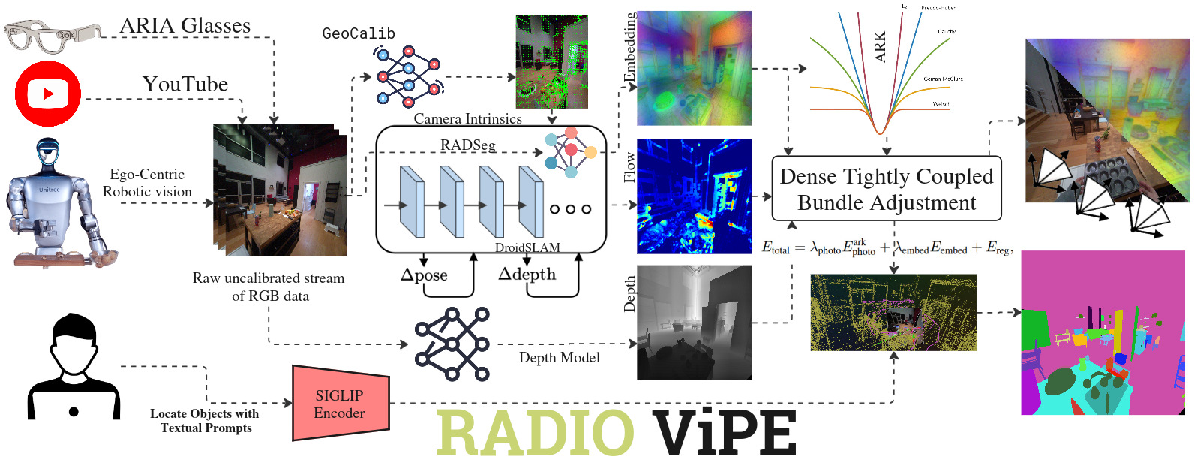
RADIO-ViPE: Online Tightly Coupled Multi-Modal Fusion for Open-Vocabulary Semantic SLAM in Dynamic Environments
Abstract: We present RADIO-ViPE (Reduce All Domains Into One -- Video Pose Engine), an online semantic SLAM system that enables geometry-aware open-vocabulary grounding, associating arbitrary natural language queries with localized 3D regions and objects in dynamic environments. Unlike existing approaches that require calibrated, posed RGB-D input, RADIO-ViPE operates directly on raw monocular RGB video streams, requiring no prior camera intrinsics, depth sensors, or pose initialization. The system tightly couples multi-modal embeddings -- spanning vision and language -- derived from agglomerative foundation models (e.g., RADIO) with geometric scene information. This coupling takes place in initialization, optimization and factor graph connections to improve the consistency of the map from multiple modalities. The optimization is wrapped within adaptive robust kernels, designed to handle both actively moving objects and agent-displaced scene elements (e.g., furniture rearranged during ego-centric session). Experiments demonstrate that RADIO-ViPE achieves state-of-the-art results on the dynamic TUM-RGBD benchmark while maintaining competitive performance against offline open-vocabulary methods that rely on calibrated data and static scene assumptions. RADIO-ViPE bridges a critical gap in real-world deployment, enabling robust open-vocabulary semantic grounding for autonomous robotics and unconstrained in-the-wild video streams. Project page: https://be2rlab.github.io/radio_vipe


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Explaining “RADIO-ViPE: Online Tightly Coupled Multi-Modal Fusion for Open-Vocabulary Semantic SLAM in Dynamic Environments”
What is this paper about?
This paper introduces RADIO-ViPE, a system that helps a robot build a 3D map of the world and understand it using everyday language, all from a normal video camera (like the one on a phone). It works even when people or objects are moving around and doesn’t need special setup, like knowing the camera’s exact details or having a depth sensor. In short: it turns regular videos into smart, searchable 3D maps that understand words.
What questions are the researchers trying to answer?
- Can a robot watch a normal video and figure out where it is, what it’s looking at, and where things are in 3D—without special calibration or depth sensors?
- Can it understand open-ended language, like “the blue chair” or “the coffee machine,” even if those words weren’t in a fixed list?
- Can it stay accurate when the world is dynamic (people walking, chairs moved, doors opening)?
- Can combining vision (images), language (words and meanings), and geometry (3D shapes and positions) improve mapping and tracking in real time?
How does the system work? (In simple terms)
Think of building a video game map while you walk around with a camera. The system does several things at once and makes them help each other:
- It watches the video and picks important frames (key moments) to work with, instead of every single frame, to keep things fast.
- It figures out how the camera is moving by tracking how tiny image patches shift between frames (like noticing how a sticker moves across the screen). This is called optical flow.
- It estimates how far things are using AI “depth” models trained on lots of images, even though there is only one camera. Think of this like a smart guess of how near or far objects are.
- It extracts “visual-language features” from each frame. You can think of these as unique fingerprints for every pixel that also carry meaning: they help the system connect what it sees to words (for example, “mug,” “lamp,” “sofa”). These features come from powerful foundation models (RADIO/RADSeg) that learned from tons of images and text.
- It puts all this information into a shared optimization process (a smart fixer-upper) that tunes the 3D map and the camera path so everything lines up. This is a bit like adjusting all the pieces in a puzzle at once so the picture looks right. In SLAM terms, this is “bundle adjustment” in a “factor graph,” which just means: “we connect related frames with rules and improve them together.”
- It automatically estimates the camera’s internal settings (focal length, center, etc.) so you don’t need to calibrate beforehand.
- It uses a “smart filter” to handle moving objects. If something doesn’t look consistent over time (like a walking person or a chair someone moved), the system reduces its impact so it won’t mess up the map.
Put simply: it fuses geometry (where things are), language (what things are called), and vision (what things look like) into one consistent, live-updating 3D map that you can search with text.
What are the main results, and why do they matter?
- Strong accuracy in dynamic scenes: On a well-known benchmark with moving objects (TUM-RGBD), RADIO-ViPE reached state-of-the-art performance in tracking where the camera is and how it moves. That means it’s reliable even when the environment isn’t still.
- Works in real time with regular video: It runs at about 8–10 frames per second without needing depth sensors, known camera settings, or a pre-given pose. That’s practical for robots or AR devices in the real world.
- Open-vocabulary understanding: You can ask for almost any object by name (not just from a fixed list), and the system can locate related 3D regions or objects. For example, “find the backpack,” even if “backpack” wasn’t pre-programmed.
- Competitive semantic mapping: On the Replica dataset (a 3D scene benchmark), it ranked among the top methods for segmenting objects in 3D, even though many other methods require perfect camera info, depth, or offline processing. The performance drop without “ground-truth” inputs (the exact correct answers) was small, which shows the system is robust and practical.
Why this matters: Real robots and AR systems need to understand the world like we do, not just as empty shapes. Being able to say “Where is the red mug?” and getting a 3D location back, from a normal camera, is a big step toward helpful, flexible robots and smarter AR.
What does this mean for the future?
- Easier deployment: Because it needs only a regular camera and no careful setup, this system can be used on many devices (robots, drones, AR headsets) in everyday places.
- More natural interaction: People can talk to robots in normal language and get meaningful, grounded answers in 3D space.
- Handles real life: It’s built for dynamic, messy environments—like homes, offices, or streets—where things move and change.
- Builds on internet video: Since it can learn from unstructured videos, it could scale using publicly available footage, not just expensive robot datasets.
Potential next steps include improving how it handles large, plain background surfaces (like walls and floors) and pushing the speed/accuracy even further. Overall, RADIO-ViPE is a strong step toward robots and devices that see, map, and understand the world using both geometry and language—live, flexible, and ready for the real world.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper leaves the following concrete gaps and open questions that future work could address:
- Calibration robustness and intrinsics modeling
- No quantitative analysis of GeoCalib’s reliability under diverse optics (e.g., strong distortion, fisheye, smartphone auto-focus/variable focal length, zoom). The optimization only uses a pinhole model (fx, fy, cx, cy) with no distortion parameters; impact and failure modes remain unreported.
- Unclear robustness when intrinsics vary during capture (e.g., autofocus/zoom changes in-the-wild video).
- Metric scale and depth prior usage
- Metric scale hinges on foundation depth priors with a fixed regularization weight (α_disp = 1.0); there is no sensitivity study or uncertainty-aware weighting of the depth prior versus multi-view constraints.
- No quantitative assessment of global scale drift across sequences/cameras or of cross-device generalization of metric depth.
- Loop closure and global consistency
- Factor graph connectivity via embedding-based co-visibility lacks geometric re-verification; false-positive matches under perceptual aliasing are not analyzed, and long-loop closure robustness is untested.
- No experiments on very long trajectories or multi-minute videos to assess cumulative drift, map consistency, and catastrophic failure rates.
- Occlusions and visibility handling
- The embedding alignment term assumes visibility with bilinear sampling; there is no explicit occlusion/disocclusion reasoning (e.g., z-buffering, visibility masks) to prevent spurious residuals in overlapping or newly revealed regions.
- Dynamic scene modeling limits
- The adaptive robust kernel down-weights moving/quasi-static objects but does not explicitly estimate or track their motions or maintain multiple map states; how to model, reconstruct, and query dynamic objects over time is left open.
- No evaluation on scene rearrangement sequences (e.g., furniture moved mid-session) to test whether the map adapts or maintains temporal layers/versions.
- Temporal stability field design
- The thresholds (θ_s, θ_m) and α_dyn in the Barron-loss mapping are fixed; there is no sensitivity analysis, learning-based adaptation, or per-scene tuning strategy.
- The stability field uses cosine similarities of dense embeddings; its reliability under large viewpoint/illumination changes and on textureless surfaces (e.g., walls/floors) is not assessed.
- Semantic grounding pipeline details and validation
- The step “decode compressed RADIO features of 3D points and project into SigLIP space” is underspecified: the projection/decoder architecture, training procedure, and calibration losses are not described, hindering reproducibility.
- Open-vocabulary evaluation is limited to mIoU/f-mIoU on Replica; there is no assessment of phrase-level grounding, referring expressions, category-level retrieval precision/recall, or robustness to synonyms/compositional queries, nor multilingual performance.
- Dense embedding compression and its effects
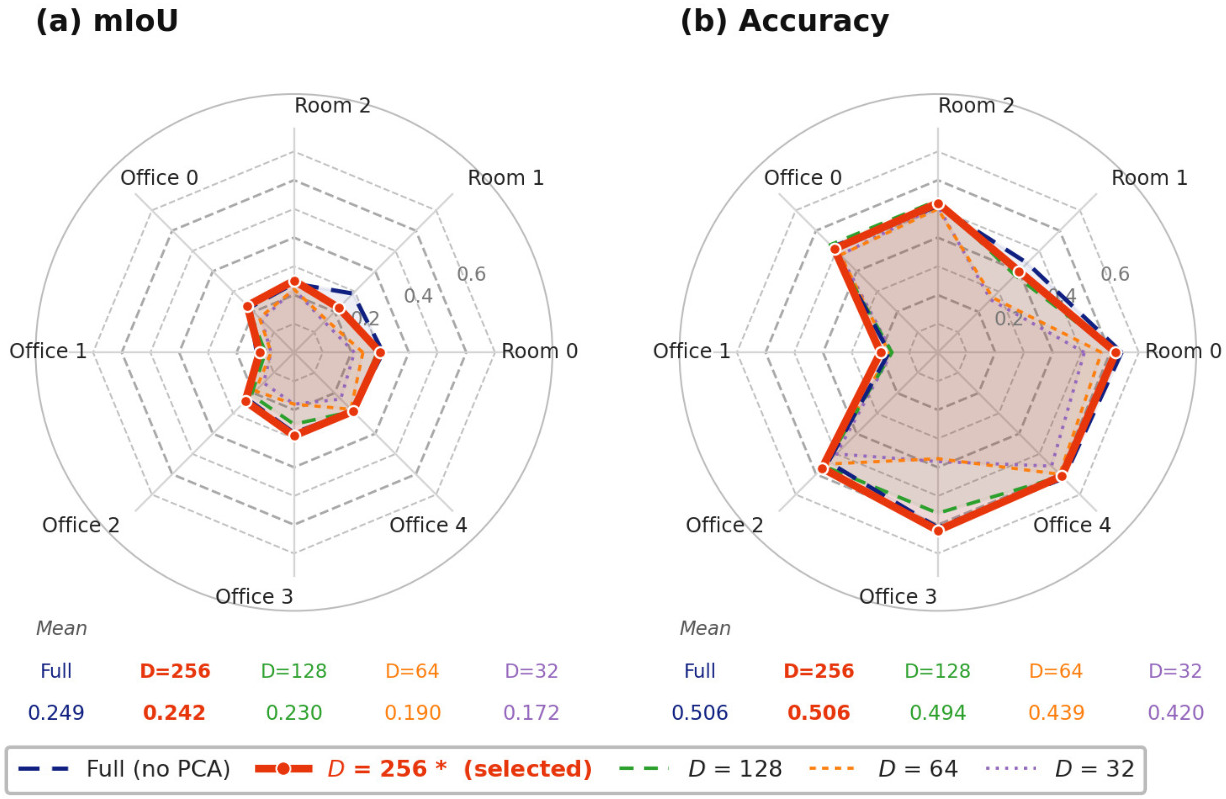
- PCA is trained on an initial buffer and then fixed; no analysis of drift when scene content changes, or of strategies for updating PCA online without destabilizing BA.
- Ablations focus on mIoU; the impact of embedding dimensionality on SLAM accuracy, BA convergence, and runtime is not reported.
- Efficiency, memory, and scalability
- Runtime (8–10 FPS on RTX 4090) lacks detailed profiling; the contribution of each module (flow, depth, RADSeg, BA, kernels) to compute/memory is not broken down.
- Memory scaling is unclear: storing H/8 × W/8 × 256 embeddings per keyframe can be prohibitive for long videos; policies for keyframe marginalization, feature compression beyond PCA, and map thinning are not specified.
- No evaluation on embedded or resource-constrained platforms; real-time viability on robot-class hardware remains unknown.
- Dataset coverage and robustness
- Experiments are limited to TUM-RGBD (indoor dynamic) and Replica; there is no testing on outdoor/ego-centric datasets with challenging conditions (rolling shutter, HDR/low light, severe motion blur, weather), or large-scale scenes with strong perceptual aliasing.
- The acknowledged drop on background classes (walls/floors) is not further analyzed; potential remedies (planar priors, geometry-aware regularization, surface normals) are unexplored.
- Non-keyframe pose estimation reliability
- Non-keyframe poses use photometric alignment without depth estimation; robustness in highly dynamic or low-texture regimes is not evaluated, and failure recovery strategies are unspecified.
- Place recognition and false matches
- Embedding-only similarity for non-adjacent keyframe linkage may introduce spurious edges; there is no geometric consistency check (e.g., PnP+RANSAC) or robust verification stage, nor an ablation on the similarity threshold (η) and exclusion window (τ).
- Cross-modal uncertainty and weighting
- The multi-term objective combines photometric, embedding, and depth priors without a probabilistic uncertainty model; how to estimate and adapt cross-modal confidences online is an open question.
- Map representation and semantics granularity
- The global 3D structure used for mapping/grounding is not fully specified (e.g., surfels/TSDF/point cloud) and there is no instance-level or scene-graph reasoning; extending to object instances, relations, and affordances remains open.
- Interaction and query-time scalability
- The indexing and retrieval strategy for real-time text queries over large 3D maps (e.g., ANN over millions of features, latency, batching) is not described; scalability and latency of interactive grounding are untested.
- Domain shift in foundation models
- Reliance on RADSeg/RADIO and monocular depth foundation models is not stress-tested for domain shift; failure cases, uncertainty estimation, or on-the-fly adaptation are not explored.
- Reproducibility details
- Several implementation hyperparameters are omitted (e.g., similarity thresholds, sliding-window size, feature normalization specifics, PCA training schedule); a comprehensive ablation and release of these settings would improve reproducibility.
Practical Applications
Below is an overview of practical, real-world applications enabled by the RADIO-ViPE system’s findings and methods. Each item includes sectors, example tools/workflows/products that could be built, and key assumptions/dependencies that affect feasibility.
Immediate Applications
The following use cases can be prototyped or deployed today using the paper’s calibration-free, online open-vocabulary semantic SLAM on monocular RGB video (8–10 FPS), robust to dynamic scenes.
- Language-queryable maps for mobile robots (indoor navigation and assistance)
- Sectors: robotics, logistics, smart buildings
- Tools/workflows/products: ROS/ROS2 node that provides a language-to-3D query API (“navigate to the nearest trash can,” “find the pallet jack”), on-device or edge server module for semantic waypoint generation and dynamic obstacle suppression
- Assumptions/dependencies: moderate GPU (edge GPU or discrete GPU) for 8–10 FPS; monocular camera feed; reliance on foundation depth and vision-LLMs (RADSeg, SigLIP) that generalize to the target domain; privacy controls for video capture in public spaces
- Handheld semantic scanning for inventory and asset audits
- Sectors: warehousing, retail, facilities management
- Tools/workflows/products: smartphone or action-camera app that builds a 3D semantic map and supports free-form queries (“all fire extinguishers,” “missing cereal SKUs on aisle 3”); export to point clouds with language-aligned embeddings for downstream BI tools
- Assumptions/dependencies: adequate lighting, method tested primarily indoors; model weights available on-device or via edge/cloud; consistent camera motion for stable mapping
- AR content anchoring via open-vocabulary semantics (no calibration)
- Sectors: AR/VR, media/entertainment, education
- Tools/workflows/products: Unity/Unreal plugin to anchor content to objects named in natural language (“place the instruction overlay on the boiler valve,” “attach label to the sofa”); interactive scene exploration
- Assumptions/dependencies: mobile or headset GPU budget; stable frame rate for AR compositing; model size and memory fit for target device; legal/UX handling for dynamic people in view
- Real-time safety monitoring and spatial search in dynamic environments
- Sectors: occupational safety, security, event management
- Tools/workflows/products: edge box that creates a language-queryable 3D map from surveillance video to flag queryable conditions (“person near forklift,” “blocked exit,” “spilled liquid on floor”) and track moving obstacles
- Assumptions/dependencies: privacy and compliance for video processing; model robustness to lighting/crowds; compute placement near cameras or on a central server
- Facility inspection and maintenance mapping
- Sectors: industrial operations, utilities, real estate
- Tools/workflows/products: maintenance app for mechanical rooms that supports queries like “locate pressure gauges,” “find corroded pipe near valve,” and logs semantic 3D snapshots for progress over time
- Assumptions/dependencies: coverage of industrial categories by open-vocabulary embeddings; ambient lighting and line-of-sight; user training to ensure smooth handheld capture
- Media/video indexing with 3D-grounded semantics
- Sectors: media asset management, sports analytics, film production
- Tools/workflows/products: batch video processing tool that produces a language-queryable 3D index across shots (“all shots with a blue car near the storefront”); editorial search and content retrieval
- Assumptions/dependencies: GPU farm or cloud inference; model generalization to diverse scenes; embedded privacy filters for people/org-specific queries
- Indoor drone/UAV mapping without calibration targets
- Sectors: inspection, public safety, logistics
- Tools/workflows/products: drone payload app that fuses monocular video to generate a live 3D semantic map, enabling queries like “find exits,” “locate toolbox,” or “identify loose cables”
- Assumptions/dependencies: IMU integration optional but recommended; vibration and motion blur management; RF/compute constraints for on-drone vs edge processing
- Construction site progress capture and semantic queries
- Sectors: construction, architecture/engineering, digital twins
- Tools/workflows/products: foreman’s smartphone workflow to scan areas and query “window frames installed,” “drywall missing,” “stairs exist”; comparisons across time
- Assumptions/dependencies: robustness to dust/occlusions; semantics for evolving structures; standardized capture routes to improve coverage and repeatability
- Cultural heritage quick digitization with open-vocab tags
- Sectors: cultural heritage, museums
- Tools/workflows/products: low-cost field scanning for small-to-medium indoor artifacts/sites with natural language tagging and subsequent curation
- Assumptions/dependencies: controlled indoor settings preferred; less reliable on featureless walls/backgrounds (noted limitation)
- Academic workflows: dataset bootstrapping and benchmarking for dynamic SLAM and open-vocab perception
- Sectors: academia, R&D
- Tools/workflows/products: scripts to generate pseudo-labeled 3D maps with language-aligned features from in-the-wild videos; ablation and benchmarking of dynamic-robust kernels; reproducible baselines for open-vocab SLAM
- Assumptions/dependencies: research compute cluster; licensing/redistribution of model weights and video content
Long-Term Applications
The following use cases are promising but require further research, scaling, integration, or hardware optimization (e.g., to address large-scale outdoor deployment, regulatory/UX considerations, and tighter control loops).
- Language-to-action autonomous robots in dynamic spaces
- Sectors: robotics (service, hospitality, manufacturing)
- Tools/workflows/products: full-stack platform where natural language queries set semantic goals that directly drive navigation/manipulation (“pick the red mug on the left shelf despite people moving around”)
- Assumptions/dependencies: tighter integration with control and grasping; improved background/structural class segmentation; robust real-time performance on embedded hardware
- Multi-robot cooperative, open-vocabulary semantic mapping
- Sectors: logistics, public safety, smart buildings
- Tools/workflows/products: shared, language-queryable semantic maps across fleets; task allocation via natural language across agents
- Assumptions/dependencies: consistent cross-robot embeddings; bandwidth-efficient map fusion; privacy-safe identity handling (people) and dynamic object reconciliation
- City-scale, outdoor open-vocabulary SLAM
- Sectors: autonomous vehicles, municipal services, digital twins
- Tools/workflows/products: calibration-free semantic mapping and querying of large urban areas (“find all bus stops with ad panels,” “identify damaged guardrails”), integrating with GIS/BIM
- Assumptions/dependencies: robustness to illumination/weather; long-range depth estimation with monocular foundations outdoors; memory/compute scaling; regulatory approvals for city-scale video capture
- On-device AR glasses with open-vocabulary anchoring and spatial memory
- Sectors: consumer electronics, enterprise AR, education
- Tools/workflows/products: “find my keys” or “show me all hazardous materials” with language-grounded persistence over sessions; semantic anchors across devices
- Assumptions/dependencies: energy-efficient on-device models; privacy-preserving continual mapping; reliable real-time performance without cloud
- Healthcare facilities: language-driven wayfinding and asset tracking
- Sectors: healthcare
- Tools/workflows/products: live maps to query “nearest crash cart,” “available wheelchair,” “oxygen tank,” integrated with hospital operations
- Assumptions/dependencies: strict compliance (HIPAA/GDPR); high reliability; staff acceptance and integration with existing RTLS/BMS systems
- Autonomous retail operations and planogram enforcement by robots
- Sectors: retail, robotics
- Tools/workflows/products: shelf-scanning robots with open-vocab queries (“identify misplaced SKUs,” “detect empty facings for beverages”) and dynamic-robust mapping during shopping hours
- Assumptions/dependencies: robust SKU-level grounding (fine-grained categories); model retraining on store-specific inventories; safety and shopper privacy protocols
- Advanced inspection in energy/utilities using open-vocab semantics
- Sectors: energy, utilities, oil & gas
- Tools/workflows/products: robot or drone inspection with queries (“find corrosion on pipeline flanges,” “locate missing signage near high voltage cabinet”)
- Assumptions/dependencies: domain adaptation to industrial scenes; hazardous environment certification; improved handling of repetitive structures/backgrounds
- Autonomous driving: language-aligned perception overlays for operators and digital twins
- Sectors: automotive, mobility
- Tools/workflows/products: operator-facing semantic overlays (“identify construction cones,” “locate cyclists near curb”) and language-queryable logs for post hoc analysis
- Assumptions/dependencies: moving platform + outdoor performance; sensor fusion with LiDAR/radar; real-time constraints beyond 8–10 FPS on automotive-grade hardware
- Semantic digital twins with natural language interfaces
- Sectors: AEC, facilities, enterprise asset management
- Tools/workflows/products: continuously updated, open-vocabulary semantic layers on top of digital twins; “show me all emergency lights not visible from exits”
- Assumptions/dependencies: interoperability with BIM/IFC; persistent identity tracking across sessions; accuracy on structural classes (e.g., walls/floors) improved
- Privacy-first, policy-compliant open-vocabulary mapping frameworks
- Sectors: policy, public sector, standards bodies
- Tools/workflows/products: reference implementations that perform on-device feature extraction, biometric scrubbing, and secure embedding storage; audit and redaction tools for language-based queries involving people or sensitive assets
- Assumptions/dependencies: evolving regulations; standardized evaluation of privacy risk in language-grounded maps; stakeholder engagement for best practices
- Content creation pipelines that bridge 2D video to 3D, language-rich assets
- Sectors: VFX, gaming, education
- Tools/workflows/products: “scan and describe” workflows that turn video captures into language-annotated 3D assets for rapid scene set-up in engines
- Assumptions/dependencies: higher-fidelity geometry and texture reconstruction; integration with Gaussian Splatting/NeRF pipelines; licensing for foundation model assets
- Human-robot interaction with open-vocabulary task grounding and dialogue
- Sectors: service robotics, elder care, hospitality
- Tools/workflows/products: conversational interfaces where users specify goals in natural language (“tidy the table near the window”) with live semantic grounding and robust mapping
- Assumptions/dependencies: integration with LLM-based planners; safety validation; generalization to cluttered, highly dynamic homes
- Large-scale video analytics with 3D-aware, language-driven search
- Sectors: smart cities, transportation hubs, public safety
- Tools/workflows/products: indexing of multi-camera, multi-session video into a shared 3D semantic space enabling queries like “objects left near entrances in last 24h”
- Assumptions/dependencies: cross-camera calibration-free fusion at scale; strong privacy measures and access control; compute/storage planning
Notes on cross-cutting assumptions and dependencies:
- Compute: Reported 8–10 FPS on a desktop GPU (RTX 4090). Deployment likely requires edge GPUs (e.g., Jetson class) or cloud inference with careful latency control.
- Models: Availability and licensing of foundation depth models and RADSeg/RADIO/SigLIP features; model generalization to new domains remains a variable.
- Environments: Demonstrated on indoor datasets; outdoor and strong background/structural segmentation remain challenging and may degrade performance.
- Data governance: Open-vocabulary mapping of people and sensitive objects raises privacy, consent, and retention concerns; production use requires policy-compliant pipelines.
- Capture quality: Textureless/featureless surfaces and extreme motion can reduce robustness; smooth capture and adequate lighting improve outcomes.
- Integration: For robotics, tight coupling with motion planning, grasping, and multi-sensor fusion (IMU, LiDAR) will improve reliability beyond monocular-only setups.
Glossary
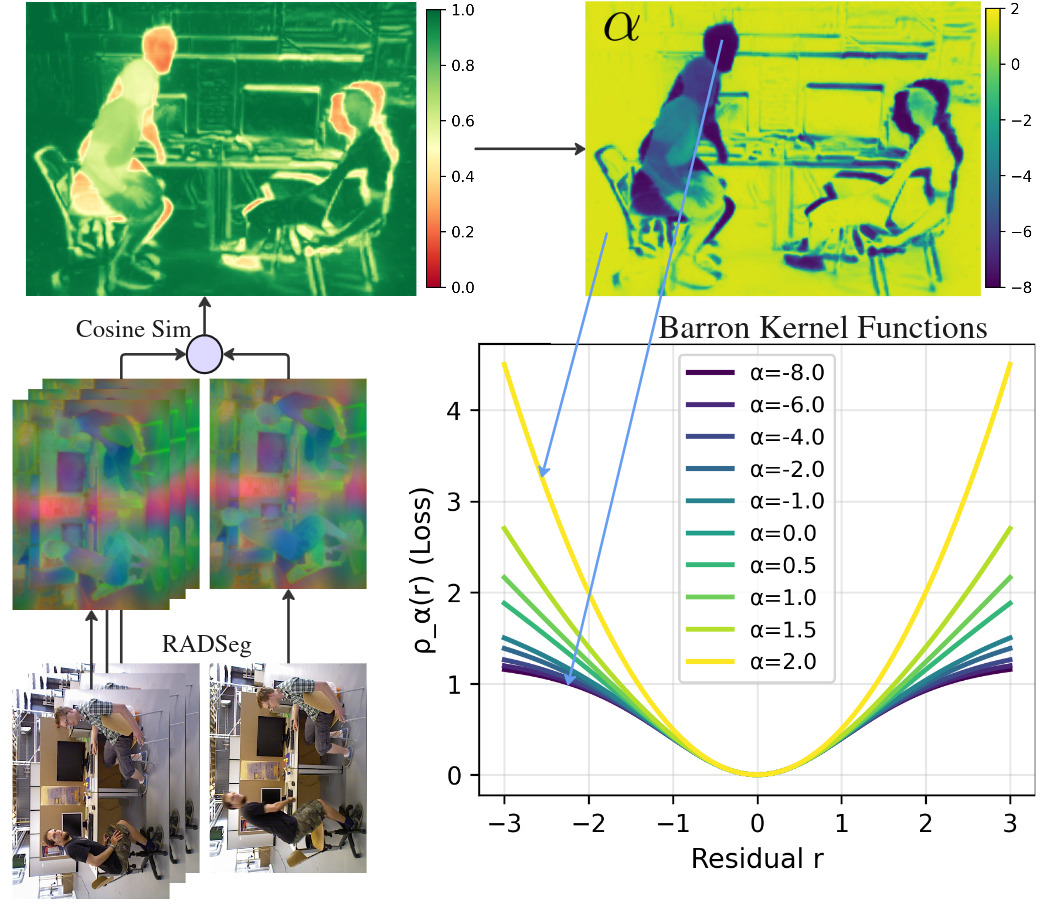
- Adaptive robust kernel: A per-residual weighting scheme that adapts its robustness to down-weight outliers and dynamics during optimization; "The optimization is wrapped within adaptive robust kernels, designed to handle both actively moving objects and agent-displaced scene elements (e.g., furniture rearranged during ego-centric session)."
- Agglomerative foundation models: Foundation models obtained by distilling multiple teacher models into a unified student that preserves diverse capabilities; "agglomerative foundation models (e.g., RADIO~\cite{radio})"
- ATE (Absolute Trajectory Error): A standard SLAM metric measuring absolute pose error of an estimated trajectory with respect to ground truth (lower is better); "SLAM Performance Comparison on TUM-RGBD in cm (ATE )"
- Barron’s general loss: A family of robust losses parameterized by that smoothly interpolates between , Huber, and Cauchy behaviors; "Adaptive robust kernels based on Barron's general loss~\cite{barron}."
- Bilinear interpolation: A method to compute values at non-integer pixel locations using weighted averages of the four nearest neighbors; "upsampled via bilinear interpolation to "
- Bundle adjustment: A joint nonlinear optimization of camera poses, intrinsics, and scene structure to enforce multi-view consistency; "within a dense bundle adjustment framework."
- Calibration-free: Operating without pre-known camera intrinsics or calibration targets; "Calibration-Free Online Open-Vocabulary Semantic SLAM."
- Camera intrinsics: The internal camera parameters (e.g., focal lengths and principal point) required for projection and unprojection; "requiring no prior camera intrinsics"
- Cosine similarity: An angle-based similarity measure between two vectors, often used to compare embeddings; "we compute cosine similarities between the PCA-compressed Radio embedding and pixels embeddings "
- Co-visibility: A criterion linking frames/nodes that view overlapping content, here constructed using embedding similarity; "Factor graph connectivity is augmented beyond geometric proximity by embedding-based co-visibility"
- Cross-view feature alignment: Enforcing that features of corresponding 3D points match across different viewpoints; "enforces cross-view feature alignment under geometric constraints"
- Dense optical flow: A per-pixel 2D motion field between two images used to enforce geometric and photometric consistency; "geometric consistency is enforced via dense optical flow constraints."
- Disparity (inverse depth): Representing depth as its inverse for numerical stability in optimization; "converted to inverse depth (disparity) for numerical stability"
- Ego-centric: A first-person, agent-centered viewpoint or session; "ego-centric session"
- Embedding similarity term: An optimization term that penalizes differences in learned feature embeddings across projected correspondences; "we introduce a novel embedding similarity term that enforces cross-view feature alignment under geometric constraints"
- Extrinsic estimation: Estimating a camera’s pose (rotation and translation) with respect to the world; "intrinsic and extrinsic estimation with near-metric depth at 3--5 FPS."
- Factor graph: A bipartite graph connecting variables and factors (constraints) used for probabilistic inference and optimization; "sliding window factor graph optimization framework."
- Feed-forward SLAM: SLAM methods that directly regress geometry and/or poses without iterative optimization loops; "feedforward SLAM methods \cite{mast3r, vggt, dust3r}"
- Gauss–Newton method: An iterative least-squares optimization algorithm used to jointly refine poses, depth, and intrinsics; "we perform optimization with Gauss--Newton method"
- Gaussian splatting representation: A 3D representation that uses Gaussian primitives for real-time rendering and mapping; "integrates CLIP embeddings within a Gaussian splatting representation for real-time open-vocabulary mapping."
- Geometric reprojection prior: An initial correspondence prior computed by projecting 3D points from one view into another; "we augment the geometric reprojection prior with a semantic correspondence term"
- Huber loss: A robust loss function that behaves quadratically for small residuals and linearly for large ones; "recovers (), Huber (), and Cauchy () as special cases."
- Keyframe: A selected frame that serves as a node in the optimization graph to reduce computation while preserving coverage; "Keyframe Selection."
- Loop closure: Detecting revisits to previously mapped areas to correct drift and improve global consistency; "loop closure across diverse sensor configurations"
- Mean-pooling: Averaging feature vectors spatially to form a compact global descriptor; "a global descriptor per keyframe is obtained by mean-pooling its RADSeg embeddings"
- Metric depth: Depth values expressed in real-world units (e.g., meters), as opposed to relative or scale-ambiguous depth; "A metric depth map is estimated per keyframe"
- Monocular RGB video: Video from a single color camera, lacking direct depth measurements; "raw monocular RGB video streams"
- Multi-modal embeddings: Feature vectors aligned across different modalities (e.g., vision and language) for joint reasoning; "multi-modal embeddings â spanning vision and language â"
- Multi-teacher distillation: Training a student model to learn from multiple teacher models, aggregating their strengths; "leverage multi-teacher distillation, and provide a unified student model that retains and improves the distinct capabilities of multiple teachers"
- Open-vocabulary grounding: Associating arbitrary natural-language queries with spatial regions or objects without a fixed label set; "geometry-aware open-vocabulary grounding, associating arbitrary natural language queries with localized 3D regions and objects"
- Optical flow network: A neural network that predicts dense optical flow and associated confidences between frames; "An optical flow network~\cite{droid} predicts a residual dense flow field alongside per-pixel confidence weights"
- PCA (Principal Component Analysis): A dimensionality-reduction technique projecting features into a lower-dimensional subspace; "compressed to dimensions via PCA (Sec.~\ref{sec:experiments})"
- Photometric alignment: Estimating poses by minimizing differences in image appearance under reprojection; "its pose is recovered through photometric alignment"
- Pose priors: Prior knowledge or assumptions about camera poses used to aid optimization; "with no depth sensors, pose priors, or category-specific supervision required."
- Projective ambiguity: The inherent ambiguity (e.g., scale) in monocular uncalibrated reconstruction under projective geometry; "resolve the 15-DoF projective ambiguity inherent to uncalibrated monocular reconstruction."
- Scene graph: A structured representation of objects and their relations within a 3D scene; "construct semantically rich 3D scene graphs with natural language grounding."
- SE(3): The Lie group of 3D rigid-body transformations (rotations and translations); "Let denote the world-to-camera pose for frame "
- Self-attention mechanism: An attention module that enables features to interact and aggregate contextual information; "refining the aggregated feature map through a self-attention mechanism."
- Semantic SLAM: SLAM augmented with semantic understanding to enrich maps with object/category information; "an online semantic SLAM system"
- SigLIP embedding space: The joint vision-language feature space produced by the SigLIP model; "within the SigLIP~\cite{siglip} embedding space."
- Sliding window: Maintaining and optimizing over a fixed-size recent set of frames for online operation; "within a sliding window factor graph optimization framework."
- SL(4) manifold: The special linear group related to projective transformations used to parameterize uncalibrated reconstructions; "explicitly optimizing over the SL(4) manifold to resolve the 15-DoF projective ambiguity"
- Temporal stability field: A per-pixel statistic combining temporal mean and variance of similarity to identify static vs. dynamic regions; "The temporal stability field is then defined as: "
- Tightly coupled multi-modal fusion: Jointly optimizing geometric and semantic terms so that different modalities directly constrain each other; "A novel tightly coupled multi-modal fusion that jointly embeds high-level features ... with geometric constraints directly within a dense bundle adjustment framework."
- Visual-inertial odometry: Estimating motion by fusing visual data with inertial measurements; "a strong baseline for visual-inertial odometry"
- Voxel-wise embedding: Assigning a learned feature vector to each voxel in a 3D grid for semantic mapping; "dense voxel-wise embedding of the map."
- Weighted dense optical flow: Dense optical flow equipped with per-pixel confidence weights to guide optimization; "Relative motion between each incoming frame and the most recent keyframe is estimated via weighted dense optical flow"
Collections
Sign up for free to add this paper to one or more collections.

