- The paper introduces a novel Q-Gated Attention mechanism that transforms the Query into a learnable gating unit for efficient spatial feature modulation.
- The approach achieves state-of-the-art results on BEE24, SportsMOT, MOT17, and MOT20 benchmarks with improved accuracy and reduced computational overhead.
- The architecture tightly couples detection, motion estimation, and ReID tasks, demonstrating robust performance and adaptability across various backbones.
GateMOT: Q-Gated Attention for Dense Object Tracking
Introduction and Motivation
GateMOT addresses a fundamental limitation in dense object tracking—scaling attention mechanisms to crowded, high-resolution scenes without prohibitive computational overhead. Standard attention, while highly expressive, exhibits quadratic complexity and global feature mixing, which are unsuitable for dense motion estimation tasks. Existing paradigms, whether Kalman-based, sparse query-based, or decoupled deep motion modules, fail to leverage attention's feature selection strength while maintaining efficient, locality-preserving computation. GateMOT reconfigures the Query component of attention as a learnable gating unit, enabling efficient, spatially-aware element-wise modulation of Key features. This Q-Gated Attention (Q-Attention) forms the foundation for a tightly coupled, online multi-task decoder architecture.
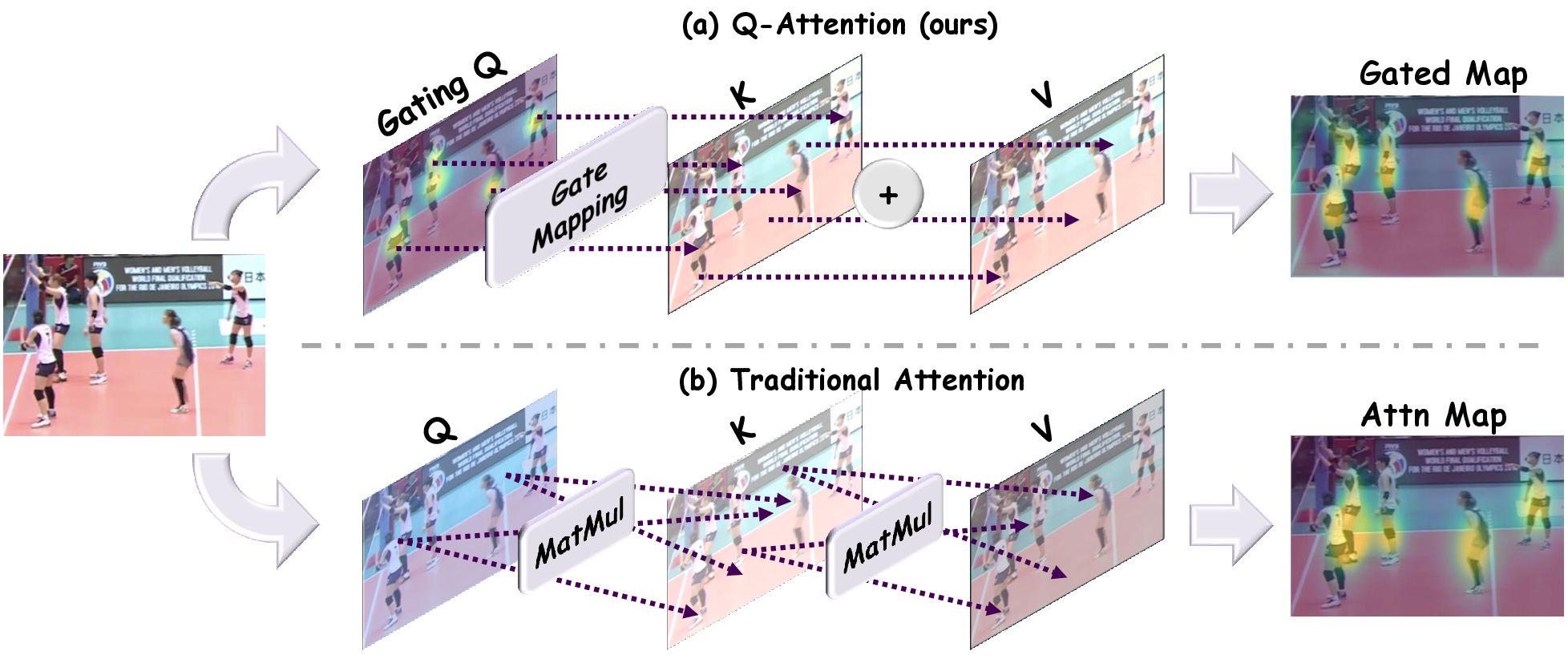
Figure 1: Comparison between Q-Attention (top) and vanilla attention (bottom); Q-Attention uses learned Gating-Q for element-wise gating, avoiding costly matrix multiplications involved in global aggregation.
Q-Gated Attention: Mechanism and Structure
Q-Attention innovates by replacing token-pair weighting in vanilla attention with a point-wise, Query-guided mechanism. The gating query (Gating-Q) produces a probabilistic mask via sigmoid activation, which modulates the Key features at each spatial location. The result is:
- Efficient spatial selection through element-wise multiplication.
- Local aggregation of gated Key for potent evidence extraction.
- Parallel Value stream as an unfiltered residual, preserving holistic feature integrity.
- Final fusion via 1×1 convolution yields task-adaptive representations.
Importantly, Q-Attention’s linear complexity (O(Nd2), O(Nd) for gating) enables deployment in parallel task heads and maintains computational practicality even at high resolution.
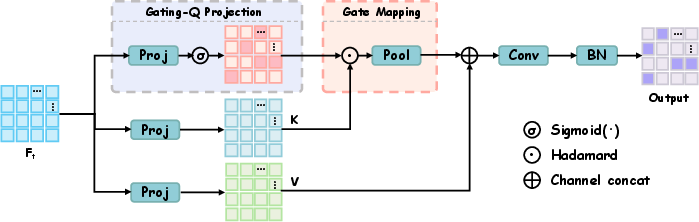
Figure 2: Architecture of Q-Attention module with learnable Gating-Q component modulating Key features and fused with a Value branch.
GateMOT Architecture and Tracking Protocol
GateMOT utilizes a DLA-34 backbone, encoding the current and previous frames plus prior center heatmaps into a high-resolution shared feature map. The multi-head Q-Attention decoder, built from separate detection, motion, and ReID heads, transforms this feature map into dense prediction maps: center heatmap, bounding box size, motion vectors, and embedding. For online association, detections are back-projected using motion vectors and matched with existing trajectories via geometry-first costs, followed by ReID-based refinement under geometric constraints. Confidence-adaptive updating of appearance templates is applied to suppress noise from occlusion.
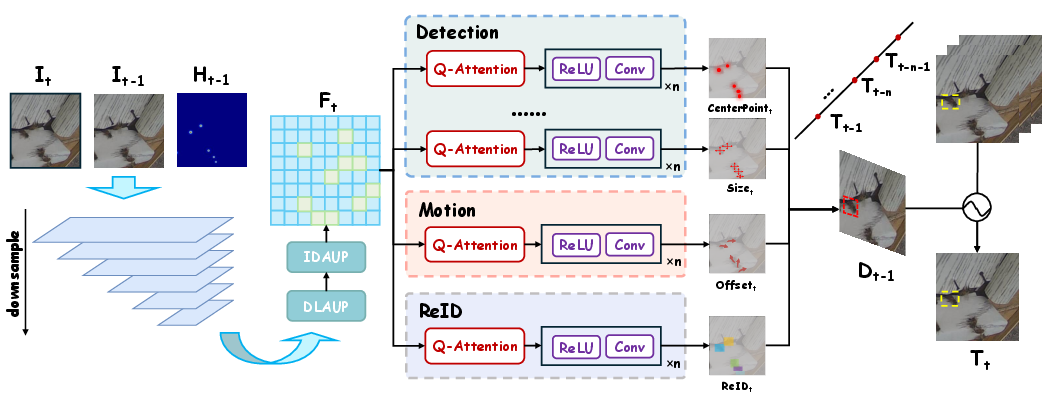
Figure 3: GateMOT architecture showing input frames and heatmap, encoder, multi-head Q-Attention decoder, and tracking protocol.
GateMOT achieves state-of-the-art performance on BEE24, SportsMOT, MOT17, and MOT20:
- BEE24: HOTA 48.4, MOTA 67.8, IDF1 64.5; lowest identity switches among all baselines.
- SportsMOT: HOTA 76.3, MOTA 96.5, IDF1 79.0; superior AssA and identity discrimination.
- MOT17: HOTA 63.3, MOTA 78.0, IDF1 77.9; balanced localization and association.
- MOT20: HOTA 62.8, MOTA 77.6, IDF1 77.3; robust tracking in highly crowded scenes.
Across all datasets, GateMOT demonstrates consistent gains in HOTA and IDF1, outperforming vanilla attention, convolutional, and deformable attention heads both in accuracy and computational efficiency.
Ablation Studies and Component Analysis
Extensive ablation reveals:
- One Q-Attention layer is optimal; stacking further layers provides marginal benefit and can degrade localization precision.
- Q-Attention surpasses vanilla and deformable attention in both accuracy and efficiency, maintaining high throughput and practical memory footprint under resolution scaling.
- Key components—Q-gating, local aggregation, adaptive fusion—are necessary for full benefit; removing any degrades performance toward convolutional baselines.
- SIoU loss outperforms L1 for box regression, and ReID loss weight λid=1.0 provides the best trade-off.
- The method is backbone-agnostic; transfer to ResNet-50 and YOLOX-X yields competitive HOTA without retraining decoders.

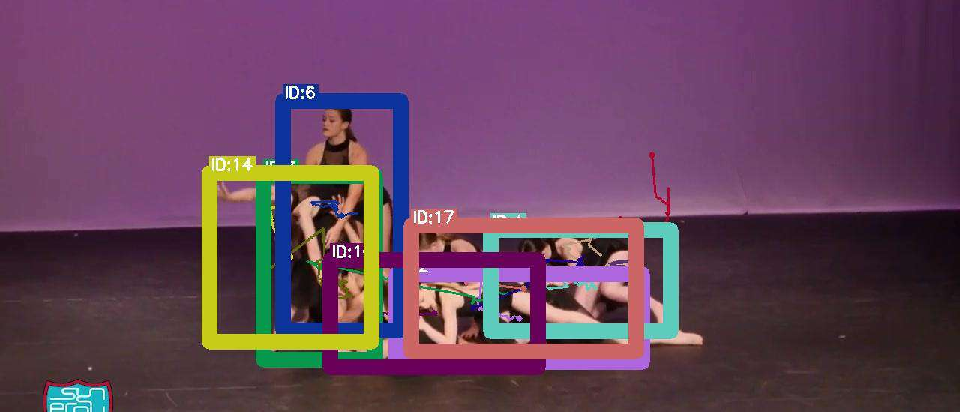

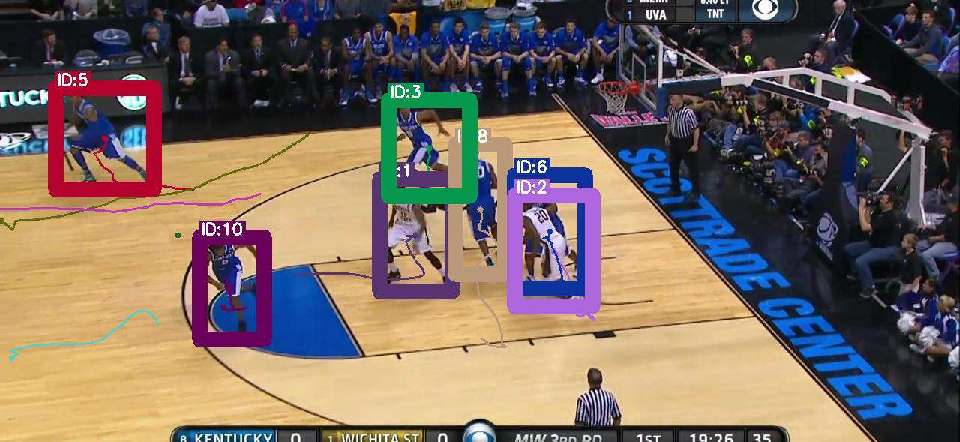
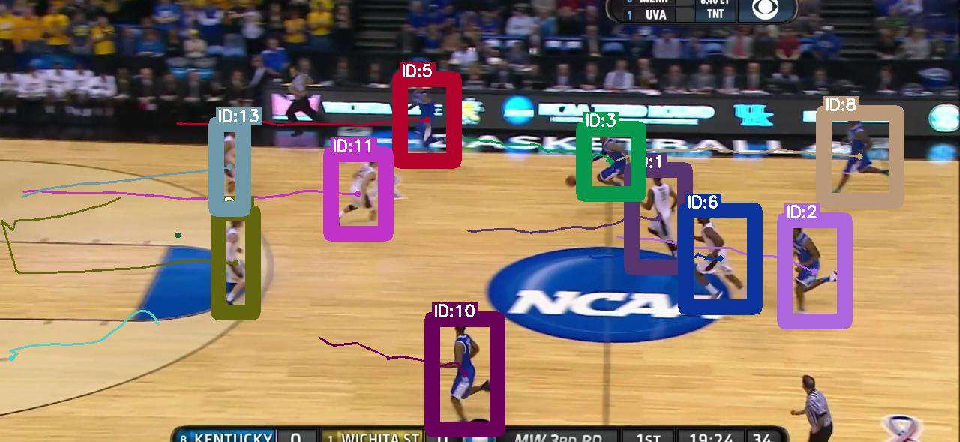
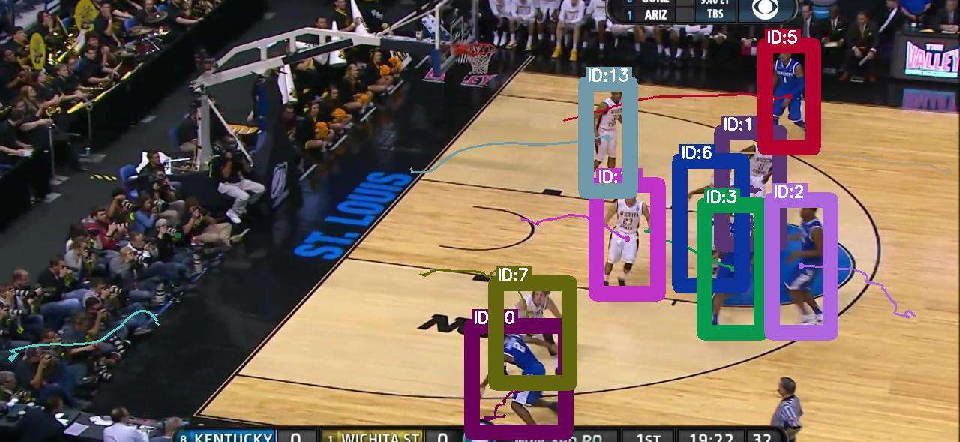
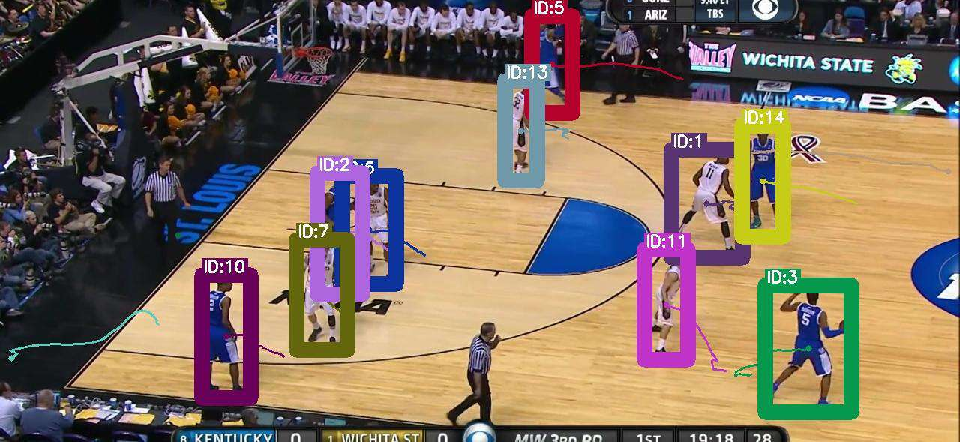

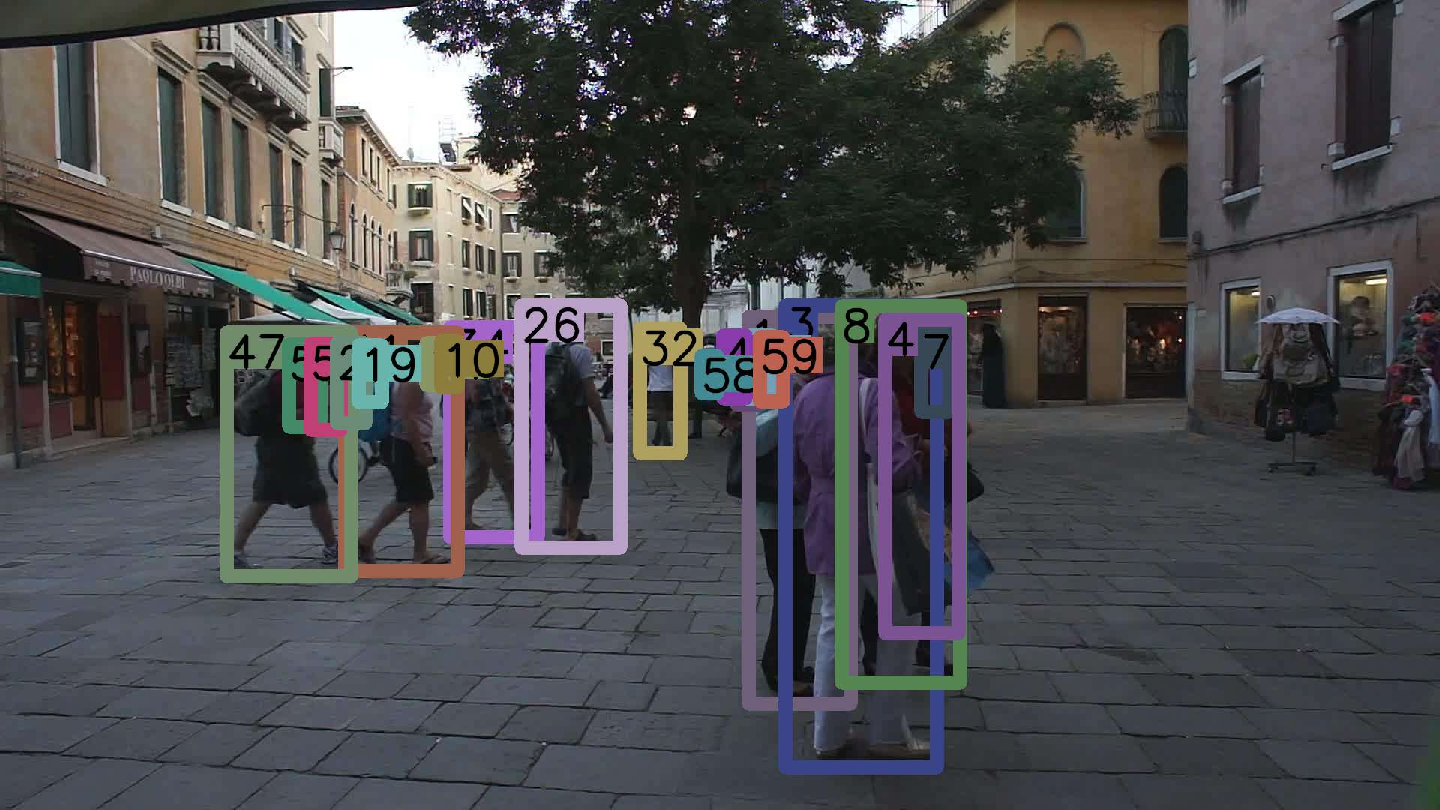

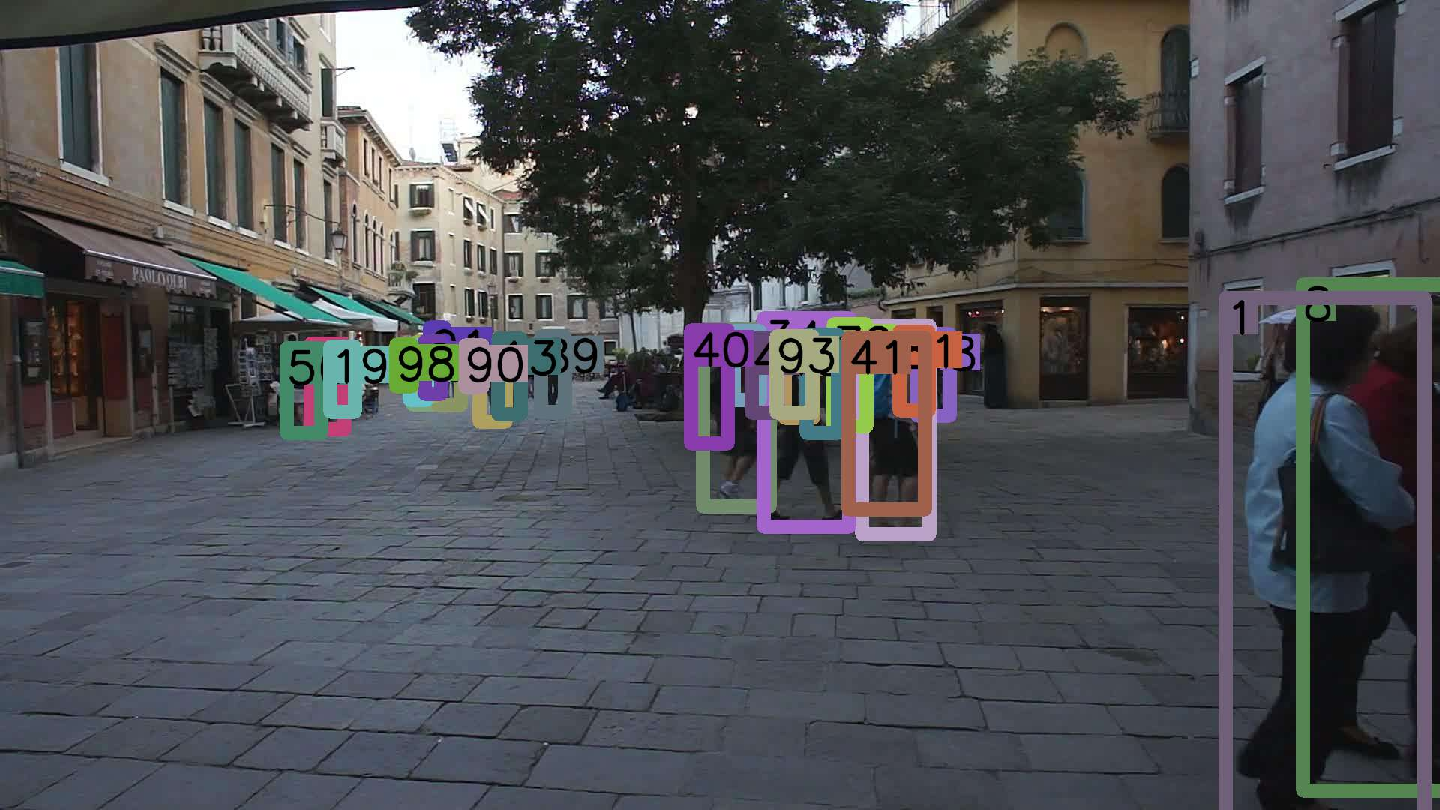
Figure 4: Decoder architecture comparison (Q-Attn, Conv, Attn) visualized on MOT17 validation; Q-Attn achieves better detection and association, especially in occlusion/crowding.
Failure Modes and Robustness
Qualitative analysis highlights that GateMOT struggles in sparse-scene long-occlusion cases and rapid-camera-motion scenarios. The local evidence aggregation of Q-Attention suppresses cross-object contamination, but cannot compensate for insufficient local information during prolonged gaps or abrupt viewpoint changes, resulting in missed reactivation or increased identity switches.
Figure 5: Failure cases—long occlusion and camera motion induce missed track reactivation and identity confusion, illustrating limitations of local evidence aggregation.
Theoretical and Practical Implications
GateMOT demonstrates that Query-transformed gating mechanisms allow spatially precise, low-cost attention modeling in dense tracking tasks. This approach enables tightly coupled multi-task decoders, producing task-specific yet spatially consistent features, improving detection, motion estimation, and ReID jointly. The method's backbone-agnostic design and robust scaling behavior suggest its utility as a general building block for dense prediction tasks in large-scale vision systems.
Practically, GateMOT is deployable in real-time settings where dense spatial resolution and high throughput are required, such as autonomous driving and robotic perception in urban or crowded environments.
Conclusion
GateMOT introduces a practical reformulation of attention for dense object tracking, achieved by transforming Query into a gating unit for efficient, spatially-aware feature selection. The Q-Attention mechanism yields state-of-the-art accuracy and identity stability across challenging MOT benchmarks, combining the discriminative selectivity of attention with computational efficiency. The framework’s architectural flexibility and superior accuracy-efficiency trade-off present a promising direction for multi-task dense prediction and future MOT architectures. Further research may focus on augmenting long-range memory and enhancing track reactivation for sparse and rapidly changing scenes.

