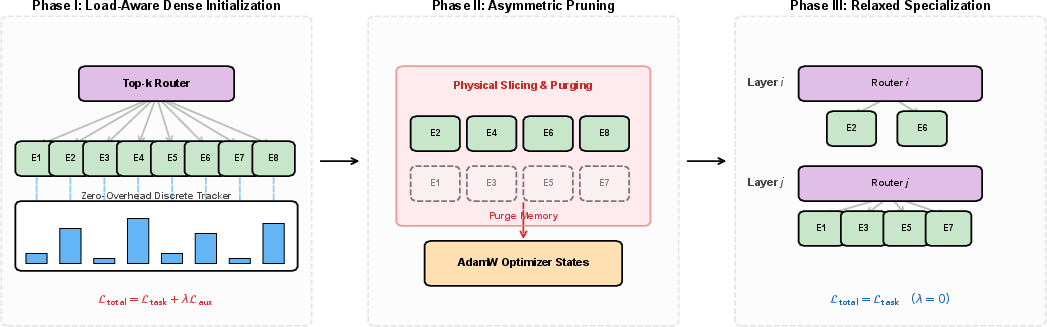
- The paper demonstrates that DMEP dynamically prunes underutilized experts to align module capacity with actual routing demands.
- It introduces a three-phase framework using online routing statistics to structurally eliminate redundant parameters, enhancing training throughput.
- Empirical evaluations on Qwen3-0.6B and Qwen3-8B show parameter reductions of 35–43% with maintained or improved accuracy.
Adaptive, Fine-grained Module-wise Expert Pruning for Efficient LoRA-MoE Fine-Tuning
The LoRA-MoE paradigm enhances parameter-efficient fine-tuning by combining LoRA's low training cost with MoE's conditional computational capacity. However, typical LoRA-MoE implementations assume a fixed, uniform allocation of experts across all Transformer modules, irrespective of functional heterogeneity. This uniform configuration ignores module- and layer-specific requirements, resulting in localized over-provisioning and latent parameter redundancy. Empirical profiling of expert routing during fine-tuning exposes substantial intra-layer and intra-module heterogeneity: attention projection modules demonstrate skewed routing, with token traffic concentrated in a minority of experts, while MLP projections distribute tokens more evenly.
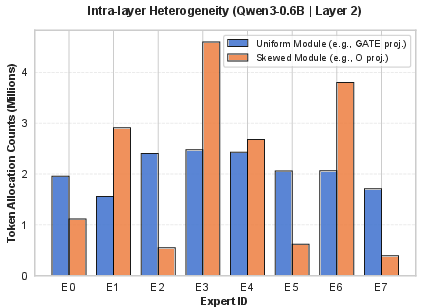
Figure 1: Intra-layer heterogeneity of expert utilization—O_PROJ attention projection shows dominating experts, while GATE_PROJ MLP projections distribute tokens uniformly.
Uniform layer-wise allocation thus fails to reflect the distinct demands of attention versus feed-forward modules, leading to severe capacity over-provisioning.
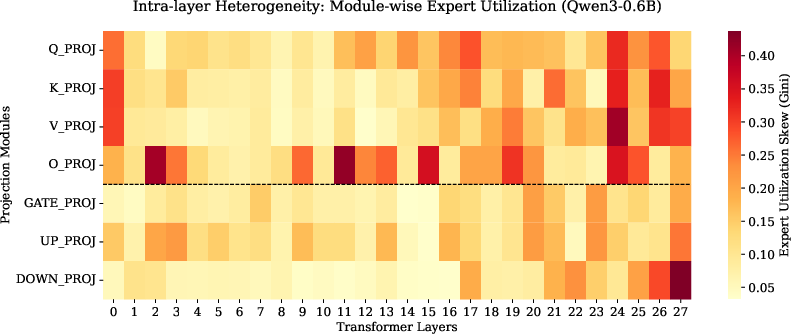
Figure 2: Module-wise utilization heatmap, displaying extreme load imbalance (dark red) in O_PROJ, versus uniform routing (light yellow) in GATE_PROJ, highlighting intra-layer heterogeneity and redundancy.
Moreover, persistent enforcement of auxiliary load-balancing loss (Laux) during training increases routing entropy and inhibits task-driven specialization even after routing preferences stabilize. Disabling Laux post-exploration yields sharper expert specialization and slightly higher accuracy.
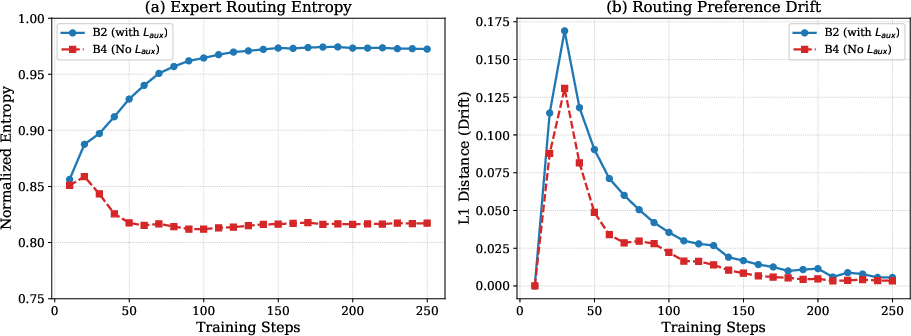
Figure 3: Routing entropy with and without Laux; lower entropy and rapid drift stabilization achieved after auxiliary loss removal.
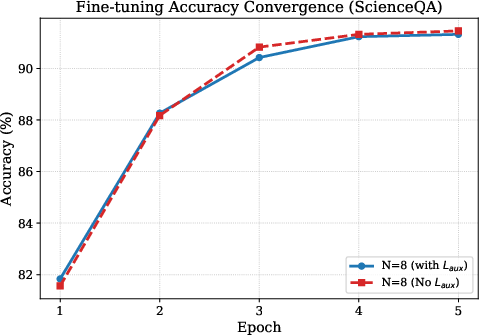
Figure 4: Fine-tuning accuracy convergence, showing peak accuracy with load-balancing disabled after routing preferences stabilize.
Dynamic Module-wise Expert Pruning (DMEP) Framework
DMEP introduces a dynamic, module-adaptive approach wherein expert capacity is progressively pruned based on observed online routing statistics:
Empirical Evaluation
Extensive experiments on Qwen3-0.6B and Qwen3-8B across ScienceQA, OpenBookQA, and GSM8K confirm DMEP's efficacy. DMEP reduces trainable parameters by 35–43% and improves training throughput by ~10%, with accuracy maintained or surpassed relative to uniform MoE baselines. For instance, on OpenBookQA with Qwen3-8B, DMEP cuts parameters from 185.2M to 107.9M (41.7% reduction) while preserving accuracy at 95.00%. On GSM8K with Qwen3-0.6B, accuracy improved from 17.00% to 19.00% under a 40.7% parameter reduction.
DMEP's impact is pronounced in smaller models, where redundancy removal leads to modest accuracy gains; in larger models, benefits are seen primarily in efficiency. Aggressive threshold adjustments provide controllable trade-offs: increasing τ to 0.15 or 0.20 further reduces parameters and increases throughput but yields minor accuracy losses. Early pruning before adequate exploration reduces accuracy, while late pruning retains more redundancy.
Structural Analysis of the Post-Pruning Architecture
DMEP's pruning outcomes reflect the statistical routing heterogeneity. Post-pruning heatmaps reveal sparse expert retention in attention projections—often only 4–5 experts per module—while MLP projections retain 7–8 experts to support broad knowledge distribution. This observed asymmetry validates DMEP's adaptive capacity allocation, confirming alignment between utilization patterns and architectural compression.
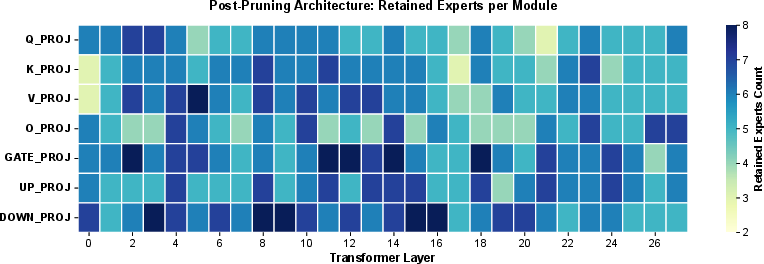
Figure 6: Post-pruning expert heatmap—attention projections sparsified with fewer retained experts, MLP projections maintain broad capacity.
Implications and Future Directions
DMEP systematically overcomes key bottlenecks in symmetric LoRA-MoE fine-tuning: it delivers module-adaptive compression, removes optimizer-state overhead by structural parameter slicing, and enables sharper specialization by relaxing load-balancing constraints post-routing stabilization. The framework is deployable for both small and large models and allows practitioners to select desired efficiency-accuracy trade-offs. Future developments may extend online pruning to multi-task or dynamic environments, further optimizing conditional computation and expanding the scalability frontier for resource-constrained LLM fine-tuning.
Conclusion
DMEP provides a robust, task-adaptive framework for parameter-efficient fine-tuning, leveraging module-wise utilization profiling to prune redundant experts and optimize downstream specialization. Across empirical benchmarks, DMEP consistently reduces parameter footprint and accelerates throughput without sacrificing accuracy, advancing the Pareto frontier for fine-tuned LLMs. The alignment between statistical routing heterogeneity and structural compression underscores DMEP's effectiveness in tailoring capacity to functional module demands (2604.26340).