Folding Tensor and Sequence Parallelism for Memory-Efficient Transformer Training & Inference
Abstract: We present tensor and sequence parallelism (TSP), a parallel execution strategy that folds tensor parallelism and sequence parallelism onto a single device axis. In conventional multi-dimensional parallelism layouts, tensor parallelism (TP) shards model weights while sequence parallelism (SP) shards tokens, reducing per-device parameter or activation memory, respectively. Traditionally, each scheme is assigned its own mesh dimension. TSP instead assigns each rank both a weight shard and a sequence shard, reducing both parameter and activation memory along the same device axis. We implement this design with two runtime schedules. For attention, ranks iterate over broadcast parameter shards and reconstruct context through a sequence-wise key/value exchange. For gated MLPs, weight shards circulate in a ring while partial outputs accumulate locally. By sharding both weights and activations across the same devices, TSP trades additional communication volume for reduced memory overhead. We provide a theoretical communication and memory analysis, describe our implementation of TSP attention and gated MLP blocks, and benchmark TSP against TP, SP, and TP+SP. These results position TSP as a hardware-aware alternative for long-context and memory-constrained model training, and as a viable axis of parallelism in concert with existing parallelism schemes such as pipeline and expert parallelism for dense and mixture-of-expert models.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview: What this paper is about
This paper is about a new way to train big AI LLMs (Transformers) using many graphics cards (GPUs) more efficiently. The authors introduce “TSP” (Tensor-and-Sequence Parallelism), a technique that splits both the model’s weights and the input text across the same group of GPUs. This saves memory on each GPU, which is especially helpful when training models with very long inputs (long context).
Think of a Transformer like a huge recipe book (the “weights”) used to cook meals (process text). Traditional methods either split the recipe book among cooks (GPUs) or split the meal prep across different parts of the meal (tokens). TSP does both at once with the same team of cooks, so each cook has less to hold in their hands.
What questions the paper asks
The authors focus on simple, practical questions:
- Can we reduce memory per GPU by splitting both the model and the input text across the same set of GPUs?
- If we do that, can we still run fast enough, even though GPUs will need to talk to each other more?
- How should we organize that communication so it fits real hardware (like AMD MI300X or NVIDIA systems) well?
- Is this better than standard methods that split the model and the input along separate “axes” (TP+SP), or than using just one of them (TP or SP)?
How the method works (in everyday terms)
First, a few quick definitions in plain language:
- Weights: The learned “knowledge” of the model, like pages in the recipe book.
- Tokens/sequence: The stream of words/characters the model reads, like the ingredients lined up in order.
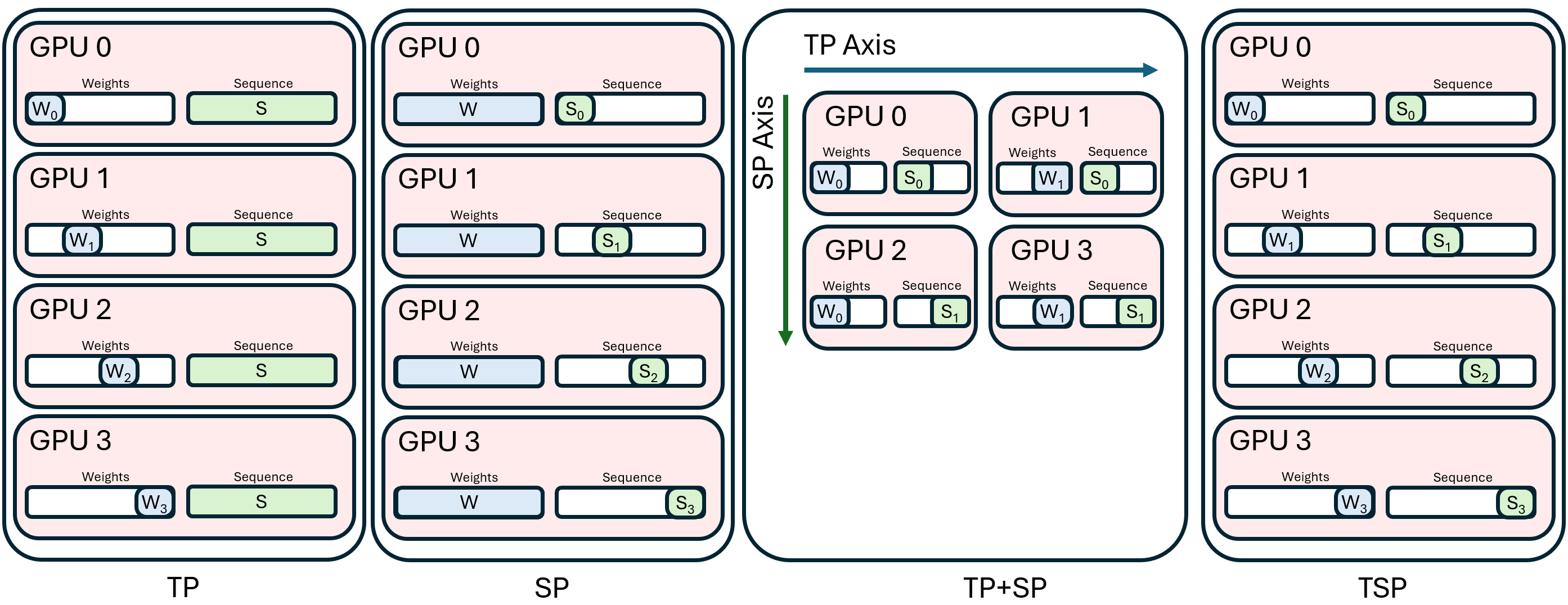
- Tensor Parallelism (TP): Split the model’s weights across GPUs so each one stores fewer pages.
- Sequence Parallelism (SP): Split the input tokens across GPUs so each one handles fewer words.
- TSP: Do both together on the same group of GPUs.
Analogy: Imagine eight cooks working together.
- TP alone: Each cook keeps different pages of the recipe book (weights), but all cooks see the full list of ingredients (full input).
- SP alone: Each cook is responsible for only part of the ingredient list (tokens), but every cook keeps the entire recipe book (all weights).
- TSP: Each cook keeps only some recipe pages and some ingredients. This cuts both kinds of memory in one go.
How TSP runs the two main parts of a Transformer:
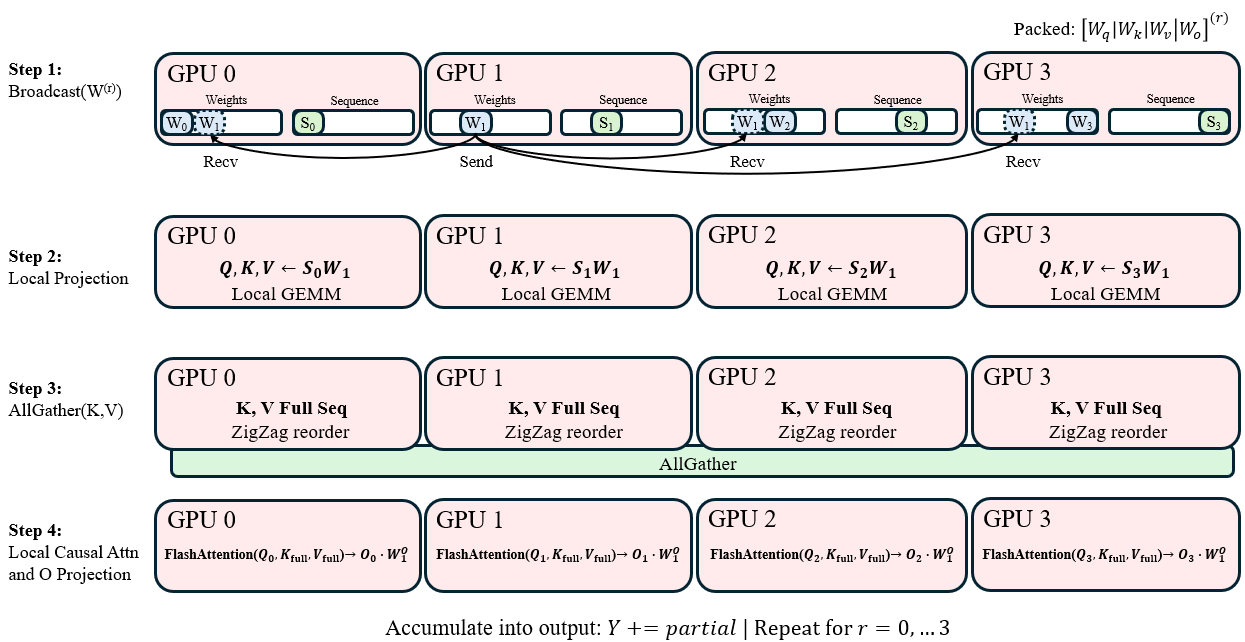
- Attention (the part that decides which earlier words matter for the current word):
- Each cook (GPU) temporarily shares their piece of the recipe pages needed for attention (weights) so everyone can compute their share for their local ingredients.
- Then, cooks exchange the “key/value” information (summaries of what’s in the sequence) so each can correctly “pay attention” to the right words.
- In short: brief weight sharing + a single, well-timed exchange of key/value info across the group.
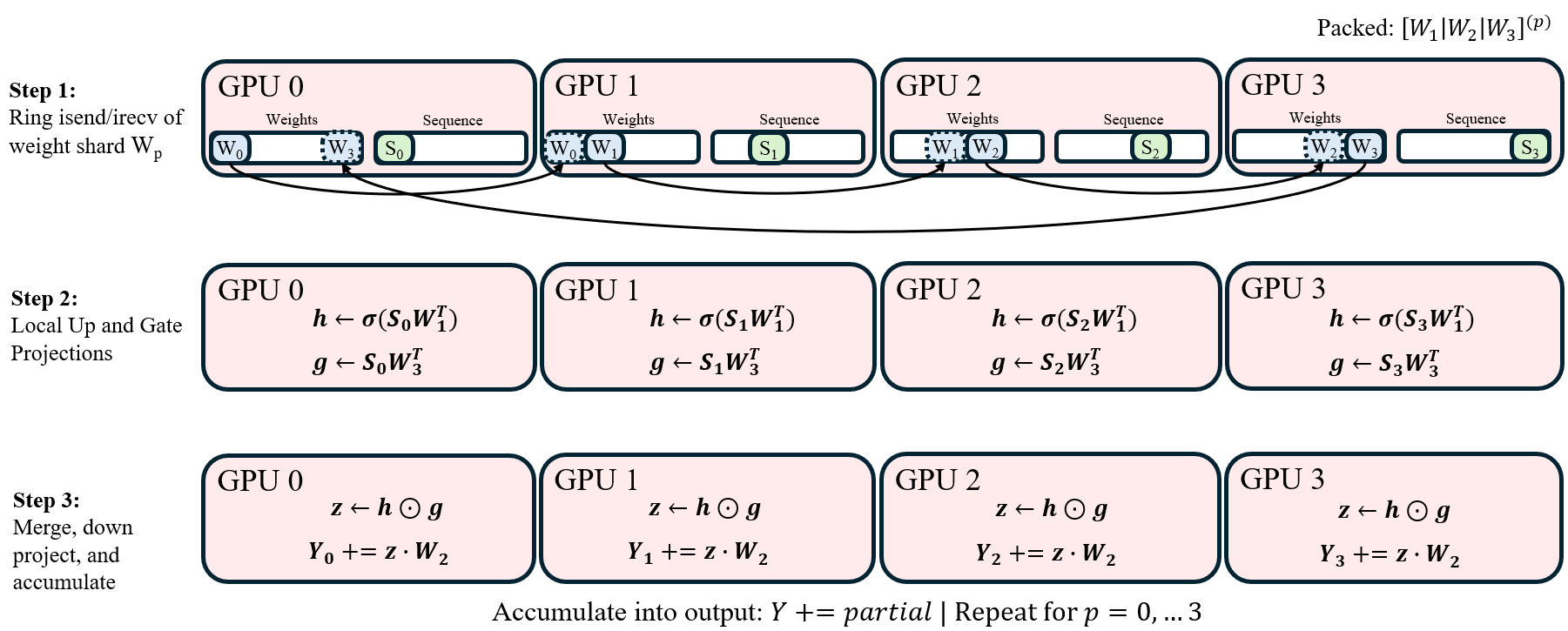
- MLP (the feed-forward “thinking” layer after attention):
- The cooks pass their MLP weight chunks around in a ring (like passing a bowl around the table).
- Each cook applies every chunk to their local ingredients and adds up the results.
- Because the sequence stays local, they avoid a big “sum-everything” step that standard methods need.
Why this helps hardware:
- By folding both splits onto the same axis, the whole group of GPUs can often fit within a single server box (intra-node high-bandwidth links), avoiding slower links between servers.
- The authors carefully schedule communication so much of it overlaps with computation, hiding a lot of the waiting time.
What the researchers found and why it matters
Main findings in simple terms:
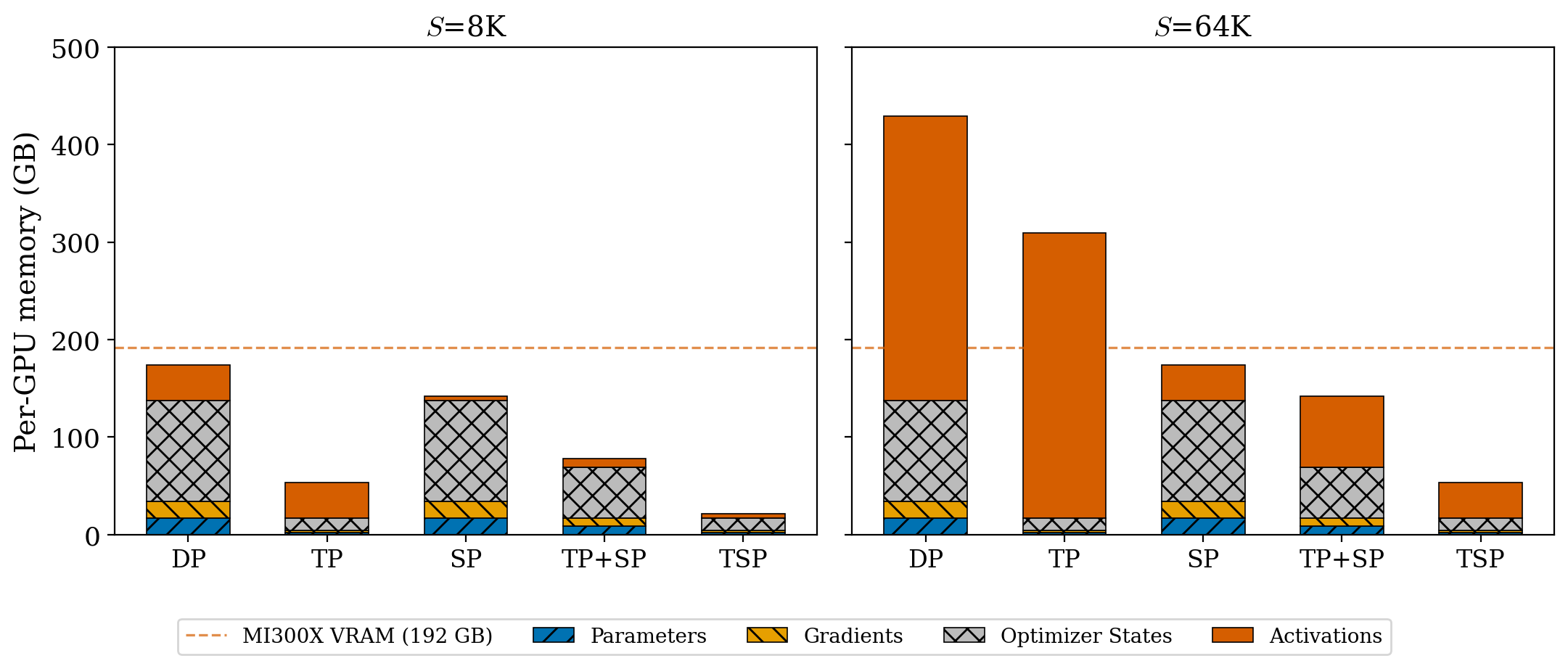
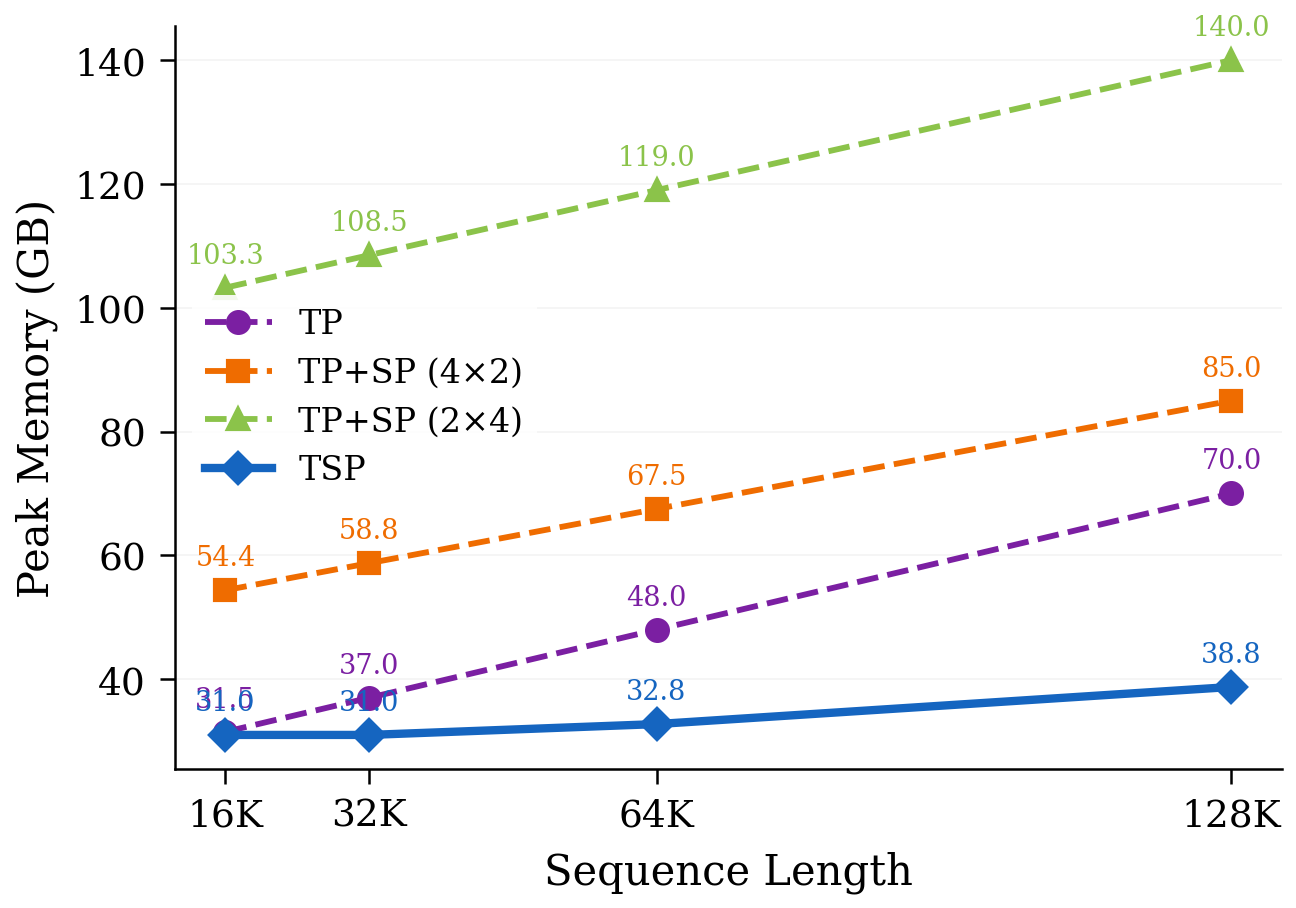
- Memory per GPU goes down for both the model weights and the activations (temporary results). TSP is the only single-axis method in their study that shrinks both at the same time by the same factor.
- At short sequences (short inputs), weight memory is the main problem; at long sequences, activation memory becomes the main problem. TSP helps in both cases, so it’s balanced and future-proof as contexts grow.
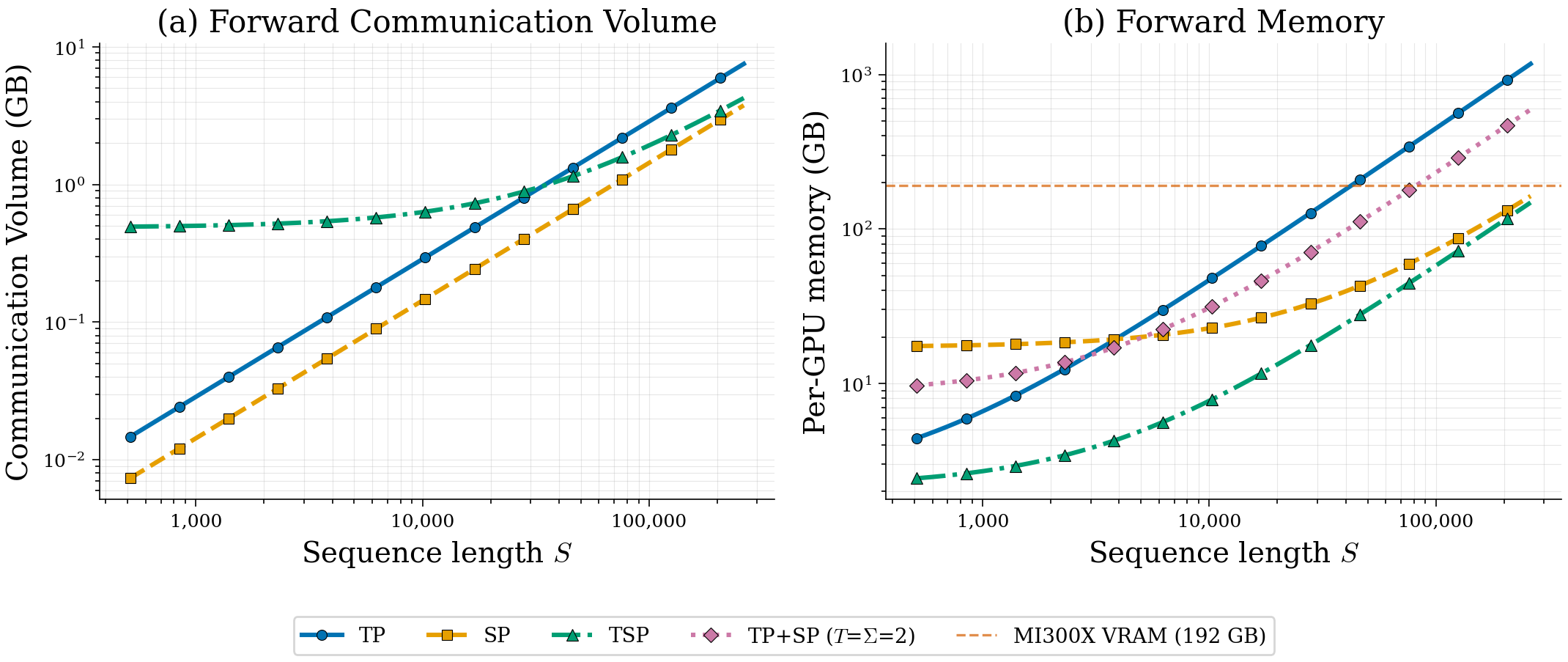
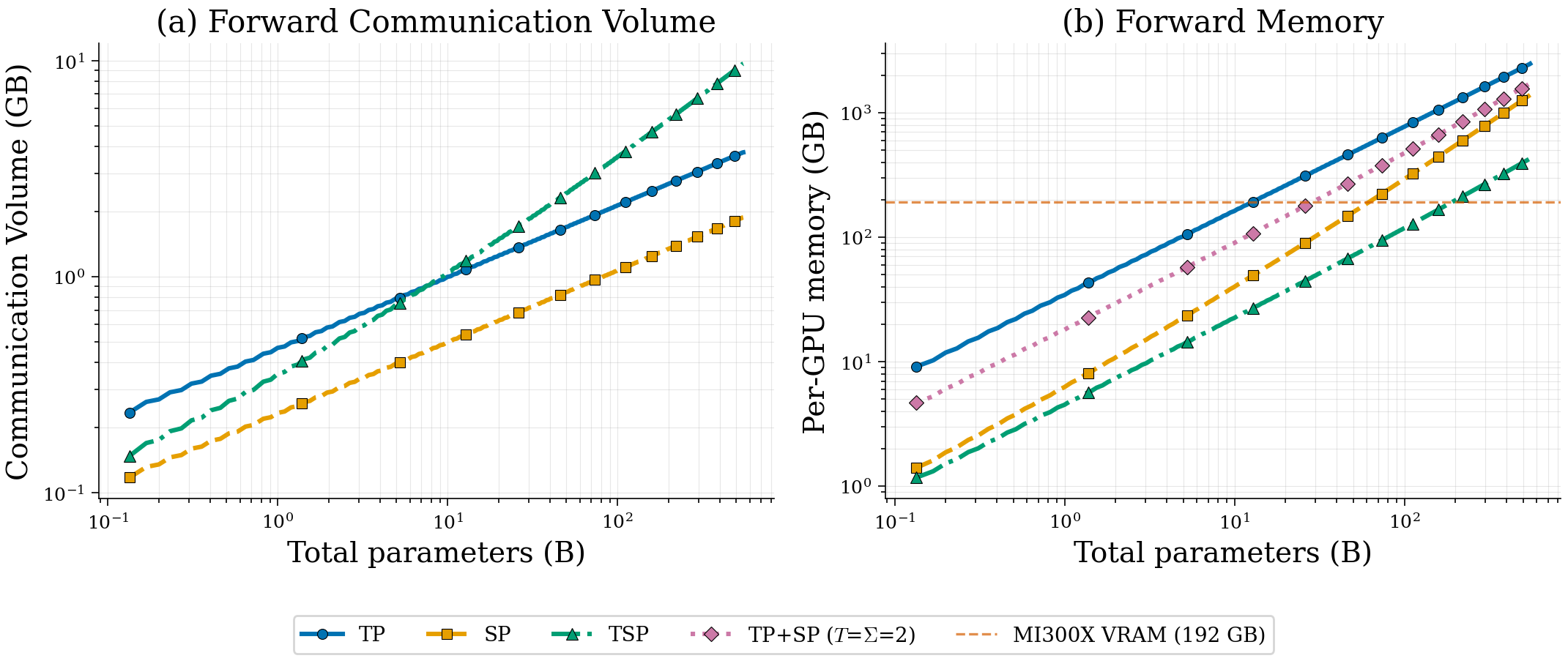
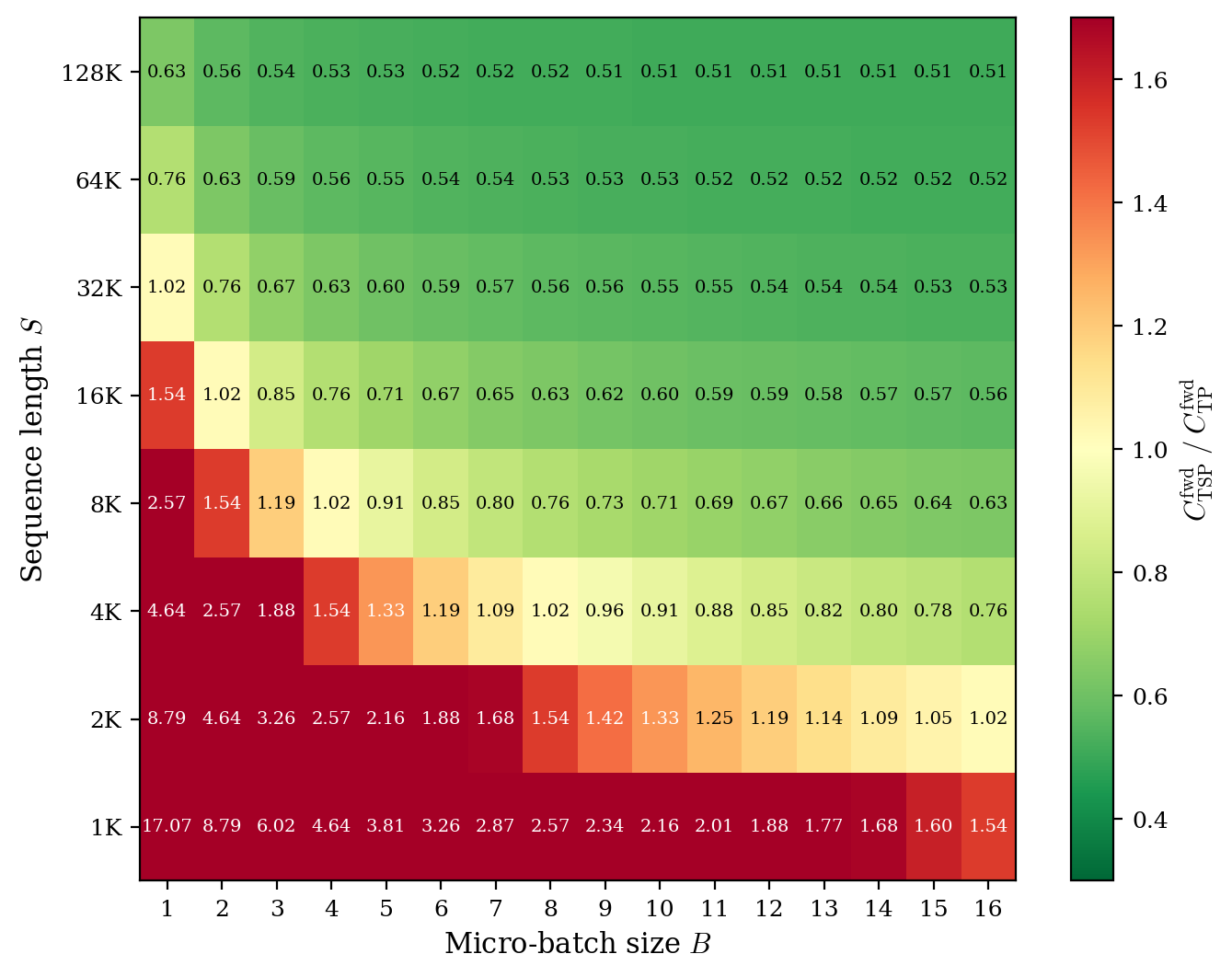
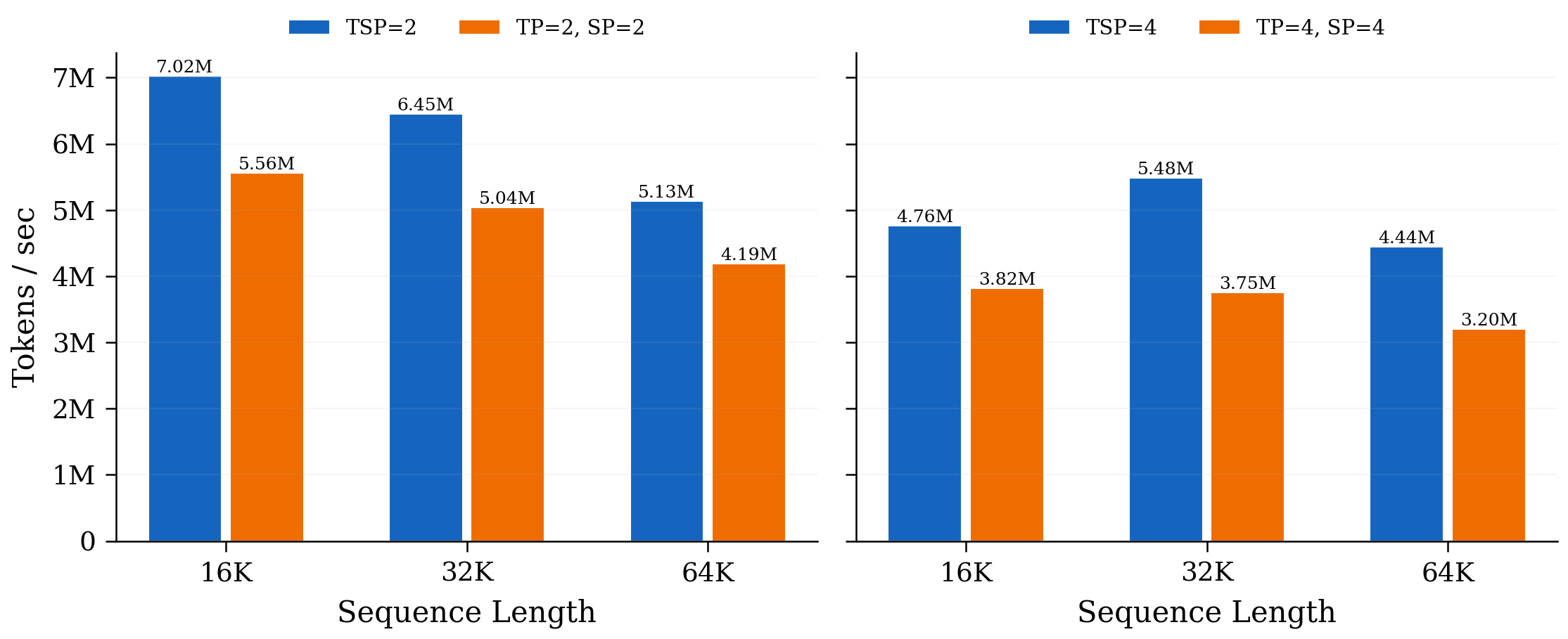
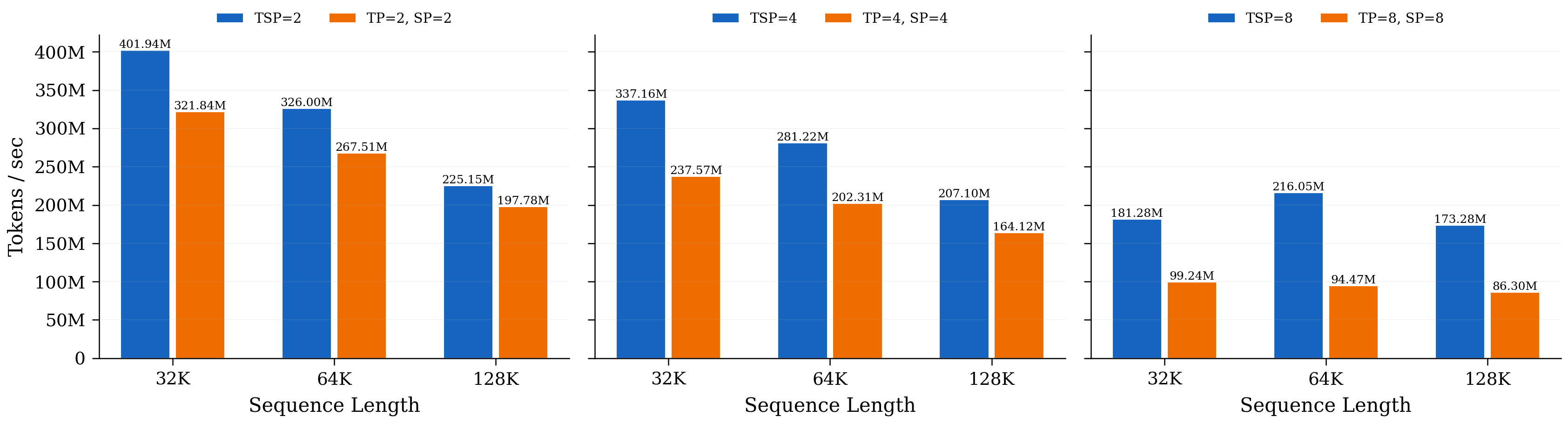
- Communication trade-off: TSP moves more weights around than some other methods, but it reduces duplicate storage and uses communication patterns that can be overlapped with computation. As sequences or batch sizes grow, TSP’s total communication can match or beat standard tensor-parallel setups.
- A handy rule from their theory: when micro-batch size times sequence length is bigger than about 8×(model width), TSP’s communication can be lower than pure tensor parallelism.
- Compared to SP: TSP and SP have similar “attention-related” communication, but TSP also shards the model weights so it uses much less memory for parameters, gradients, and optimizer states.
- Compared to TP+SP on two separate axes: TSP uses fewer total GPUs to get the same memory benefits, which frees up more replicas for data parallelism (more throughput), and often keeps all traffic within fast intra-node links.
Why it matters:
- Training long-context models (for example, reading tens of thousands of tokens at once) often runs out of memory. TSP makes this much more manageable on today’s hardware.
- With lower memory per GPU, teams can run bigger batches or bigger models on the same machines, improving speed and cost.
- Keeping groups within a single node can make runs more stable and faster, because intra-node GPU links are much faster than inter-node links.
Practical approach and hardware-fit
The authors:
- Give a clear “how-to” for TSP in both attention and MLP blocks.
- Provide a mathematical analysis of memory, computation, and communication for TSP versus DP, TP, SP, and TP+SP.
- Show schedules that overlap communication with compute:
- Attention: pack-and-broadcast small weight shards while gathering key/value info and running the attention kernel.
- MLP: rotate weights in a ring while doing compute, so time isn’t wasted waiting.
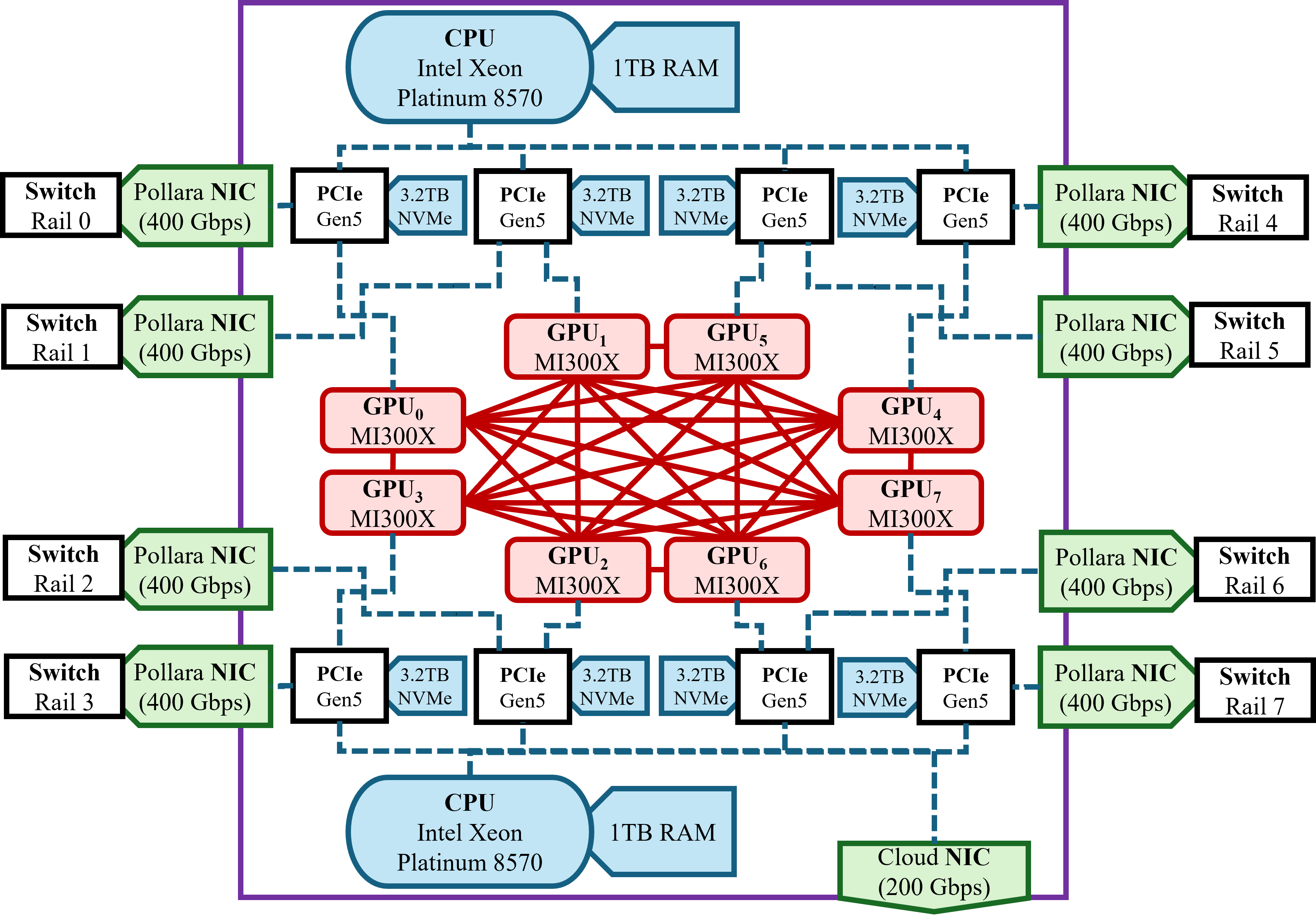
- Discuss how this maps to AMD MI300X nodes with Infinity Fabric (and also works well for NVLink/NVSwitch), making TSP hardware-aware.
So what’s the impact?
In short:
- TSP makes it easier to train and run large Transformers with long inputs on limited hardware by saving GPU memory on both the model weights and the activations at the same time.
- It can be combined with other parallel methods (like pipeline or expert parallelism) for even larger or more specialized models.
- Because it often keeps communication inside a single server, it can be faster and simpler to deploy in real clusters.
- As LLMs keep growing and use longer contexts, techniques like TSP will help keep training affordable and practical.
Overall, TSP is a smart, balanced way to share both the “recipe pages” and the “ingredients” among the same group of GPUs, trading a bit more talking between GPUs for a lot less memory per GPU—exactly what’s needed to push to bigger, longer-context models.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of concrete gaps and unresolved questions that future work could address:
- Lack of empirical validation: no end-to-end training or inference benchmarks comparing TSP vs TP, SP, and TP+SP on real hardware (throughput, latency, scaling efficiency, stability), despite extensive theoretical analysis.
- Missing backward-pass algorithms: forward schedules are provided, but detailed backward schedules (including exact collective types, reduction ownership, ordering, and overlap) are not specified or evaluated.
- Gradient synchronization ambiguity: the paper upper-bounds gradient communication as an all-reduce; it does not implement or quantify the tighter reduce-scatter/sum-to-owner cost or show how it integrates with autograd and optimizer updates.
- Inference is not described: despite “Inference” in the title, there is no TSP schedule for autoregressive decoding (K/V cache layout, incremental updates, latency, batching/streaming behavior, cache residency).
- Multi-node scalability unanswered: TSP is framed around an 8-GPU intra-node fabric; performance, overlap, and stability on inter-node links (InfiniBand/Ethernet), and hierarchical/multi-level TSP designs, are not explored.
- Communication–compute overlap efficacy unquantified: the paper proposes overlap strategies but provides no timelines, stall breakdowns, or achieved overlap ratios under varying batch/sequence lengths and D.
- Peak memory omissions: temporary communication/workspace buffers (e.g., K/V all-gather buffers, reorder scratch, GEMM workspaces, broadcast staging) are omitted from the memory model; peak VRAM headroom and OOM thresholds are therefore uncertain.
- Load balancing of causal attention: zigzag partitioning is assumed to balance work, but there is no quantitative analysis of imbalance (e.g., per-rank utilization variance) or sensitivity to head bucketing B_h and micro-batch sizes.
- Sensitivity to grouped-query attention (GQA): formulas include g, but there are no experiments quantifying TSP’s comm/compute crossover and memory impacts vs g and varying head counts.
- Alternative sequence-exchange primitives: TSP fixes attention to an all-gather K/V exchange; it does not evaluate ring or all-to-all variants under TSP, nor provide criteria for when each is preferable given topology and kernel arithmetic intensity.
- Interaction with pipeline parallelism (PP): how TSP composes with PP (stage boundaries, bubble size, inter-stage comm overlap, activation rematerialization across PP) is not specified or benchmarked.
- Interaction with ZeRO/optimizer sharding: it is unclear how TSP’s parameter/optimizer sharding composes with ZeRO Stage 2/3 (state partitioning, optimizer step locality, communication conflicts) or whether combining them yields net wins.
- Checkpointing/fault-tolerance: there is no description of checkpoint formats for folded sharding (weight/optimizer-state ownership), resume semantics, or recovery under rank/node failure.
- Numerical stability and determinism: the ring MLP accumulation order and iterative accumulation across weight shards may introduce non-determinism or increased rounding error; effects on convergence and reproducibility are not studied.
- Kernel efficiency and tiling: the impact of head bucketing and shard-iterative GEMMs on kernel utilization (SM occupancy/warp efficiency/MIOpen/cuBLASLt tuning) is not measured; potential for grouped/fused kernels remains unexplored.
- Dynamic regime selection: no policy or autotuner is provided to switch between TSP, TP, SP, or TP+SP when batch size, sequence length, or model size moves the system across the theoretical crossover boundaries.
- Topology generalization: the claim that TSP is “no worse” on NVSwitch is unverified; mapping strategies, bandwidth/latency sensitivity, and contention under partial subgroups on diverse fabrics (NVSwitch, xGMI, PCIe-only) are not evaluated.
- Scaling with large D: the MLP ring requires D−1 sequential steps; latency and throughput impacts as D grows (beyond a node) and potential hierarchical/radix rings are not explored.
- Recomputation integration: selective vs full recomputation under TSP is not instantiated; which tensors to checkpoint, extra communication in backward due to recompute, and net speed–memory trade-offs are not measured.
- Memory fragmentation/allocator behavior: repeated large all-gathers and broadcasts can fragment memory; strategies (pre-allocation, pooling) and their effects on usable VRAM are not discussed.
- Applicability to other architectures: encoder–decoder, bidirectional attention, local/sliding-window/block-sparse attention, and structured state-space models under TSP are not addressed.
- MoE and expert parallelism: while TSP is claimed to be compatible, there is no concrete schedule for combining TSP with expert all-to-all, nor analysis of overlapping expert dispatch with TSP’s weight/activation traffic.
- Energy and cost efficiency: there is no analysis of energy per token, cost per training step, or heat/power headroom implications of increased communication vs memory savings.
- Library/stack integration: practical integration with PyTorch/RCCL/NCCL, stream/communicator management, and deadlock/livelock avoidance for concurrent broadcasts and all-gathers are not described; portability to major frameworks (Megatron/DeepSpeed) is unclear.
- Real-task convergence: training curves (loss vs tokens), generalization, and stability across long contexts with TSP vs baselines are absent; potential optimizer/learning-rate schedule adjustments for TSP are unexplored.
- K/V traffic mitigation for very long contexts: strategies such as compression, low-precision K/V exchange, windowed/sparse attention, or incremental cache partitioning under TSP are not proposed or evaluated.
- Parameter update locality: with weight movement during forward/backward, where and when optimizer updates occur (owner vs replicated views) and whether extra sync is required is not concretely specified.
- Reproducibility and code: no artifact or implementation details (versions, kernels, launch configs) are released to reproduce the proposed schedules and theory-derived figures.
Practical Applications
Immediate Applications
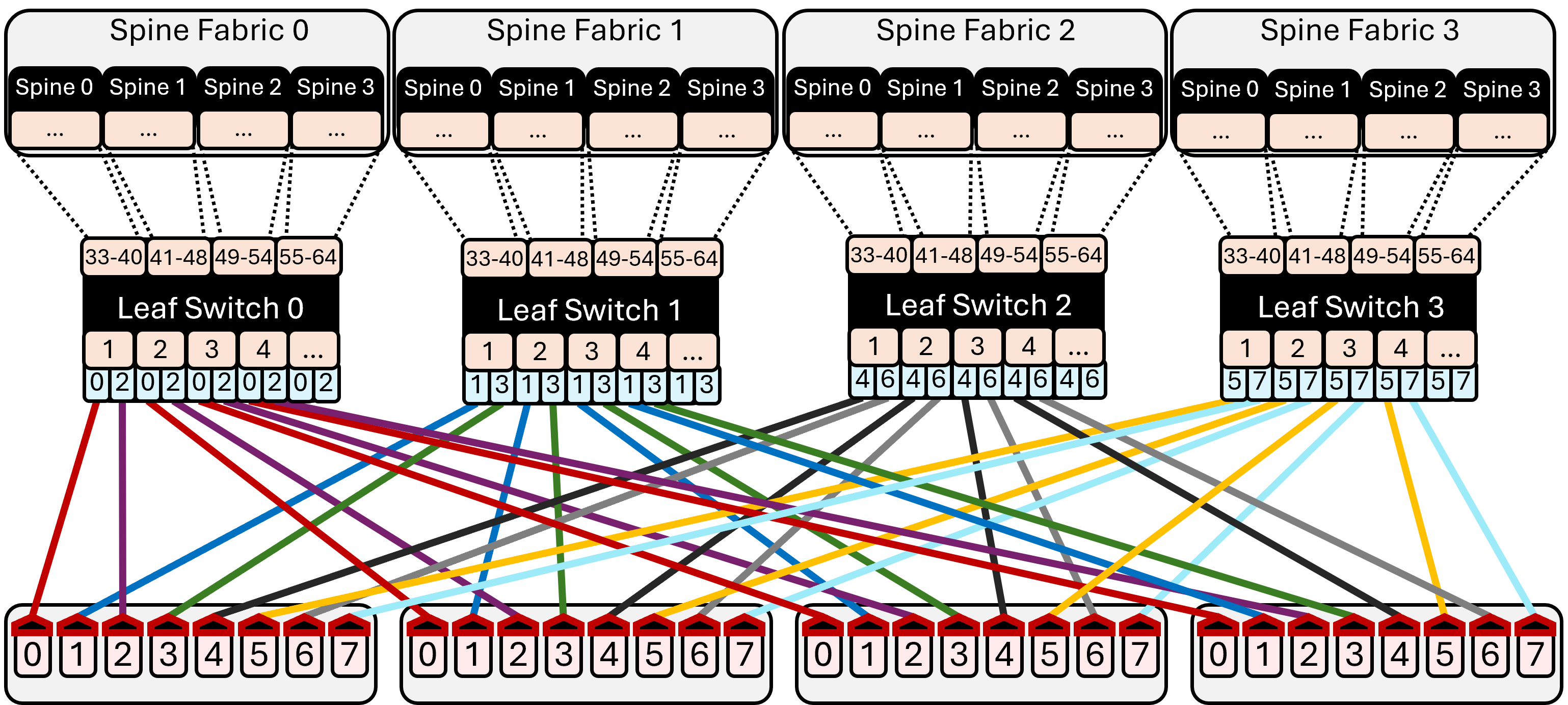
The following use cases can be deployed today on multi-GPU nodes with high-bandwidth intra‑node interconnects (e.g., NVIDIA NVLink/NVSwitch, AMD Infinity Fabric) and standard distributed training stacks (e.g., PyTorch, DeepSpeed, Megatron-LM).
- Long‑context LLM training and finetuning on a single node
- Sector: software, cloud, education, healthcare, legal, finance.
- What: Train/finetune 7B–70B+ Transformers with 32k–65k+ tokens by sharding both weights and sequence across 8 GPUs on a node; reduce both parameter and activation memory per GPU by ~1/D.
- Tools/workflows: Integrate TSP attention (broadcast + K/V all‑gather) and ring MLP schedule into PyTorch; use FlashAttention with zigzag sequence partitioning; combine with selective activation recomputation and mixed precision; map the TSP group strictly intra‑node.
- Assumptions/dependencies: High-bandwidth intra‑node fabric; overlapping comm/compute via dedicated streams; kernels for packed broadcasts/all-gathers; workloads in TSP-advantaged regime (approx. BS > 8h as per paper’s break‑even).
- Multi‑GPU long‑context inference and serving
- Sector: enterprise AI platforms, document analytics, code assistants.
- What: Serve long‑document summarization, contract analysis, multi‑file code assistants, or EHR summarization with 8‑GPU nodes by sharding KV cache and weights on the same axis to fit VRAM.
- Tools/workflows: Add TSP execution path to inference engines (e.g., vLLM/DS-MII style backends); KV‑cache all‑gather across the TSP group; integrate zigzag load-balancing.
- Assumptions/dependencies: Engine support for multi‑GPU attention with K/V exchange; predictable batch/sequence length; sufficient node VRAM to hold shard buffers.
- Higher throughput via more data‑parallel replicas at fixed cluster size
- Sector: cloud/HPC training operations.
- What: Fold TP and SP onto one axis (TSP) to free a mesh dimension for more DP replicas, increasing global batch or utilization without adding GPUs.
- Tools/workflows: Re‑configure job meshes so each node runs one D‑way TSP group plus DP across nodes; leverage existing DP all‑reduce.
- Assumptions/dependencies: Cross‑node bandwidth adequate for DP gradient synchronization; scheduler placement keeps TSP groups within nodes.
- Cost and energy savings for on‑prem labs and SMEs
- Sector: academia, startups, public sector.
- What: Fit long‑context finetuning or pretraining on a single 8‑GPU node vs. multiple nodes; reduce inter‑node traffic and power/cooling.
- Tools/workflows: TSP runtime in PyTorch/DeepSpeed; conservative recompute to tune memory/throughput; local NVMe dataset staging to avoid NIC contention.
- Assumptions/dependencies: Rails‑only or similar node topology; operations discipline to avoid spilling TSP groups across nodes.
- MoE models with TSP as an additional axis alongside expert parallelism
- Sector: large‑scale web services, recommendation, assistants.
- What: Combine TSP with expert parallelism (EP) to shrink per‑GPU state and enable larger experts or longer contexts.
- Tools/workflows: EP all‑to‑all for routing plus TSP ring MLP/attention for dense sublayers; topology‑aware group mapping.
- Assumptions/dependencies: All‑to‑all bandwidth for EP; careful overlap between EP traffic and TSP K/V exchange.
- Secure on‑prem analytics with reduced inter‑node exposure
- Sector: healthcare, finance, government.
- What: Keep sensitive workloads (e.g., PHI, PII, contracts) within a single node by using TSP to hit context targets without inter‑node comms.
- Tools/workflows: Single‑node deployments with hardened access; audit‑friendly topology (no cross‑rack traffic); TSP‑enabled inference/training pipeline.
- Assumptions/dependencies: Compliance requirements that prefer intra‑node data movement; sufficient node VRAM.
- Topology‑aware scheduling and placement policies
- Sector: HPC/cluster operations.
- What: Enforce “TSP group = node” placement in Slurm/Kubernetes to maximize intra‑node bandwidth and avoid OOMs at long context.
- Tools/workflows: Scheduler affinity/constraint rules; automatic detection of NVLink/Infinity Fabric groups; pack jobs to avoid subgrouping.
- Assumptions/dependencies: Cluster supports GPU‑aware placement; observability for fabric utilization.
- Better small‑lab finetuning via TSP + LoRA/QLoRA
- Sector: academia, startups, applied research.
- What: Combine parameter‑efficient finetuning with TSP to fit long contexts on 4–8 GPUs, enabling domain adaptation with large sequence windows.
- Tools/workflows: PEFT/QLoRA + TSP runtime; memory‑aware batch sizing; apply GQA to cut K/V all‑gather volume by 1/g.
- Assumptions/dependencies: Library integration (PEFT/bitsandbytes) with TSP; modest engineering to route comms around adapter weights.
- Reproducible academic benchmarking of parallelism trade‑offs
- Sector: academia.
- What: Evaluate memory/communication break‑even (e.g., BS > 8h) across TP, SP, TP+SP, and TSP on AMD/NVIDIA nodes.
- Tools/workflows: Open‑sourcing kernels/schedules; standard testbeds (7B/32‑layer configs); runbooks for selective vs. full recompute.
- Assumptions/dependencies: Availability of TSP implementations; access to nodes with high‑bandwidth intra‑connects.
Long‑Term Applications
These require further engineering, scaling research, or ecosystem maturation before broad deployment.
- Cross‑node TSP (elastic folded axis across multiple nodes)
- Sector: hyperscale training, national labs.
- What: Extend TSP groups beyond a single node to scale long‑context models when node‑local VRAM is insufficient.
- Tools/workflows: Hierarchical TSP (intra‑node + inter‑node stages), collective offload (e.g., SHARP), GPUDirect RDMA optimization.
- Assumptions/dependencies: Much higher inter‑node bisection bandwidth/latency improvements; smarter overlap and credit‑based flow control.
- Auto‑tuning/compilers that pick TP/SP/TSP per layer
- Sector: ML systems software.
- What: Compilers/runtime planners that select/fold axes adaptively by layer based on B, S, h, g, fabric, and memory headroom.
- Tools/workflows: PyTorch dynamo/inductor or XLA/TVM passes; runtime heuristics (“BS > 8h” rule) and cost models; Triton kernels for packed comms.
- Assumptions/dependencies: Accurate performance models; portable collectives; kernel fusion for broadcast/compute overlap.
- Hardware co‑design for folded parallelism
- Sector: semiconductors, systems vendors.
- What: NIC/switch and GPU runtime features to accelerate packed weight broadcasts and KV all‑gathers (e.g., multicast trees, in‑network reduction, future NVLink/IF features).
- Tools/workflows: Firmware support for dual‑stream collectives; credit‑based, compute‑gated transfers; topology‑aware schedulers.
- Assumptions/dependencies: Vendor adoption; cross‑stack coordination (drivers, libraries, compilers).
- Unifying TSP with FSDP/ZeRO and pipeline parallelism
- Sector: large‑scale training platforms.
- What: Combine optimizer‑state sharding (FSDP/ZeRO) and PP with TSP to minimize memory while maintaining high utilization.
- Tools/workflows: Gradient “sum‑to‑owner” or reduce‑scatter integration; stage‑wise TSP groups; activation rematerialization policies.
- Assumptions/dependencies: Backward pass correctness and overlap; stability with heterogeneous sharding granularities.
- Long‑context (100k–1M+) inference via TSP + KV paging/compression
- Sector: enterprise AI, legal/finance analytics.
- What: Push context windows to 100k–1M tokens by combining TSP with paged attention, KV compression, or chunked retrieval.
- Tools/workflows: vLLM‑style paged KV + TSP; adaptive chunk/sparsity scheduling; head‑wise or blockwise K/V all‑gathers.
- Assumptions/dependencies: Memory bandwidth limits; numerical stability; scheduler sophistication.
- TSP for multimodal and sparse Transformers
- Sector: media, robotics, autonomous systems.
- What: Apply TSP to video/vision‑LLMs with very large token grids; adapt K/V exchange to sparse/structured attention.
- Tools/workflows: Block‑sparse all‑gathers; hybrid folding across modalities; per‑modality ring schedules.
- Assumptions/dependencies: Kernel support for sparsity and layout transforms; balanced load across zigzag partitions.
- “Long‑Context as a Service” cloud SKUs
- Sector: cloud providers.
- What: Managed offerings optimized for long‑context training/inference using TSP‑tuned nodes and placement policies.
- Tools/workflows: Autoscaling with node‑local affinity; TSP‑aware quotas; customer‑facing SLAs for context length.
- Assumptions/dependencies: Productization and ecosystem support in inference/training stacks; demand aggregation.
- Policy and procurement guidance for public research compute
- Sector: policy/HPC funding.
- What: Recommend nodes with 8‑GPU fully connected intra‑node fabrics and per‑GPU NICs; encourage topology‑aware schedulers for AI workloads.
- Tools/workflows: Best‑practice playbooks; funding criteria that value intra‑node bandwidth for parallelism folding.
- Assumptions/dependencies: Coordination with vendors and centers; alignment with broader HPC needs.
- TSP‑aware observability and profilers
- Sector: DevOps/MLOps.
- What: Tooling that attributes overlapped comm/compute by sublayer (broadcast vs. K/V all‑gather vs. ring P2P) to guide tuning.
- Tools/workflows: Per‑stream timeline views; alerts on subgroup/topology misplacement; automated break‑even analysis.
- Assumptions/dependencies: Hooks in collective libraries; low‑overhead tracing.
- Edge/embedded multi‑accelerator deployments
- Sector: robotics, automotive, telecom.
- What: Use TSP across small multi‑GPU/accelerator boards (e.g., GH200‑class systems) to fit larger policies with longer horizons.
- Tools/workflows: Reduced‑precision weights; compact KV; static scheduling with guaranteed latency budgets.
- Assumptions/dependencies: Robust real‑time kernels and predictability; limited thermal envelopes.
Notes on feasibility across all applications:
- TSP benefits are strongest when communication can be overlapped and the TSP group remains intra‑node; performance may degrade if collectives spill over slow inter‑node links.
- The paper’s break‑even guidance (e.g., TSP forward comm < TP when BS > 8h for MHA) should inform configuration choices.
- Grouped‑Query Attention (larger g) reduces K/V exchange volume and further favors TSP for long contexts.
- Implementations depend on efficient packed broadcasts, all‑gathers, and P2P rings, plus kernels like FlashAttention and zigzag partitioning to balance causal attention.
Glossary
- All-gather: A collective operation that assembles data from all ranks and distributes the concatenated result back to every rank. "participates in an all-gather of the keys and values"
- All-reduce: A collective that aggregates data (e.g., by summation) across ranks and returns the result to all ranks. "typically an all-reduce or a reduce-scatter/all-gather pair"
- All-to-all: A collective where every rank sends distinct data to every other rank. "replaces the sequence-dimension exchange with all-to-alls that redistribute Q/K/V across the head dimension"
- AMD Infinity Fabric: AMD’s high-bandwidth, intra-node interconnect for GPU-to-GPU communication. "AMD Infinity Fabric"
- Bisection bandwidth: The total bandwidth available across the minimum cut that divides a network into two halves; a key metric for scalable communication. "under-utilizes the available bisection bandwidth."
- Broadcast: A collective that sends the same data from one source rank to all other ranks. "broadcasts one rank's weight shards"
- Causal attention: Attention where each token can attend only to previous (or current) positions, enforcing autoregressive ordering. "For causal attention, naive equal-sized sequence chunks lead to load imbalance"
- Collective communication: Communication primitives (e.g., all-reduce, all-gather) operating over groups of ranks. "collective communication, typically an all-reduce or a reduce-scatter/all-gather pair"
- Data parallelism (DP): Training scheme that replicates the full model on each device and splits the batch across devices. "DP replicates the full model on every device"
- Device-mesh axis: A logical dimension of devices along which tensors are partitioned or replicated. "collapsing two logically distinct sharding dimensions onto a single device-mesh axis"
- Expert parallelism (EP): Distributing different experts (sub-networks) across devices to scale Mixture-of-Experts models. "expert parallelism"
- FlashAttention: An optimized attention algorithm/kernels that reduce memory traffic via tiling and fusion. "FlashAttention once against the full-sequence keys and values"
- Full recomputation: Strategy of re-deriving activations during backprop to reduce activation memory at the cost of extra compute. "Under full recomputation, only the input to each transformer layer is stored"
- Gated MLP: A feed-forward block that multiplies an activated gate projection with an up-projection before a down-projection (e.g., SwiGLU). "For gated MLPs, weight shards circulate in a ring"
- GEMM (General Matrix Multiply): High-performance matrix-multiply operation underpinning neural network linear layers. "matching GEMMs cost on the order of"
- Grouped-query attention (GQA): Attention variant where multiple query heads share fewer key/value heads to reduce memory and compute. "GQA replaces the K/V shard widths"
- GQA ratio: The ratio between the number of query heads and key/value heads, controlling sharing in GQA. "GQA ratio"
- InfiniBand: A high-speed interconnect commonly used for inter-node communication in HPC clusters. "InfiniBand"
- MI300X: AMD’s data-center GPU used in the described cluster. "MI300X GPU"
- Mixture-of-expert models: Architectures where input tokens are routed to a subset of expert networks for efficiency and capacity. "mixture-of-expert models"
- NVLink: NVIDIA’s high-bandwidth, intra-node GPU interconnect. "NVIDIA NVLink"
- NVSwitch: NVIDIA’s switching fabric enabling full-bandwidth, any-to-any GPU communication within a node. "NVSwitch systems"
- Optimizer states: Additional per-parameter tensors (e.g., moments in AdamW) maintained by optimizers during training. "optimizer states"
- Pipeline parallelism (PP): Splitting model layers across device stages and pipelining micro-batches through them. "pipeline (PP)"
- Point-to-point (P2P): Direct communication between pairs of ranks without collective coordination. "point-to-point send/recv"
- Pre-norm residual connections: Transformer variant applying layer normalization before sublayers within residual blocks. "pre-norm residual connections"
- Rails-only topology: Network layout where each GPU has a dedicated NIC connected in a fixed rails pattern to switches. "rails-only topology"
- Reduce-scatter: A collective that reduces data across ranks while scattering the reduced shards to different ranks. "reduce-scatter/all-gather pair"
- Ring (communication schedule): A pattern where data (e.g., weights) circulates among ranks in a ring, enabling overlap of compute and communication. "a ring-communication schedule"
- Ring Attention: An SP variant that circulates K/V shards around ranks stepwise, overlapping transfers with blockwise attention compute. "Ring Attention"
- Selective recomputation: Recomputing only certain activations (e.g., attention probabilities) to save memory with less overhead than full recompute. "selective recomputation"
- Sequence parallelism (SP): Sharding the input sequence across ranks while replicating model weights. "Sequence parallelism partitions the input along the sequence dimension"
- Sharding: Splitting a tensor (parameters or activations) into disjoint parts across devices to reduce per-device memory. "sequence sharding"
- Sum-to-owner reduction: Reducing partial gradients or results to the rank that “owns” a particular shard, instead of all-reducing to everyone. "sum-to-owner reduction"
- Tensor parallelism (TP): Sharding model parameters across devices while replicating inputs/activations. "Tensor parallelism partitions the parameters of a layer across multiple devices"
- Topology: The physical/logical arrangement of interconnects that shapes bandwidth and latency characteristics for distributed training. "sensitivity to topology"
- Two-dimensional mesh: A device layout with two orthogonal parallel axes (e.g., TP and SP) to shard different dimensions. "two-dimensional mesh"
- xGMI: AMD’s high-speed GPU interconnect protocol used within Infinity Fabric. "xGMI Infinity Fabric"
- Zigzag context partition: An SP load-balancing scheme giving each rank two disjoint subsequences (front and back) to even out causal attention work. "a zigzag context partition"
Collections
Sign up for free to add this paper to one or more collections.