- The paper presents an innovative method for automatically generating context-based QA pairs, reducing the need for human labeling.
- It employs prompt-based techniques with Mistral-7b and QLoRA fine-tuning on models like Llama-3-8b to enhance logical coherence and factual accuracy.
- Experimental results on the TechQA dataset show improved reasoning and higher metrics such as BLEU, ROUGE, and F1 scores compared to manual annotations.
Automatic Dataset Generation for Knowledge Intensive Question Answering Tasks
The paper "Automatic Dataset Generation for Knowledge Intensive Question Answering Tasks" (2505.14212) proposes a novel method for enhancing LLMs in knowledge-intensive QA tasks through automated generation of context-based QA pairs. This approach leverages LLMs to create fine-tuning data, reducing the need for human labeling and improving model comprehension and reasoning capabilities. An automated QA generator and a model fine-tuner, evaluated using metrics like perplexity, ROUGE, BLEU, and BERTScore, demonstrate improvements in logical coherence and factual accuracy compared to human-annotated QA pairs.
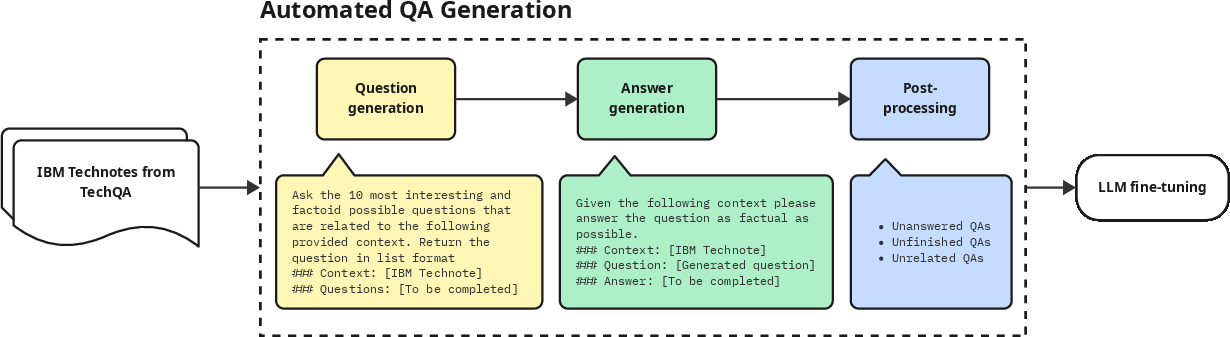
Figure 1: Example generation procedure of QA pairs with the TechQA dataset.
Introduction
Question-answering systems are designed to provide relevant answers to user questions and have become instrumental in customer support, technical document summarization, and report generation. Despite advancements through complex neural architectures such as Transformers, QA systems often struggle with queries requiring real-time knowledge integration and complex reasoning. Retrieval-Augmented Generation (RAG), introduced by Lewis et al., merges information retrieval techniques with generative LLMs, enhancing real-time document integration during the response generation process. However, RAG systems face challenges in handling complex reasoning between multiple sources of information.
To address these challenges, the paper introduces an automated method for generating context-based QA pairs, thereby reducing the reliance on human labeling while enhancing reasoning capabilities within LLMs. The method consists of an automatic QA generator and a model fine-tuner that leverage generated QA pairs to improve the target LLM's comprehension capabilities significantly.
Methodology
The methodology revolves around a self-improving cycle that generates synthetic datasets to reduce human intervention and enhance learning adaptability. The system architecture comprises two components:
- Automated QA Generator: Utilizes Mistral-7b-instruct-v0.3, leveraging prompt-based techniques to generate diverse and contextually relevant QA pairs from initial datasets. This LLM generates factoid questions and factual answers per document, using semantic similarity scoring for post-processing cleanup.
- Model Fine-Tuner: Utilizes QLoRA for efficient and memory-reduced fine-tuning of target LLMs, such as Llama-3-8b and Mistral-7b-v0.3. Optimized model updates incorporate standard fine-tuning methods using 0-shot, 1-shot, and 5-shot prompting strategies.
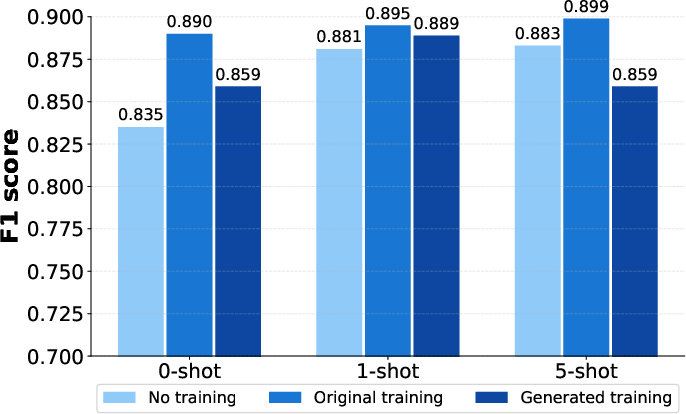
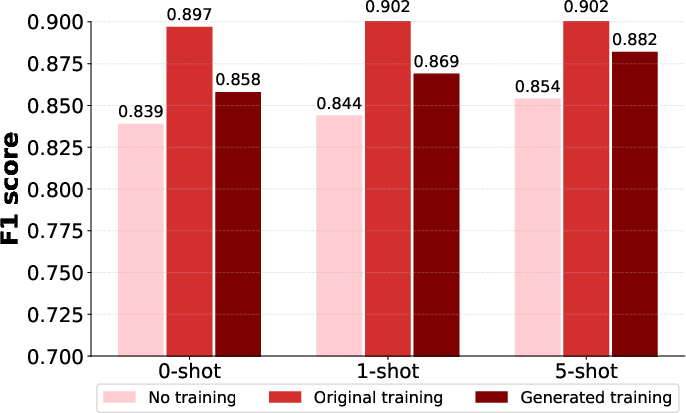
Figure 2: Llama-3-8b.
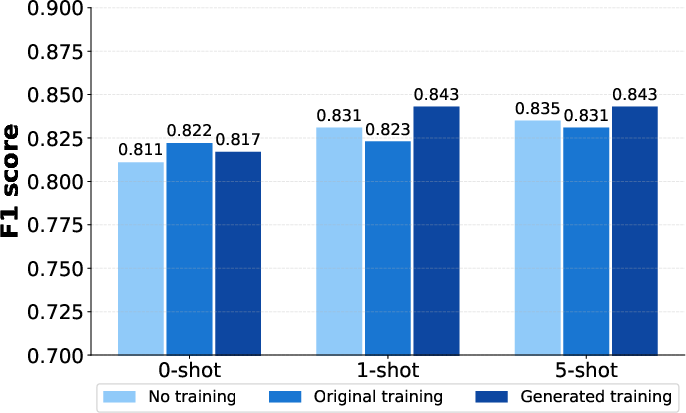
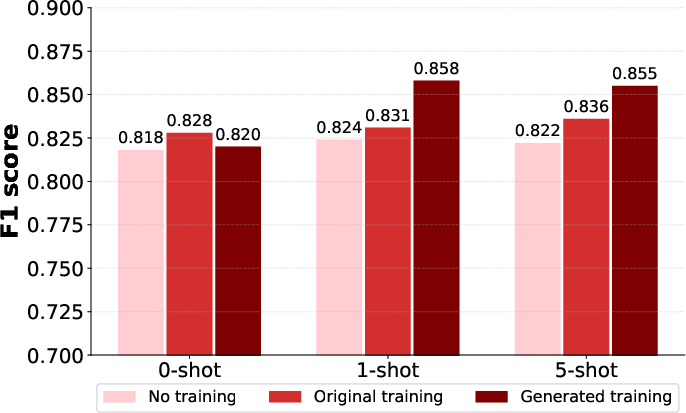
Figure 3: Llama-3-8b.
Experimental Results
Comprehensive experiments were conducted using the TechQA dataset, which includes technical QA instances. The synthetic datasets generated achieved superior performance metrics, notably in the absence of contextual documents, stressing models' reasoning capabilities.
- With Context: When provided with contextual documents, Llama-3-8b and Mistral-7b-v0.3 exhibited enhanced performance when trained on the original dataset, achieving higher precision and BLEU scores. The models displayed consistency across different prompting strategies.
- No Context: Without contextual documents, models trained on generated datasets performed better, indicating improved reasoning and knowledge integration. F1 scores demonstrated notable improvements in models trained with synthetic datasets.
Limitations and Impact
The approach is primarily tested on the TechQA dataset, with limitations in the generalization to other data types or domains. Fine-tuning utilized smaller models with computational efficiency considerations, leaving full-scope large models untested. While the automated system reduces human labor costs, there remain societal impacts, such as potential job displacement risks and biases associated with excessive reliance on synthetic data.
Conclusion
This paper successfully demonstrates the potential of automated QA dataset generation to enhance QA tasks within technical domains. While human-annotated datasets provide superior results when context is known, the synthetic generation offers an efficient alternative, facilitating quick adaptation to new domains without the need for costly human resources. Moving forward, this methodology opens avenues for developing sophisticated reasoning capabilities in LLMs, optimizing QA systems for diverse real-world applications.