- The paper introduces CurEvo, a framework that integrates curriculum learning with self-evolution to enhance video understanding by adaptively filtering and weighting pseudo-labeled QA supervision.
- It achieves performance improvements across multiple video QA datasets by leveraging three cognitive dimensions: perception, semantic recognition, and reasoning.
- The framework demonstrates robust model-agnostic gains by dynamically reallocating training focus to underperforming dimensions, mitigating issues like drift and mode collapse.
CurEvo: Curriculum-Guided Self-Evolution for Video Understanding
Introduction
CurEvo addresses the limitations of self-evolving video understanding systems, particularly their weakly controlled optimization and inability to structure difficulty progression. Traditional supervised methods and even advanced Video-LLMs are bound by static data distributions and annotation bias, impeding adaptability and generalization. CurEvo proposes a solution by integrating curriculum learning principles with self-evolution, dynamically organizing, filtering, and weighting pseudo-labeled QA supervision by cognitive level in an adaptive, multi-dimensional paradigm.
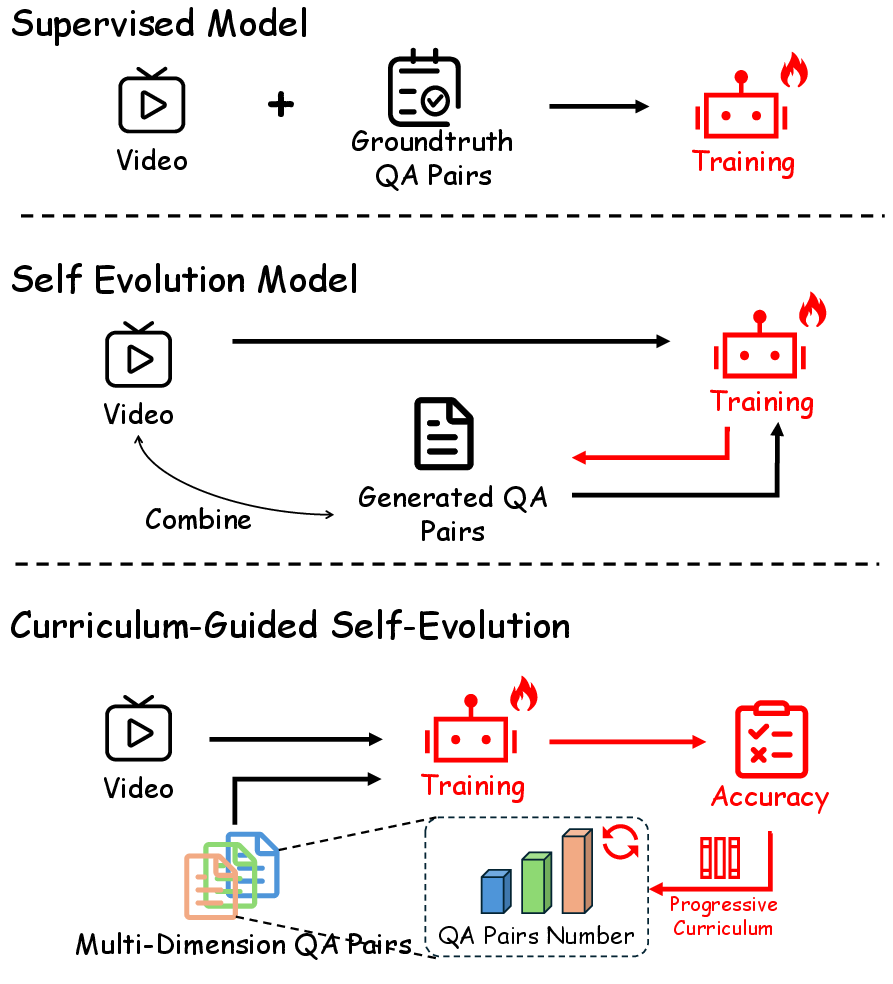
Figure 1: Supervised vs. self-evolving and CurEvo frameworks, highlighting CurEvo’s multi-dimensional curriculum control for autonomous video understanding evolution.
Framework Overview
CurEvo consists of three core modules: curriculum-guided self-evolution, multi-dimensional question generation, and type-adaptive evaluation. At each iteration, the system generates QA pairs from unlabeled videos, filters them via a dedicated evaluator, adaptively adjusts sampling ratios based on dimension-specific competence, and incrementally retrains the base model.
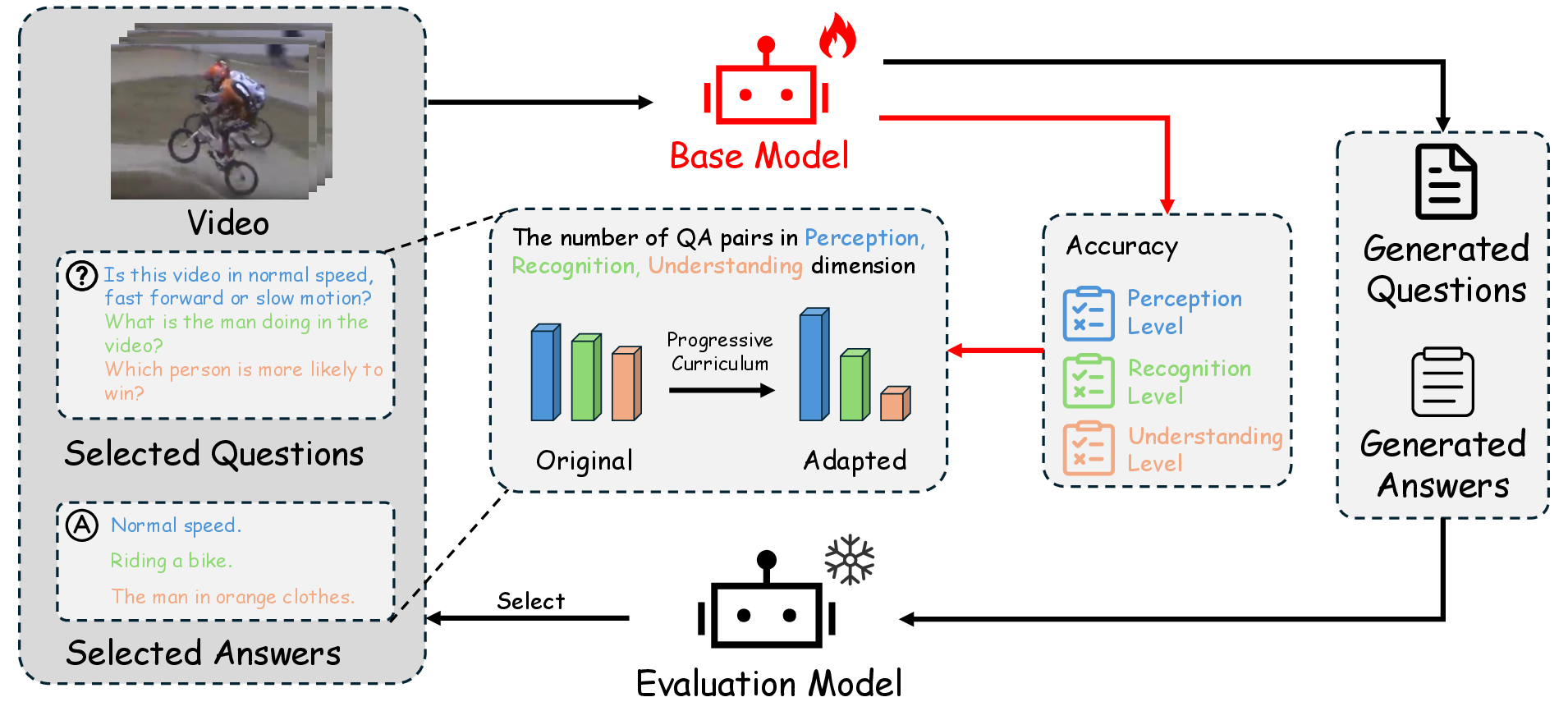
Figure 2: Schematic of the curriculum-guided self-evolution pipeline for progressive and balanced question-answer generation, evaluation, and learning.
The key novelty is adaptive ratio and threshold regulation across three cognitive dimensions: perception, semantic recognition, and reasoning. Feedback-driven reallocation ensures underperforming capabilities receive more optimization focus, addressing drift and mode collapse that plague naive self-evolution pipelines.
Multi-Dimensional Curriculum Construction
CurEvo generates questions along three axes:
- Perception: Structural/temporal cues (frame counting, motion coherence, localization), enabling fully self-supervised QA via pseudo labels.
- Semantic Recognition: Object, action, attribute, or scene understanding; supervision is based on LLM-evaluated answer consistency.
- Reasoning: Temporal, causal, or intent-based queries requiring high-level integration, filtered and weighted purely by evaluator inference.
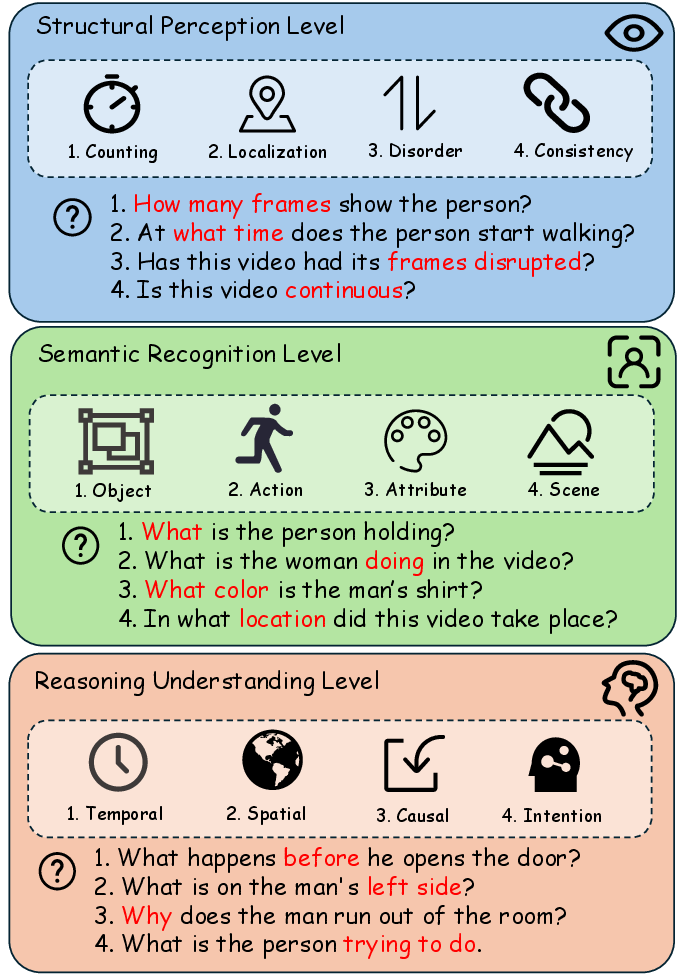
Figure 3: The graduated question-generation process, progressing from perception, through semantic recognition, to reasoning.
This progression ensures that the challenge and abstraction of tasks increases in synchrony with the model’s competence, yielding more robust semantic and causal representations.
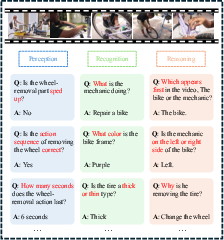
Figure 4: Examples of generated data for each question dimension show diverse and structured self-supervised QA pairs.
Type-Adaptive Evaluation and Optimization
CurEvo utilizes a unified evaluation protocol across question types, encompassing both heuristic and model-based scoring for question quality and candidate answer reliability. Each sample receives a normalized weight that combines its curriculum sampling ratio, evaluator confidence, and informativeness proxy, ensuring the loss landscape remains stable and selectively emphasizes challenging dimensions.
The adaptive sampling ratio rd(t) is dynamically modulated by recent feedback Ad(t), directly enforcing curriculum shifts in training. Final weighted optimization is conducted using standard cross-entropy loss, with empirical and theoretical justification for its compatibility with type-mixed QA data.
Experimental Results and Analysis
CurEvo is benchmarked on ActivityNet-QA, MSRVTT-QA, MSVD-QA, and NExT-QA, reflecting low, mid, and high-level cognitive challenges. Across all seven backbones, including Video-LLaVA, Video-LLaMA3, Qwen2.5-VL, and InternVL2.5, CurEvo delivers consistent accuracy and semantic-score improvements over vanilla baselines. The most substantial gains are observed in Qwen2.5-VL and LLaVA-OneVision, where the joint learning of low-level and high-level dimensions closes substantial gaps left by static pretraining.
Model-agnostic performance further demonstrates the importance of evaluator quality: stronger evaluation models yield larger and more robust curriculum-driven improvements, with diminishing returns observed when evaluators are weaker than the base model.
Ablative studies show that all three curriculum dimensions are crucial for maximal self-evolution efficacy, with perception and reasoning dimensions most ablated in datasets requiring temporal and causal understanding.
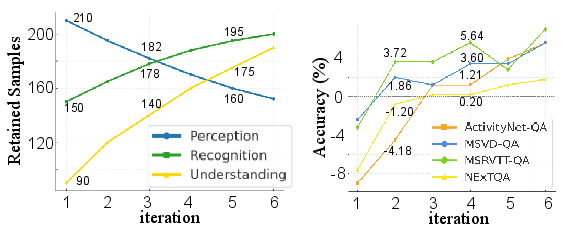
Figure 5: Left—Curriculum progression exemplified by dimension-wise retained sample numbers; right—Accuracy improvement across four VideoQA datasets through training iterations.
The iterations show that CurEvo adaptively reallocates learning focus and sample acceptance toward challenging dimensions over time, validating its theoretical curriculum control mechanisms.
Implications and Future Directions
CurEvo represents a significant step toward scalable, annotation-free video understanding systems capable of structured, autonomous improvement. Its curriculum mechanisms align well with the goal of bridging the gap between low-level perception and high-level causal reasoning, a core unsolved challenge in Video-LLM research. In the context of multi-modal pretraining and foundation models, the methods demonstrated in CurEvo can be generalized to other domains suffering from static, label-bound optimization cycles.
Potential future directions involve the extension of curriculum axes to support long-form video reasoning, cross-scene abstraction, and unsupervised discovery of novel reasoning predicates. Furthermore, the integration of reinforcement learning and active sampling, alongside alignment with human-centric evaluation protocols, could enable even more robust and adaptive self-evolving systems.
Conclusion
CurEvo establishes curriculum-guided self-evolution as a rigorous, effective approach for label-free video understanding. By balancing structured curriculum progression across perception, semantic recognition, and reasoning within an adaptive feedback loop, it outperforms previous unconstrained self-evolution strategies. The proposed architecture yields both practical and theoretical advances toward the realization of autonomous, self-improving multimodal reasoning systems, with broad implications for the future of unsupervised and continual learning paradigms in AI.
(2604.26707)

