- The paper introduces Hive, which uses a Logits Cache to eliminate redundant computations in advanced test-time scaling methods like Tree-of-Thoughts.
- It presents Agent-Aware Scheduling that dynamically allocates resources based on agent contribution, significantly reducing cache miss rates and improving throughput.
- Experimental evaluations demonstrate speedups from 1.11× to 1.76× and notable reductions in token evictions, validating Hive’s efficiency in multi-agent LLM systems.
Hive: Multi-Agent Infrastructure for Algorithm- and Task-Level Scaling
Motivation and Problem Scope
The proliferation of LLM-based agentic systems intensifies the demand for inferences that scale beyond the prevailing optimization of model size and hardware resources. Real-world deployments require scaling along algorithmic and task dimensions. At the algorithm level, the use of advanced test-time scaling methods (notably, hybrid methods like Tree-of-Thoughts) induces substantial cross-path redundancy—where distinct reasoning branches repeatedly recompute overlapping computation. At the task level, decomposing tasks into specialized agents (multi-agent systems) exposes heterogeneity in agent workloads that existing agent-agnostic schedulers do not exploit, resulting in inefficient resource allocation and cache miss patterns that degrade throughput.
Architecture Overview
Hive offers a principled infrastructure to address these challenges through a descriptive Pythonic front end and an optimized inference back end. The front end allows intuitive coroutine-based definition of agents and their supervisors, abstracting asynchronous agent spawning and test-time scaling within a unified flow graph model.
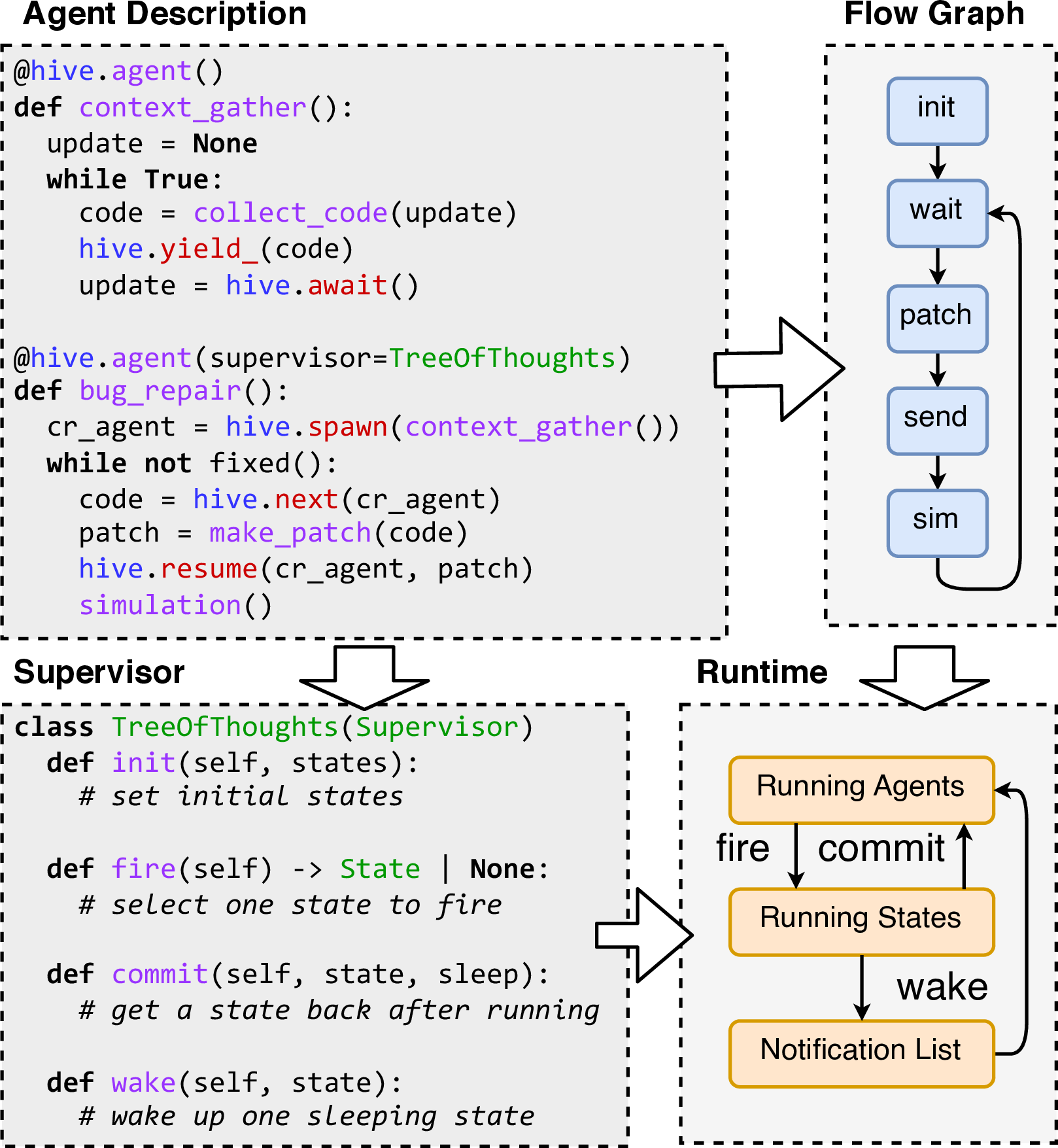
Figure 2: Hive’s Python-based front end generates agent flow graphs and integrates algorithmic supervisors into the runtime system.
On the back end, Hive introduces Logits Cache for algorithm-level redundancy elimination and Agent-Aware Scheduling for dynamic, contribution-weighted resource management.

Figure 4: Schematic of Hive’s backend architecture, integrating per-agent description, runtime profiling, Logits Cache, and agent-aware resource allocation.
Logits Cache: Redundancy Elimination Across Reasoning Paths
Hybrid test-time scaling (e.g., Tree-of-Thoughts) explores multiple reasoning branches via repeated resampling. Traditional prefix caching only amortizes computation up to the branch point, but trajectories frequently overlap well beyond their prefixes as sampling distributions over high-probability tokens lead to common subsequences.
Hive’s Logits Cache stores the logits sequences at each state during agent execution, enabling efficient replay-based resampling that avoids redundant forward passes through the transformer stack. Two replay policies are supported:
- Step-wise Sampling: Sequentially resamples tokens along the cached logits trajectory until the trajectory diverges.
- Hotspot Sampling: Selectively recomputes only at decode positions identified as "hotspots" of high entropy or importance, accepting cached tokens elsewhere to maximize prefix reuse.
Under both policies, memory-resident logits cache mitigates expensive compute on both CPU and GPU resources. Notably, the logit storage and lookup are orchestrated asynchronously to minimize RPC and I/O latency during inference.
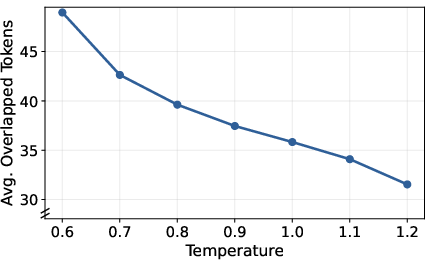
Figure 5: Visualization of branching and replay in Tree-of-Thoughts with Logits Cache, and detailed process of selective cache-based resampling.
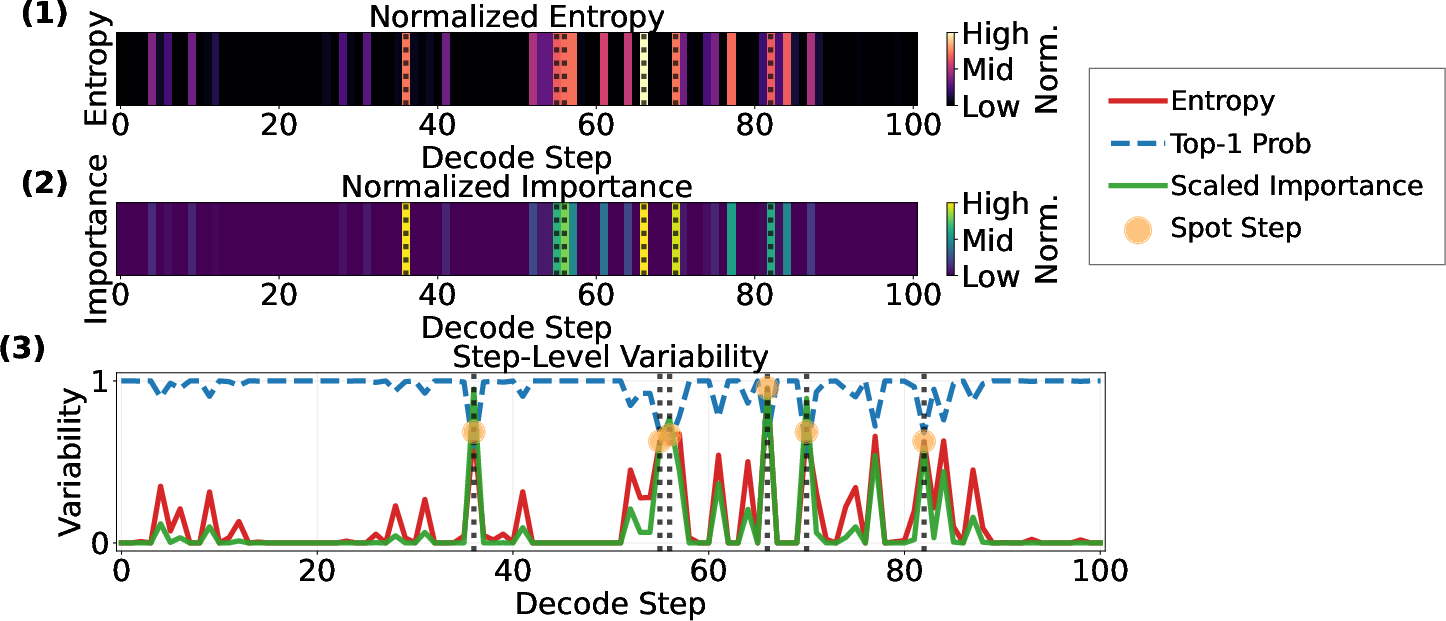
Figure 7: Average token overlap observed with step-wise sampling at various sampling temperatures, highlighting substantial redundancy.
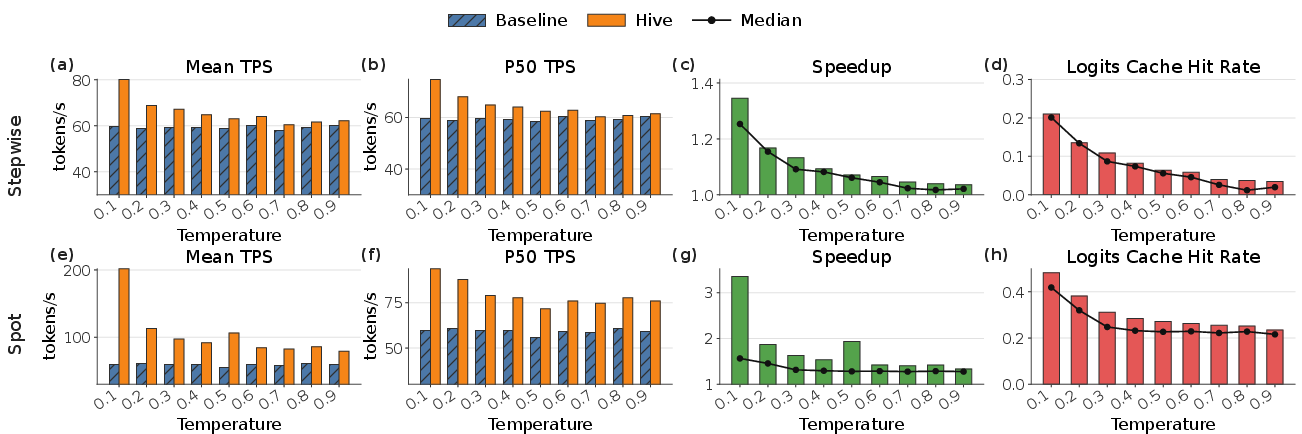
Figure 3: Evaluation of Logits Cache under varying temperatures and replay policies. Metrics include mean/median TPS, speedup, and hit rates, demonstrating consistent performance gains.
The empirical evaluation reveals average speedup of 1.11× (step-wise) to 1.76× (hotspot) in replay throughput and cache hit rates up to 30.4% under realistic low-temperature decode settings, meaning that a significant fraction of the replay computation is avoided via cache hits on redundant decoding (2604.17353).
Agent-Aware Scheduling: Heterogeneity-Aware Resource Management
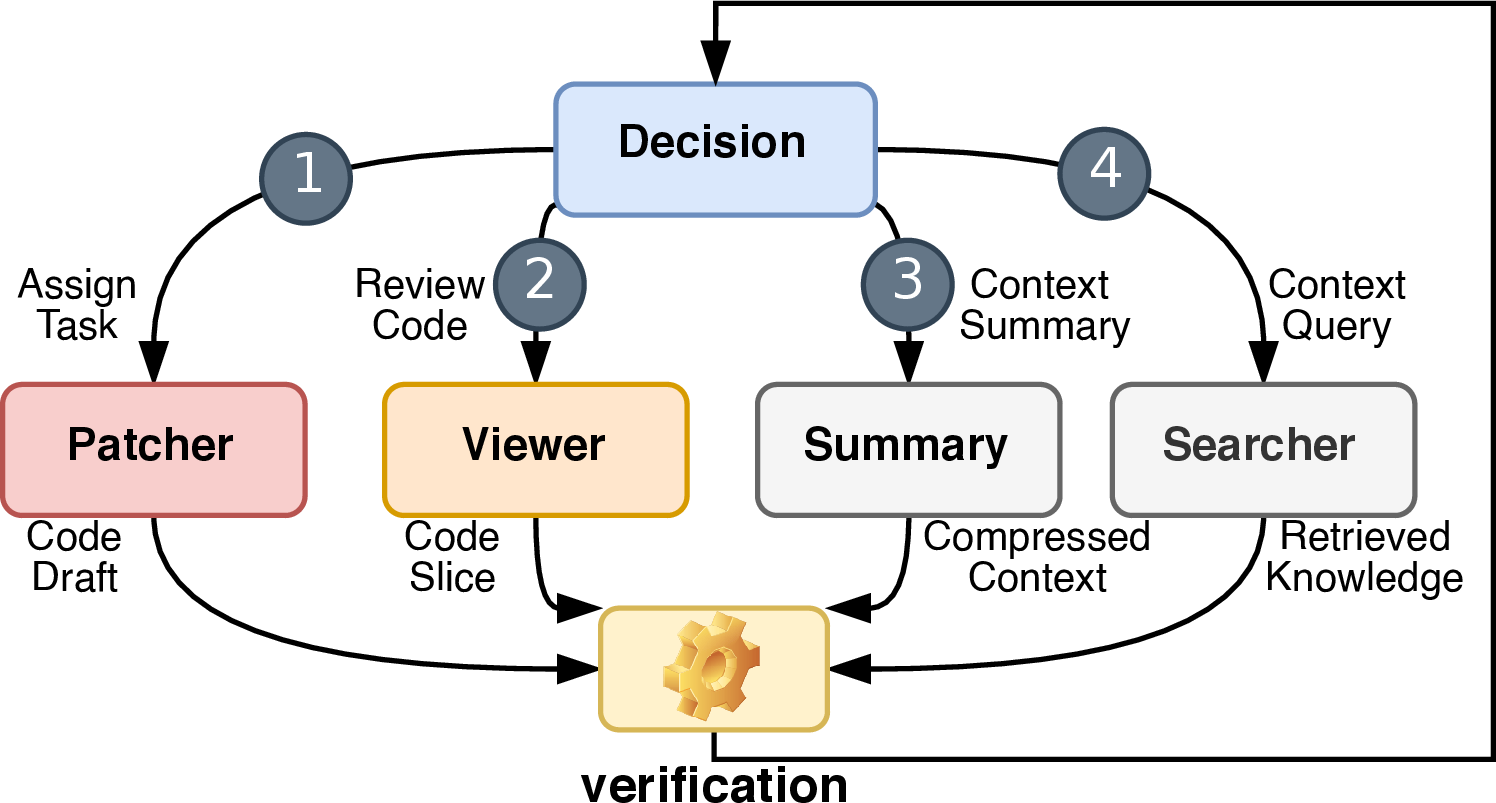
Conventional LLM serving platforms allocate KV cache and compute under simplistic LRU or request-uniform policies, suffering acute inefficiency for multi-agent systems where core agents (e.g., patchers, viewers) dominate invocation frequency and context retention, while auxiliary agents generate transitory workloads.
Hive’s runtime models each agent’s marginal system contribution via a Shapley-value-inspired scheme integrating:
KV cache residency is prioritized according to agent contribution scores, dynamically computed and updated to capture shifting workload patterns during execution.

Figure 6: Temporal evolution of normalized agent contribution scores over multiple scheduler rounds, reflecting adaptive response to agent workload changes.
Empirical results indicate that Agent-Aware Scheduling reduces KV cache evictions of critical state and achieves a 33–51% reduction in hotspot miss rate (besting unstructured LRU policies) and 19.2–30.2% in total evicted token count. This translates to improved latency and higher system throughput under highly concurrent, memory-constrained agent settings.
Evaluation Summary
Extensive experiments on representative Tree-of-Thoughts and multi-agent R³A workloads (Qwen3-8B, SGLang, A100 GPUs) validate both simulation and real-world efficiency gains. Notably, benefits are orthogonal to baseline model/hardware scaling, illustrating that algorithm- and task-level improvements realized by Hive are compositional with ongoing system-level innovation.
Implications and Future Outlook
Hive’s infrastructure enables practical deployment of LLM-powered agents at scale, supporting algorithm-level test-time scaling with redundancy-eliminating mechanisms and explicit, contribution-aware management of shared computation and memory resources across heterogeneous agents. The modular architecture allows extensibility: front end abstraction enables rapid prototyping of agent behaviors and integration of novel test-time scaling algorithms, while the back end can generalize to new cache structures and resource schedulers as agentic workloads continue to grow.
The next wave of research—motivated by the systemic findings established here—may extend Hive-style optimization toward distributed agentic serving, multi-model orchestration, and broadened definitions of agent contributions encompassing not only cache and compute but external tool, storage, and I/O patterns. The interplay between agent scheduling, adaptive resource partitioning, and algorithmic redundancy minimization will be central for scaling LLM-based systems to emerging "AI OS"-level deployments.
Conclusion
Hive provides a comprehensive infrastructure for LLM inference that fundamentally advances both algorithm- and task-level scaling in agentic settings. By introducing the Logits Cache and Agent-Aware Scheduling, Hive achieves substantial improvements in run-time efficiency, enabling robust large-scale multi-agent deployments. This work reframes LLM-system research to systematically address structure-aware execution patterns, setting a strong foundation for next-generation agentic architectures (2604.17353).