- The paper introduces Autellix, treating entire LLM programs as first-class scheduling units to minimize wait times and head-of-line blocking.
- The system incorporates PLAS and ATLAS metrics for adaptive scheduling, achieving 4-15x throughput improvements over traditional methods.
- Autellix integrates with existing LLM serving engines to enhance latency reduction and scalability across complex, agentic workloads.
Autellix: An Efficient Serving Engine for LLM Agents as General Programs
Introduction
The paper "Autellix: An Efficient Serving Engine for LLM Agents as General Programs" addresses the increasing complexity and scale of LLM applications, which require efficient serving solutions beyond individual LLM calls. Autellix proposes a novel serving system that considers LLM programs as first-class entities, optimizing end-to-end latencies by minimizing cumulative wait times and enhancing scheduling strategies for both single-threaded and distributed agentic programs.
Problem Statement
Current LLM serving systems often lack program-level context, leading to significant inefficiencies in handling dynamic and complex agentic applications. As highlighted, these systems face challenges like head-of-line blocking, where LLM requests experience long delays due to dependency-induced wait times. Autellix is designed to treat entire programs as fundamental units, thereby addressing these bottlenecks through enriched scheduling algorithms.
Proposed Solution
Autellix introduces a comprehensive framework that incorporates global program-level statistics into the scheduling process:
- Program-Level Attained Service (PLAS): This metric prioritizes LLM calls based on previously completed program-level service times, effectively reducing both call-level and program-level blocking.
- Adaptive Thread-Level Attained Service (ATLAS): Specifically for distributed programs, ATLAS optimizes scheduling by estimating critical paths and prioritizing threads accordingly.
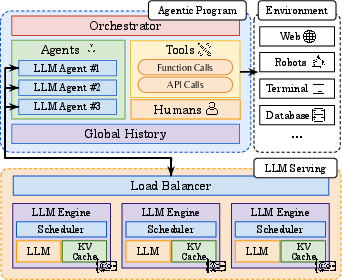
Figure 1: \smallAI Agent Infrastructure. Top: Developers and users build and execute agentic programs that orchestrate execution and persist global, cumulative history across agents, tools, and humans. Bottom: LLM serving systems process agents' LLM calls and route calls across one or more LLM engines.
System Architecture
Autellix integrates seamlessly as a layer on top of existing LLM serving engines, offering a stateful API for persistent session management. The architecture is divided into:
- Front-End: Simplifies the user's interface with Autellix, allowing programmatic LLM call management.
- Back-End Scheduler: Leverages PLAS and ATLAS for effective request scheduling.
- Load Balancer: Ensures efficient engine utilization by considering data locality, balancing short and long LLM call assignments accordingly.
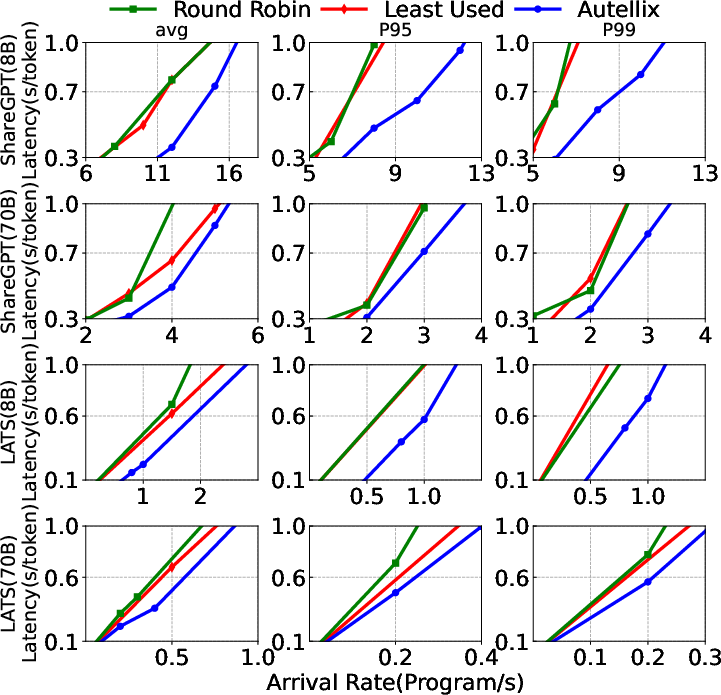
Evaluation and Results
The evaluation demonstrates Autellix's significant improvement in throughput and latency metrics across various workloads, outperforming baseline systems like vLLM and MLFQ:
Implementation Considerations
Autellix's deployment involves several intricate aspects:
- Scheduling Complexity: The introduction of PLAS and ATLAS necessitates efficient process tracking and priority management, but these are essential for reducing bottlenecks.
- Data Locality Optimizations: By optimizing LLM call routing based on program data sharing characteristics, Autellix minimizes redundant computations across engines.
- Scalability Potential: The system is designed for expansive LLM infrastructure, with demonstrated scalability across multiple engines and workloads.
Conclusion
Autellix represents a pivotal advancement in LLM serving systems by effectively treating entire programs as atomic units for scheduling, achieving remarkable improvements in efficiency and resource usage. The system's ability to dynamically adapt to agentic workloads highlights its relevance for future AI applications, ensuring sustained performance under increasing computational demands.
Future Directions
Future developments could expand Autellix's capabilities with speculative execution, incorporating insights from compiler optimizations to anticipate program paths further. Additionally, exploration into post-training LLM optimizations could complement Autellix's robust serving infrastructure, enhancing the overall capability of LLM-driven applications.