- The paper demonstrates a novel framework that extracts graphlets from biomedical knowledge graphs to generate 119,856 factually anchored QA pairs.
- It employs modular prompt engineering coupled with LLM-based curation and retrieval augmentation to enhance diversity and scientific grounding.
- Empirical results reveal that augmenting with 10,000 synthetic QA pairs significantly boosts accuracy on benchmarks like PubMedQA and MedQA under low-resource settings.
BioGraphletQA: Knowledge-Anchored Generation of Complex QA Datasets
Introduction and Motivation
BioGraphletQA introduces a principled, scalable framework for systematic generation of complex and factually-anchored biomedical question-answer (QA) datasets by leveraging graphlets—small, coherent subgraphs—extracted from domain-specific knowledge graphs (KGs). The framework addresses the primary limitations of traditional KGQA resource creation: manual curation is intractable at scale and template-based approaches lack requisite diversity and complexity, especially in high-stakes domains like biomedicine. Current LLM-based biomedical QA approaches are prone to hallucination and lack robust factual grounding, which is mitigated here using graph-derived prompts and multi-step data validation.
The initial instantiation, BioGraphletQA, is centered on the OREGANO KG and produces 119,856 QA pairs, each grounded in graphlets of 3–5 nodes. The resource is validated via domain expert annotation and downstream performance on PubMedQA and MedQA, with strong observed gains under low-resource settings.
Framework Overview
The proposed pipeline consists of five stages: (1) KG pre-processing and graphlet extraction, (2) modular prompt-based QA pair generation, (3) LLM-based automatic filtering, (4) retrieval of textual supporting evidence from PubMed, and (5) task-specific rephrasing for downstream QA settings.
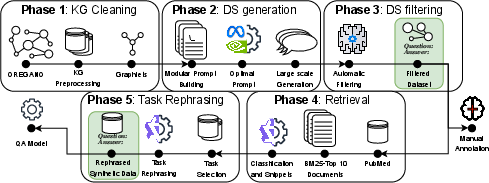
Figure 1: End-to-end data generation framework encompassing KG reduction, graphlet extraction, prompt creation, QA pair filtering, retrieval augmentation, and dataset adaptation for downstream tasks.
The framework’s modularity—encompassing both knowledge grounding and prompt engineering—yields complex, diverse, and scientifically credible QA pairs. By precisely controlling graphlet structure and leveraging multi-module prompt strategies, the method enables significant improvements over predecessor synthetic data approaches.
Knowledge Graph Preparation and Graphlet Extraction
OREGANO KG, selected for its comprehensive representation of biomedical entities and relations, underwent a two-stage pre-processing: entity hydration (enrichment and normalization of node identities) and structural reduction (removal of low-degree edge nodes and high-degree hubs to balance tractability with complexity).
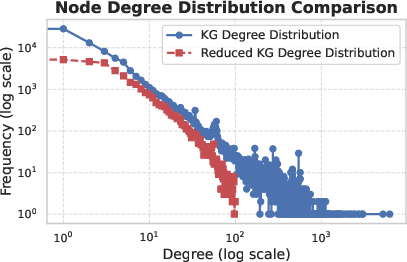
Figure 2: Comparison of raw and reduced OREGANO KG node degree distributions, highlighting the effects of graph cleansing and selection for optimal graphlet extraction.
Graphlet extraction was performed explicitly for all 29 non-isomorphic 3–5 node structures, yielding 269,574 distinct graphlets via efficient motif enumeration with targeted sampling to ensure structural diversity and computational feasibility.

Figure 3: Distribution of the 29 graphlet shapes, showing raw sample and final acceptance ratios after QA generation and post-filtering.
Modular Prompt Engineering and Data Generation
A structured, multi-module prompt design is employed, integrating graphlet topology and canonical entity names as contextual knowledge. The prompt omits explicit edge types to encourage LLM-induced relational inferences, enhancing linguistic richness. Prompt variants were systematically ablated and selected based on six LLM-judged quality criteria reflecting independence, fidelity, and scientific soundness of the generated QA pairs.
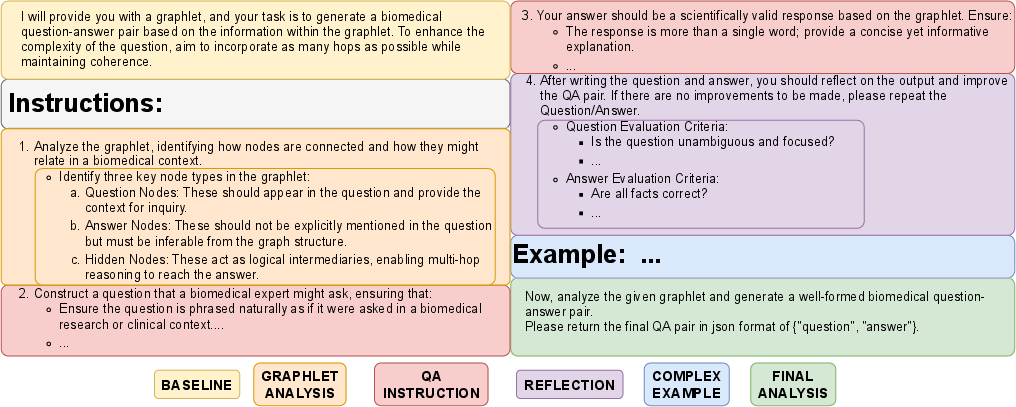
Figure 4: Abbreviated prompt structure with annotated modules showcasing the orchestration of graphlet-based factual grounding and trigger mechanisms for QA pair diversity and complexity.
Data generation using a quantized Llama-Nemotron-70B model yielded 269k raw QA pairs, subjected to multi-phase curation: removal of structurally invalid output, statistical length-based outlier pruning, and LLM-automated answer validation. The resulting resource retained only 45% (119,856) of the original pairs following strict filtering, ensuring high-quality standards.
LLM-Based Post-Generation Filtering and Human Validation
Automated LLM-based scoring of QA pairs for coherence and factuality enabled removal of outputs with incomplete, incoherent, or extraneously hallucinated content (independent from the generating graphlet context).
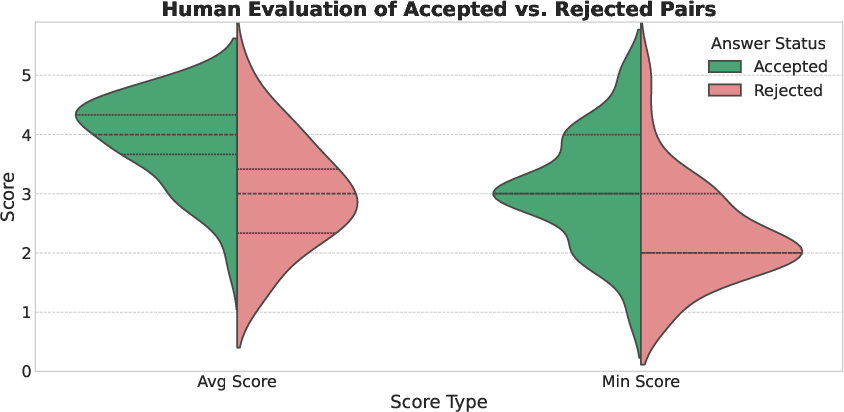
Figure 5: Human evaluation scores demonstrate a pronounced gap between LLM-accepted and LLM-rejected outputs, corroborating effectiveness of the automated filter.
A manual annotation round by a domain expert on a stratified validation set (across graphlet shapes, and accepted/rejected split) reinforced filtering efficacy. Accepted pairs scored high in scientific validity (100%) and complexity (88.46%), while specificity was slightly lower (79.49% achieving perfect scores).
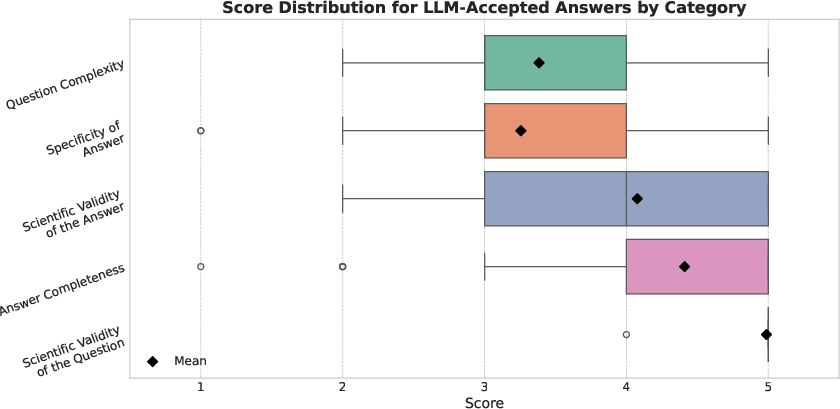
Figure 6: Boxplots of Likert-scale human annotation scores (scientific validity, complexity, answer completeness, and specificity) for LLM-accepted pairs indicate stringent quality retention criteria.
Retrieval-Augmented QA and Task-Specific Adaptation
Supporting document snippets from PubMed were appended to QA pairs through BM25-based retrieval and LLM-based relevance assessment (Qwen3-32B). Notably, 79% of QA pairs were backed by ≥2 abstracts, supporting evaluation of retrieval-augmented QA architectures and experimental setups.
The dataset was further adapted for PubMedQA (yes/no) and MedQA (MCQA) by automatic task-specific rephrasing, enabling direct, controlled benchmarking in standardized evaluation regimes.
Downstream Task Evaluation and Empirical Results
BioGraphletQA’s augmentation effects were tested on PubMedQA and MedQA benchmarks, employing BioLinkBERT-large as backbone. For PubMedQA, augmenting as little as 100 gold samples with 10,000 synthetic pairs boosted accuracy from 49.2% to 68.5%. On MedQA, supplementing the full training set with 10,000 synthetic pairs increased performance from 41.4% to 44.8%. Gains saturated and reversed with 20k synthetic samples, indicating an optimal augmentation size.
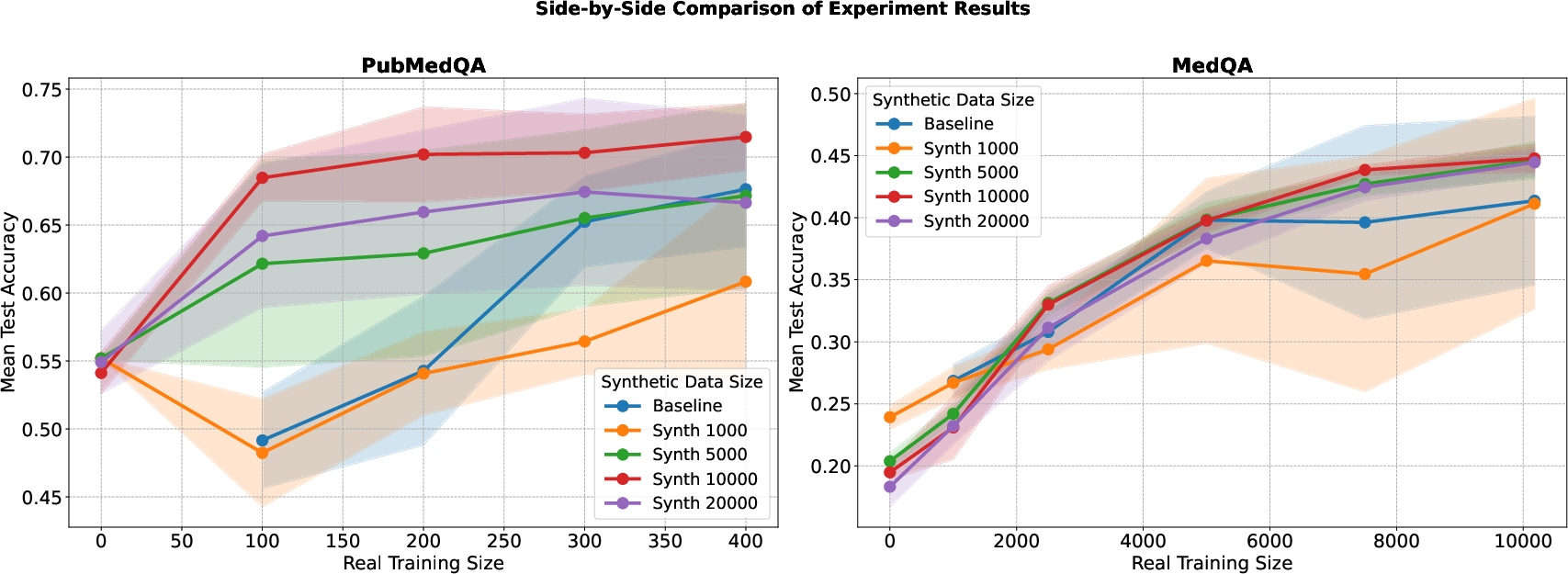
Figure 7: Performance curves for PubMedQA and MedQA. Augmentation with 10,000 synthetic QA pairs consistently yields maximal and stable improvements, especially in low-resource settings.
Discussion and Implications
BioGraphletQA establishes a robust pipeline for controllable, knowledge-anchored QA dataset generation, validated by stringent multi-phase filtering and human review. The empirical improvements in low-resource downstream benchmarks affirm the practical value of high-quality synthetic data for specialized QA in biomedicine.
The explicit modularity and extensibility of the framework allow adaptation to new KGs, domains, and expansion to multimodal or generative QA settings. Limitations include dependency on the LLM’s inherent biomedical knowledge boundaries and reliance on single-annotator validation. Expansion to multi-annotator settings and improvements in answer specificity are recommended.
Conclusion
BioGraphletQA demonstrates that principled, graphlet-anchored LLM prompting, paired with multi-stage data quality control and automated retrieval augmentation, delivers large-scale, complex, and scientifically robust biomedical QA resources. The dataset and framework provide a generalizable foundation for advancing MCQA and KGQA tasks, supporting continued methodological innovations in fact-anchored, high-complexity question answering.
Reference:
Jonker, R. A. A., Ribeiro de Abreu Martins, B. M., & Matos, S. "BioGraphletQA: Knowledge-Anchored Generation of Complex QA Datasets" (2604.26048).

