- The paper introduces a high-performance Python library that delivers fast, batched IV computations and option pricing under Black-76, Black-Scholes, and Black-Scholes-Merton models.
- It combines vectorized Halley iterations with Jäckel’s LBR algorithm, using rational initial guesses and Householder(3) refinement for rapid, machine-precision convergence.
- The library supports diverse hardware backends (CPU, GPU, PyTorch, JAX) and features drop-in compatibility and differentiable interfaces for seamless integration into quant workflows.
Overview
The paper "Fast-Vollib: A Fast Implied Volatility Library for Python with PyTorch, JAX, and CUDA Fused-Kernel Backends" (2604.27210) introduces fast-vollib, a Python library designed to efficiently compute European option prices, implied volatilities (IVs), and Greeks under the Black-76, Black-Scholes, and Black-Scholes-Merton paradigms. The package emphasizes batched execution, hardware acceleration (via PyTorch, JAX, and Triton backends), and direct compatibility with the prevalent py_vollib/py_vollib_vectorized API conventions.
The library’s principal contributions include an extensible vectorized Halley-method-based IV solver and a fully batched, multi-platform implementation of Jäckel’s "Let’s Be Rational" (LBR) algorithm, featuring both CPU and GPU single-pass kernels. This enables the integration of batched, differentiable, and hardware-adaptive IV computation into modern ML/AI quant workflows.
Numerical Methodology and Rational-Guess Initial Regimes
Implied volatility inversion is central for quoting, calibration, and risk management. The two numerical strategies addressed in fast-vollib are:
- Halley/Newton-Style Iteration: Leveraging rational initial guesses (Brenner–Subrahmanyam-type), this approach is traceable but unreliable in deep ITM/OTM cases.
- Jäckel’s LBR Algorithm: Utilizes a normalized Black function, subdividing the domain into four regions, each handled by a regime-specific rational approximation and followed by Householder(3) refinement for rapid convergence.
The library implements the four rational-initial-guess regimes of LBR as separate branches, followed by high-order root-polishing for machine-precision IVs.
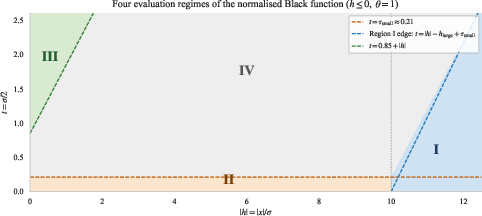
Figure 1: The four rational-initial-guess regimes of the normalized Black function used by the LBR algorithm. Each regime uses a separate rational approximation before Householder(3) refinement.
Library Capabilities and API Design
fast-vollib strategically mirrors the py_vollib interface while exposing advanced backend selection and compositional output. Major functionalities are:
- Model Coverage: Black-76, Black-Scholes, and Black-Scholes-Merton (including dividend yield).
- IV Solvers: Batch-capable Halley iteration; LBR solver modules for NumPy/Numba, torch.compile, JAX, and Triton-based CUDA kernels.
- Greeks: Full vectorized computation for Δ, Γ, Θ, ρ, ν; ability to co-compute via
get_all_greeks for computational efficiency.
- Vectorization: Universal NumPy broadcasting; multi-flag support; DataFrame integration for tabular workflows.
- Backend Abstraction: Environment- and keyword-driven selection of NumPy, PyTorch, or JAX; Triton for batched GPU IVs; autograd compatibility for deep learning pipelines.
- Output Flexibility: Results may be returned as pandas DataFrames, Series, NumPy arrays, Python dicts, JSON, or backend-native tensors.
- Drop-in Compatibility: Monkey-patching enables transparent substitution in legacy codebases.
- Differentiable Interfaces: PyTorch-mode autograd IVs for integration with neural calibration and deep hedging.
Implementation Structure
The package orchestrates a unified dispatch and preprocessing layer, handling input normalization, backend negotiation, and output formatting. All core pricing and IV routines are implemented as broadcasted array operations, ensuring backend parity. The LBR implementation features:
- Four-Region Rational Initial Guess: Selects the rational approximation regime based on normalized Black input.
- Three-Branch Transformed Objective: Handles Black call, put, and ATM cases separately.
- Householder(3) Method: Rapid, stable convergence for the IV root via iterative cubic correction.
- Triton Kernel: For fully fused, in-register, batched GPU inversion on CUDA pipelines.
Extensive parity checks and consistency tests guarantee congruent results across CPU, PyTorch, and JAX modes.
Practical and Theoretical Implications
The strong architectural focus on vectorized execution and pluggable hardware backends significantly lowers the friction for integrating robust IV inversion within differentiable, batched, and high-throughput quant research and production stacks. This is specifically valuable in modern deep learning-based calibration, neural volatility surface fitting, and real-time risk deployments, all of which require both computational efficiency and differentiability [buehler2019deep, horvath2021deep].
The ability to expose Jäckel’s highly accurate LBR solver in batch and GPU form factors removes historical bottlenecks in classic quant workflows, enabling more sophisticated model training and scenario analysis. Furthermore, the compatibility-first API ensures immediate adoption in existing codebases, minimizing migration and debugging costs.
Limitations and Future Directions
The current scope is constrained to European vanilla options under Black-style models. American, exotic, and local/stochastic volatility models remain out-of-scope, for which libraries such as QuantLib are more appropriate. The reliance on Python ≥ 3.11 and optional deep learning backends may present non-trivial environment configuration overhead for some users.
The Triton kernel is experimental and requires further validation for stability, especially on fringe CUDA hardware or atypical market regimes. Additional work may target generalization to other parametric models, support for path-dependent payouts, and enhanced support for mixed-model bi-temporal calibration workflows. Another logical development path would be enhanced autodiff support for alternative ML platforms and further reductions in latency for deployment-critical inference workloads.
Conclusion
fast-vollib offers a rigorously designed, high-performance, and extensible library for Black-Scholes-type option pricing, IV computation, and Greeks, built to interoperate seamlessly with both classic and ML-driven quant pipelines. Its support for hardware acceleration, backend-agnostic execution, and autograd-friendly IV inversion positions it as an essential tool for researchers and practitioners seeking scalable, differentiable, and maintainable IV infrastructure.

