- The paper introduces OVO, an innovative framework that integrates open-vocabulary semantic mapping into established SLAM backbones for real-time performance.
- The methodology leverages CLIP vectors and unsupervised SAM mask prediction to dynamically extract and merge 3D segments from RGB-D frames, enhancing loop closure and reducing drift.
- Experimental results demonstrate higher mIoU and segmentation accuracy on datasets like Replica and ScanNetv2 while significantly lowering computational and memory demands.
Analysis of "Open-Vocabulary Online Semantic Mapping for SLAM" (2411.15043)
Introduction
The paper "Open-Vocabulary Online Semantic Mapping for SLAM" (2411.15043) introduces an innovative approach to 3D semantic mapping using a pipeline referred to as OVO (Open-Vocabulary Online). This methodology is designed to outperform current approaches by effectively handling a significantly lower computational and memory intensity while producing superior segmentation accuracy. OVO is integrated into SLAM backbones like Gaussian-SLAM and ORB-SLAM2, achieving end-to-end mapping with loop closure capabilities.
Methodology
OVO uses a sequence of posed RGB-D frames to detect and track 3D segments, which are characterized by CLIP vectors computed via a novel merging method. This approach allows the system to utilize an open-vocabulary framework, overcoming the limitations of predefined categories that restrict traditional SLAM systems.
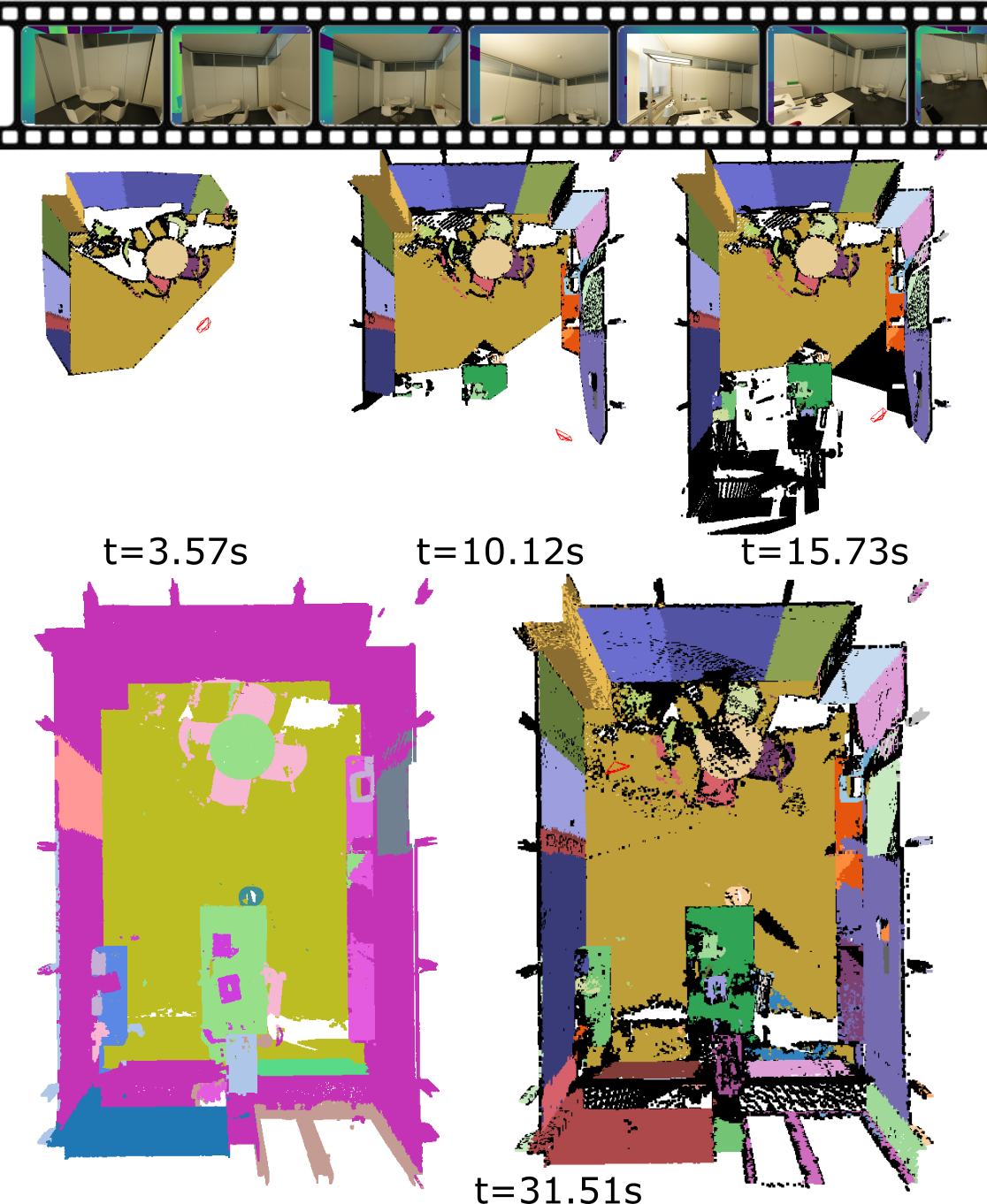
Figure 1: OVO mapping demonstrates how RGB-D keyframes are used to reconstruct a 3D open-vocabulary scene over time.
Key to OVO’s advancement is its computation of the CLIP vectors, which offer optimization-free generalization and classification across a wide range of categories expressible in language. By leveraging unsupervised methods such as Segment Anything Model (SAM) for mask prediction, OVO extracts and maintains 3D segments dynamically, selecting the most informative viewpoints to represent these segments.
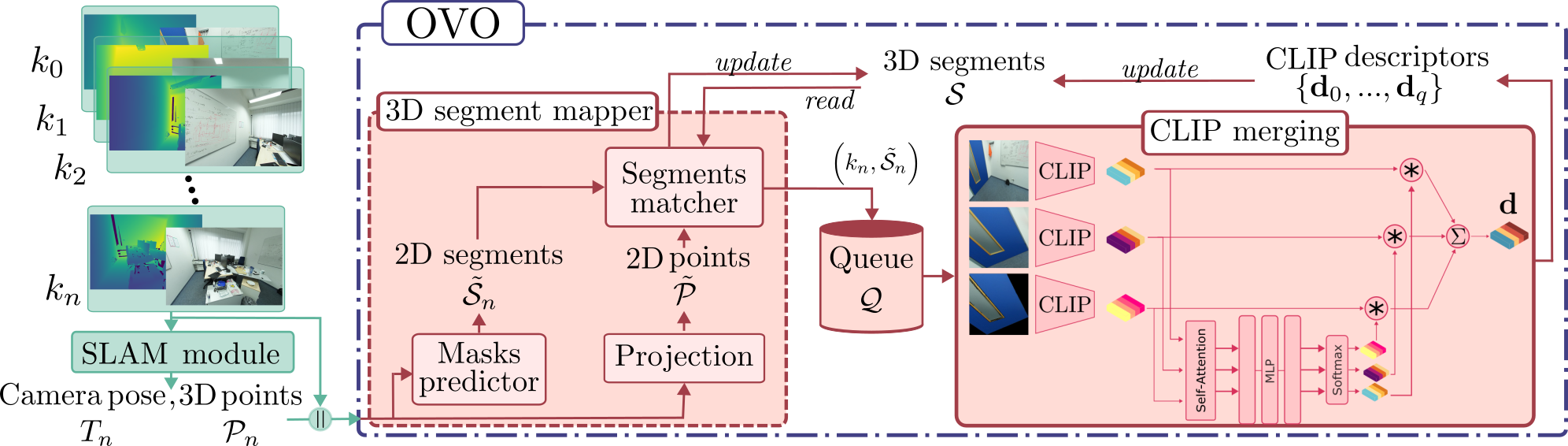
Figure 2: Overview of OVO’s operation, showcasing 3D semantic representation from RGB-D streams, relying on clustering and novel CLIP merging for efficient processing.
Integration and Loop Closure
OVO sets itself apart by integrating within full SLAM pipelines, allowing for efficient loop closure and minimizing odometric drift—a common challenge in SLAM applications. This integration ensures that segments are correctly merged post loop-closure corrections, refining the map for accurate semantic understanding.

Figure 3: Visualization of loop closure demonstrating the effective merging of instances after correcting for tracking drift.
Experimental Results
Comparative evaluations with state-of-the-art methods such as OpenScene, Open3DIS, and OpenNeRF confirm OVO's superior performance across various datasets like Replica and ScanNetv2. Notably, OVO exhibited higher mIoU and segmentation accuracy, particularly on infrequent (tail) categories, showcasing its robustness and adaptability in varied environments.

Figure 4: OVO's enhanced accuracy in 3D semantic segmentation on the Replica dataset, outperforming other offline baselines.
The paper also highlights the computational efficiency of OVO, being significantly faster than traditional methods while maintaining or exceeding performance, making it suitable for real-time applications.
CLIP Merging and Semantic Generalization
The innovative CLIP merging technique, which predicts per-dimension weights using a neural network, allows for the dynamic adaptation of descriptors. This adaptability results in strong generalization capabilities, enabling effective handling of unseen environments and zero-shot learning scenarios.

Figure 5: Demonstration of out-of-distribution queries successfully interpreted by OVO, showcasing its semantic generalization capacities.
Conclusion
OVO represents a significant step forward in open-vocabulary 3D mapping, offering a scalable solution that balances precision and computational demand. It broadens the applicability of semantic SLAM systems to operate effectively in open-ended real-world environments. This advancement is positioned to influence future developments in AI, specifically in autonomous navigation, robotic interaction, and augmented reality.
Overall, OVO's contribution to integrating language-guided semantic interpretation into SLAM systems marks a noteworthy evolution in the domain, setting new benchmarks for efficiency and adaptability in complex environments.