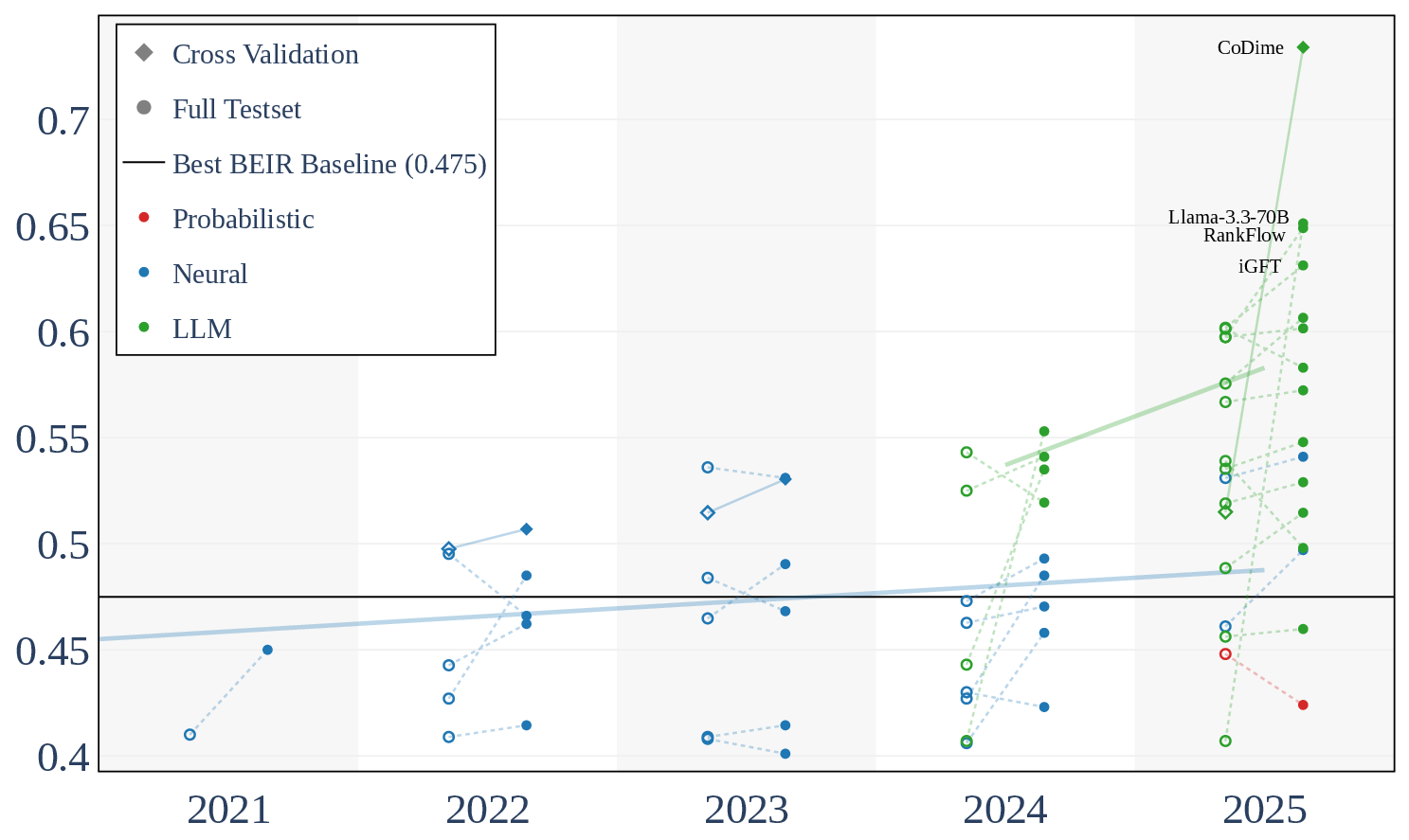
Figure 2: Robust04 nDCG@10 performance (2021–2025) illustrates marked gains by LLM-based systems, evidenced by strong increases in top-reported results, especially after 2023.
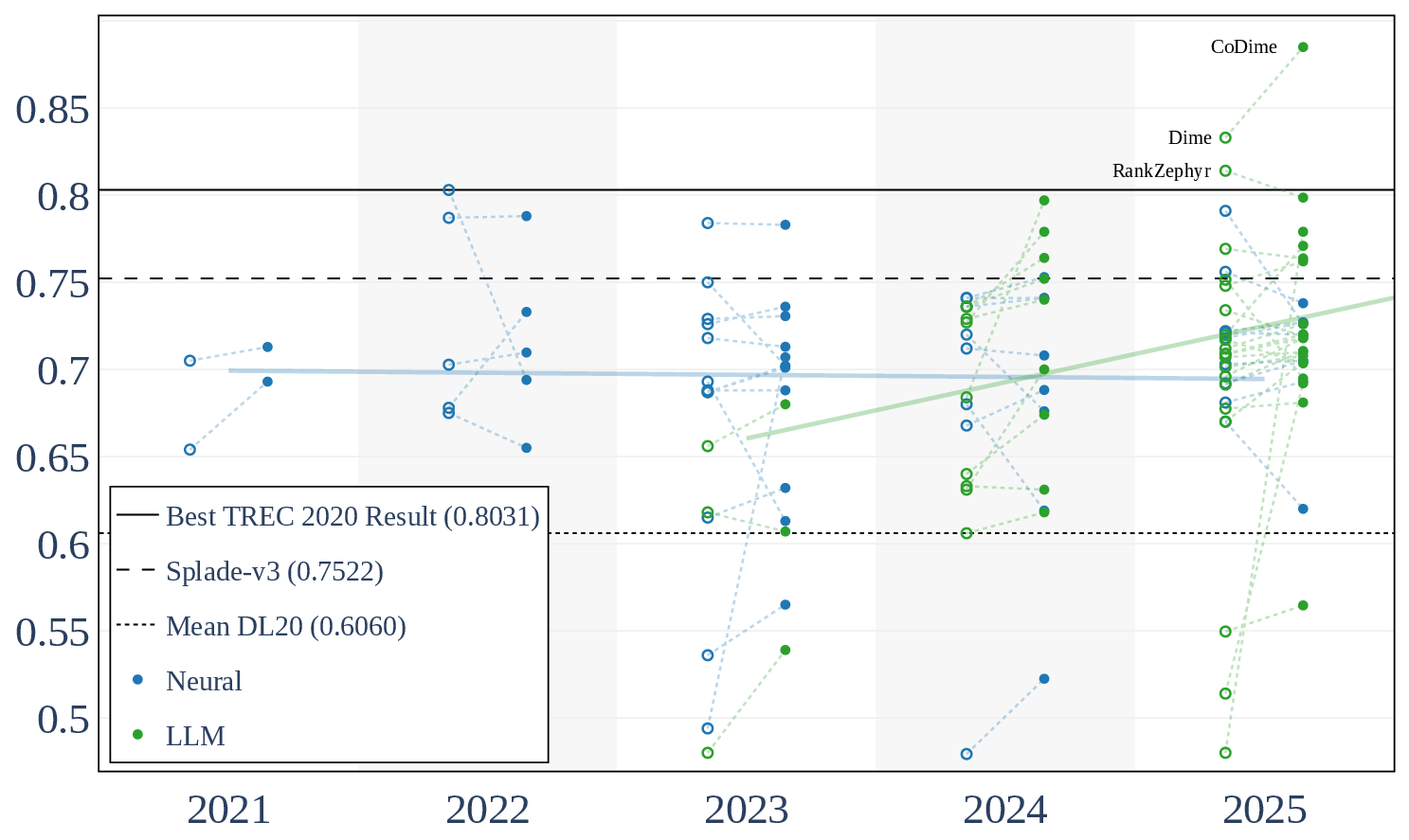
Figure 3: TREC DL2020 nDCG@10 results (2021–2025) confirm the LLM effect, with recent years' best results surpassing previous top baselines by 8.8% nDCG@10.
Evaluation Practices and Metric Heterogeneity
A notable finding is the disruption in evaluation practice, particularly in metric selection:
- Robust04 results since 2021 show 19 different evaluation metrics, complicating direct comparisons. A notable metric transition is visible: MAP (historically dominant and sensitive to overall ranking quality) is eclipsed by nDCG@10 (sensitive to top ranks) as the primary metric, reflecting not only community-wide methodological evolution but also alignment with leading evaluation initiatives such as BEIR.
- The dominance of nDCG@10 aligns temporally with widespread LLM adoption, raising questions of whether observed gains reflect underlying methodological improvements or metric reoptimization (i.e., LLMs excelling where nDCG@10 is most sensitive).
This shift introduces significant challenges for direct longitudinal comparison and the interpretation of effectiveness gains, as improvements may be metric- or cutoff-dependent. The heterogeneity in evaluation settings also complicates the attribution of improvements to model innovation rather than experimental or reporting choices.
The LLM Effect: Gains and Caveats
The analysis substantiates a reproducible "LLM effect": recent systems leveraging LLM components achieve higher reported effectiveness against strong baselines on both Robust04 and DL20. However, three qualifying factors are emphasized:
- Metric drift: LLM effect sizes often parallel metric transitions, in particular the shift from MAP to nDCG@10.
- Baseline selection: Improvement magnitudes are reduced when strong, recent baselines are used versus traditional or weak ones.
- Non-effectiveness objectives: Many recent models prioritize explainability, efficiency, or robustness, rather than strictly maximizing raw retrieval effectiveness, which diminishes the cumulative pace of effectiveness gains.
Data Contamination: Detection and Impact
With LLMs pretrained on vast and partially undocumented corpora, data contamination (training/test overlap) in IR evaluation has become a pressing concern. The authors adapt the Data Contamination Quiz (DCQ) for reranking contexts to quantify memorization leakage in LLM rerankers:
- Detection protocol: Models are prompted to identify the verbatim original among paraphrased passage variants, revealing memorization if the original is consistently chosen.
- Findings: Contamination is measurable—RankZephyr and GPT-4o-mini show 26–41% contamination on DL20, and 12–21% on Robust04.
- Effect on effectiveness: Exclusion of contaminated topics reduces nDCG@10 by up to 14% on DL20 and up to 6% on Robust04, but these drops are accompanied by wide confidence intervals due to the small number of uncontaminated topics post-filtering. This undermines statistical certainty but raises legitimate concerns about the extent to which effectiveness gains reflect genuine generalization rather than memorization.
Implications and Future Directions
The analysis highlights potent theoretical and practical implications:
- Benchmark validity: The prevalence of contamination entangles methodological progress with possible test-set exposure during pretraining, threatening the validity of benchmark-driven progress claims.
- Evaluation best practices: The convergence of LLM adoption and metric changes warrants standardized reporting of multiple effectiveness metrics and systematic contamination screening in future evaluations.
- Leaderboards and automation: The proliferation of metrics and increased risk of contamination make the case for automated, contamination-aware leaderboards and standardized evaluation pipelines to ensure both comparability and reproducibility.
- Community standards: The field must develop protocols for pre-registration of evaluation metrics, broader benchmark collection diversity, and requirements for contamination checks (especially for unpublished, proprietary pretraining collections).
Conclusion
The meta-analysis delineates the contours of the LLM effect in IR: clear, though sometimes modest, longitudinal improvements in retrieval effectiveness for LLM-based systems; simultaneous metric drift that complicates direct comparison with historical results; and significant, measurable contamination that challenges the interpretability of recent performance gains. The work cautions that benchmark-driven progress in the LLM era must be contextualized within a rapidly evolving and heterogeneous evaluation landscape, where both metric choice and training data provenance strongly condition the meaning of reported improvements.
Future research must address contamination with more discriminative estimation tools, focus on standardized multi-metric reporting, and forge reproducible evaluation infrastructure that minimizes methodological ambiguity—critical steps for preserving the evidentiary value of IR benchmarks as LLMs continue to evolve (2604.05766).