- The paper introduces an innovative aggregate LLM pipeline abstraction that leverages stable per-LLM execution fractions to predict workflow performance.
- It employs a joint GPU scheduler with topology-aware placement to dynamically balance latency and throughput in complex multi-LLM workflows.
- Experimental results demonstrate up to 2.4× higher throughput and 27× lower latency compared to conventional single-LLM serving methods.
Scepsy: Efficient Serving of Agentic Workflows via Aggregate LLM Pipelines
Motivation and Problem Statement
Agentic workflows orchestrating multiple heterogeneous LLMs and external tools are increasingly deployed to accomplish complex tasks while leveraging structured reasoning (e.g., beam search, MCTS) and external computation (e.g., RAG, code execution). However, serving these workflows within tight latency and throughput constraints poses substantial challenges in self-managed GPU clusters. The difficulties stem from arbitrary agentic programming models, unpredictable data-dependent workflow execution paths, conflicting latency-throughput-resource tradeoffs across models, and oversubscribed heterogeneous GPUs.
Current solutions either operate at the level of single LLMs or require restrictive workflows, suffering from inefficiencies and suboptimal allocations due to a lack of holistic, workflow-aware scheduling. Systems that rely on user-defined allocations or that schedule LLMs in isolation fail to account for complex inter-LLM dependencies and dynamic workloads.
Scepsy System Overview
Scepsy introduces a novel agentic workflow serving architecture that jointly optimizes GPU allocations for complex, dynamic, multi-LLM workflows. Its key insight is that while per-request execution times vary widely, the relative fraction of time spent on each constituent LLM is comparatively stable across requests (Figure 1). This observation enables Scepsy to predict end-to-end performance using aggregate per-LLM statistics, abstracting the workflow as an "Aggregate LLM Pipeline". This pipeline model captures both latency and throughput bottlenecks without requiring static program analysis or a priori knowledge of workflow structure.
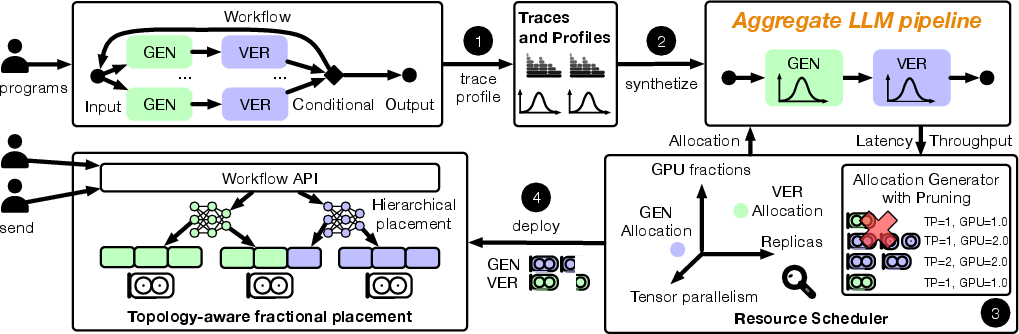
Figure 2: System overview showing profiling, pipeline abstraction, workflow prediction, and topology-aware placement in Scepsy.
Scepsy's architecture consists of several stages:
- Profiling Stage: Agentic workflows are profiled via execution traces that capture LLM invocations regardless of underlying programming model or framework.
- Statistical Aggregation: Average per-LLM invocation counts and concurrency levels are computed, capturing dynamic control flow characteristics.
- LLM Profiling: Fine-grained per-LLM performance curves are generated across various parallelism and resource allocation settings, preserving workload-specific token distributions.
- Aggregate LLM Pipeline Synthesis: Workflow-level performance is modeled as a pipeline of LLM stages, parameterized by the aggregated statistics and performance profiles.
- Joint GPU Scheduler: A hierarchical search explores fractional GPU allocations, tensor/data parallelism degrees, and replica counts to optimize the latency-throughput tradeoff under cluster and topology constraints.
- Topology-aware Placement: Allocations are deployed such that large LLMs are placed within high-bandwidth domains, while small fractions are tightly packed to minimize fragmentation.
Aggregate LLM Pipeline Abstraction
The Aggregate LLM Pipeline is Scepsy’s core abstraction. By leveraging relative execution-time fractions across LLMs—quantities empirically shown to be stable across uncontrolled, variable-length agentic workflow executions—Scepsy predicts both workflow latency and throughput with high fidelity.
Scepsy translates observed workflow traces into per-LLM invocation frequency nm and parallelism pm, producing per-LLM load estimates. The aggregate pipeline’s workflow-level latency is the sum of per-LLM average latency contributions (adjusted for parallelism), and the maximum achievable throughput is determined by the workflow's throughput bottleneck LLM:
Lw(λw)=m∑Lm(λw⋅nm)⋅pmnm
Tw=minmnmTm
where Lm and Tm are the per-LLM latency and throughput profiles at the effective per-LLM arrival rate.
This abstraction applies regardless of how many times a given LLM is invoked, the degree of fan-out/fan-in, or the dynamic structure of the workflow.
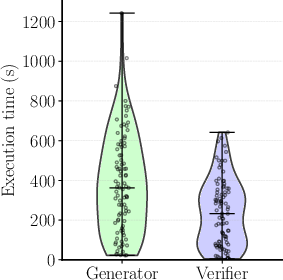
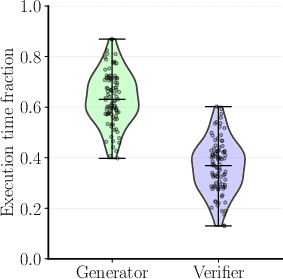
Figure 1: Absolute workflow execution times are highly variable for each LLM, while the relative fractions of time per LLM remain up to 4× more stable, enabling accurate resource allocation.
Advanced Scheduling and Placement
The scheduler in Scepsy performs a multi-dimensional search across:
- Fractional GPU allocations: Allowing co-location of models and more precise allocation than whole-GPU granularity.
- Tensor parallelism: Tradeoff between reduced individual request latency and replication for higher throughput, subject to interconnect bandwidth/topology.
- Replica counts: Increasing serving capacity for bottlenecked LLMs when latency permits.
The scheduler uses aggregate pipeline predictions to prune infeasible allocations, favoring placement that better matches LLMs' empirically observed latency demand. Placement is made topology-aware, grouping tensor-parallel replicas inside NVLink domains and prioritizing large allocations to avoid GPU fragmentation, which can otherwise impede subsequent deployments.
Scepsy supports arbitrary workflows authored in any programming model or agentic framework, requiring no user intervention or custom APIs, and predicts performance for unseen arrival rates and scale-out configurations.
Experimental Results and Claims
Scepsy demonstrates strong empirical improvements over Kubernetes autoscaling, Aegaeon accelerator-level multiplexing, and Ayo workflow-aware serving. For a 16-GPU cluster:
- Throughput Improvement: Up to 2.4× higher throughput over both single-LLM and multi-LLM serving baselines, especially when LLM resource demands are heterogeneous or when workflows exhibit significant per-request variation.
- Latency Reduction: Up to 27× lower average workflow latency, due to joint optimization and dynamic adjustment of parallelism and allocation granularity.
- Ablation Analysis: Both fractional co-location and parallelism tuning are necessary to maximize cluster utilization and optimize the throughput-latency tradeoff.
Scepsy's performance frameworks achieve these gains with search/placement times below one minute, even on cluster scales up to 128 GPUs and many LLM types, demonstrably enabling practical deployment at scale.
Implications and Future Directions
Scepsy operationalizes the insight that aggregate, steady-state reasoning over per-LLM metrics suffices to accurately optimize agentic workflow deployments in unpredictable, dynamic regimes. This enables autonomous, framework-agnostic resource management for rapidly evolving agentic programming paradigms, reducing operational overhead for smaller institutions and private clusters.
Theoretical implications: The Aggregate LLM Pipeline model abstracts away the combinatorial explosion of dynamic execution traces, enabling scalable, model-free optimization. This may influence future design of workflow serving systems and profiling-based performance modeling.
Practical implications: Scepsy enables flexible, performant self-managed LLM clusters, reducing GPU resource waste and improving the accessibility of agentic workflows outside hyperscaler environments.
Future directions:
- Extending the pipeline abstraction to dynamic fan-out/fan-in across LLMs or tools with significant compute footprints.
- Integrating error- or output-quality-aware resource allocation via utility functions.
- Adaptive, online pipeline statistics with drift detection for evolving workflow characteristics.
- Support for hardware heterogeneity, accelerator diversity, and variable cost targeting.
Conclusion
Scepsy introduces a new paradigm for agentic workflow serving: leveraging stable aggregate execution characteristics for accurate joint GPU allocation across dynamic, heterogeneous LLM workflows. Its Aggregate LLM Pipeline abstraction and advanced scheduler deliver substantial performance improvements without restricting programming model, substantiating aggregate profiling as a practical foundation for efficient multi-agent LLM serving. The approach paves the way for scalable, autonomous infrastructure for complex agentic workflows in resource-constrained deployments.

